今天,我将告诉您如何解决将
Spark结构化流应用程序移植到
Kubernetes (K8)并实现CI流的问题。
这一切是如何开始的?
流媒体是FASTEN RUS BI平台的关键组成部分。 日期分析团队使用实时数据来构建运营报告。
流应用程序是使用
Spark结构化流实现的 。 该框架提供了方便的数据转换API,可以在改进速度方面满足我们的需求。
流本身在
AWS EMR集群上上升。 因此,在向集群提出新的流时,将布置一个ssh脚本来提交Spark-job,然后启动该应用程序。 起初,一切似乎都适合我们。 但是随着流数量的增加,实现CI流的需求变得越来越明显,这将在启动用于在新实体上传递数据的应用程序时增加分析日期命令的自主性。
现在,我们将探讨如何通过将流媒体移植到Kubernetes来解决此问题。
为什么选择Kubernetes?
Kubernetes作为资源管理器,最适合我们的需求。 这是一个无需停机的部署,并且是Kubernetes上的各种CI实施工具,包括Helm。 此外,我们的团队在K8上实施CI管道方面具有足够的专业知识。 因此,选择是显而易见的。
基于Kubernetes的Spark应用程序管理模型是如何组织的?

客户端在K8上运行spark-submit。 创建了一个应用程序驱动程序窗格。 Kubernetes Scheduler将Pod绑定到集群节点。 然后,驱动程序发送一个请求来创建要运行执行程序的Pod,Pod被创建并附加到集群节点。 之后,执行一组标准操作,随后将应用程序代码转换为DAG,分解为阶段,分解为任务并在可执行文件上执行。
手动启动Spark应用程序时,此模型非常成功。 但是,在CI实施方面,在集群外部启动spark-submit的方法并不适合我们。 有必要找到一种解决方案,使Spark可以直接在集群的节点上运行(执行spark-submit)。 Kubernetes运营商模型完全可以满足我们的要求。
Kubernetes Operator作为Spark应用程序生命周期管理模型
Kubernetes Operator是CoreOS提出的在Kubernetes中管理全状态应用程序的概念,涉及自动化操作任务,例如部署应用程序,在出现文件的情况下重新启动应用程序,更新应用程序的配置。 关键的Kubernetes运算符模式之一是CRD(
CustomResourceDefinitions ),它涉及向K8s集群添加自定义资源,从而允许您像使用本地Kubernetes对象一样使用这些资源。
操作员是驻留在群集容器中的守护程序,它响应自定义资源状态的创建/更改。
考虑将此概念用于Spark应用程序生命周期管理。
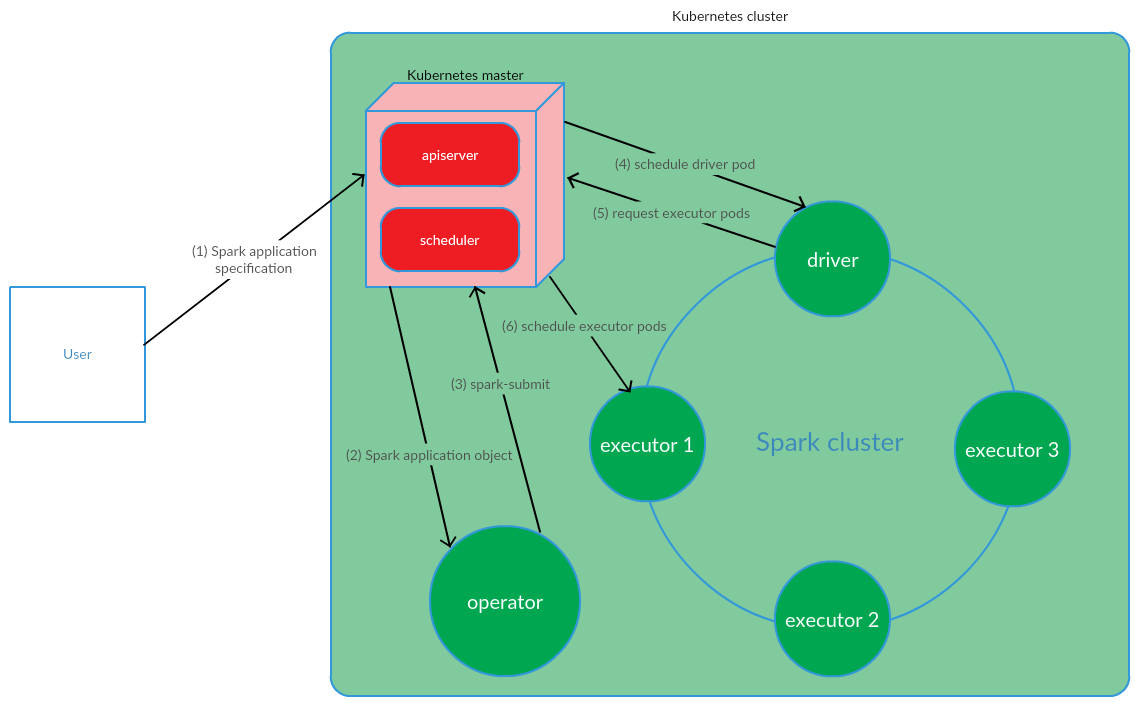
用户运行kubectl apply -f spark-application.yaml命令,其中spark-application.yaml是Spark应用程序的规范。 操作员接收Spark应用程序对象并执行spark-submit。
如我们所见,Kubernetes Operator模型涉及直接在Kubernetes集群中管理Spark应用程序的生命周期,这在解决我们的问题的背景下是支持该模型的一个严肃的论点。
作为管理流应用程序的Kubernetes运营商,决定使用
spark-on-k8s-operator 。 该运算符提供了一个相当方便的API,以及为Spark应用程序配置重启策略的灵活性(这在支持流应用程序的上下文中非常重要)。
CI实施
为了实现CI流,使用了
GitLab CI / CD 。 使用
Helm工具在K8上部署了Spark应用程序。
管道本身涉及两个阶段:
- 测试-执行语法检查,以及渲染Helm模板;
- 部署-将流应用程序部署到测试(dev)和产品(prod)环境。
让我们更详细地考虑这些阶段。
在测试阶段,
将使用特定于环境的值来
呈现 Spark应用程序Helm模板(CRD-
SparkApplication )。
Helm模板的关键部分包括:
- 火花:
- 版本-Apache Spark版本
- image-使用的Docker映像
- nodeSelector-包含与炉膛标签相对应的列表(键→值)。
- 公差-指示Spark应用程序的公差列表。
- mainClass-Spark应用程序类
- applicationFile-Spark应用程序jar所在的本地路径
- restartPolicy-Spark应用程序重启策略
- 从不-完整的Spark应用程序不会重新启动
- 始终-不论停止原因如何,完成的Spark应用程序都会重新启动。
- OnFailure-仅在有文件的情况下,Spark应用程序才会重新启动
- maxSubmissionRetries-Spark应用程序的最大提交数量
- 驱动程序/执行程序:
- cores-分配给驱动程序/执行程序的内核数
- 实例(仅用于配置高管)-高管数量
- memory-分配给驱动程序/执行程序进程的内存量
- memoryOverhead-分配给驱动程序/执行程序的堆外内存量
- 流:
- 名称-流应用程序的名称
- arguments-流应用程序的参数
- sink-S3上的Data Lake数据集的路径
渲染模板后,使用Helm将应用程序部署到开发测试环境。
制定出CI管道。
然后,我们启动deploy-prod作业-在生产中启动应用程序。
我们坚信工作成功。
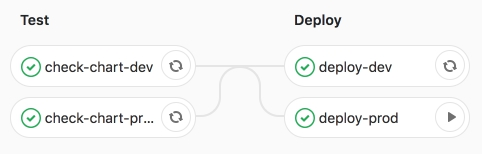
如下所示,应用程序正在运行,窗格处于RUNNING状态。

结论
将Spark结构化流应用程序移植到K8以及随后的CI实施使我们能够自动启动流的发布,以将数据传递给新实体。 要引发下一个流,足以准备合并请求,并在yaml值文件中描述Spark应用程序的配置,并且当deploy-prod作业开始时,将启动向Data Lake(S3)的数据传递。 当执行与向存储库中添加新实体相关的任务时,此解决方案确保了分析日期命令的自治性。 此外,将流媒体移植到K8上,尤其是使用Kubernetes Operator的spark-on-k8s-operator管理Spark应用程序,大大提高了流媒体的弹性。 但是在下一篇文章中会对此进行更多介绍。