哈Ha!
在2017年的黑色星期五期间,负载几乎增加了一半半,并且我们的服务器处于极限状态。 在过去的一年中,客户数量显着增长,并且很明显,如果没有充分的初步准备,该平台可能根本无法承受2018年的负载。
该目标设定为所有目标中最雄心勃勃的:我们希望为任何活动(甚至是最强大的活动)做好充分准备,并在这一年开始提前撤出新能力。
我们的首席技术官Andrei Chizh(
chizh_andrey )讲述了我们如何为2018年黑色星期五做准备,为避免摔倒采取了哪些措施,当然还有经过如此精心准备的结果。

今天我想谈谈黑色星期五2018的准备工作。为什么现在大多数主要销售都落后了? 我们在大型活动开始大约一年之前就开始准备,通过反复试验,我们找到了最佳解决方案。 我们建议您提前照顾炎热的季节,并防止在最不合时宜的时刻出现fakaps。
该材料将对希望从此类股票中获取最大利润的每个人有用,例如 问题的技术方面并不逊于营销方面。
大量销售的流量特征
与普遍的看法相反,黑色星期五不是一年中的一天,而是几乎整个一周:首个折扣优惠在销售前7-8天到达。 网站访问量整周开始平稳增长,在周五达到峰值,在周六急剧下降到常规商店指标。
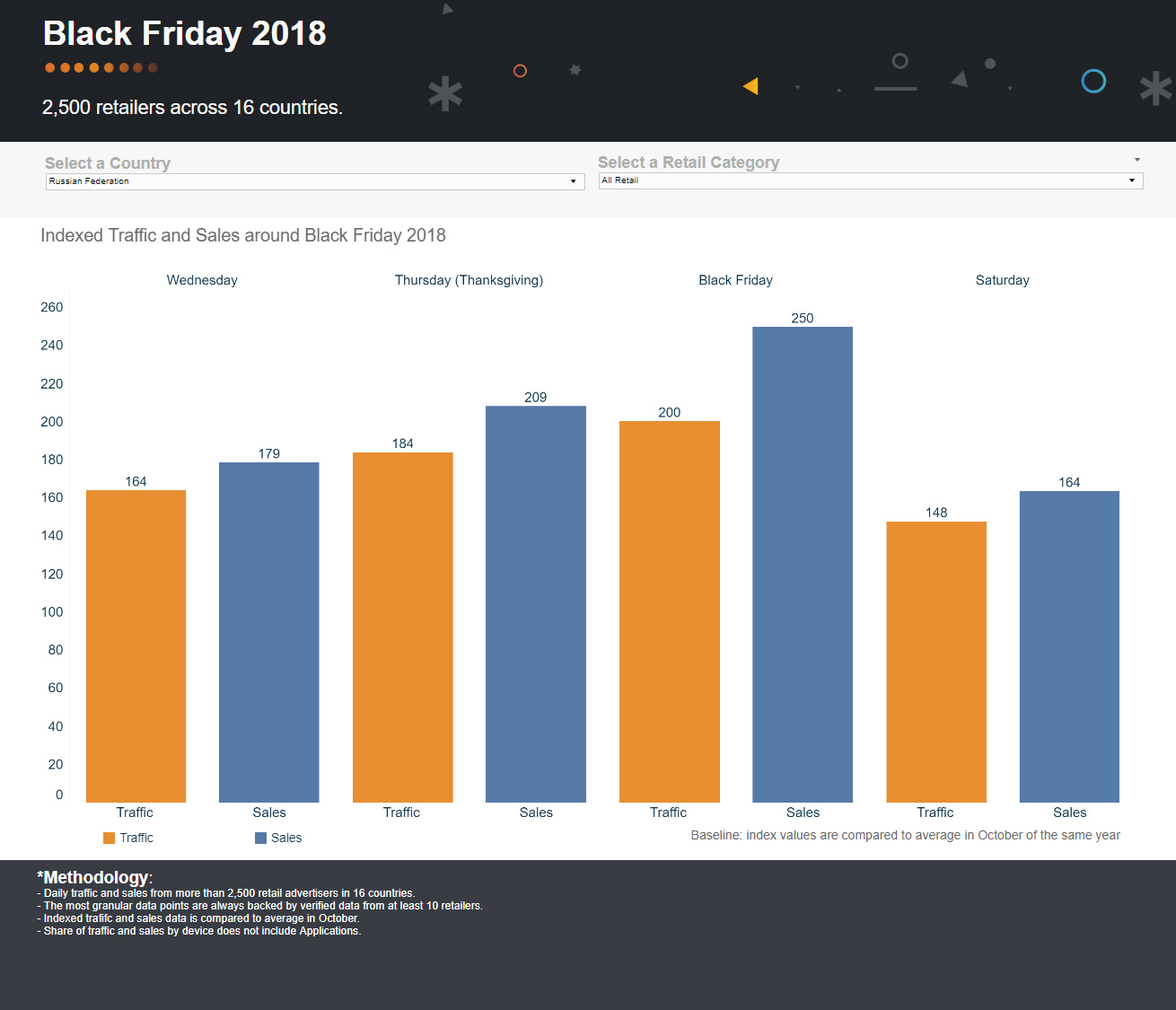
必须考虑以下重要因素:在线商店对系统中的任何“减速”变得特别敏感。 此外,我们的电子邮件通讯也大大增加了发送次数。
对我们而言,在不跌倒的情况下度过黑色星期五具有重要的战略意义 网站和商店邮件列表的最重要功能取决于平台的操作,即:
- 跟踪和发布产品建议,
- 发行相关材料(例如,图像设计建议书,例如箭头,徽标,图标和其他视觉元素),
- 发行尺寸合适的产品图片(为此,我们拥有“ ImageResizer” –一个子系统,可以从商店的服务器下载图片,将其压缩到所需的大小,并通过缓存服务器在每个推荐区域中为每种产品提供尺寸合适的图片)。
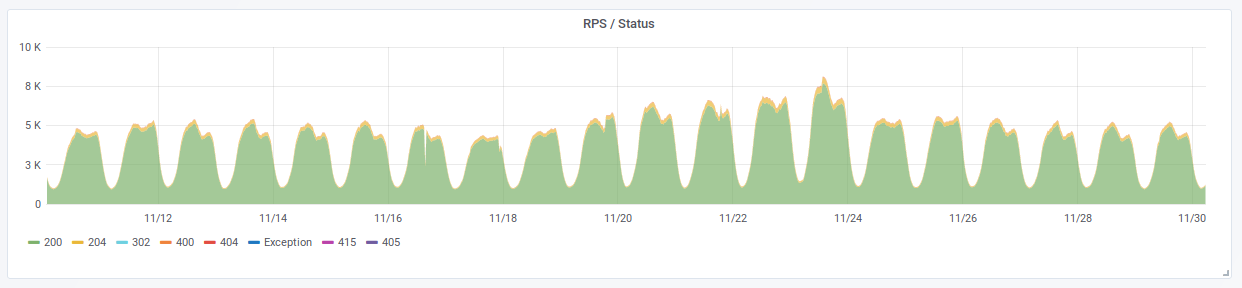
实际上,在2019年黑色星期五期间,服务的负载增加了40%,即 Retail Rocket系统在在线商店站点上监视和处理的事件数量从每秒5个增加到每秒8000个请求。 由于我们正准备承受更大的负载,因此我们很容易经历了这种激增。
一般准备
黑色星期五是所有零售尤其是电子商务的热门时间。 用户的数量及其活动有时会不断增长,因此,我们一如既往地为这个繁忙的时间做好了充分的准备。 我们在这里添加一个事实,即不仅在俄罗斯,而且在欧洲,许多在线商店都与我们建立了联系,因为欧洲的炒作要高得多,而且我们的热情水平比巴西系列差。 为增加负载做好充分准备需要做什么?
使用服务器
首先,有必要找出我们在增加服务器容量方面到底缺少什么。 已经在8月,我们开始为黑色星期五专门订购新服务器-总共增加了10台计算机。 到11月,他们已经完全处于战斗状态。
同时,部分构建机器被重新安装以用作应用程序服务器。 我们立即为使用不同的功能做好了准备:既用于发布建议,又用于ImageResizer服务,以便根据负载的类型,将它们中的每一个用作这些角色之一。 在正常模式下,Application和ImageResizer服务器具有明确定义的功能:第一个涉及推荐的发布,第二个提供在线商店网站上的字母和推荐块的图像。 在为黑色星期五做准备时,决定使所有两用服务器根据负载类型来平衡它们之间的流量。
然后,我们为Kafka(Apache Kafka)添加了两个大型服务器,并获得了由5台强大计算机组成的集群。 不幸的是,一切都没有我们想要的那么顺利:在数据同步过程中,两台新机器占据了整个网络通道的整个宽度,我们不得不迅速想出如何对整个基础架构快速安全地执行添加过程。 为了解决此问题,我们的管理员不得不勇敢地牺牲了周末。
处理数据
除了服务器之外,我们还决定优化文件以减轻负载,对我们而言,一大进步是静态文件的翻译。 先前托管在服务器上的所有静态文件都被带到S3 + Cloudfront。 他们一直想这样做很久,因为服务器上的负载接近极限值,现在出现了一个很好的原因。
黑色星期五之前的一周,我们将图像的缓存时间增加到3天,因此,如果ImageResizer下降,则可以从cdn获取以前缓存的图像。 它还减少了我们服务器上的负载,因为存储图像的时间越长,我们在调整大小上花费的资源就越少。
最后但并非最不重要的一点:在黑色星期五之前的5天,宣布暂停任何新功能的部署以及与基础架构的任何工作-所有注意力都集中在应对增加的负载上。
紧急应变计划
无论准备多么出色,fakapy始终是可能的。 我们针对可能的紧急情况制定了3个应对计划:
方案A:减少负荷。 如果由于负载激增,我们的服务器超出了可接受的响应时间,应该参与其中。 在这种情况下,我们准备了通过将部分流量切换到Amazon服务器来逐渐减少负载的机制,这将简单地对所有请求给出“ 200 OK”并给出空答案。 我们知道这是服务质量的下降,但是很明显,在服务根本不起作用或没有显示有关10%流量的建议的事实之间进行选择是显而易见的。
计划B:禁用服务。 暗示服务的部分降级。 例如,为了减轻一些数据库和通信渠道的负担,降低了计算个人推荐的速度。 在正常模式下,建议以实时模式计算,从而为每个访问者创建一个在线商店版本,但是在负载增加的情况下,速度降低使得其他核心服务可以继续工作。
计划C:为大决战。 如果发生完整的系统故障,我们已经准备了一个计划,该计划将使我们与客户安全断开连接。 购物者只会停止看到推荐;在线商店的性能不会受到影响。 为此,我们必须重置我们的集成文件,以便新用户停止与该服务进行交互。 也就是说,我们将禁用主要跟踪代码的工作,该服务将停止收集数据并计算推荐,而用户只会看到没有推荐块的页面。 对于以前收到过集成文件的所有用户,我们提供了将DNS记录切换到Amazon和200 OK存根的选项。
总结
即使无需使用其他构建机器,我们也可以应付全部负载。 而且,由于提前准备,我们不需要任何已制定的响应计划。 但是,所做的所有工作都是宝贵的经验,将有助于我们应对最意外和最庞大的流量涌入。
与2017年一样,服务负担增加了40%,黑色星期五在线商店的用户数量增加了60%。 所有的困难和错误都是在准备期间发生的,这使我们和我们的客户免于不可预见的情况。
您对黑色星期五感觉如何? 如何准备关键负荷?