
Prometheus 2中的时间序列数据库(TSDB)是工程解决方案的一个很好的例子,它在数据存储和查询执行的速度以及资源效率方面对Prometheus 1中的v2存储进行了重大改进。 我们在Percona监视和管理(PMM)中实施了Prometheus 2,我有机会了解了Prometheus 2 TSDB的性能。 在本文中,我将讨论这些观察结果。
普罗米修斯的平均工作量
对于那些习惯于处理主数据库的人,Prometheus的常规工作量非常好奇。 数据积累的速度趋于达到一个稳定的值:通常,您监视的服务发送大约相同数量的指标,并且基础结构的变化相对较慢。
信息请求可能来自不同的来源。 其中一些警报(例如警报)也努力争取稳定和可预测的价值。 其他问题(例如用户查询)可能会导致峰值,尽管这在大多数负载中并不常见。
负载测试
在测试期间,我专注于累积数据的能力。 我使用以下脚本在Linode服务上部署了用Go 1.10.1(作为PMM 1.14的一部分)编译的Prometheus 2.3.2。 为了最实际地生成负载
,我使用此
StackScript启动了几个具有实际负载的MySQL节点(Sysbench TPC-C测试),每个节点都模拟了10个Linux / MySQL节点。
以下所有测试均在具有八个虚拟核心和32 GB内存的Linode服务器上执行,在该服务器上启动了监视200个MySQL实例的20个负载模拟。 或者,以普罗米修斯的术语来说,有800个目标,每秒440次刮擦,每秒38万个样本和170万个活动时间序列。
设计方案
包括Prometheus 1.x在内的传统数据库的常用方法是
内存限制 。 如果不足以承受负载,您将遇到很大的延迟,并且某些请求将无法满足。
使用
storage.tsdb.min-block-duration键配置Prometheus 2中的内存使用情况,该键确定在刷新到磁盘之前记录将在内存中存储多长时间(默认为2小时)。 所需的内存量将取决于时间序列,标签的数量以及净输入流中数据收集(抓取)的强度。 在磁盘空间方面,Prometheus的目标是每条记录(样本)使用3个字节。 另一方面,内存要求更高。
尽管可以配置块大小,但不建议手动对其进行配置,因此您将面临为Prometheus提供所需存储量的需求。
如果没有足够的内存来支持传入的度量标准流,则Prometheus将从内存不足中跌落,或者OOM杀手将到达内存。
当Prometheus内存不足时,添加交换以延迟崩溃并没有真正的帮助,因为使用此功能会导致爆炸性的内存消耗。 我认为事情就是Go,它的垃圾收集器以及它如何与swap一起工作。
另一种有趣的方法是将磁头块设置为在特定时间重置为磁盘,而不是从过程开始就对其进行计数。
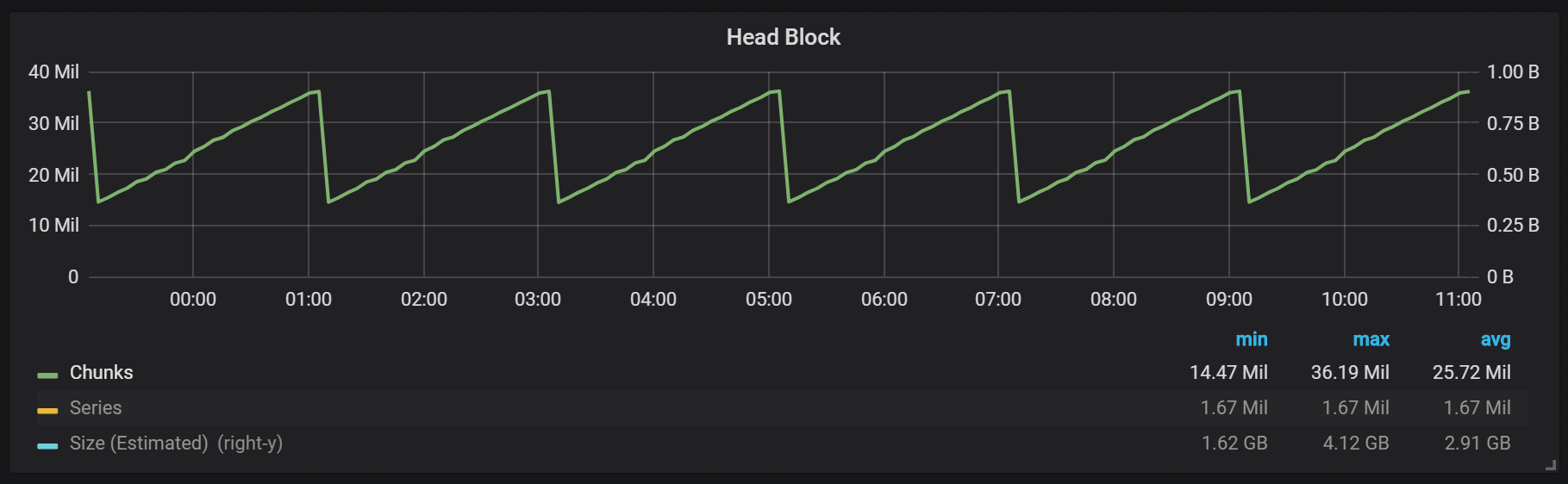
从图中可以看到,磁盘刷新每两小时发生一次。 如果将min-block-duration参数更改为一小时,则这些放电将在每小时开始的半小时内发生。
如果要在Prometheus安装中使用此图形和其他图形,则可以使用此仪表板 。 它是专为PMM开发的,但稍作修改后即可适用于Prometheus的任何安装。我们有一个称为头块的活动块,该块存储在内存中。 具有较旧数据的块可通过
mmap()访问。 这样就无需分别配置高速缓存,也意味着如果要请求比head块更早的数据,则需要为操作系统高速缓存保留足够的空间。
这也意味着Prometheus虚拟内存的使用量看起来会很高,这不值得担心。

另一个有趣的设计点是使用WAL(预写日志)。 从存储文档中可以看到,Prometheus使用WAL以避免由于跌落而造成的损失。 不幸的是,确保数据可生存性的特定机制没有得到很好的记录。 Prometheus版本2.3.2每10秒将WAL刷新到磁盘上,并且该参数不是用户可配置的。
密封件
Prometheus TSDB是在LSM存储库(日志结构合并-具有合并的日志结构树)的映像中设计的:头块定期刷新到磁盘,而压缩机制将几个块组合在一起,以防止在请求期间扫描太多的块。 在这里,您可以看到一天工作后在测试系统上观察到的块数。
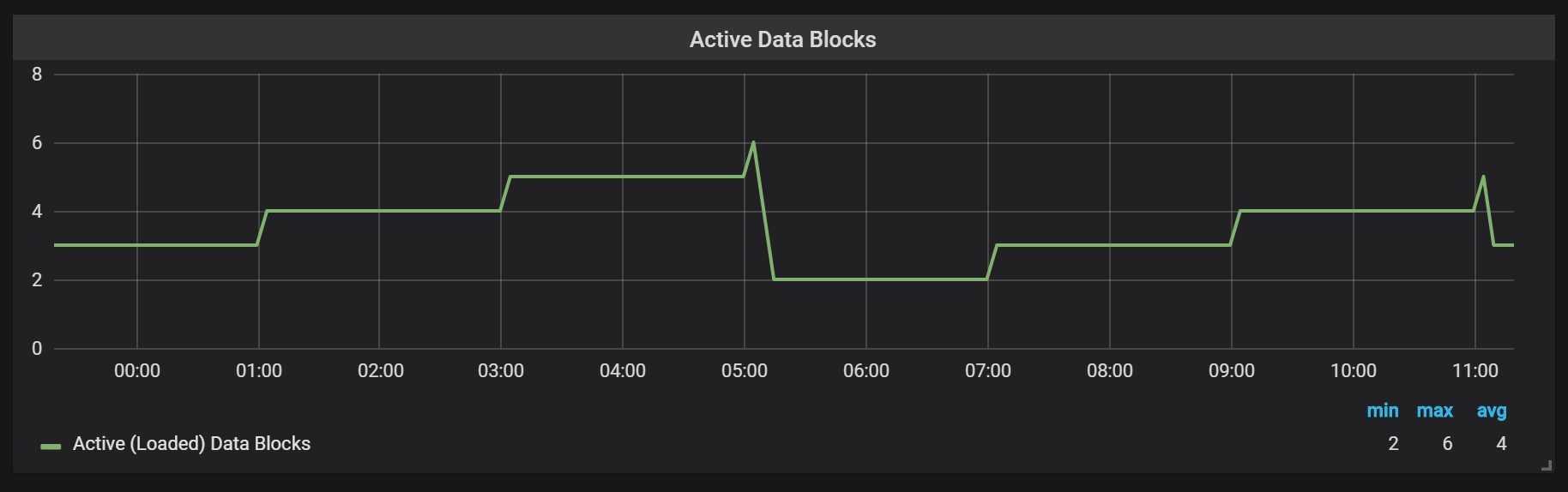
如果您想进一步了解存储库,可以研究meta.json文件,该文件包含有关可用块及其显示方式的信息。
{ "ulid": "01CPZDPD1D9R019JS87TPV5MPE", "minTime": 1536472800000, "maxTime": 1536494400000, "stats": { "numSamples": 8292128378, "numSeries": 1673622, "numChunks": 69528220 }, "compaction": { "level": 2, "sources": [ "01CPYRY9MS465Y5ETM3SXFBV7X", "01CPYZT0WRJ1JB1P0DP80VY5KJ", "01CPZ6NR4Q3PDP3E57HEH760XS" ], "parents": [ { "ulid": "01CPYRY9MS465Y5ETM3SXFBV7X", "minTime": 1536472800000, "maxTime": 1536480000000 }, { "ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ", "minTime": 1536480000000, "maxTime": 1536487200000 }, { "ulid": "01CPZ6NR4Q3PDP3E57HEH760XS", "minTime": 1536487200000, "maxTime": 1536494400000 } ] }, "version": 1 }
Prometheus中的密封圈与将磁头冲洗到磁盘的时间有关。 此时,可以执行几个这样的操作。
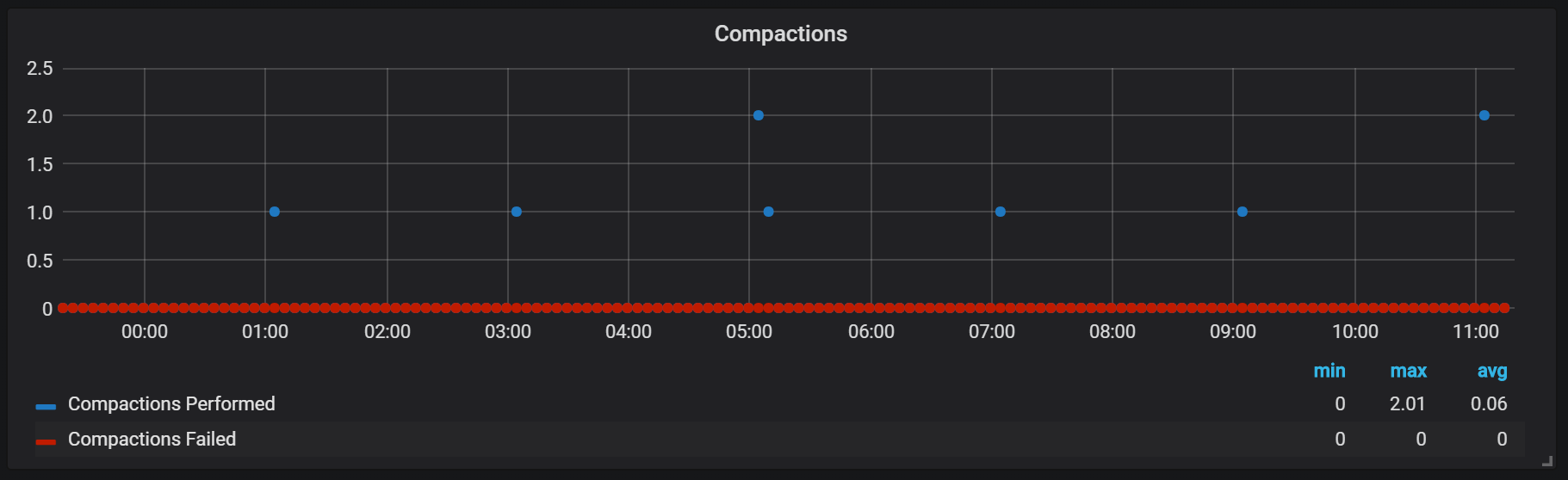
显然,密封在任何方面都是不受限制的,并且可能在运行时导致大的磁盘I / O跳转。

CPU下载高峰

当然,这对系统的速度有相当负面的影响,对于LSM存储来说也是一个严峻的挑战:如何制作密封以支持高查询速度而又不会造成过多开销?
在压缩过程中使用内存看起来也很有趣。

我们可以看到压缩之后,大多数内存如何从“已缓存”状态变为“空闲”状态:这意味着从那里删除了潜在有价值的信息。 奇怪的是,是否在这里使用
fadvice()或其他最小化技术,还是由缓存中的数据从压缩期间破坏的块中释放出来引起的?
崩溃恢复
灾难恢复需要时间,这是合理的。 对于每秒一百万条记录的传入流,在考虑到SSD驱动器的情况下执行恢复时,我不得不等待大约25分钟。
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)" level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)" level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))" level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)" level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090 level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..." level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0 level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363 level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started" level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."
恢复过程的主要问题是高内存消耗。 尽管在正常情况下服务器可以在相同的内存量下稳定运行,但当服务器崩溃时,由于OOM可能不会使服务器上升。 我发现的唯一解决方案是禁用数据收集,提升服务器,允许其恢复并在已启用收集的情况下重新启动。
热身
在预热期间应记住的另一行为是刚启动后生产率低下和资源消耗高的比率。 在某些(但不是全部)启动过程中,我观察到CPU和内存上的负担很重。
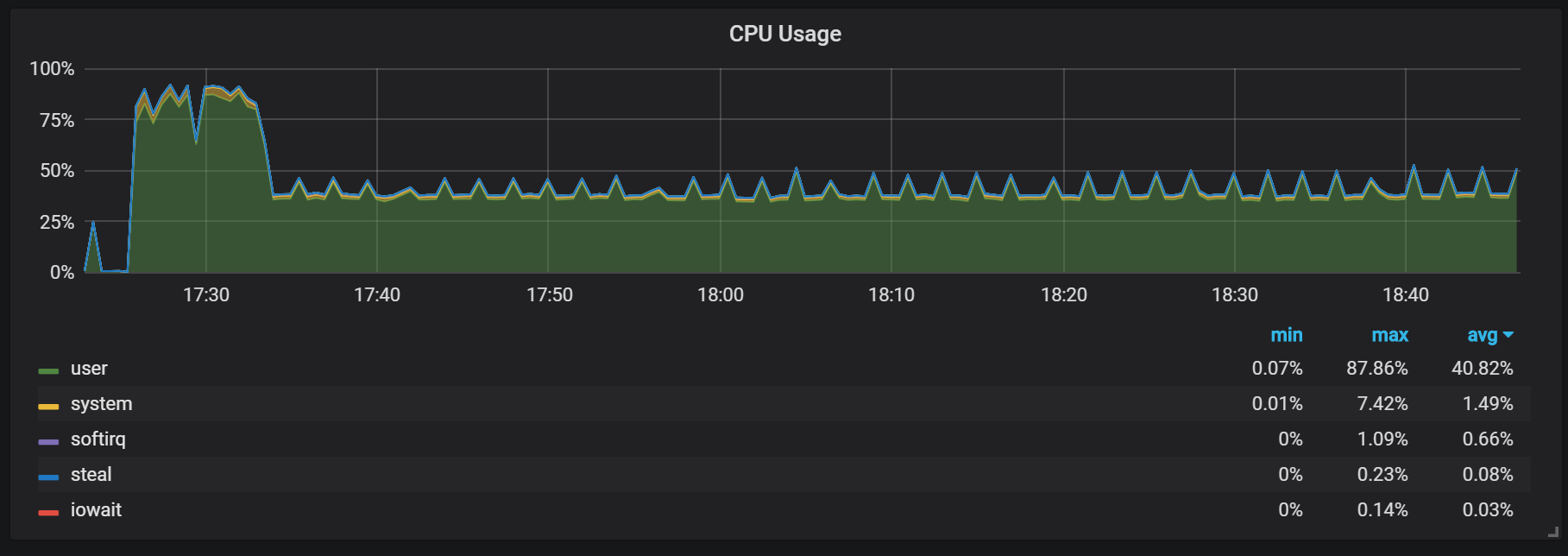

内存不足表明Prometheus从一开始就无法配置所有费用,并且某些信息会丢失。
我没有找到造成处理器和内存高负载的确切原因。 我怀疑这是由于在高频头中创建了新的时间序列。
CPU负载峰值
除了会产生较高I / O负载的密封之外,我还注意到每两分钟处理器上的负载会急剧增加。 突发持续时间较长,且传入流很高,这看起来像是Go垃圾回收器引起的,至少某些内核已完全加载。

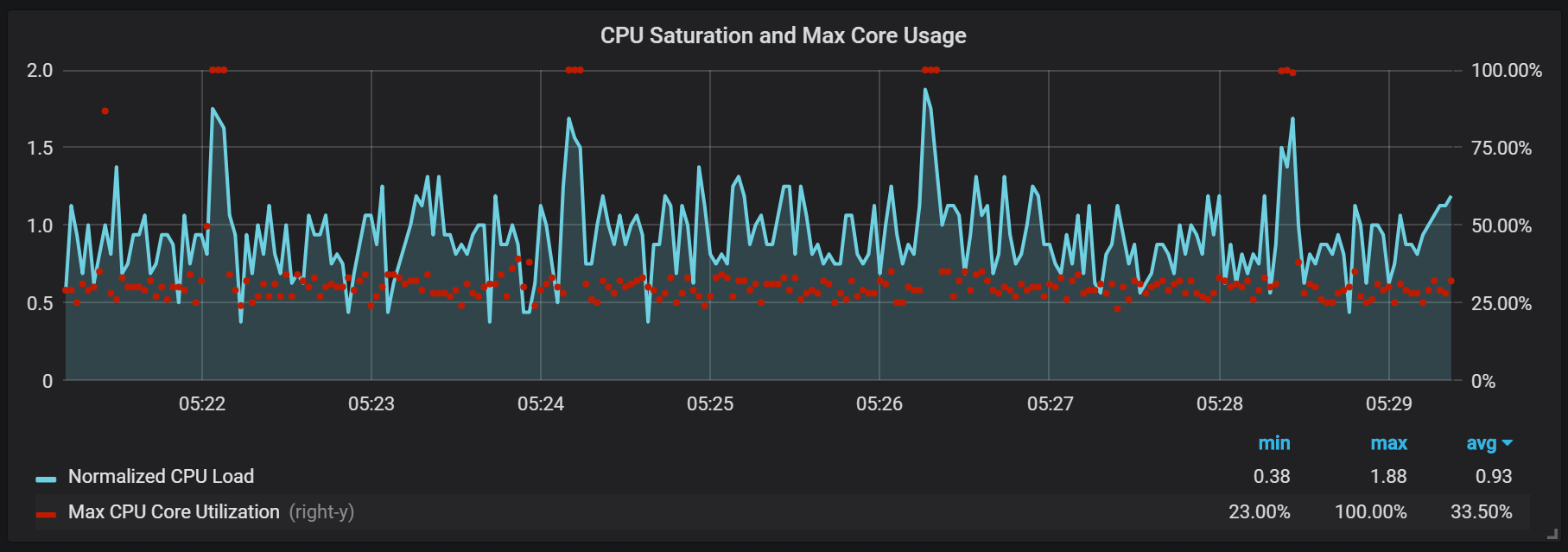
这些飞跃并不是那么微不足道。 看起来,当它们发生时,内部入口点和Prometheus度量标准将变得不可访问,从而在相同的时间间隔内导致数据缺口。
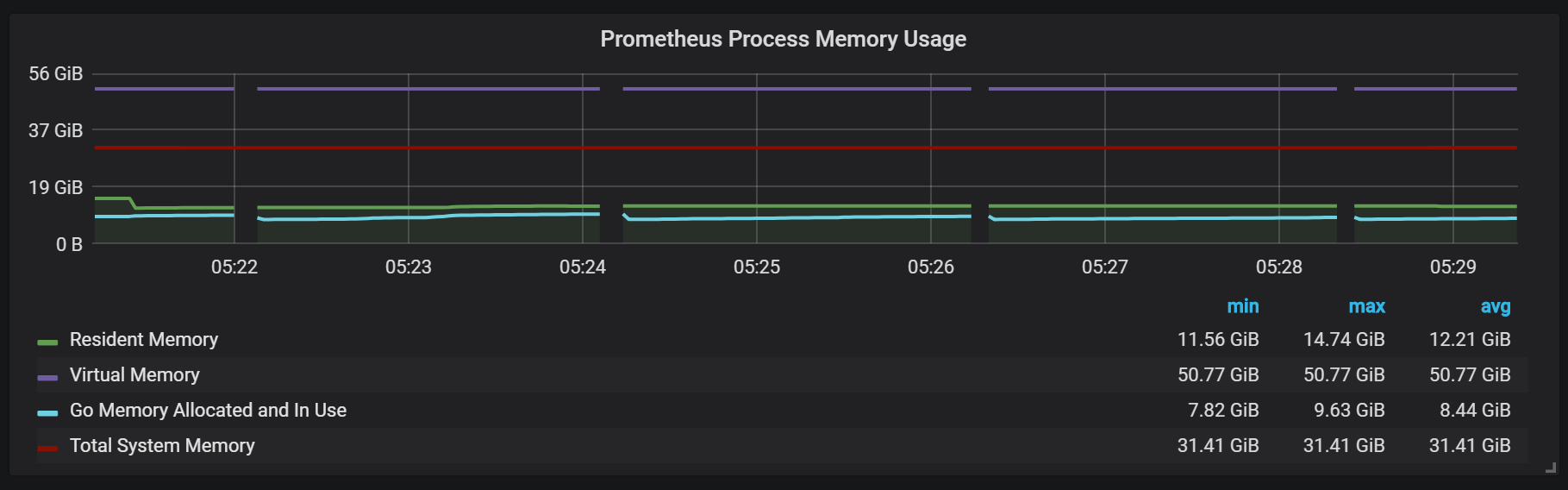
您还可以注意到Prometheus导出器关闭了一秒钟。
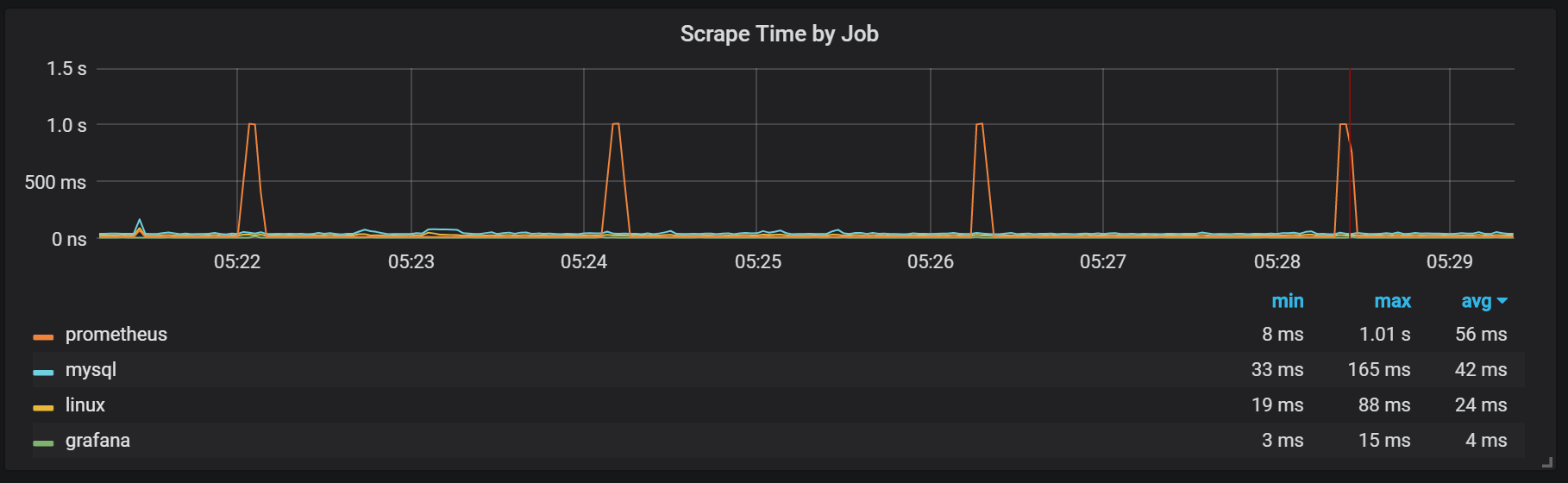
我们可以看到与垃圾回收(GC)的相关性。

结论
Prometheus 2中的TSDB速度很快,能够使用相当适度的硬件处理数百万个时间序列,同时每秒处理数千个记录。 CPU和磁盘I / O的利用率也令人印象深刻。 我的示例显示了每个使用的内核每秒高达200,000个指标。
要计划扩展,您需要记住足够的内存量,这应该是实际内存。 我观察到的已使用内存量约为传入流的每秒每100,000个条目5 GB,再加上操作系统缓存约8 GB的占用内存。
当然,仍然需要大量工作来控制CPU和磁盘I / O的爆发,鉴于TSDB Prometheus 2与InnoDB,TokuDB,RocksDB,WiredTiger相比还很年轻,这不足为奇,但是它们在生命周期开始时都有类似的问题。