哈Ha!
我在一家开发在线游戏的游戏公司工作。 目前,我们所有的游戏都被划分为多个“市场”(每个国家/地区一个“市场”),并且在每个“市场”中都有十几个世界,玩家在注册时可以在这些世界之间进行分配(当然,有时他们可以自己选择)。 每个世界都有一个数据库和一个或多个Web /应用程序服务器。 因此,负载几乎均匀地分布在世界/服务器之间,结果,我们获得了最大的在线6K-8K播放器(这是最大数量,多数情况下少了几倍),每个世界每个黄金时段有200-300个请求。
这种将参与者分为市场和世界的结构已经过时;参与者希望获得全球化的东西。 在上一届的比赛中,我们停止了按国家/地区划分人员,只留下了一个/两个市场(美国和欧洲),但每个市场仍然有很多世界。 下一步将是开发具有新架构的游戏,并通过
一个数据库将所有玩家统一在一个世界中。
今天,我想谈谈我的任务是如何检查一个流行游戏的整个网络(一次是50-200,000个用户)是否“发送”以玩基于新架构的下一款游戏,以及是否整个系统,特别是数据库(
PostgreSQL 11 )实际上可以承受这样的负载,如果不能承受,则找出最大值。 我将告诉您一些有关已出现的问题以及准备测试如此多的用户的决定,过程本身以及有关结果的信息。
前言
过去,在
InnoGames GmbH,每个游戏团队经常使用不同的技术,编程语言和数据库来根据自己的口味和肤色创建一个游戏项目。 此外,我们有许多外部系统负责付款,发送推送通知,营销等。 为了与这些系统一起使用,开发人员还尽可能地创建了他们独特的界面。
当前在移动游戏业务中有很多
钱 ,因此竞争也很多。 在这里,从营销上花费的每一美元以及从上面获得的更多钱取回都是非常重要的,因此,即使所有游戏公司都不满足分析期望,即使在封闭测试阶段,它们也经常“关闭”游戏。 因此,在下一轮发明上浪费时间是无利可图的,因此决定创建一个统一的平台,该平台将为开发人员提供一个现成的解决方案,用于与所有外部系统,带有复制的数据库和所有最佳实践的集成。 开发人员所需要做的就是在此基础上开发和“投放”一款出色的游戏,而不是在与游戏本身无关的开发上浪费时间。
这个平台叫做
GameStarter :

所以,到了重点。 将来所有InnoGames游戏都将在此平台上构建,该平台具有两个数据库-master和game(PostgreSQL 11)。 Master会存储有关玩家的基本信息(登录名,密码等),并且主要仅参与游戏本身的登录/注册过程。 游戏-游戏本身的数据库,相应地,所有游戏数据和实体都存储在该数据库中,这是游戏的核心,整个负载将在此存储。
因此,出现了一个问题,即整个结构是否可以承受这样一个潜在的用户数量,该数量等于我们最受欢迎的游戏之一的最大在线人数。
挑战赛
任务本身是这样的:检查启用了复制的数据库(PostgreSQL 11)是否可以承受整个PowerEdge M630系统管理程序(HV)所承受的当前负载最大的游戏中的所有负载。
我要澄清的是,目前的任务
只是使用现有的数据库配置
来验证 ,我们是根据最佳做法和我们自己的经验形成的。
我马上要说数据库,整个系统显示得很好,除了几点。 但是,这个特定的游戏项目处于原型阶段,并且在将来,随着游戏机制的复杂化,对数据库的请求将变得更加复杂,负载本身可能会显着增加,并且其性质可能会发生变化。 为避免这种情况,有必要对每个或多或少重要的里程碑进行迭代测试。 在数十万名用户中自动化运行这些测试的能力已成为现阶段的主要任务。
个人资料
像任何负载测试一样,这一切都从负载配置文件开始。
我们的潜在价值CCU60(CCU是特定时间段内的最大用户数,在这种情况下为60分钟)为
250,000个用户。 竞争性虚拟用户(VU)的数量低于CCU60,分析家建议可以将其安全地分为两个。 汇总并接受
150,000个竞争性VU。
每秒的总请求数来自一个负载比较大的游戏:
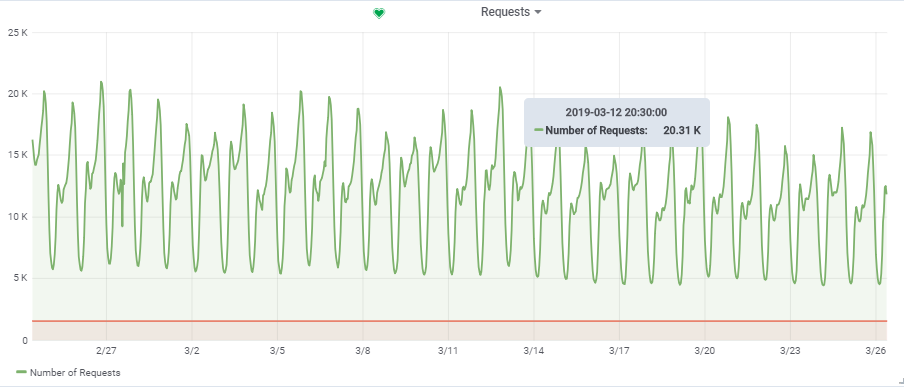
因此,我们的目标负载为
150,000 VU时〜20,000
个请求/秒 。
结构形式
“看台”的特征
在上
一篇文章中,我已经讨论了自动化负载测试的整个过程。 此外,我可能会再说一遍,但我会更详细地告诉您一些要点。

在图中,蓝色方块是我们的虚拟机管理程序(HV),它是由许多服务器(Dell M620-M640)组成的云。 在每个HV上,通过KVM(混合的Web /应用程序和数据库)启动了十二个虚拟机(VM)。 创建任何新的VM时,会在适当的HV的参数集中进行平衡和搜索,并且最初不知道它将在哪个服务器上运行。
数据库(游戏数据库):
但出于db1的目的,我们基于
M630保留了单独的HV targer_hypervisor。
targer_hypervisor的简要特征:
戴尔M_630
型号名称:英特尔®至强®CPU E5-2680 v3 @ 2.50GHz
CPU(s):48
每个核心线程数:2
每个插槽的芯数:12
插座:2
内存:128 GB
Debian GNU / Linux 9(延伸)
4.9.0-8-amd64#1 SMP Debian 4.9.130-2(2018-10-27)
详细规格Debian GNU / Linux 9(延伸)
4.9.0-8-amd64#1 SMP Debian 4.9.130-2(2018-10-27)
lscpu
架构:x86_64
CPU操作模式:32位,64位
字节顺序:小尾数
CPU(s):48
在线CPU列表:0-47
每个核心线程数:2
每个插槽的芯数:12
插座:2
NUMA个节点:2
供应商ID:正版英特尔
CPU系列:6
型号:63
型号名称:英特尔®至强®CPU E5-2680 v3 @ 2.50GHz
步进:2
CPU MHz:1309.356
CPU最大MHz:3300.0000
CPU最低MHz:1200.0000
BogoMIPS:4988.42
虚拟化:VT-x
L1d快取:32K
L1i缓存:32K
L2快取:256K
三级缓存:30720K
NUMA node0 CPU(s):0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42 44.46
NUMA node1 CPU:1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43 ,45.47
标志:fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm常数qtsopmooptoptsoptsoptsoptsoptsoptsoptsoptsopts SMX EST TM2 SSSE3 SDBG FMA CX16 xtpr PDCM PCID DCA sse4_1 sse4_2 x2apic movbe POPCNT tsc_deadline_timer AES XSAVE AVX F16C rdrand lahf_lm ABM EPB invpcid_single SSBD IBRS ibpb stibp凯泽tpr_shadow vnmi FlexPriority可EPT VPID fsgsbase tsc_adjust BMI1 AVX2 SMEP bmi2 ERMS invpcid CQM xsaveopt cqm_llc cqm_occup_llc dtherm IDA阿拉特pln积分flush_l1d
/ usr / bin / qemu-system-x86_64 --version
QEMU仿真器版本2.8.1(Debian 1:2.8 + dfsg-6 + deb9u5)
版权所有©2003-2016 Fabrice Bellard和QEMU项目开发人员
db1的简要特征:
架构:x86_64
CPU(s):48
内存:64 GB
4.9.0-8-amd64#1 SMP Debian 4.9.144-3.1(2019-02-19)x86_64 GNU / Linux
Debian GNU / Linux 9(延伸)
psql(PostgreSQL)11.2(Debian 11.2-1.pgdg90 +1)
PostgreSQL配置和一些解释seq_page_cost = 1.0
random_page_cost = 1.1#我们有SSD
包括'/etc/postgresql/11/main/extension.conf'
log_line_prefix ='%t [%p-%l]%q%u @%h'
log_checkpoints =开启
log_lock_waits =开
log_statement = ddl
log_min_duration_statement = 100
log_temp_files = 0
autovacuum_max_workers = 5
autovacuum_naptime = 10秒
autovacuum_vacuum_cost_delay = 20ms
vacuum_cost_limit = 2000
maintenance_work_mem = 128MB
sync_commit =关
checkpoint_timeout = 30分钟
listen_addresses ='*'
work_mem = 32MB
Effective_cache_size = 26214MB#50%的可用内存
shared_buffers = 16384MB#可用内存的25%
max_wal_size = 15GB
min_wal_size = 80MB
wal_level = hot_standby
max_wal_senders = 10
wal_compression =开启
archive_mode =开
archive_command ='/ bin / true'
archive_timeout = 1800
hot_standby =开启
wal_log_hints =开启
hot_standby_feedback =开启
hot_standby_feedback默认为关闭,我们已将其打开,但后来必须将其关闭才能进行成功的测试。 稍后我将解释原因。
数据库中的主要活动表(构造,生产,游戏实体,建筑物,core_inventory_player_resource,幸存者)使用bash脚本预先填充了数据(大约80GB)。
复制:
SELECT * FROM pg_stat_replication; pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state -----+----------+---------+---------------------+--------------+---------------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------ 759 | 17035 | repmgr | xl1db2 | xxxx | xl1db2 | 51142 | 2019-01-27 08:56:44.581758+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000393 | 00:00:00.001159 | 00:00:00.001313 | 0 | async 977 | 17035 | repmgr | xl1db3 |xxxxx | xl1db3 | 42888 | 2019-01-27 08:57:03.232969+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000373 | 00:00:00.000798 | 00:00:00.000919 | 0 | async
应用服务器
然后,在各种配置和容量的生产性HV(prod_hypervisors)上,启动了15个应用程序服务器:8个内核,4GB。 可以说的最主要的事情:openjdk 11.0.1 2018-10-16,春季,通过
hikari与数据库交互(hikari.maximum-pool-size:50)
压力测试环境
整个负载测试环境由一台主服务器
admin.loadtest和几
台generatorN.loadtest服务器组成(本例中有14台)。
generatorN.loadtest- “裸机” VM Debian Linux 9,已安装Java8。32个内核/ 32 GB。 它们位于“非生产型” HV上,以免意外破坏重要VM的性能。
admin.loadtest -Debian Linux 9
虚拟机 ,16个核心/ 16个演出,它运行Jenkins,JLTC和其他其他不重要的软件。
JLTC-
jmeter负载测试中心 。 Py / Django中的一个系统,用于控制和自动化测试的启动以及结果的分析。
测试启动方案

运行测试的过程如下所示:
- 该测试从詹金斯(Jenkins )启动。 选择所需的作业,然后您需要输入所需的测试参数:
- 持续时间-测试持续时间
- RAMPUP- “热身”时间
- THREAD_COUNT_TOTAL-所需的虚拟用户数(VU)或线程
- TARGET_RESPONSE_TIME是一个重要的参数,因此为了避免整个系统过载,我们设置了所需的响应时间,因此该测试会将负载保持在整个系统的响应时间不超过指定响应时间的水平。
- 发射
- Jenkins从Gitlab克隆了测试计划,并将其发送给JLTC。
- JLTC可以配合测试计划工作(例如,插入CSV简单编写器)。
- JLTC计算所需数量的Jmeter服务器以运行所需数量的VU(THREAD_COUNT_TOTAL)。
- JLTC连接到每个loadgeneratorN生成器并启动jmeter服务器。
在测试期间,
JMeter客户端会生成一个包含结果的CSV文件。 因此,在测试过程中,数据量和该文件的大小以惊人的速度增长,并且在测试
Daemon发明出来(作为实验)后就无法用于分析,
Daemon可以
“动态”解析它。
测试计划
您可以在
此处下载测试计划。
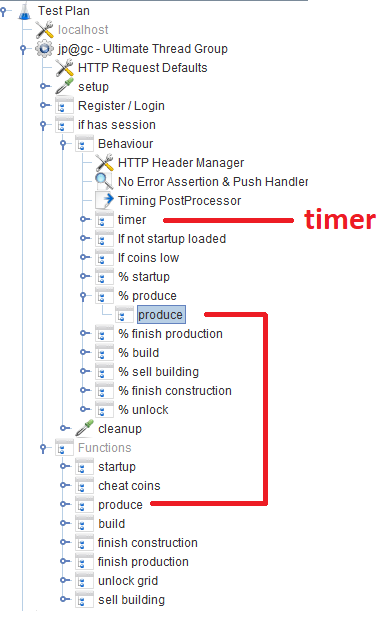
注册/登录后,用户将在“
行为”模块中工作,该模块由几个
吞吐量控制器组成,这些
控制器指定特定游戏功能的可能性。 在每个吞吐量控制器中,都有一个
模块控制器 ,它引用实现该功能的相应模块。
离题
在脚本的开发过程中,我们尝试最大程度地使用Groovy,并且由于我们的Java程序员,我为自己找到了一些技巧(也许对某人有用):
VU /线程
在Jenkins中配置作业时,当用户使用THREAD_COUNT_TOTAL参数输入所需数量的VU时,有必要以某种方式启动所需数量的Jmeter服务器并在它们之间分配最终VU数量。 这部分与JLTC一起位于称为
控制器/配置的部分中。
本质上,算法如下:
- 我们将所需数量的VUthreads_num划分为200-300个线程,并根据或多或少的适当大小-Xmsm -Xmxm确定一个jmeter-server required_memory_for_jri (JRI-我称为Jmeter远程实例,而不是Jmeter-server)的所需内存值。
- 从threads_num和Required_memory_for_jri中 ,我们找到了jmeter服务器的总数: target_amount_jri和所需内存的总数: required_memory_total 。
- 我们将所有loadgeneratorN生成器一一分类,并根据其上的可用内存启动最大数量的jmeter服务器。 只要正在运行的current_amount_jri实例数不等于 target_amount_jri。
- (如果生成器数和总内存不足,请向池中添加一个新的)
- 我们使用netstat连接到每个生成器, 我们会记住所有繁忙的端口,并在所需数量的jmeter服务器上的随机端口(未占用的端口)上运行:
netstat_cmd= 'netstat -tulpn | grep LISTEN' stdin, stdout, stderr = ssh.exec_command(cmd1) used_ports = [] netstat_output = str(stdout.readlines()) ports = re.findall('\d+\.\d+\.\d+\.\d+\:(\d+)', netstat_output) ports_ipv6 = re.findall('\:\:\:(\d+)', netstat_output) p.wait() for port in ports: used_ports.append(int(port)) for port in ports_ipv6: used_ports.append(int(port)) ssh.close() for i in range(1, possible_jris_on_host + 1): port = int(random.randint(10000, 20000)) while port in used_ports: port = int(random.randint(10000, 20000))
- 我们一次收集所有正在运行的jmeter服务器,其格式为地址:端口,例如generator13:15576,generator9:14015,generator11:19152,generator14:12125,generator2:17602
- 测试开始时,结果列表和threads_per_host将发送到JMeter客户端:
REMOTE_TESTING_FLAG=" -R $REMOTE_HOSTS_STRING" java -jar -Xms7g -Xmx7g -Xss228k $JMETER_DIR/bin/ApacheJMeter.jar -Jserver.rmi.ssl.disable=true -n -t $TEST_PLAN -j $WORKSPACE/loadtest.log -GTHREAD_COUNT=$THREADS_PER_HOST $OTHER_VARS $REMOTE_TESTING_FLAG -Jjmeter.save.saveservice.default_delimiter=,
在我们的案例中,测试是同时从300个Jmeter服务器进行的,每个服务器500个线程,一台带有Java参数的Jmeter服务器的启动格式如下所示:
nohup java -server -Xms1200m -Xmx1200m -Xss228k -XX:+DisableExplicitGC -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Stack=false -jar "/tmp/jmeter-JwKse5nY/bin/ApacheJMeter.jar" -Jserver.rmi.ssl.disable=true "-Djava.rmi.server.hostname=generator12.loadtest.ig.local" -Duser.dir=/tmp/jmeter-JwKse5nY/bin/ -Dserver_port=13114 -s -Jpoll=49 > /dev/null 2>&1
50毫秒
任务是确定我们的数据库可以承受的负载量,而不是使数据库以及整个系统整体过载到临界状态。 拥有如此多的Jmeter服务器,您需要以某种方式将负载保持在一定水平,而不是杀死整个系统。 开始测试时指定的
TARGET_RESPONSE_TIME参数对此负责。 我们同意
50ms是系统应负责的最佳响应时间。
在JMeter中,默认情况下,有许多不同的计时器可让您控制吞吐量,但是在我们的情况下,从何处获取它是未知的。 但是有
JSR223-Timer ,您可以使用它使用
当前的系统
响应时间提出一些建议 。 计时器本身位于主要的
Behavior块中:

结果分析(守护程序)
除了Grafana中的图形外,还必须具有汇总的测试结果,以便随后可以在JLTC中对测试进行比较。
一个这样的测试每秒生成16k-20k个请求,很容易计算出它在4小时内会生成一个大小为数百GB的CSV文件,因此有必要提出一项每分钟解析一次数据,将其发送到数据库并清理主文件的作业。
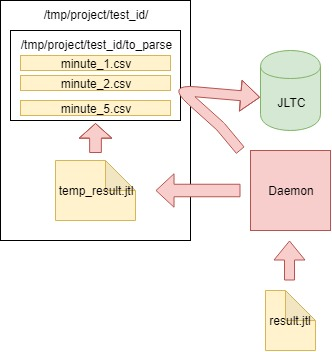
算法如下:
- 我们从jmeter-client生成的CSV文件result.jtl中读取数据,将其保存并清理文件(您需要正确清理它,否则,空文件将具有相同的FD,且大小相同):
with open(jmeter_results_file, 'r+') as f: rows = f.readlines() f.seek(0) f.truncate(0) f.writelines(rows[-1])
- 我们将读取的数据写入临时文件temp_result.jtl中 :
rows_num = len(rows) open(temp_result_filename, 'w').writelines(rows[0:rows_num])
- 我们读取了文件temp_result.jtl 。 我们以分钟为单位分发读取的数据:
for r in f.readlines(): row = r.split(',') if len(row[0]) == 13: ts_c = int(row[0]) dt_c = datetime.datetime.fromtimestamp(ts_c/1000) minutes_data.setdefault(dt_c.strftime('%Y_%m_%d_%H_%M'), []).append(r)
- minutes_data中每分钟的数据将写入to_parse /文件夹中的相应文件。 (因此,目前,测试的每一分钟都有其自己的数据文件,然后在聚合过程中,数据按什么顺序进入每个文件都无关紧要):
for key, value in minutes_data.iteritems():
- 在此过程中,我们分析了to_parse文件夹中的文件,如果它们在一分钟之内没有变化,那么该文件是数据分析,聚合并发送到JLTC数据库的候选文件:
for filename in os.listdir(temp_to_parse_path): data_file = os.path.join(temp_to_parse_path, filename) file_mod_time = os.stat(data_file).st_mtime last_time = (time.time() - file_mod_time) if last_time > 60: logger.info('[DAEMON] File {} was not modified since 1min, adding to parse list.'.format(data_file)) files_to_parse.append(data_file)
- 如果有这样的文件(一个或多个),那么我们将它们解析后发送到parse_csv_data函数(每个文件并行):
for f in files_to_parse: logger.info('[DAEMON THREAD] Parse {}.'.format(f)) t = threading.Thread( target=parse_csv_data, args=( f, jmeter_results_file_fields, test, data_resolution)) t.start() threads.append(t) for t in threads: t.join()
cron.d中的守护进程本身每分钟启动一次:
守护进程每分钟从cron.d开始:
* * * * * root sleep 21 && /usr/bin/python /var/lib/jltc/manage.py daemon
因此,具有结果的文件不会膨胀到无法想象的大小,而是会进行动态分析并清除。
结果
该应用程序
我们的150,000名虚拟玩家:

该测试试图“匹配” 50ms的响应时间,因此负载本身在16k-18k个请求/ c之间的区域中不断跳跃:
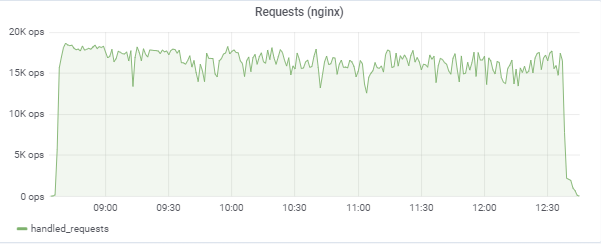
应用程序服务器负载(15个应用程序)。 速度较慢的M620上有两台服务器是“不幸的”:
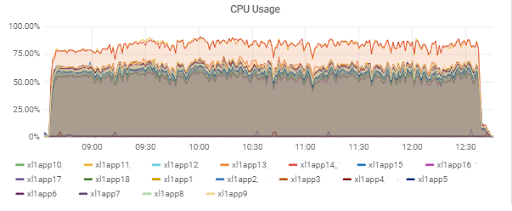
数据库响应时间(对于应用服务器):

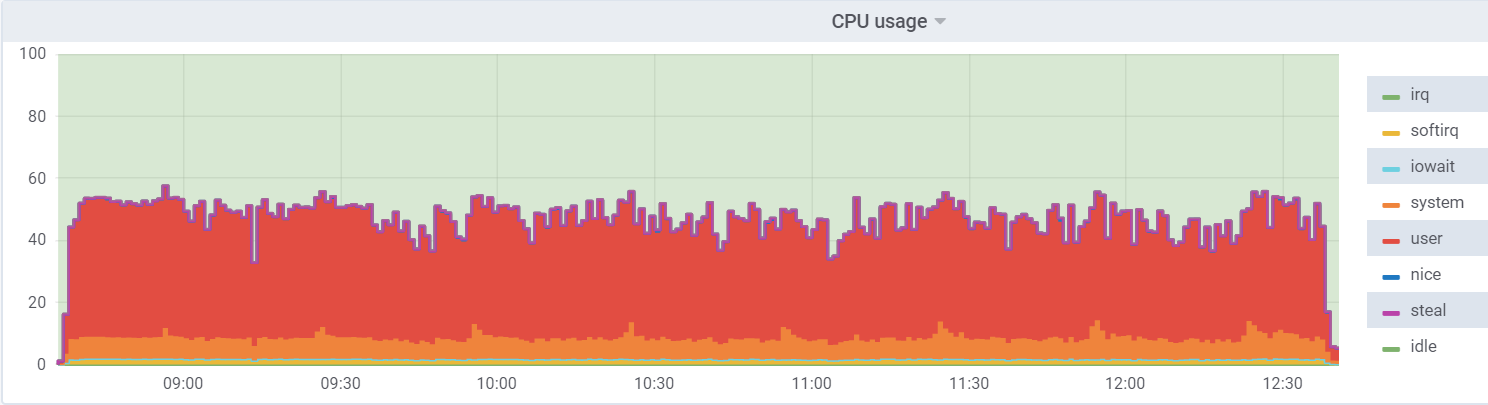
资料库
db1(VM)上的CPU util:
系统管理程序上的CPU util:
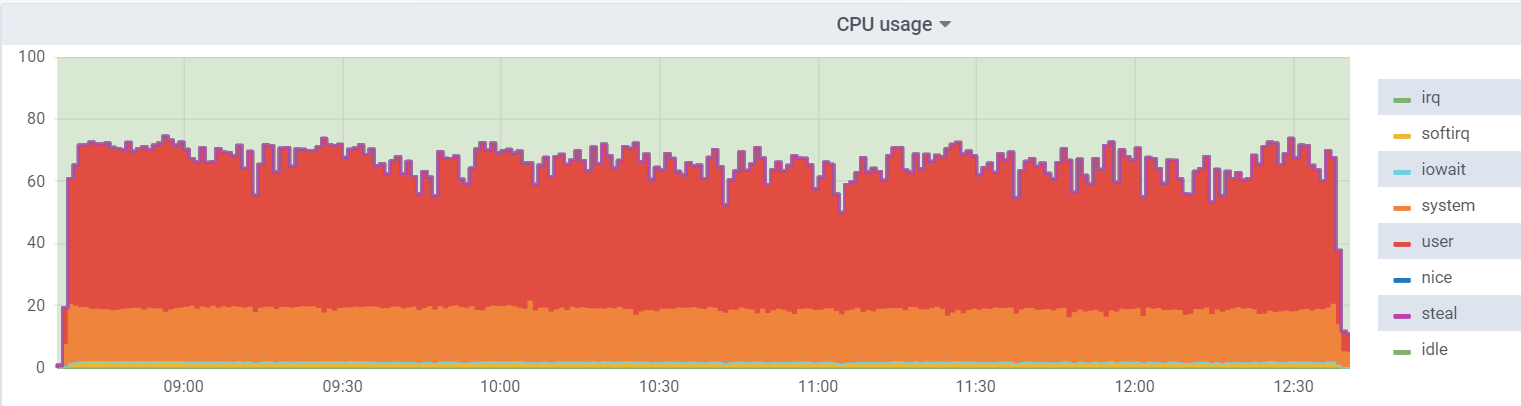
虚拟机上的负载较低,因为它认为虚拟机上有48个实际内核可供使用,实际上,虚拟机管理程序上有24个
超线程内核。
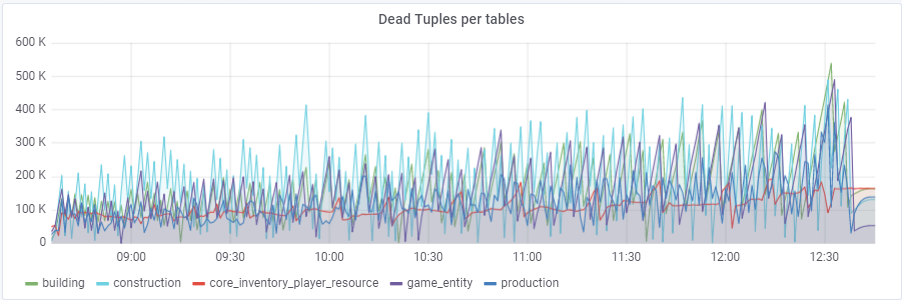
最多〜25万次查询/秒进入数据库,包括(83%选择,3%-插入,11.6%-更新(90%HOT),1.6%删除):

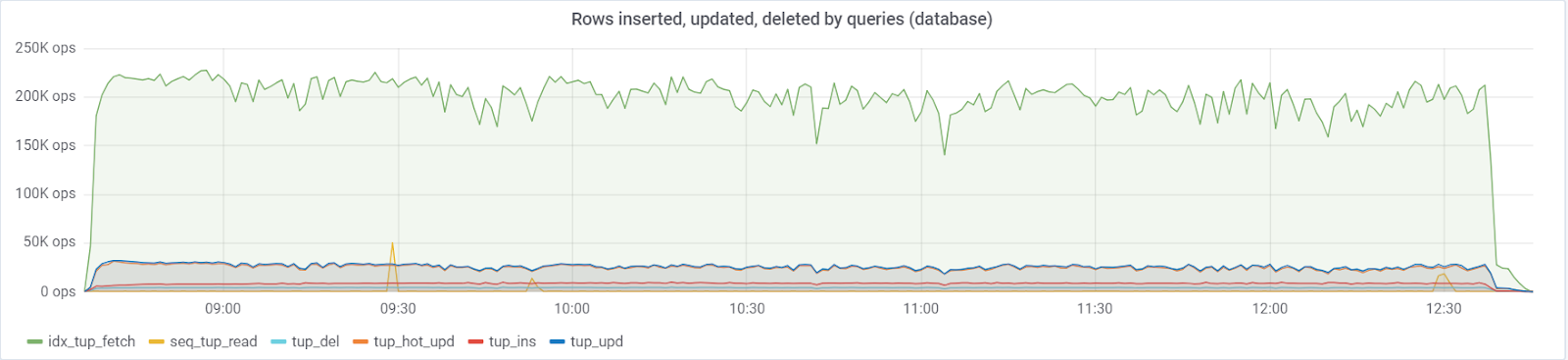
在默认值
autovacuum_vacuum_scale_factor = 0.2的情况下,随着测试的进行,死元组的数量增长非常快(表大小不断增加),这多次导致数据库性能出现问题,从而使整个测试多次崩溃。 我必须通过为此参数分配个人值autovacuum_vacuum_scale_factor来“控制”某些表的增长:
ALTER TABLE ... SET(autovacuum_vacuum_scale_factor = ...)ALTER TABLE构造集(autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE生产设置(autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET(autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET(autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE建筑物设置(autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE建筑设置(autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE core_inventory_player_resource SET(autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE Survivor SET(autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE幸存者集(autovacuum_analyze_scale_factor = 0.01);
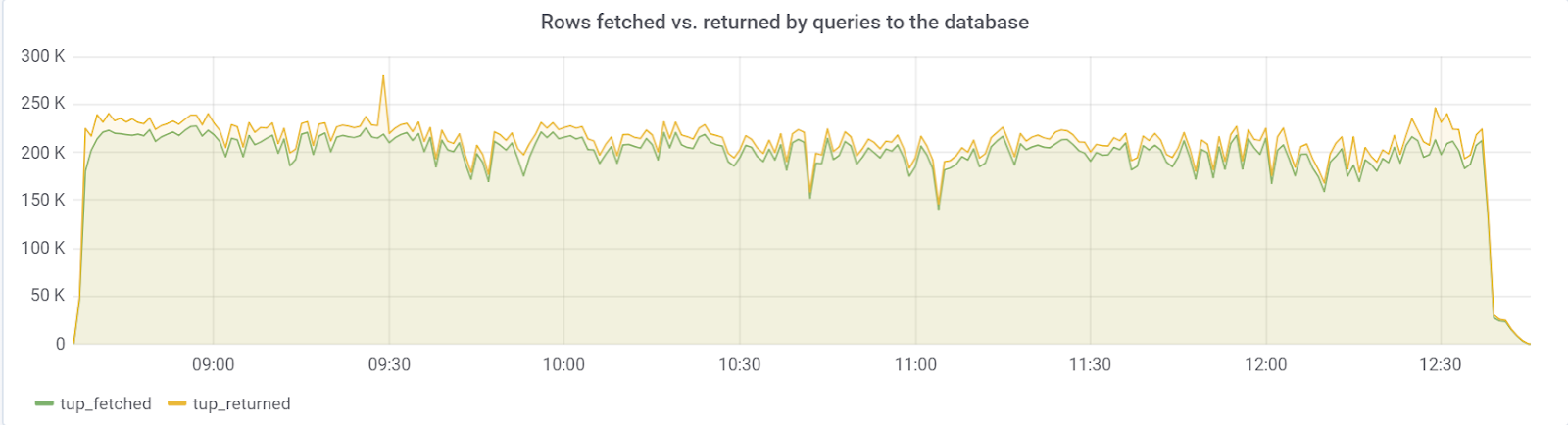
理想情况下,rows_fetched应该接近rows_returned,幸运的是,我们观察到:
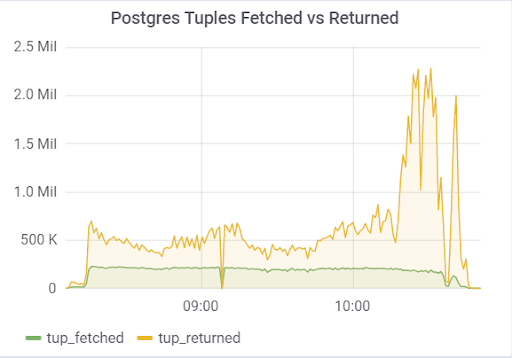
hot_standby_feedback
问题在于
hot_standby_feedback参数,如果
主服务器的
备用服务器没有时间应用来自WAL文件的更改,则该参数会极大地影响
主服务器的性能。 该文档(https://postgrespro.ru/docs/postgrespro/11/runtime-config-replication)指出,它“确定热备用服务器是将当前正在执行的请求通知主服务器还是上级从服务器。” 默认情况下它是关闭的,但是在我们的配置中它是打开的。 导致可悲的后果,如果有2个备用服务器,并且加载期间的复制滞后不同于零(出于各种原因),则可以观察到这样的情况,这可能导致整个测试崩溃:

这是由于以下事实:启用hot_standby_feedback时,VACUUM不想删除备用服务器的事务ID中的无效元组,以防止复制冲突。 详细的文章
PostgreSQL中的hot_standby_feedback实际上是做什么的 :
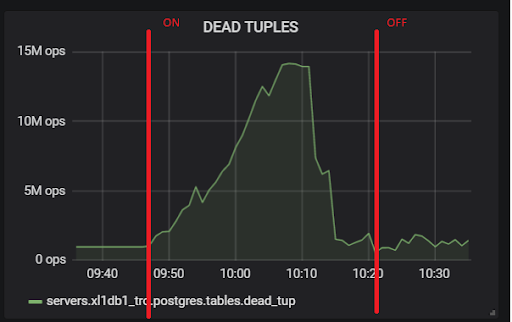
xl1_game=# VACUUM VERBOSE core_inventory_player_resource; INFO: vacuuming "public.core_inventory_player_resource" INFO: scanned index "core_inventory_player_resource_pkey" to remove 62869 row versions DETAIL: CPU: user: 1.37 s, system: 0.58 s, elapsed: 4.20 s ………... INFO: "core_inventory_player_resource": found 13682 removable, 7257082 nonremovable row versions in 71842 out of 650753 pages <b>DETAIL: 3427824 dead row versions cannot be removed yet, oldest xmin: 3810193429</b> There were 1920498 unused item pointers. Skipped 8 pages due to buffer pins, 520953 frozen pages. 0 pages are entirely empty. CPU: user: 4.55 s, system: 1.46 s, elapsed: 11.74 s.
如此大量的死元组导致了上面的图片。 这是两个测试,分别打开和关闭hot_standby_feedback:
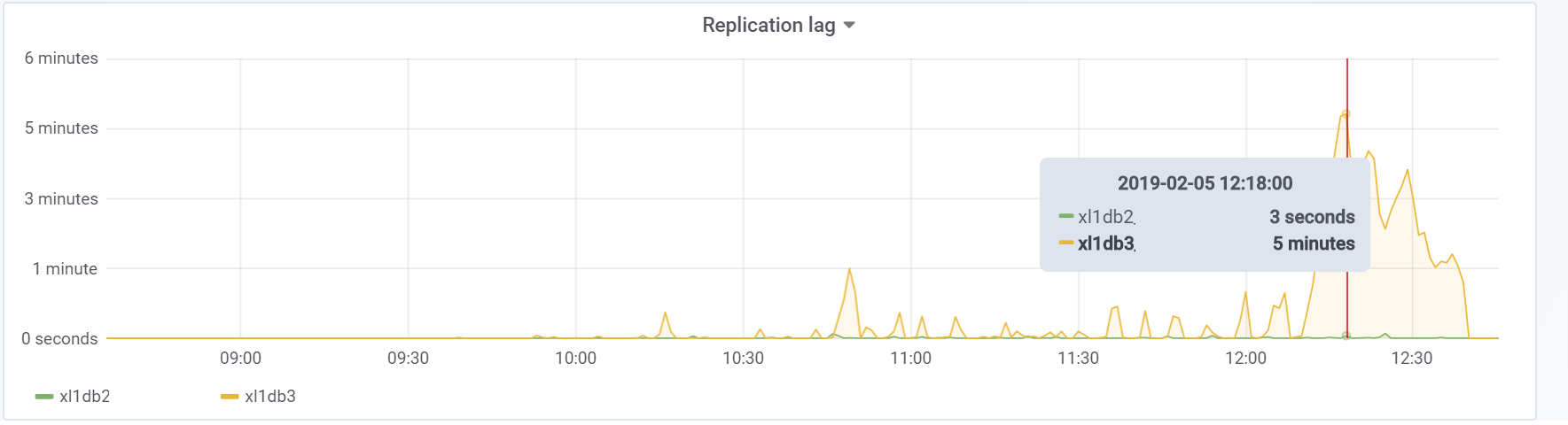
这是我们在测试过程中的复制滞后,将来有必要做一些事情:
结论
幸运的是,此测试(或不幸的是,对于本文的内容而言)表明,在游戏原型的现阶段,很有可能吸收用户方面的期望负载,这足以为进一步的原型开发提供开绿灯。 在后续的开发阶段,有必要遵循基本规则(以保持所执行查询的简单性,防止索引过多以及未索引的读数等),最重要的是,在开发的每个重要阶段都要对项目进行测试,以发现并解决问题。可以早些。 也许很快,我将写一篇文章,因为我们已经解决了特定的问题。
祝大家好运!
我们的
GitHub以防万一;)