第一部分
第二部分
今天的对话主题是处理内存。 我将讨论初始化页面目录,映射物理内存,管理虚拟机以及分配器的组织堆。
正如我在第一篇文章中所说的,我决定使用4 MB页面来简化我的生活,而不必处理分层表。 将来,我希望像大多数现代系统一样转到4 KB页面。 我可以使用一个现成的(例如, 这样的块分配器 ),但是编写自己的代码有点有趣,并且我想更多地了解内存的寿命,所以我有话要告诉你。
上一次我确定与体系结构相关的setup_pd方法并希望继续使用该方法时,但是,我在上一篇文章中没有涉及更多细节-使用Rust和标准println宏的VGA输出。 由于它的实现是微不足道的,因此我将在破坏器下将其删除。 该代码在调试包中。
宏打印#[macro_export] macro_rules! print { ($($arg:tt)*) => ($crate::debug::_print(format_args!($($arg)*))); } #[macro_export] macro_rules! println { () => ($crate::print!("\n")); ($($arg:tt)*) => ($crate::print!("{}\n", format_args!($($arg)*))); } #[cfg(target_arch = "x86")] pub fn _print(args: core::fmt::Arguments) { use core::fmt::Write; use super::arch::vga; vga::VGA_WRITER.lock().write_fmt(args).unwrap(); } #[cfg(target_arch = "x86_64")] pub fn _print(args: core::fmt::Arguments) { use core::fmt::Write; use super::arch::vga;
现在,我怀着明确的良知,回到记忆中。
页面目录初始化
我们的kmain方法采用三个参数作为输入,其中之一是页面表的虚拟地址。 要在以后将其用于分配和内存管理,您需要指定记录和目录的结构。 对于x86,Page目录和Page表的描述非常好,因此,我将仅作一个简短的介绍。 Page目录条目是一个指针大小结构,对我们来说是4个字节。 该值包含页面的4KB物理地址。 记录的最低有效字节保留给标志。 将虚拟地址转换为物理地址的机制如下所示(在我的4 MB粒度情况下,移位发生22位。对于其他粒度,移位将有所不同,并且将使用分层表!):
虚拟地址0xC010A110->通过向右移动22位地址来获取目录中的索引->索引0x300->通过索引0x300获取页面的物理地址,检查标志和状态-> 0x1000000->以虚拟地址的底22位作为偏移量,添加到页面的物理地址-> 0x1000000 + 0x10A110 =内存中的物理地址0x110A110
为了加快访问速度,处理器使用TLB-转换后备缓冲区来缓存页面地址。
因此,这是我的目录及其条目的描述方式,并且实现了setup_pd方法。 为了编写页面,实现了“构造函数”方法,该方法保证4 KB的对齐方式和设置标志,以及一种获取页面物理地址的方法。 目录只是由1024个四字节条目组成的数组。 该目录可以使用set_by_addr方法将虚拟地址与页面相关联。
#[derive(Debug, Clone, Copy, PartialEq, Eq)] pub struct PDirectoryEntry(u32); impl PDirectoryEntry { pub fn by_phys_address(address: usize, flags: PDEntryFlags) -> Self { PDirectoryEntry((address as u32) & ADDRESS_MASK | flags.bits()) } pub fn flags(&self) -> PDEntryFlags { PDEntryFlags::from_bits_truncate(self.0) } pub fn phys_address(&self) -> u32 { self.0 & ADDRESS_MASK } pub fn dbg(&self) -> u32 { self.0 } } pub struct PDirectory { entries: [PDirectoryEntry; 1024] } impl PDirectory { pub fn at(&self, idx: usize) -> PDirectoryEntry { self.entries[idx] } pub fn set_by_addr(&mut self, logical_addr: usize, entry: PDirectoryEntry) { self.set(PDirectory::to_idx(logical_addr), entry); } pub fn set(&mut self, idx: usize, entry: PDirectoryEntry) { self.entries[idx] = entry; unsafe { invalidate_page(idx); } } pub fn to_logical_addr(idx: usize) -> usize { (idx << 22) } pub fn to_idx(logical_addr: usize) -> usize { (logical_addr >> 22) } } use lazy_static::lazy_static; use spin::Mutex; lazy_static! { static ref PAGE_DIRECTORY: Mutex<&'static mut PDirectory> = Mutex::new( unsafe { &mut *(0xC0000000 as *mut PDirectory) } ); } pub unsafe fn setup_pd(pd: usize) { let mut data = PAGE_DIRECTORY.lock(); *data = &mut *(pd as *mut PDirectory); }
我非常笨拙地将初始静态初始化设置为不存在的地址,因此,如果您能给我写信,Rust社区中如何使用链接重新分配进行此类初始化,我将不胜感激。
现在我们可以从高级代码管理页面,我们可以继续编译内存初始化。 这将分两个阶段进行:通过处理物理存储卡和初始化虚拟管理器
match mb_magic { 0x2BADB002 => { println!("multibooted v1, yeah, reading mb info"); boot::init_with_mb1(mb_pointer); }, . . . . . . } memory::init();
GRUB存储卡和OS1物理存储卡
为了从GRUB获取存储卡,在引导阶段,我在标头中设置了相应的标志,而GRUB给了我结构的物理地址。 我将其从官方文档移植到Rust表示法,还添加了一些方法来轻松地遍历存储卡。 GRUB的大部分结构都不会被填充,在这个阶段,这对我来说不是很有趣。 最主要的是,我不想手动确定可用内存量。
通过Multiboot初始化时,我们首先将物理地址转换为虚拟地址。 从理论上讲,GRUB可以将结构放置在任何位置,因此,如果地址超出页面范围,则需要在Page目录中分配虚拟页面。 实际上,该结构几乎总是位于第一个兆字节之后,我们已经在引导阶段分配了该兆字节。 以防万一,我们检查存储卡是否存在并继续进行分析。
pub mod multiboot2; pub mod multiboot; use super::arch; unsafe fn process_pointer(mb_pointer: usize) -> usize {
存储卡是一个链接列表,在基本结构中为其指定了初始物理地址(不要忘记将所有内容转换为虚拟地址),并以字节为单位指定数组的大小。 您必须根据每个元素的大小遍历列表,因为理论上它们的大小可以不同。 这是迭代的样子:
impl MultibootInfo { . . . . . . pub unsafe fn get_mmap(&self, index: usize) -> Option<*const MemMapEntry> { use crate::arch::get_mb_pointer_base; let base: usize = get_mb_pointer_base(self.mmap_addr as usize); let mut iter: *const MemMapEntry = (base as u32 + self.mmap_addr) as *const MemMapEntry; for _i in 0..index { iter = ((iter as usize) + ((*iter).size as usize) + 4) as *const MemMapEntry; if ((iter as usize) - base) >= (self.mmap_addr + self.mmap_lenght) as usize { return None } else {} } Some(iter) } }
解析存储卡时,我们遍历GRUB结构并将其转换为位图,OS1将使用该位图来管理物理内存。 尽管GRUB和BIOS提供了更多选项,但我决定将自己限制在一小部分可用的控制值上-空闲,忙碌,保留,不可用。 因此,我们遍历映射条目并将其状态从GRUB / BIOS值转换为OS1的值:
pub fn parse_mmap(mbi: &MultibootInfo) { unsafe { let mut mmap_opt = mbi.get_mmap(0); let mut i: usize = 1; loop { let mmap = mmap_opt.unwrap(); crate::memory::physical::map((*mmap).addr as usize, (*mmap).len as usize, translate_multiboot_mem_to_os1(&(*mmap).mtype)); mmap_opt = mbi.get_mmap(i); match mmap_opt { None => break, _ => i += 1, } } } } pub fn translate_multiboot_mem_to_os1(mtype: &u32) -> usize { use crate::memory::physical::{RESERVED, UNUSABLE, USABLE}; match mtype { &MULTIBOOT_MEMORY_AVAILABLE => USABLE, &MULTIBOOT_MEMORY_RESERVED => UNUSABLE, &MULTIBOOT_MEMORY_ACPI_RECLAIMABLE => RESERVED, &MULTIBOOT_MEMORY_NVS => UNUSABLE, &MULTIBOOT_MEMORY_BADRAM => UNUSABLE, _ => UNUSABLE } }
物理内存在memory ::物理模块中进行管理,为此我们在上面调用了map方法,并向其传递区域的地址,其长度和状态。 系统可能可用的所有4 GB内存,并划分为4 MB页面,由位图中的两位表示,这使您可以为1024页存储4种状态。 该构造总共需要256个字节。 位图会导致严重的内存碎片,但它易于理解且易于实现,这是我的主要目标。
我将删除扰流器下的位图实现,以免使文章混乱。 该结构能够计算类和可用内存的数量,通过索引和地址标记页面,还可以搜索可用页面(将来在实现堆时将需要使用该页面)。 该卡本身是一个由64个u32元素组成的数组,用于隔离必需的两个位(块),并转换为所谓的块(数组中的索引,包装16个块)和块(块中的位位置)。
物理内存位图 pub const USABLE: usize = 0; pub const USED: usize = 1; pub const RESERVED: usize = 2; pub const UNUSABLE: usize = 3; pub const DEAD: usize = 0xDEAD; struct PhysMemoryInfo { pub total: usize, used: usize, reserved: usize, chunks: [u32; 64], } impl PhysMemoryInfo {
现在我们开始分析地图的一个元素。 如果地图元素描述的内存区域少于一页的4 MB或等于4 MB,则我们将该页面标记为整体。 如果更多,请分成4 MB,并通过递归分别标记每个部分。 在位图初始化阶段,我们认为内存的所有部分都无法访问,因此当卡用完时,例如128 MB,其余部分被标记为不可访问。
use lazy_static::lazy_static; use spin::Mutex; lazy_static! { static ref RAM_INFO: Mutex<PhysMemoryInfo> = Mutex::new(PhysMemoryInfo { total: 0, used: 0, reserved: 0, chunks: [0xFFFFFFFF; 64] }); } pub fn map(addr: usize, len: usize, flag: usize) {
堆和管理她
目前,虚拟内存管理仅限于堆管理,因为内核对此一无所知。 当然,将来有必要管理所有内存,并且将重写此小型管理器。 但是,目前,我所需要的只是静态内存(其中包含可执行代码和堆栈)以及动态堆内存,我将在其中分配用于多线程的结构。 我们在引导阶段分配静态内存(到目前为止,由于内核适合内存,所以我们只能分配4 MB的内存),并且通常来说现在没有任何问题。 另外,在这个阶段,我没有DMA设备,因此一切都非常简单,但是可以理解。
我为堆提供了512 MB的最高内核内存空间(0xE0000000),我将堆使用情况映射(0xDFC00000)降低了4 MB。 我使用位图来描述状态,就像物理内存一样,但是其中只有2个状态-忙/闲。 内存块的大小为64字节-对于u32,u8这样的小变量来说,这是很多的,但是,对于存储数据结构而言,它是最佳的。 尽管如此,我们不太可能需要在堆上存储单个变量,因为它的主要目的是存储用于多任务处理的上下文结构。
64字节的块被分组为描述整个4 MB页面状态的结构,因此我们可以将少量和大量的内存分配给多个页面。 我使用以下术语:块-64字节,包-2 KB(一个u32-64字节*每个包32位),页面-4 MB。
#[repr(packed)] #[derive(Copy, Clone)] struct HeapPageInfo {
从分配器请求内存时,我会根据粒度考虑三种情况:
- 分配器发出的内存请求少于2 KB。 您需要找到一个包,该包中的包将是免费的[大小/ 64,任何非零余数加一个]块,将这些块标记为忙,返回第一个块的地址。
- 分配器发出的内存小于4 MB但大于2 KB的请求。 您需要找到一个页面,该页面具有免费的[大小/ 2048,任何非零余数连续增加一个]包。 将[size / 2048]数据包标记为忙;如果有剩余,则将最后一个数据包中的[剩余]块标记为忙。
- 分配器要求内存大于4 MB。 连续查找[size / 4 Mi,任何非零余额加一个]页面,如果有余额,则将[size / 4 Mi]页面标记为忙-将[balance]打包标记为忙。 在最后一个包中,将其余块标记为忙。
对空闲区域的搜索还取决于粒度-选择一个用于迭代或位掩码的数组。 每当您出国时,都会发生OOM。 释放时,使用类似的算法,仅用于标记已释放。 释放的内存不会重置。 整个代码很大,我把它放在破坏者的下面。
分配和页面错误
为了使用堆,您需要一个分配器。 添加它会为我们打开一个向量,树木,哈希表,盒子等等,没有它们,它几乎是不可能生存的。 一旦我们插入alloc模块并声明一个全局分配器,生活就会立即变得更加轻松。
分配器的实现非常简单-它只是引用上述机制。
use alloc::alloc::{GlobalAlloc, Layout}; pub struct Os1Allocator; unsafe impl Sync for Os1Allocator {} unsafe impl GlobalAlloc for Os1Allocator { unsafe fn alloc(&self, layout: Layout) -> *mut u8 { use super::logical::{KHEAP_CHUNK_SIZE, allocate_n_chunks}; let size = layout.size(); let mut chunk_count: usize = 1; if size > KHEAP_CHUNK_SIZE { chunk_count = size / KHEAP_CHUNK_SIZE; if KHEAP_CHUNK_SIZE * chunk_count != size { chunk_count += 1; } } allocate_n_chunks(chunk_count, layout.align()) } unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) { use super::logical::{KHEAP_CHUNK_SIZE, free_chunks}; let size = layout.size(); let mut chunk_count: usize = 1; if size > KHEAP_CHUNK_SIZE { chunk_count = size / KHEAP_CHUNK_SIZE; if KHEAP_CHUNK_SIZE * chunk_count != size { chunk_count += 1; } } free_chunks(ptr as usize, chunk_count); } }
lib.rs中的分配器按以下方式打开:
#![feature(alloc, alloc_error_handler)] extern crate alloc; #[global_allocator] static ALLOCATOR: memory::allocate::Os1Allocator = memory::allocate::Os1Allocator;
当我们尝试以这种方式分配自己时,会出现Page Fault异常,因为我们尚未计算出虚拟内存的分配。 好吧,怎么这样! 好了,您必须返回上一篇文章的内容并添加例外。 我决定实现虚拟内存的惰性分配,也就是说,页面分配不是在内存请求时分配的,而是在尝试访问它时分配的。 幸运的是,x86处理器允许甚至鼓励这样做。 Page fault , , , — , , CR2 — , .
, . 32 ( , , 32 ), . Rust. , . , , iret , , Page fault Protection fault. Protection fault — , .
eE_page_fault: pushad mov eax, [esp + 32] push eax mov eax, cr2 push eax call kE_page_fault pop eax pop eax popad add esp, 4 iret
Rust , . , . . .
bitflags! { struct PFErrorCode: usize { const PROTECTION = 1;
, . , . . , . , , :
println!("memory: total {} used {} reserved {} free {}", memory::physical::total(), memory::physical::used(), memory::physical::reserved(), memory::physical::free()); use alloc::vec::Vec; let mut vec: Vec<usize> = Vec::new(); for i in 0..1000000 { vec.push(i); } println!("vec len {}, ptr is {:?}", vec.len(), vec.as_ptr()); println!("Still works, check reusage!"); let mut vec2: Vec<usize> = Vec::new(); for i in 0..10 { vec2.push(i); } println!("vec2 len {}, ptr is {:?}, vec is still here? {}", vec2.len(), vec2.as_ptr(), vec.get(1000).unwrap()); println!("Still works!"); println!("memory: total {} used {} reserved {} free {}", memory::physical::total(), memory::physical::used(), memory::physical::reserved(), memory::physical::free());
:
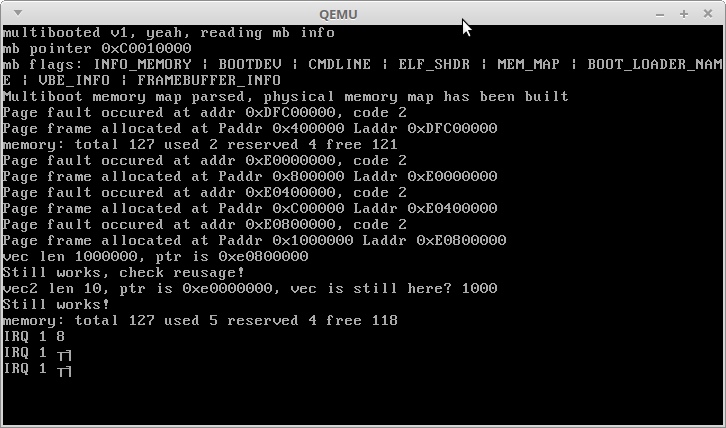
, , . 3,5 + 3 , . 3,5 .
IRQ 1 — Alt + PrntScrn :)
, , Rust — , — , !
, .
感谢您的关注!