前言
本文与之前发布的有关扫描某些国家/地区的Internet的文章不太相似,因为我没有追求对Internet的特定部分进行大规模扫描的开放端口和存在最普遍漏洞的目标,因为这是违法的。
我的兴趣稍有不同-尝试使用不同的方法来识别BY域区域中的所有相关站点,并通过Shodan,VirusTotal等服务来确定所使用的技术堆栈,以通过IP和开放端口执行被动侦察,并在附件中收集一些其他有用的信息信息,用于形成有关站点和用户的安全级别的一些常规统计信息。
介绍和我们的工具包
一开始的计划很简单-请与您的本地注册商联系以获取当前注册域的列表,然后检查所有内容以获取可用性并开始探索可运行的网站。 实际上,一切都变得更加复杂-这种信息是自然的,没有人愿意提供,除了BY区域中实际注册域名(约13万个域)的官方统计页面之外。 如果没有此类信息,则必须自己收集。
就工具而言,实际上,一切都非常简单-我们面向开放源码,您可以随时添加一些东西,完成一些基本工作。 在最受欢迎的工具中,使用了以下工具:
活动开始:起点
作为引言,正如我之前所说,理想的域名是合适的,但是在哪里可以买到呢? 我们需要从更简单的方法开始,在这种情况下,IP地址适合我们,但是再次-使用反向查找,并非总是能够捕获所有域,并且在收集主机名时-它并不总是正确的域。 在这个阶段,我再次考虑收集此类信息的可能方案-考虑到我们的预算是VPS租金5美元,其他一切都应该免费。
我们潜在的信息来源:
- IP地址( ip2location站点)
- 通过电子邮件地址的第二部分搜索域(但从何处获取它们?
- 一些注册服务商/托管服务提供商可能会以子域的形式向我们提供此类信息
- 子域及其后续反向链接(Sublist3r和Aquatone在这里可以提供帮助)
- 蛮力和手动输入(长,沉闷,但可以,尽管我没有使用此选项)
我会先行一点,说通过这种方法,我分别设法收集了大约5万个唯一的域和站点(我没有设法处理所有事情)。 如果他继续积极地收集信息,那么可以肯定,在不到一个月的工作中,我的传送带将掌握整个数据库或其中的大部分数据库。
让我们开始做生意
在前几篇文章中,有关IP地址的信息是从IP2LOCATION网站上获取的,出于明显的原因,我没有看过这些文章(因为所有操作都发生得较早),但也涉及到该资源。 没错,就我而言,方法是不同的-我决定不将数据库本地化,也不从CSV提取信息,而是决定直接在网站上持续不断地监视更改,并将其作为所有后续脚本作为目标的主要基础-制作了一个表格IP地址的格式不同:CIDR,“从”和“至”列表,国家标记(以防万一),AS编号,AS描述。
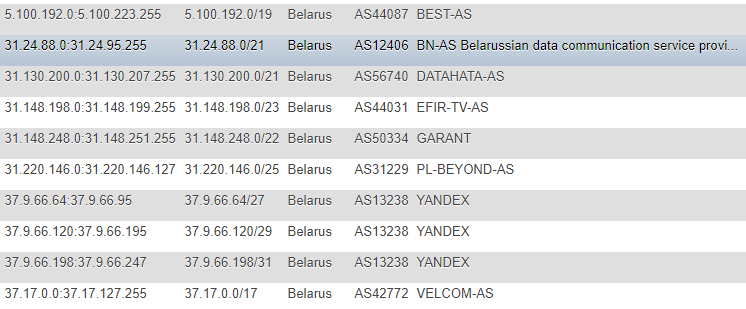
格式不是最理想的,但是我对演示和一次性升级感到非常满意,并且为了不经常获取ASN之类的辅助信息,我决定在家里另外进行记录。 为了获得此信息,我转向
IpToASN服务,它们具有便捷的API(有限制),实际上您只需要集成到自己中即可。
IP解析代码function ipList() { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $ipList = curl_exec($ch); curl_close ($ch); preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches); return $matches[0]; } function iprange2cidr($ipStart, $ipEnd){ if (is_string($ipStart) || is_string($ipEnd)){ $start = ip2long($ipStart); $end = ip2long($ipEnd); } else{ $start = $ipStart; $end = $ipEnd; } $result = array(); while($end >= $start){ $maxSize = 32; while ($maxSize > 0){ $mask = hexdec(iMask($maxSize - 1)); $maskBase = $start & $mask; if($maskBase != $start) break; $maxSize--; } $x = log($end - $start + 1)/log(2); $maxDiff = floor(32 - floor($x)); if($maxSize < $maxDiff){ $maxSize = $maxDiff; } $ip = long2ip($start); array_push($result, "$ip/$maxSize"); $start += pow(2, (32-$maxSize)); } return $result; } $getIpList = ipList(); foreach($getIpList as $item) { $cidr = iprange2cidr($ip[0], $ip[1]); }
弄清楚IP之后,我们需要通过反向查找服务运行整个数据库,可惜没有任何限制-除了钱,这是不可能的。
在最适合此功能且易于使用的服务中,我想提到两个:
- VirusTotal-限制从一个API密钥调用的频率
- Hackertarget.com(其API)-限制一个IP的点击次数
超过限制,可获得以下选项:
- 在第一种情况下,一种情况是承受15秒的超时,我们总共将每分钟有4个呼叫,这会极大地影响我们的速度,在这种情况下,使用2-3个这样的键将很有用,我建议使用相同的方法代理和更改用户代理。
- 在第二种情况下,我编写了一个脚本,用于基于公开可用的信息,其验证和后续使用来自动解析代理数据库(但后来我离开了此选项,因为VirusTotal本质上也足够了)
我们走得更远并且很顺利地转到电子邮件地址。 它们也可以成为有用信息的来源,但是在哪里收集它们呢? 我不必长时间寻找解决方案,因为 用户在我们的个人网站细分中占有很少的份额,其中大多数是组织-在线商店目录,论坛和有条件的市场等个人资料网站将非常适合我们。
例如,对这些站点之一的快速检查显示,许多用户将其电子邮件直接添加到其公共资料中,因此,可以仔细分析此业务以备将来使用。
我将不讨论解析每个站点的细节,在某个地方更容易通过蛮力猜测用户ID,在某个地方更容易解析站点地图,从中获取有关公司页面的信息,然后从中收集地址。 收集地址后,我们仍然需要执行一些简单的操作,立即按域区域对它们进行排序,保留“尾巴”并用尽它们,以从现有数据库中排除重复项。
在这个阶段,我相信随着范围的形成,我们可以结束并继续发展智能。 我们已经知道,智能可以分为主动和被动两种类型,在我们的案例中,被动方法将是最相关的。 但是再说一次,仅在端口80或443上访问站点而没有恶意负载并利用漏洞是相当合法的行为。 我们的兴趣是服务器对单个请求的响应,在某些情况下,可以有两个请求(从http重定向到https),在少数情况下,可以多达三个(使用www时)。
智商
使用此类信息作为域,我们可以收集以下数据:
- DNS记录(NS,MX,TXT)
- 答案标题
- 识别使用的技术栈
- 了解网站使用哪种协议。
- 尝试识别开放端口(基于Shodan / Censys数据库)而不进行直接扫描
- 尝试根据Shodan / Censys与Vulners数据库之间的信息相关性来识别漏洞
- 它在Google安全浏览恶意软件数据库中吗
- 此外,还可以按域收集电子邮件地址,以及已经找到的匹配项并通过“我被拥有”进行检查-链接到社交网络
- 在某些情况下,域不仅是公司的面孔,而且是其活动的产品,用于服务注册的电子邮件地址等,您可以在GitHub,Pastebin,Google Dorks(Google CSE)等资源上搜索与其相关的信息)
您可以随时使用masscan或nmap,zmap选项,先通过Tor进行设置,然后随机启动,甚至在多个实例中启动,但我们还有其他目标,而且这个名称意味着我没有进行直接扫描。
我们收集DNS记录,检查请求放大的可能性和诸如AXFR之类的配置错误:
收集NS服务器记录的示例 dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'
MX记录收集示例(请参阅NS,只需将'ns'替换为'mx'
检查AXFR(这里有很多解决方案,这里是另一个拐杖,但是不安全,我曾经查看输出) $digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'")); $ns = explode("\n", $digNs); foreach($ns as $target) { $axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'")); $axfr = preg_replace("/\;/", "", $axfr); if(!empty(trim($axfr))) { $axfr = preg_replace("/\;/", "", $axfr); $res = json_encode(explode("\n", trim($axfr)));
检查DNS放大 dig +short test.openresolver.com TXT @$dns
就我而言,NS服务器是从数据库中获取的,因此在变量的末尾,实际上您可以替换任何服务器。 关于此服务结果的正确性,我不确定那里一切正常,结果始终有效,但我希望大多数结果都是真实的。
如果出于任何目的,我们需要保留网站的完整最终网址,为此我使用了cURL:
curl -I -L $target | awk '/Location/{print $2}'
他本人将经历整个重定向并显示最后一个重定向,即 当前网站的网址。 就我而言,它对于随后使用诸如WhatWeb之类的工具非常有用。
我们为什么要使用它? 为了确定操作系统,Web服务器,所使用的CMS站点,一些标头,诸如JS / HTML库/框架之类的其他模块,以及站点名称,您以后可以通过该站点标题尝试按同一活动字段进行过滤。
在这种情况下,一个非常方便的选择是以XML格式导出该工具的操作结果以进行后续分析,如果目标是稍后进行处理,则可以将其导入数据库。
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xml
就我自己而言,我根据输出结果制作了JSON,并将其放入数据库中。
说到标题,通过执行以下形式的查询,您可以使用普通的cURL进行几乎相同的操作:
curl -I https://www.mywebsite.com
在标头中,例如,使用正则表达式捕获有关CMS和Web服务器的信息。
除了有用的方法外,我们还可以强调以下可能性:使用Shodan收集有关开放端口的信息,然后使用已经获得的数据,使用其API对Vulners数据库进行检查(在标题中提供了指向服务的链接)。 当然,在这种情况下,准确性可能会出现问题,但这不是通过手动验证进行的直接扫描,而是对第三方来源的数据进行了平庸的“弄乱”,但至少总比没有好。
Shodan的PHP函数 function shodanHost($host) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $shodanResponse = curl_exec($ch); curl_close ($ch); return json_decode($shodanResponse); }
是的,自从他们开始谈论API以来,Vulners就有了局限性,最理想的解决方案是使用Python脚本,一切都可以顺利进行而无需扭转,在PHP的情况下,我遇到了一些小困难(再次添加。超时保存了情况)。
最新测试之一-我们将研究与脚本一起使用的防火墙信息,例如“ wafw00f”。 在测试这个出色的工具时,我注意到了一件有趣的事情:并非总是第一次可以确定所使用的防火墙的类型。
要查看wafw00f可以检测到哪些类型的防火墙,可以输入以下命令:
wafw00f -l
为了确定防火墙的类型,wafw00f在向站点发送标准请求后分析服务器的响应标头,如果这种尝试还不够,它会生成一个附加的简单测试请求,如果再次不够,则第三种方法将在前两次尝试之后对数据进行操作。
因为 对于统计数据,实际上,我们不需要完整的答案,我们使用正则表达式将所有多余的内容都切除,仅保留防火墙名称:
/is\sbehind\sa\s(.+?)\n/
好吧,正如我之前写的-除了有关域和站点的信息之外,有关电子邮件地址和社交网络的信息也以被动方式进行了更新:
在这方面,最简单的方法是处理Twitter上的地址验证(2种方法),而使用Facebook(1种方法),由于生成实际用户会话的系统稍微复杂一些,事实证明它要复杂一些。
让我们继续进行干统计。
DNS统计
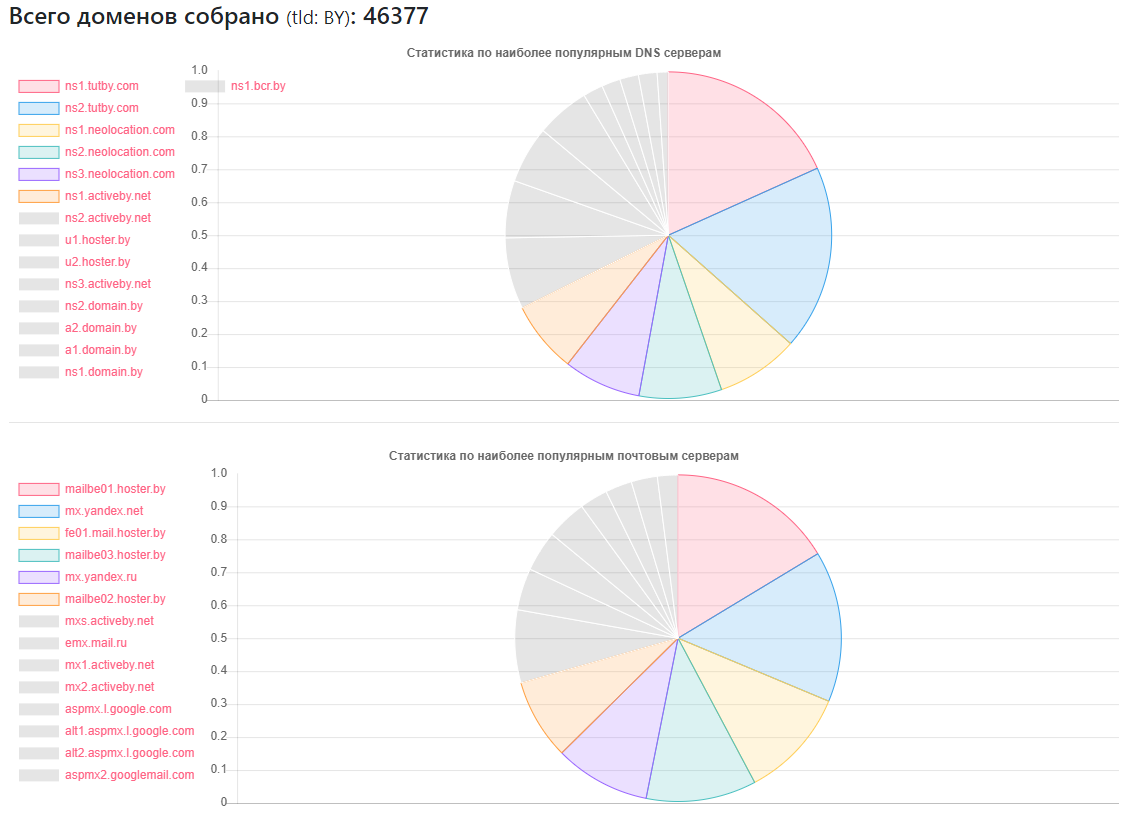 提供商-多少个站点
提供商-多少个站点ns1.tutby.com:10899
ns2.tutby.com:10899
ns1.neolocation.com:4877
ns2.neolocation.com:4873
ns3.neolocation.com:4572
ns1.activeby.net:4231
ns2.activeby.net:4229
u1.hoster.by:3382
u2.hoster.by:3378
找到唯一的DNS:2462
独特的MX(邮件)服务器:9175(除了流行的服务之外,还有足够数量的管理员使用自己的邮件服务)
受DNS区域传输影响:1011
受DNS放大影响:531
很少有CloudFlare粉丝:375(基于使用过的NS记录)
CMS统计
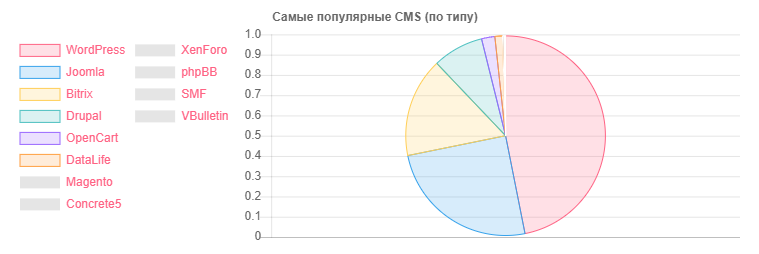 CMS-数量
CMS-数量WordPress:5118
Joomla:2722
Bitrix:1757年
Drupal:898
OpenCart的:235
数据生命:133
Magento的:32
- 潜在脆弱的WordPress安装:2977
- Joomla的潜在脆弱安装:212
- 使用Google SafeBrowsing服务,可以识别潜在的危险或受感染的网站:大约10,000个(在不同时间,有人被修复,有人被破坏,统计数据并不完全是客观的)
- 关于HTTP和HTTPS-发现的卷中不到一半的站点使用后者,但是考虑到我的数据库不完整,但仅占总数的40%,因此,下半部分站点中的大多数很可能可以通过HTTPS进行通信。
防火墙统计信息:
 防火墙-编号
防火墙-编号ModSecurity:4354
IBM Web App安全性:126
更好的WP安全性:110
耀斑:104
Imperva SecureSphere:45
Juniper WebApp安全:45
Web服务器统计
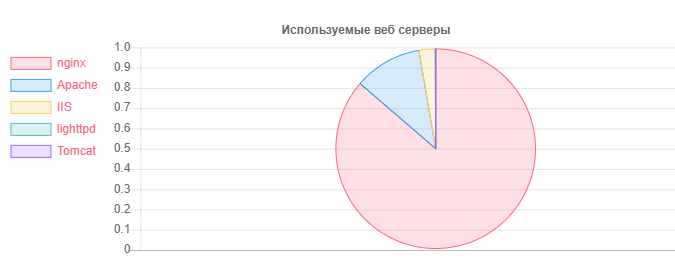 Web服务器-编号
Web服务器-编号Nginx:31752
阿帕奇:4042
IIS:959
Nginx的过时和潜在漏洞安装:20966
不推荐使用的,可能易受攻击的Apache安装:995
例如,尽管hoster.by是域名和托管领域的领导者,但通常也区分了Open Contact,但事实是一个IP上的站点数:
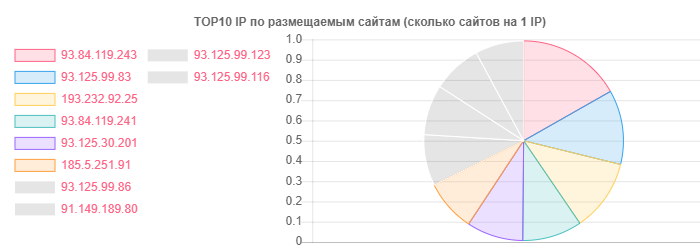 IP-网站
IP-网站93.84.119.243:556
93.125.99.83:399
193.232.92.25:386
通过电子邮件,详细的统计信息确实决定不被提取,也没有按域区域进行排序,相反,看到特定供应商的用户位置很有趣:
- 在TUT.BY服务上:38282
- 在Yandex服务上(按| ru):28127
- 在Gmail服务上:33452
- 绑在Facebook上:866
- 绑在Twitter上:652
- 符合HIBP:7844的泄漏特征
- 被动情报帮助识别超过13000个电子邮件地址
如您所见,总体情况是乐观的,尤其是托管服务提供商提供的Nginx的积极使用。 也许这主要是由于普通用户中的流行-共享托管类型。
由于我真的不喜欢它,所以有足够多的中间人托管服务提供商注意到了AXFR之类的错误,使用过时的SSH和Apache版本以及其他一些小问题。 在这里,当然可以通过活动阶段来进一步了解情况,但是目前,根据我们的立法,在我看来这是不可能的,而且我真的不想在这类问题上加入有害生物的行列。
如果您可以这样称呼,那么电子邮件的图片通常会非常漂亮。 哦,是的,指示了TUT.BY提供程序的位置-这意味着使用域,因为 此服务基于Yandex。
结论
总而言之,我可以说一件事-即使获得了可用的结果,您也可以快速了解,涉及清理病毒,设置WAF以及配置/添加不同CMS的专家的工作量很大。
好吧,严肃地说,就像前两篇文章一样,我们看到问题在Internet和国家的绝对所有细分市场中存在着完全不同的层次,其中一些问题甚至在没有使用攻击性方法的情况下就进行了远程研究。 e。 使用公开信息收集不需要的特殊技能。