
在本文中,我将讨论
SNA Hackathon 2019任务的文本部分的解决方案。 某些拟议的想法对3月30日至4月1日在Mail.ru Group莫斯科办公室举行的黑客马拉松全日制课程的参与者很有用。 此外,这个故事对于解决机器学习的实际问题的读者可能也很感兴趣。 由于我无法索取奖金(我在Odnoklassniki工作),因此我尝试提供最简单但有效且有趣的解决方案。
在阅读有关机器学习的新模型时,我想了解作者在执行任务时的推理方式。 因此,在本文中,我将尝试详细证实解决方案的所有组件。 在第一部分中,我将讨论问题陈述和局限性。 在第二个-关于模型的演变。 第三部分是模型的结果和分析。 最后,在评论中,我将尝试回答任何出现的问题。 不耐烦的读者可以立即查看
最终的体系结构 。
挑战赛
Hackathon组织者建议我们解决组成智能磁带的问题。 对于每个用户,有必要对一组帖子进行排序,以使用户将其设置为“类别”的帖子的最大数量位于列表的顶部。 为了配置排名算法,应该使用表格(用户,帖子,反馈)的历史数据。 该表对文本部分中的数据进行了简要说明,并在本文中将使用该符号。
来源
| 代号
| 型式
| 内容描述
|
|---|
用户
| user_id
| 绝对的
| 用户名
|
发布
| post_id
| 绝对的
| 邮政编号
|
发布
| 文字
| 分类清单
| 标准化单词列表
|
发布
| 特点
| 绝对的
| 帖子的特征组(作者,语言等)
|
意见回馈
| 意见回馈
| 二进制清单
| 用户可以对帖子执行的各种操作(视图,类,评论等)
|
在开始构建模型之前,我对将来的解决方案引入了一些限制。 为了满足简单性和实用性以及我的兴趣并减少可能的选择数量,这是必需的。 这是这些限制中最重要的。
预测“阶级”的可能性 。 我立即决定将这个问题作为分类问题来解决。 例如,可以应用排名中使用的方法来预测帖子对的顺序。 但是我决定采用一种更简单的表述,即根据预测获得“班级”的可能性对帖子进行排序。 值得注意的是,下面描述的方法可以扩展以制定排名。
整体模型 。 尽管模型合奏往往会赢得比赛,但要保持战斗系统的集成比单个模型要困难得多。 另外,我希望至少具有一些非黑匣子解释功能。
可微的计算图 。 首先,此类模型(神经网络)确定了许多任务中的最新技术,包括与
文本 数据 分析有关的任务。 其次,现代框架(在我的情况下为
Apache MXNet )使您可以实现非常多样化的架构。 因此,您只需更改几行代码即可尝试使用不同的模型。
尽量减少带标志的工作 。 我希望使用新数据轻松扩展模型。 在全职工作中可能需要这样做,因为那里准备时间很少。 因此,我决定采用最简单的方法来识别属性:
- 二进制数据由值为1或0的标签表示;
- 数值数据保持不变或离散化;
- 分类数据通过嵌入表示。
确定总体策略后,我开始尝试不同的模型。
模型演变
起点是矩阵分解方法,通常用于推荐任务中:
pi,j= sigma(ui cdotvj)
损失(yi,j,pi,j) rightarrowminu,v
用计算图的语言来说,这意味着用户
i将在职位
j上放置“类别”的概率的估计值是嵌入用户标识符和职位标识符的标量的S形。 可以用图表来表示:

这样的模型不是很有趣:它不使用所有功能,对于低频标识符不是太有用,并且存在冷启动的问题。 但是,通过以计算图的形式制定任务,我们“松开了手”,现在可以分阶段解决问题。 首先,对于低频值,我们将创建唯一
的词外嵌入。 接下来,摆脱具有相同尺寸的嵌入的需求。 为此,我们用浅的感知器代替标量乘积,该感知器接收级联特征作为输入。 结果显示在图中:

一旦摆脱了固定的维度,任何事情都不会阻止我们开始添加新属性。 用各种特征(语言,作者,文本等)表示帖子,我们将解决帖子冷启动的问题。 例如,该模型将学习到
user_id = 42的用户将“类”放在包含单词“ carpet”的俄语帖子中。 将来,我们将向该用户推荐所有关于地毯的俄语帖子,即使这些帖子未出现在培训数据中也是如此。 对于文本嵌入,目前,我们仅对其中包含的单词的嵌入进行平均。 结果,该模型如下所示:
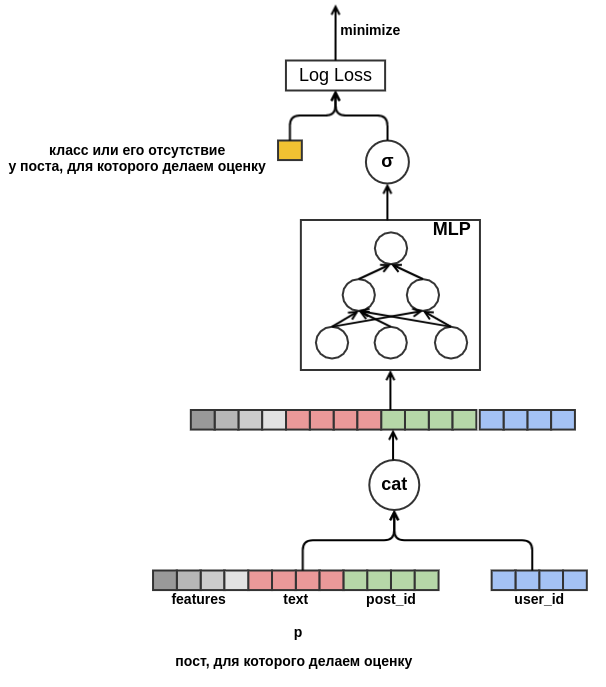
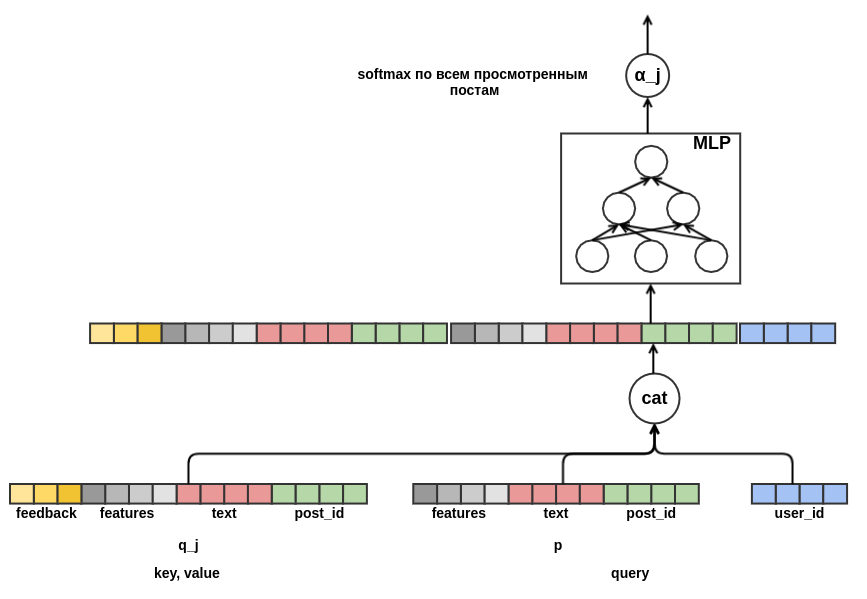
最后,我想面对用户的冷门。 可以根据帖子用户视图上的历史数据来构建要素。 这种方法不能满足所选择的策略:我们决定将手动创建属性的可能性降到最低。 因此,我为模型提供了机会,从正在评估“类别”可能性的帖子之前查看的帖子序列中独立学习用户的演示文稿。 与要评估的帖子不同,序列中每个帖子的所有反馈都是已知的。 这意味着该模型将可以访问有关用户是否已将“帖子”设置为先前帖子或相反地从供稿中删除它们的信息。

还有待决定如何将不同长度的柱序列组合成固定宽度的表示形式。 作为这种组合,我使用了每个职位代表的加权总和。 在图表上,后权重
j用
α_j表示。 权重是使用查询键值注意机制来计算的,类似于在
转换器或
NMT中使用的机制。 因此,还针对正在对其进行评估的帖子配置用户的学习演示。 这是一张负责计算
α_j的图:
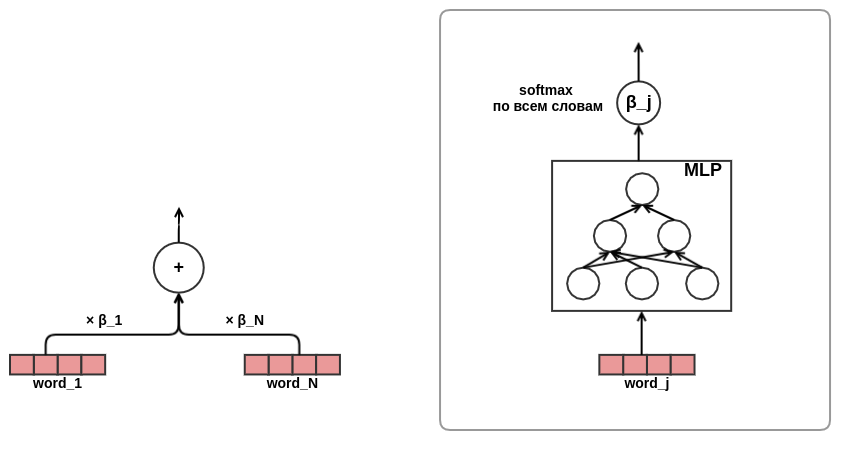
当我
感到狂欢后,我对注意方法的有效性深信不疑,于是决定在文本介绍中使用注意力。 为了节省时间和省力,我决定不像在同一个变压器中那样使用自注意力,而是直接训练文本中的单词权重,如下所示:
至此,模型架构的开发完成。 结果,我从经典矩阵分解变成了一个相当复杂的序列模型。
结果与分析
我在具有16 GB内存和GeForce 930MX显卡的笔记本电脑上,对数据的七分之一进行了开发和调试。 完整数据实验在具有256 GB内存和Tesla T4卡的专用服务器上运行。 为了进行优化,使用了具有MXNet默认参数的Adam算法。 该表显示了简化模型的结果-职位序列的长度限制为十个。 在竞赛提交中,我使用了长度为50的序列。
型号
| 日志丢失
| 上一行的改进
| 训练时间
|
|---|
随机的
| 0.4374±0.0009
| | |
感知器
| 0.4330±0.0010
| 0.0043±0.0002
| 7分钟
|
感知器的迹象
| 0.4119±0.0008
| 0.0212±0.0003
| 44分钟
|
带有一系列帖子的感知器
| 0.3873±0.0008
| 0.0247±0.0003
| 4小时16分钟
|
Perceptron在文章中有一系列的帖子和注意事项
| 0.3874±0.0008
| 0.0001±0.0001
| 4小时43分钟
|
最后一行对于我来说是最出乎意料的:在文本显示中使用注意力并不能明显改善结果。 我希望注意力网络能够学习文本中单词的权重,例如
idf 。 也许这没有发生,因为组织者提前删除了停用词,而准备好的清单中仍保留着同样重要的词。 因此,与简单平均相比,“智能”称量没有明显优势。 另一个可能的原因是单词的注意力网络很小:它只包含一个狭窄的隐藏层。 也许她缺乏代表能力来学习有用的东西。
查询键值关注机制使您可以查看模型内部,并找出制定决策时“关注”的内容。 为了说明这一点,我
选择了一些示例:
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g
第一行显示需要评估的帖子文本,然后显示先前查看的帖子和相应的注意力得分。 松了一口气,我们注意到该模型已学会忽略填充。 该模型认为帖子对于灵魂类型和Windows最重要。 应该牢记,注意力可以是正面的(用户将以关于灵气的帖子回应方式与关于灵魂类型的帖子大致相同)或负面的(我们对关于灵气的帖子进行评估-因此,反应与对该信息的反应不会相同技术)。 以下示例是“在所有荣耀中”的关注:
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ...
在此,模型清楚地看到了暑假的主题。 甚至儿童和小猫也走了过去。 下面的示例说明了不一定总是能够引起注意。 有时甚至一无所知:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300
在查看了许多此类列表之后,我得出结论,该模型能够了解我的期望。 接下来我要做的就是看单词的嵌入。 在我们的问题中,我们不能指望嵌入会变得像学习
语言模型时一样漂亮:我们试图预测一个嘈杂的变量,此外,我们没有一个小的上下文窗口-所有单词的嵌入都被简单地平均而不考虑其在文本中的顺序。 令牌及其在嵌入空间中最接近邻居的示例:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , ,
此列表中的某些内容很容易解释(程序-bl),某些内容令人困惑(iPhone-youki),但总的来说,结果再次达到了我的期望。
结论
我喜欢基于可微图构建模型的方法(
很多人 都同意 )。 它使您摆脱了繁琐的手动功能选择,而专注于问题的正确表述和有趣的体系结构的设计。 尽管我的模型在SNA Hackathon 2019文本任务中仅获得第二名,但由于其简单性和几乎无限的扩展选项,我对该结果感到非常满意。 我相信未来,基于类似思想的战斗系统将有越来越多有趣和适用的模型。