 由DataArt解决方案架构师Denis Tsyplakov发布
由DataArt解决方案架构师Denis Tsyplakov发布问题陈述
构建微服务架构时,尤其是将整体架构迁移到微服务时,问题之一通常是事务。 每个微服务负责其自己的功能组,可能管理与该组相关的数据,并且可以自主地或通过将请求发送到其他微服务来满足用户请求。 在我们需要确保由不同的微服务控制的数据的一致性之前,所有这些工作都很好。
例如,我们的应用程序可以在某些大型在线商店中使用。 除其他事项外,我们有三个独立的,相互联系薄弱的业务领域:
- 仓库-库存,在何处,如何存储以及存储了多长时间,当前有多少种某种类型的货物在仓库中等等。
- 发送货物-包装,运输,跟踪交货,对延迟的投诉进行分析等。
- 如果将货物运往国外,则保持海关对货物流动的报告(实际上,我不知道在这种情况下是否有必要专门设计一些东西,但我仍会把国家服务与增加戏剧性的过程联系起来)。
这三个区域中的每个区域都包含许多不相交的功能,并且可以表示为几个微服务。
有一个问题。 假设有人购买了产品,将其包装并通过快递发送。 除其他事项外,我们需要指出仓库中的货物减少了一个单位,要注意货物的交付过程已经开始,并且例如如果货物被运到中国,则要照管海关文件。 如果应用程序在流程的第二阶段或第三阶段崩溃(例如,节点崩溃),我们的数据将进入不一致状态,并且只有少数此类失败会导致业务上非常不愉快的问题(例如,海关人员的来访)。
在这种经典的单片架构中,该问题可以通过数据库中的事务简单而优雅地解决。 但是,如果我们使用微服务怎么办? 即使我们使用所有服务中的一个数据库(虽然不是很好,但在我们的情况下也是可以的),但使用该数据库来自不同的流程,我们将无法在流程之间扩展事务。
解决方案
该问题有几种解决方案:
- 奇怪的是,有时问题可以忽略。 如果我们知道一个月内不会发生一次以上的故障,并且手动消除后果会花费企业可以接受的金钱,那么无论看起来多么难看,您都不会注意到该问题。 我不知道是否有可能忽略海关的要求,但是可以假设即使在某些情况下也可以这样做。
- 补偿(这与向海关的金钱补偿无关,例如,您支付了罚款)是一组各种步骤,这些步骤使处理顺序复杂化,但允许您检测和处理失败的流程。 例如,在开始操作之前,我们会写信给特殊服务,我们正在开始装运操作,最后,我们标记一切都结束了。 然后,我们定期检查是否有任何挂起的操作,是否有任何操作在查看所有三个数据库时尝试将数据置于一致状态。 这是一种完全可行的方法,但是它极大地增加了处理逻辑的复杂度,并且每次操作都非常麻烦。
- 严格来说,XA +规范是两阶段事务,它允许您创建相对于应用程序分布的事务,这是一种非常重要的机制,很少有人喜欢,更重要的是,很少有人可以配置。 另外,对于轻量级微服务,它在意识形态上弱兼容。
- 原则上,交易是共识问题的特例,可以使用许多分布式共识系统来解决该问题(大致来说,使用关键字paxos,raft,zookeeper,etcd,consul的google都是这样)。 但是在实际应用中,要获得大量的,繁琐的仓库活动数据,这看起来比两阶段交易还要复杂。
- 队列和最终的一致性(从长远来看是一致性)-我们将任务分为三个异步任务,依次处理数据,在队列之间的服务之间传递数据,并使用传递确认机制。 在这种情况下,代码不是很复杂,但是需要牢记以下几点:
- 队列保证了“一次或多次”的发送,也就是说,当重新发送相同的消息时,服务必须正确处理这种情况,并且不能两次装运货物。 例如,这可以通过订单的唯一UUID完成。
- 任何给定时间的数据都会略有不一致。 也就是说,货物将首先从仓库中消失,然后才稍有延迟,创建发货订单。 稍后,海关数据将被处理。 在我们的示例中,这是完全正常的,不会给业务造成问题,但是在某些情况下,此类数据行为可能会非常令人不快。
- 结果,如果第一个服务必须将一些数据返回给用户,那么最终将数据传递给用户的浏览器的调用顺序可能就很简单了。 主要问题是浏览器同步发送请求,并且通常需要同步响应。 如果执行异步请求处理,则需要构建将响应异步传递到浏览器的功能。 传统上,这是通过Web套接字或通过定期请求从浏览器到服务器的新事件来完成的。 有一些机制,例如SocksJS,可以简化构建此链接的某些方面,但是仍然会增加复杂性。
在大多数情况下,后一种选择是最可接受的。 尽管它的工作时间长了好几倍,但它并没有使处理请求复杂化,但是通常,对于这种操作来说,这是可以接受的。 它还需要稍微复杂一些的数据组织来切断重复的请求,但是这也没有什么超级复杂的。
在示意图上,使用队列和最终一致性处理事务的选项之一可能看起来像这样:
- 用户进行了购买,有关此消息将发送到队列(例如,RabbitMQ集群,或者,如果我们在Google Cloud Platform中工作-Pub / Sub)。 队列是持久性的,可以保证传递一次或多次,并且是事务性的,也就是说,如果处理该消息的服务突然丢失,则该消息不会丢失,但会再次传递给该服务的新实例。
- 消息到达服务,该服务将仓库中的货物标记为准备装运,然后将消息“货物已准备好装运”发送到队列。
- 在下一步中,负责派遣的服务接收到有关准备派遣的消息,创建派遣任务,然后发送消息“计划派遣货物”。
- 接收到已计划调度的消息后,下一个服务将启动海关的文书工作。
此外,将检查服务接收到的每个消息的唯一性,如果已经处理了具有此类UUID的消息,则将其忽略。
在这里,每个时间数据库的数据库处于稍微不一致的状态,即仓库中的货物已经被标记为正在交付过程中,但是交付任务本身还没有在那儿,它将在一两秒钟后出现。 但是同时,我们有99.999%(实际上,这个数字等于队列服务的可靠性级别)保证了发送任务将出现。 对于大多数企业来说,这是可以接受的。
那这篇文章是关于什么的?
在本文中,我想讨论解决微服务应用程序中事务性问题的另一种方法。 尽管每个服务都有自己的数据库时微服务最有效,但对于中小型系统,所有数据通常都可以轻松地放入现代关系数据库中。 几乎所有内部企业系统都是如此。 也就是说,我们通常不需要严格地在不同的物理机器之间共享数据。 我们可以将来自不同微服务的数据存储在同一数据库的不相关的表组中。 如果将旧的单一应用程序划分为服务并且已经划分了代码,但是数据仍然存在于同一数据库中,则这特别方便。 但是,事务拆分问题仍然存在-事务与网络连接以及打开该连接的过程紧密地联系在一起,并且我们有单独的过程。 如何成为
上面,我描述了解决该问题的几种常用方法,但是我想为所有数据都在一个数据库中的特殊情况提供另一种方法。 我
不建议尝试在此项目中实现此方法,但是对于我在本文中
介绍它已经足够了。 好吧,突然之间,在某些特殊情况下,它将派上用场。
其本质非常简单。 事务与网络连接相关联,数据库并不真正知道谁坐在开放网络连接的那一端。 她不在乎,主要是将正确的命令发送到套接字。 显然,套接字通常只属于客户端上的一个进程,但是我看到至少有三种方法可以解决此问题。
1.更改数据库代码
在数据库的数据库代码级别上,我们可以更改其代码,并制作自己的数据库程序集,我们实现了在连接之间传输事务的机制。 从客户的角度来看它如何工作:
- 我们开始交易,进行一些更改,是时候将交易转移到下一个服务了。
- 我们告诉数据库为我们提供事务的UUID,然后等待N秒。 如果在此期间没有使用此UUID的另一个连接,请回滚该事务,如果是,则将与该事务关联的所有数据结构传输到新连接并继续使用它。
- 我们将UUID传递给下一个服务(即传递给另一个进程,可能传递给另一个VM)。
- 在其中,打开一个连接并发出DB命令-使用指定的UUID继续事务。
- 我们将继续使用数据库,这是另一个进程启动的事务的一部分。
这种方法使用起来最轻巧,但是需要修改数据库代码,应用程序程序员通常不这样做,它需要很多特殊技能。 最有可能的是,有必要在数据库进程和数据库之间传输数据,而我们可以安全地更改其代码的数据库-PostgreSQL。 此外,这仅适用于非托管服务器,RDS或Cloud SQL中将不支持。
从示意图上看,它看起来像这样:

2.插座的操作
我想到的第二件事是套接字对数据库连接的微妙操纵。 我们可以制作一些“反向套接字代理”,它将来自多个客户端的命令定向到数据库中一个命令流中的特定端口。
实际上,此应用程序与pgBouncer非常相似,除了其标准功能外,还对来自客户端的字节流进行了一些操作,并能够在命令中用一个客户端替换另一个客户端。
我非常不喜欢这种方法,因为要实现该方法,必须清理服务器和客户端之间循环的二进制数据包。 而且它仍然需要大量的系统编程。 我纯粹是出于完整性而提出的。
3.网关JDBC
我们可以制作一个网关JDBC驱动程序-我们将标准JDBC驱动程序用于特定的数据库,让它成为PostgreSQL。 我们包装该类,并为其所有外部方法(不是HTTP,但差别很小)建立HTTP接口。 接下来,我们制作另一个JDBC驱动程序-Facade,它将所有方法调用重定向到JDBC网关。 也就是说,实际上,我们将现有驱动程序分为两半,并通过网络将这些两半连接起来。 我们得到以下组件图:
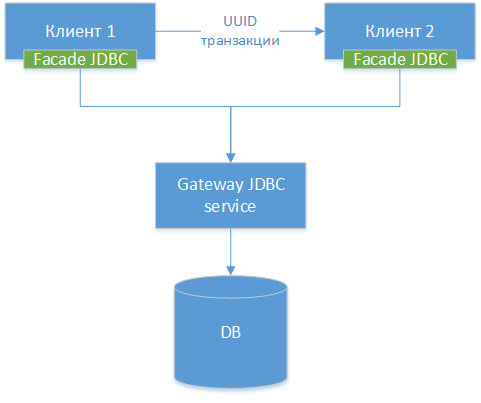 注意!:正如我们所看到的,这三个选项都是相似的,唯一的区别是传输连接的级别以及为此使用的工具。
注意!:正如我们所看到的,这三个选项都是相似的,唯一的区别是传输连接的级别以及为此使用的工具。
之后,我们教驱动程序对方法1中描述的UUID事务进行基本相同的操作。
在Java应用程序代码中,使用此方法可能如下所示。
服务A-交易开始
下面是启动事务,更改数据库并将其传递给另一个服务以完成它的某些服务的代码。 在代码中,我们直接使用JDBC类。 当然,2019年没有人这样做,但是为了简单起见,代码被简化了。
服务B-交易完成
与其他组件和框架的交互
考虑这种架构解决方案可能带来的副作用。
连接池
由于实际上我们将在JDBC网关内部拥有一个真实的连接池-最好关闭服务中的连接池,因为它们将捕获并保留服务内部的连接,该连接可被其他服务使用。
另外,在接收到UUID并等待转移到另一个进程之后,该连接实际上变得不可用,并且从JDBC前端的角度来看,该连接会自动关闭,并且从JDBC网关的角度来看,必须保留该连接而不将其分配给谁将带有所需的UUID。
换句话说,网关JDBC和每个服务中的连接池的双重管理可能会产生细微的,令人不快的错误。
pa
使用JPA,我看到两个可能的问题:
- 交易管理。 提交JPA时,引擎可能会认为它已经保存了所有数据,而尚未保存。 最有可能的是,在传输事务之前进行手动事务管理和flush()应该可以解决问题。
- 二级缓存可能无法正常工作,但是在分布式系统中,无论如何它的使用都受到限制。
春季交易
可能无法激活Spring事务管理机制,您将不得不手动管理它们。 我几乎可以肯定它可以扩展-例如,编写自定义范围-但是可以肯定地说,我们需要研究Spring Transactions扩展在其中的排列方式,但是我还没有看到。
利弊
优点
- 锯切时实际上不需要修改现有的整体代码。
- 您可以编写复杂的跨服务器事务,而几乎没有代码复杂性。
- 允许您对事务执行进行跨服务跟踪。
- 该解决方案非常灵活,您可以在不需要分发的情况下使用经典事务,而仅在需要跨服务交互的那些操作中共享事务。
- 不需要项目团队强行掌握新技术。 新技术固然很好,但是任务-这是当务之急和紧迫的任务(直到昨天!)要向20位开发人员传授构建反应系统的概念-可能并非易事。 但是,不能保证所有20个人都会按时完成培训。
缺点
- 与排队解决方案相比,它在数据库级别不可扩展,并且实际上是非模块化的。 您仍然只有一个数据库,所有查询和整个负载都汇入其中。 从这个意义上讲,解决方案是死胡同:如果以后要增加负载或根据数据使解决方案模块化,则必须重做所有事情。
- 在流程之间,尤其是在框架中编写的流程之间转移事务时,您必须非常小心。 会话具有自己的设置,对于各种框架,与数据库的连接突然更改可能导致错误的操作。 例如,参见PostgreSQL的会话设置和事务。
- 当我在本地建筑师在DataArt上的聊天中说出这个主意时,同事们问我的第一件事就是我是否在喝酒(不,不喝酒!)。 但我承认,这个想法并不是最常见的,如果在项目中实现它,对于其他参与者来说,这将是非常不寻常的。
- 需要自定义的JDBC驱动程序。 编写它需要花费时间,您必须对其进行调试,查找其中的错误,包括由网络通信错误引起的错误等。
警告
我再次警告您:
请勿在本项目中
尝试 在家里 重复此技巧 ,除非您对为什么需要它有非常清楚的解释,并且有说服力的证据表明根本没有其他方法。
从四月一号开始!