
机器的逻辑是无可挑剔的,如果算法正确运行且设置的参数符合必要的标准,则它们不会出错。 要求汽车选择从A点到B点的路线,这将考虑距离,燃油消耗,加油站的存在等因素,为您提供最佳的路线。 这是一个纯粹的计算。 汽车不会说:“让我们沿着这条路走,我觉得这条路更好。” 汽车的计算速度也许比我们好,但是直觉仍然是我们的王牌之一。 人类花了数十年的时间来制造类似于人类大脑的机器。 但是它们之间有太多共同点吗? 今天,我们将考虑一项研究,其中科学家对基于卷积神经网络的无与伦比的机器“视觉”表示怀疑,进行了一项实验,该实验使用一种算法来欺骗对象识别系统,该算法的任务是创建“伪造”图像。 该算法的破坏活动取得了多大的成功,人们比汽车更能应付识别问题,这项研究将为这项技术带来什么? 我们将在科学家的报告中找到答案。 走吧
学习基础
粗略地说,使用卷积神经网络(SNS)的对象识别技术使机器能够区分9号天鹅和一只猫猫。 该技术发展非常迅速,目前正在各个领域中应用,其中最明显的是无人驾驶汽车的生产。 许多人认为,物体识别系统的SNA可以视为人类视觉的模型。 但是,由于人为因素,此声明太大声。 问题是,愚弄汽车比愚弄人要容易(至少在对象识别方面)。 SNA系统非常容易受到恶意算法(如果需要的话,则是敌对的)的影响,这将以各种方式阻止其正确执行其任务,从而创建将被SNA系统错误分类的映像。
研究人员将这种图像分为两类:“愚弄”(完全改变目标)和“尴尬”(部分改变目标)。 第一个是无意义的图像,被系统识别为熟悉的图像。 例如,一组线可以被分类为“棒球”,而彩色数字噪声可以被分类为“ armadillo”。 第二类图像(“尴尬”)是在正常情况下可以正确分类的图像,但是恶意算法在SNA系统的眼中使它们稍微失真,夸大地说。 例如,由于几个像素的少量补充,手写数字6将被分类为数字5。
试想一下这种算法会带来什么危害。 值得将道路标志的分类用于自动运输,而事故将不可避免。
以下是欺骗SNA系统,经过训练可以识别对象的“伪造”图像,以及类似系统如何对它们进行分类。
 图片编号1
图片编号1系列说明:
- -间接编码的“欺诈性”图像;
- b-直接编码的“欺诈性”图像;
- c- “令人尴尬”的图像,迫使系统将一个数字归为另一个数字;
- d-即使“噪声”仅位于一个点(在右下角),LaVAN攻击(局部和可见的对抗性/恶意噪声)也可能导致错误的分类。
- e-从不同角度错误分类的三维对象。
对此最奇怪的是,一个人可能不会屈服于一种恶意的算法,并且无法根据直觉对图像进行正确的分类。 像科学家所说,以前,没有人在实验中比较机器和人的能力,以对抗伪造图像的恶意算法。 这就是研究人员决定要做的。
为此,准备了一些由恶意算法制作的图像。 受试者被告知机器将这些(正面)图像分类为熟悉的物体,即 机器无法正确识别它们。 受试者的任务是确切确定机器如何对这些图像进行分类,即 他们认为机器在图像中看到的是这种分类是否正确,等等。
总共进行了8个实验,其中使用了5种类型的恶意图像,这些图像是在不考虑人类视觉的情况下创建的。 换句话说,它们是由机器为机器创建的。 这些实验的结果非常有趣,但是我们不会破坏它们并按顺序考虑所有问题。
实验结果
实验#1:欺骗带有无效标签的图像
在第一个实验中,使用了48张被欺骗的图像,该图像是由该算法创建的,用以对抗基于称为AlexNet的SNA的识别系统。 该系统将这些图像分类为“齿轮”和“甜甜圈”(
2a )。
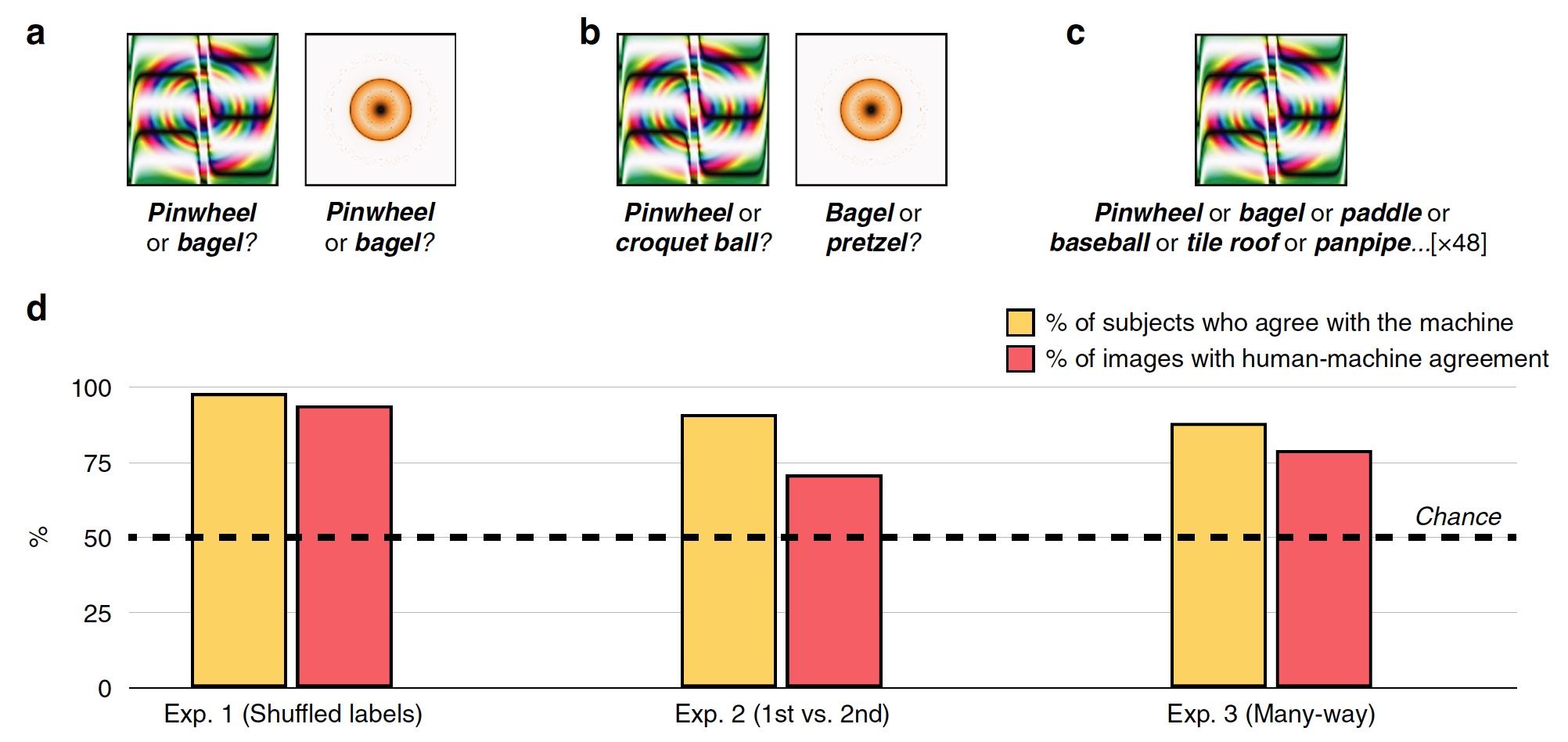 图片编号2
图片编号2在每次尝试期间,测试人员(其中有200名)看到一个假冒图像和两个标记,即 分类标签:系统SNS标签和其他47张图片中的随机标签。 受试者必须选择由机器创建的标签。
结果,大多数受试者选择选择由机器创建的标签,而不是恶意算法的标签。 分类准确度,即 受试者对机器的同意程度为74%。 从统计上讲,98%的受试者选择机器标签的程度高于统计随机性(
2d ,“受试者的百分比与机器相符”)。 94%的图像显示出很高的人机对齐率,也就是说,在48张图像中,只有3张图像被人分类的方式与机器不同。
因此,受试者表明一个人能够共享真实的图像和傻瓜,即根据基于SNA的程序进行操作。
实验2:第一选择与第二选择
研究人员提出了这个问题-由于什么对象能够很好地识别图像并将其与错误的标记和复制的图像区分开? 受试者可能将橙黄色的戒指称为“甜甜圈”,因为实际上,甜甜圈的形状和颜色大致相同。 认识到,基于经验和知识的联想和直观选择可以帮助一个人。
为了验证这一点,将随机标签替换为机器选择的第二种可能的分类选项。 例如,AlexNet将橘黄色的戒指归类为“甜甜圈”,该程序的第二个选项是“椒盐脆饼”。
受试者面临的任务是选择机器的第一个标记或在所有48张图像(
2s )中占据第二名的位置。
图像
2d中心的图形显示了该测试的结果:91%的受试者选择了第一版标签,人机匹配水平为71%。
实验3:多线程分类
鉴于受试者可以在两个可能的答案(机器标签和随机标签)之间做出选择,上述实验非常简单。 实际上,在图像识别过程中,机器会反复选择成百上千的标签选项,然后再选择最合适的标签。
在该测试中,48张图像的所有标记均位于被摄对象的正前方。 他们必须从该组中选择最适合每个图像的图像。
结果,88%的受试者选择了与机器完全相同的标签,协调度为79%。 一个有趣的事实是,即使选择了机器选择的错误标签,在这种情况下,仍有63%的受检者选择了前5个标签之一。 也就是说,汽车上的所有标记都按照从最合适到最不合适的列表排序(夸张的示例:“百吉饼”,“椒盐脆饼”,“橡胶圈”,“轮胎”等,直到“夜空鹰” )
实验3b:“这是什么?”
在这项测试中,科学家对规则做了些微改动。 并没有要求他们“猜测”机器将为特定图像选择的标签,而是只是询问被摄对象在他们面前看到的内容。
基于卷积神经网络的识别系统为特定图像选择适当的标签。 这是一个相当清晰和合乎逻辑的过程。 在该测试中,受试者表现出直觉思维。
结果,90%的受试者选择了标签,机器也选择了标签。 图像之间的人机对齐率为81%。
实验4:电视静噪
科学家注意到,在以前的实验中,图像是不寻常的,但它们具有可区分的特征,可能会促使受试者做出正确(或错误)的标签选择。 例如,图像“棒球”不是球,但是真实的棒球球上存在线条和颜色。 这是一个惊人的区别特征。 但是,如果图像没有这种特征,而本质上是静态噪点,那么人们至少可以识别出图像上的某些东西吗? 那就是决定检查的内容。
 图片编号3a
图片编号3a在此测试中,有8张图像在被摄体前面带有静电,SNS系统将其识别为特定对象(例如,鸟-zaryanka)。 此外,在被摄对象的前面有一个标签和与其相关的普通图像(8张静态照片,1张标签“ zaryanka”和5张该鸟的照片)。 测试对象必须从8个最适合一个或另一个标签的静态图像中选择1个。
您可以测试自己。 在上方,您可以看到这种测试的示例。 这三个图像中的哪个图像最适合标签“ zaryanka”,为什么?
81%的受试者选择了机器选择的标签。 同时,在机器看来,有75%的图像由对象标记了最合适的标签(如前所述,从许多选项中选择)。
对于这个特定的测试,您可能会像我一样遇到问题。 事实是,在上面建议的静力学中,我个人看到了三个明显的特征,将它们彼此区分开。 而且仅在一个图像中,此功能与相同的zaryanka非常相似(我认为您了解这三个图像中的哪个)。 因此,我个人和非常主观的看法是,这种测试不是特别指示性的。 尽管静态图像的其他选项可能实际上是无法区分和不可识别的。
实验5:“可疑”数字
上述测试基于无法立即完整且毫无疑问地归类为一个或另一个对象的图像。 总是充满怀疑。 愚弄的图像在工作中非常简单-破坏图像以至于无法识别。 但是,还有第二种恶意算法,它们仅添加(或删除)图像中的一小部分细节,这可能完全违反SNA系统的识别系统。 加几个像素,数字6神奇地变成数字5(
1s )。
科学家认为这种算法是最危险的算法之一。 您可以稍微更改图像标签,而无人驾驶车辆会错误地考虑限速标志(例如,由75代替45),这可能会导致严重的后果。
 图片#3b
图片#3b在这项测试中,科学家建议受试者选择错误的答案,而选择错误的答案。 在测试中,使用了100张由恶意算法更改的数字图像(LeNet SNA更改了它们的分类,即,恶意算法成功运行)。 受试者不得不说他们认为机器看到了什么数字。 正如预期的那样,89%的受试者成功完成了该测试。
实验6:照片和局部“失真”
科学家注意到,不仅正在开发对象识别系统,而且还在开发阻止它们执行此操作的恶意算法。 以前,要对图像进行错误分类,必须使目标图像中所有像素的14%失真(更改,删除,损坏等)。 现在这个数字变得小得多了。 在目标内部添加一个小的图像就足够了,并且会违反分类。
 图片编号4
图片编号4在此测试中,使用了一种相当新的恶意LaVAN算法,该算法将一幅定位在目标照片上的小图像放置在目标照片上。 结果,对象识别系统可以将地铁列车识别为一罐牛奶(
4a )。 该算法最重要的功能就是目标图像中受损像素的比例很小(仅为2%),并且无需将其整体或主要(最重要的)部分扭曲。
在测试中,使用了由LaVAN损坏的22张图像(此算法成功破解了SNA识别系统Inception V3)。 受试者应该对照片中的恶意插入物进行分类。 87%的受试者能够成功做到这一点。
实验7:三维物体
我们之前看到的图像是二维的,就像任何照片,图片或报纸剪报一样。 大多数恶意算法都会成功处理此类图像。 但是,这些害虫只能在某些条件下起作用,也就是说,它们具有许多局限性:
- 复杂度:只有二维图像;
- 实际应用:只有在读取接收到的数字图像的系统上才可能进行恶意更改,而不能读取来自传感器和传感器的图像;
- 稳定性:如果旋转二维图像(调整大小,裁剪,锐化等),恶意攻击就会失去力量;
- 人:我们以不同的角度,光线,而不是以从一个角度拍摄的二维数字图像的形式,以3D视角看待世界和周围的物体。
但是,正如我们所知,进步并没有幸免恶意算法。 其中出现了一个不仅能够扭曲二维图像而且能够扭曲三维图像的人,这导致了对象识别系统的错误分类。 当使用用于三维图形的软件时,这种算法会从不同的距离和视角误导基于SNA(在这种情况下为Inception V3程序)的分类器。 最令人吃惊的是,这种愚蠢的3D图像可以打印在适当的打印机上,即 创建一个真实的物理对象,对象识别系统仍然会错误地对其进行分类(例如,将橙色作为电钻)。 这全都归功于目标图像(
4b )上纹理的微小变化。
对于物体识别系统,这种恶意算法是一个严重的对手。 但是人不是机器;他的见解和思维方式不同。 在该测试中,在被摄体之前存在三维物体的图像,其中从三个角度存在上述纹理变化。 受试者也被给予正确和错误的标记。 他们必须确定哪些标签正确,哪些标签不正确以及原因,即 测试对象是否看到图像中的纹理变化。
结果,83%的受试者成功完成了任务。
为了更详尽地了解这项研究的细微差别,我强烈建议您研究一下
科学家的
报告 。
在
此链接中,您将找到研究中使用的图像,数据和代码文件。
结语
进行的工作使科学家有机会得出一个简单而相当明显的结论-人类的直觉可以成为非常重要的数据的来源,并且是做出正确的决定和/或感知信息的工具。 一个人能够直观地理解对象识别系统的行为,它将选择什么标签以及原因。
一个人更容易看到真实图像并正确识别它的原因。 最明显的是获取信息的方法:机器接收数字形式的图像,然后一个人用自己的眼睛看到它。 对于机器,图片是一个数据集,对其进行更改,就可以扭曲其分类。 对我们而言,地铁列车的图像将始终是地铁列车,而不是一罐牛奶,因为我们看到了它。
科学家们还强调,这样的测试很难评估,因为一个人不是机器,而机器也不是人。 例如,研究人员正在谈论“甜甜圈”和“车轮”的测试。 这些图像类似于“甜甜圈”和“车轮”,因为识别系统以这种方式对其进行分类。 一个人看到他们看起来像一个“甜甜圈”和“轮子”,但事实并非如此。 这是人与程序之间在视觉信息感知上的根本区别。
谢谢大家的关注,保持好奇心,祝您工作愉快。
感谢您与我们在一起。 你喜欢我们的文章吗? 想看更多有趣的资料吗? 通过下订单或将其推荐给您的朋友来支持我们,为我们为您开发
的入门级服务器的独特模拟,为Habr用户提供
30%的折扣: 关于VPS(KVM)E5-2650 v4(6核)的全部真相10GB DDR4 240GB SSD 1Gbps从$ 20还是如何划分服务器? (RAID1和RAID10提供选件,最多24个内核和最大40GB DDR4)。
VPS(KVM)E5-2650 v4(6核)10GB DDR4 240GB SSD 1Gbps直到夏天免费,在六个月内付款,您可以
在此处订购。
戴尔R730xd便宜2倍? 仅
在荷兰和美国,我们有
2台Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100电视(249美元起) ! 阅读有关
如何构建基础架构大厦的信息。 使用价格为9000欧元的Dell R730xd E5-2650 v4服务器的上等课程?