该文章以吉加(Jiga)的约翰· 阿克哈尔采夫 (John Akhaltsev)的名义发表
今天的Tinkoff.ru不仅仅是一家银行,它还是一家IT公司。 它不仅提供银行服务,而且围绕它们建立一个生态系统。
我们在Tinkoff.ru与各种服务建立合作伙伴关系,以提高客户服务质量,并帮助改善服务质量。 例如,我们对其中一项服务的负载测试和性能分析进行了分析,这些服务有助于发现系统中的瓶颈-操作系统配置中包括“透明大页面”。
如果您想知道如何对系统性能进行分析以及对我们产生的影响,欢迎与我们联系。
问题描述
目前,服务架构为:
- Nginx Web服务器用于处理HTTP连接
- php-fpm用于php流程控制
- Redis缓存
- PostgreSQL用于数据存储
- 一站式购物解决方案
我们在高负载下一次销售中发现的主要问题是cpu的利用率高,而内核模式下的处理器时间(系统时间)增加了,并且比用户模式下的时间(用户时间)更长。
- 用户时间-处理器花费在用户任务上的时间。 这是购买处理器时要支付的主要费用。
- 系统时间-系统在分页,更改上下文,启动计划任务和其他系统任务上花费的时间。
确定系统的主要特征
首先,我们收集了一个负荷资源接近生产的负荷电路,并编制了与典型一天中的正常负荷相对应的负荷曲线。
选择了Gatling版本3作为脱壳工具,并且脱壳本身是通过gitlab-runner在本地网络内部进行的。 代理和目标在一个本地网络中的位置是由于降低了网络成本,因此,我们专注于验证代码本身的执行,而不是系统所在基础架构的性能。
在确定系统的主要特征时,采用http配置的负载呈线性增加的方案是合适的:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
在此阶段,我们实现了一个脚本来打开主页并下载所有资源。

该测试的结果表明最大性能为1500 rps,负载强度的进一步增加导致与软性时间增加相关的系统性能下降。


Softirq是一种延迟中断机制,在内核/ softirq.s文件中进行了描述。 同时,它们将指令队列打入处理器,从而阻止它们在用户模式下进行有用的计算。 中断处理程序还可以延迟OS线程中网络数据包的其他工作(系统时间)。 简要介绍网络堆栈的工作和优化可在另一篇文章中找到。
没有确认是否怀疑主要问题,因为该产品的系统时间更长,网络活动更少。
用户脚本
下一步是开发自定义脚本并添加其他内容,而不仅仅是打开带有图片的页面。 该配置文件包含大量操作,这些操作完全涉及站点代码和数据库,而不包含提供静态资源的Web服务器。
具有稳定负载的测试从最高强度开始以较低强度启动,并向配置中添加了重定向转换:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
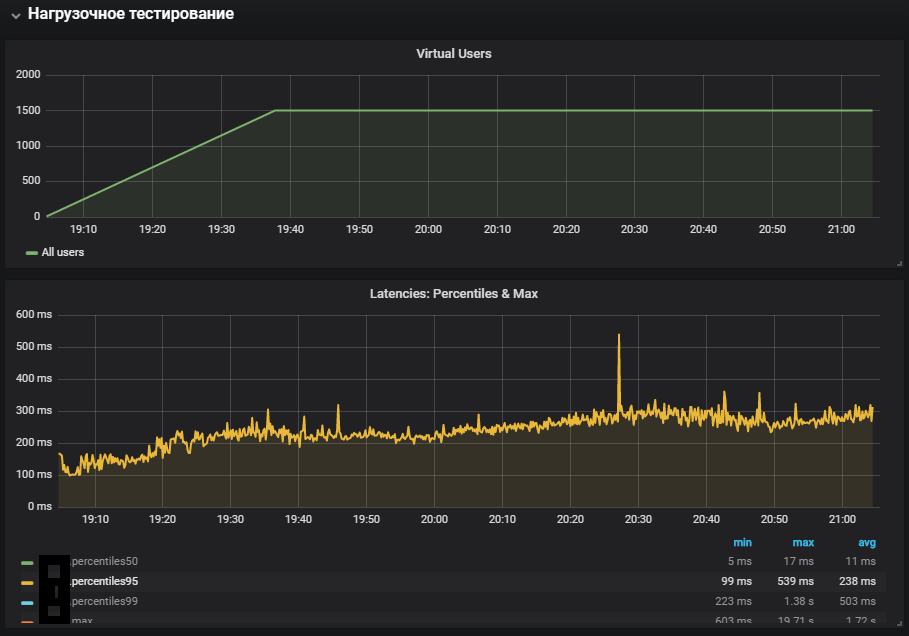

最完整的系统使用显示了系统时间指标的增加,以及在稳定性测试期间的增长。 复制了生产环境的问题。
与Redis联网
在分析问题时,对系统的所有组件进行监视非常重要,以了解其工作方式以及所提供的负载对其有何影响。
随着Redis监视的出现,不再需要查看系统的一般指标,而是查看其特定组件。 压力测试的方案也进行了更改,它与其他监视一起有助于解决问题的本地化。

在监视中,Redis看到了与cpu利用率类似的情况,或者说,系统时间明显比用户时间长,而cpu的主要利用率是在SET操作中,即分配RAM来存储值。

为了消除与Redis进行网络交互的影响,决定测试该假设并将Redis切换到UNIX套接字而不是tcp套接字。 这是在通过php-fpm连接到数据库的框架中完成的。 在文件/yiisoft/yii/framework/caching/CRedisCache.php中,我们用硬代码redis.sock替换了host:port中的行。 在本文中阅读有关套接字性能的更多信息。
protected function connect() { $this->_socket=@stream_socket_client(
不幸的是,这没有太大作用。 CPU利用率略有稳定,但并不能解决我们的问题-大多数CPU利用率是在内核模式下进行的。
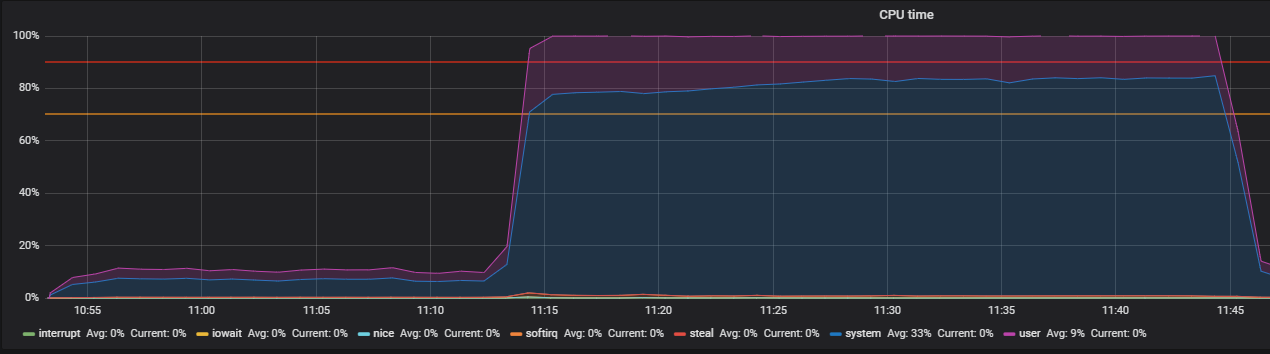
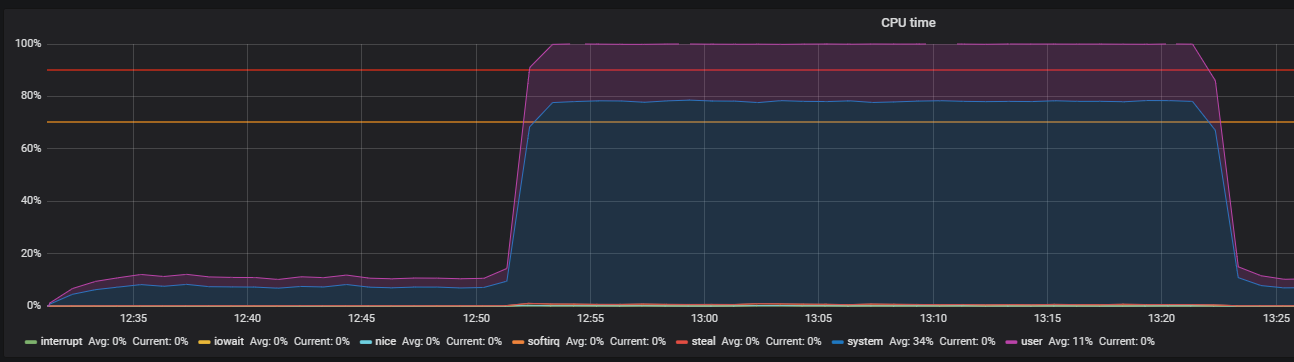
使用压力和识别THP问题进行基准测试
压力实用程序有助于解决问题-一个用于POSIX系统的简单工作负载生成器,它可以加载各个系统组件,例如CPU,内存,IO。
应该在硬件和操作系统版本上进行测试:
Ubuntu 18.04.1 LTS
12个英特尔®至强®CPU
使用以下命令安装实用程序:
sudo apt-get install stress
我们看一下如何在负载下利用CPU,运行一个测试,以创建工时来计算300秒的平方根:
-c, --cpu N spawn N workers spinning on sqrt() > stress --cpu 12 --timeout 300s stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
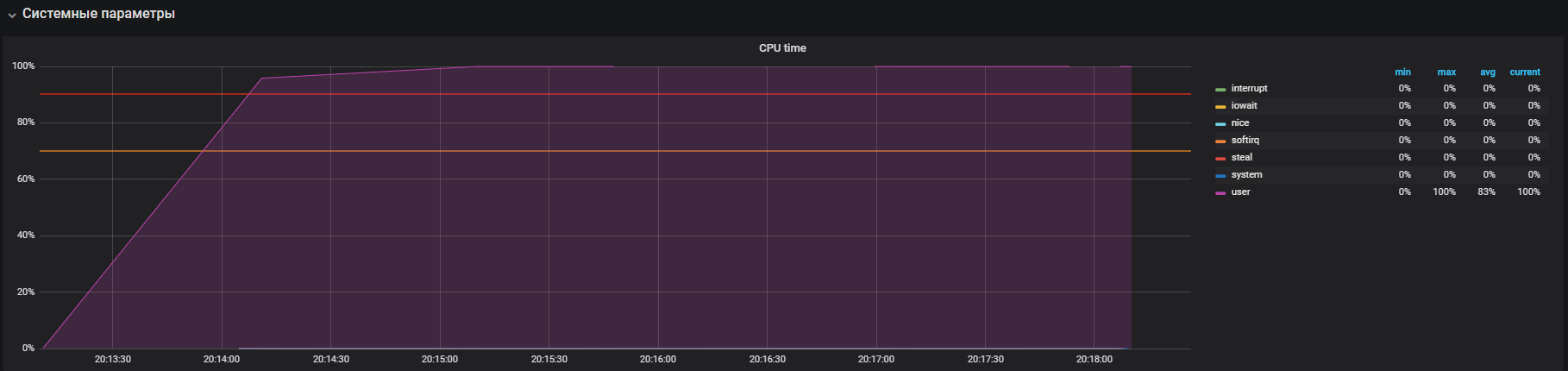
该图显示了用户模式下的完全利用率-这意味着所有处理器内核都已加载并且执行了有用的计算,而不是系统服务调用。
下一步是在深入处理io时使用资源。 创建12个执行sync()的工作程序,以运行300秒的测试。 sync命令将缓冲在内存中的数据写入磁盘。 内核将数据存储在内存中,以避免频繁(通常很慢)的磁盘读写操作。 sync()命令可确保将内存中存储的所有内容都写入磁盘。
-i, --io N spawn N workers spinning on sync() > stress --io 12 --timeout 300s stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd
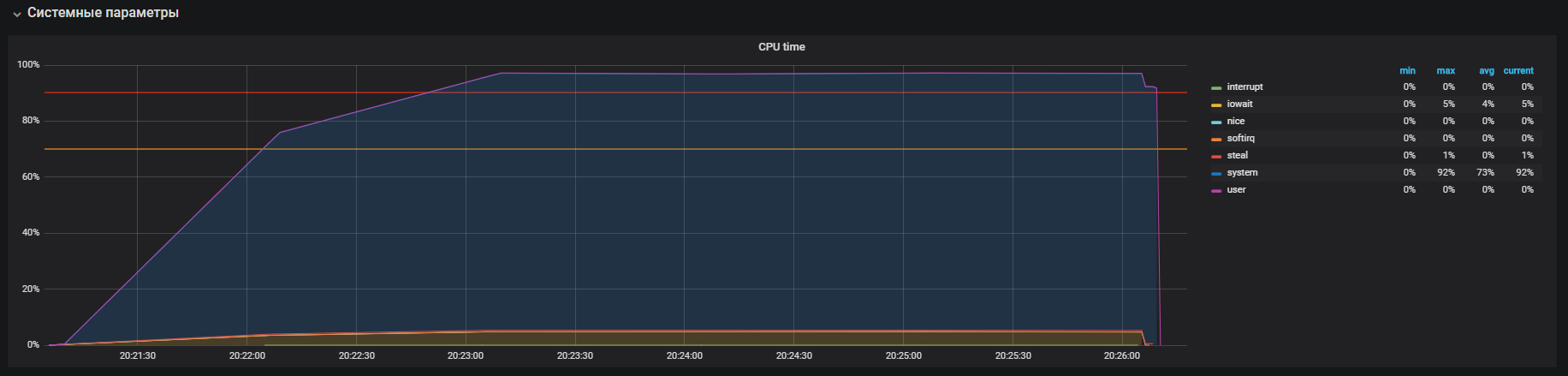

我们看到处理器主要在内核模式下处理调用,而在iowait中则有点处理,您还可以看到> 35k ops写入磁盘。 此行为类似于系统时间过长的问题,我们正在分析其原因。 但是这里有几个差异:iowait和iops分别大于生产电路上的差异,这不适合我们的情况。
现在该检查您的记忆了。 我们启动20个工作人员,他们将使用以下命令分配和释放内存300秒:
-m, --vm N spawn N workers spinning on malloc()/free() > stress -m 20 --timeout 300s stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
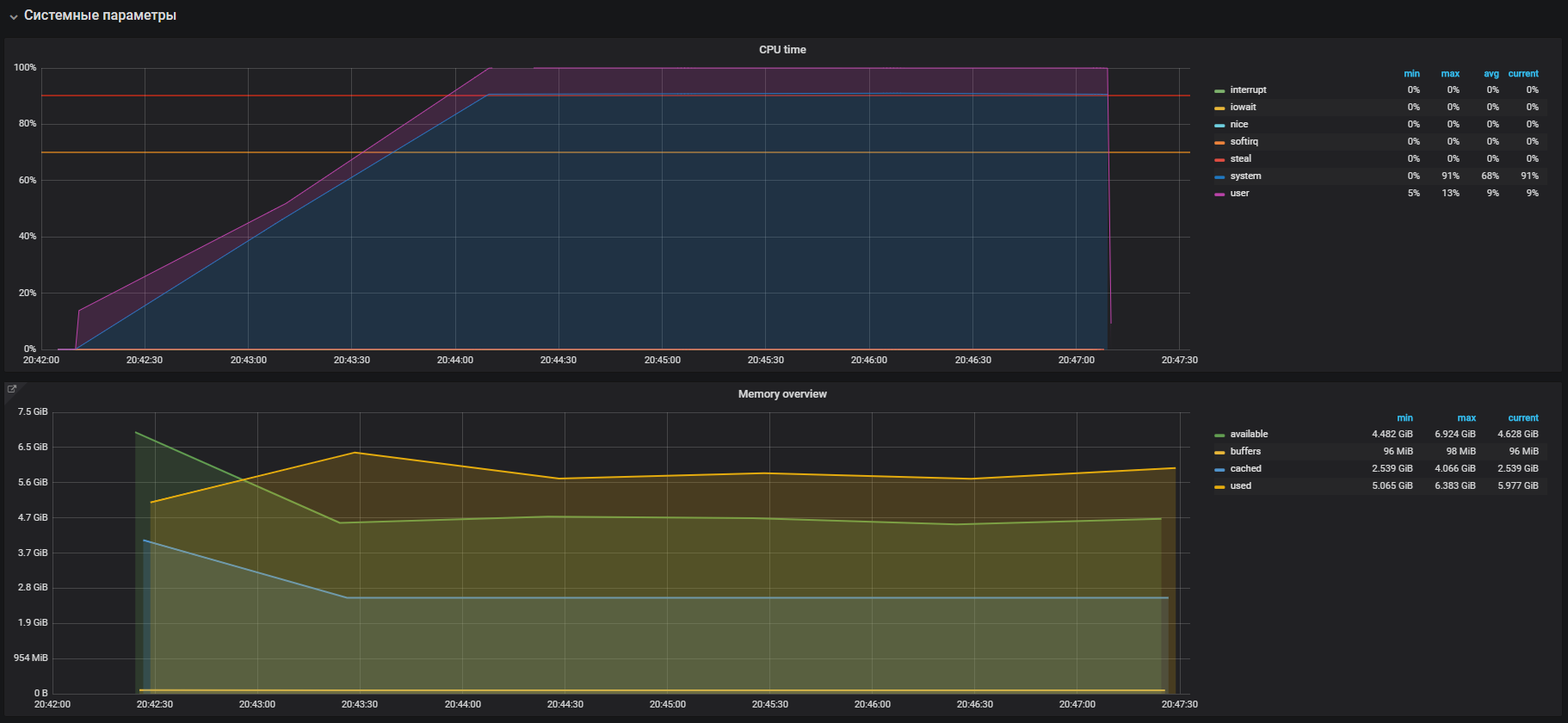
立即我们看到系统模式下CPU的利用率高,而用户模式下CPU利用率高,并且使用的RAM超过2 GB。
这种情况与产品问题非常相似,可以通过在负载测试中大量使用内存来确认。 因此,必须在存储操作中寻找问题。 内存的分配和释放分别使用malloc和free调用进行,它们最终将由内核系统调用处理,这意味着它们将作为系统时间显示在CPU利用率中。
在大多数现代操作系统中,虚拟内存是使用分页来组织的,通过这种方法,整个内存区域被分为固定长度的页面,例如4096字节(许多平台默认),并且在分配例如2 GB的内存时,内存管理器将必须运行超过500,000页。 在这种方法中,管理开销很大,并且大页面和透明大页面技术被发明来减少它们,借助它们的帮助,您可以将页面大小增加到例如2MB,这将显着减少内存堆中的页面数。 技术上的区别仅在于,对于大页面,我们必须显式配置环境并教程序如何使用它们,而透明大页面对于程序是“透明”的。
THP和问题解决
如果您搜索有关“透明大页面”的信息,则可以在搜索结果中看到很多页面,其中包含“如何关闭THP”问题。
事实证明,这个“酷”功能是由Red Hat公司引入到Linux内核中的,其实质是应用程序可以透明地与内存一起工作,就像它们与真正的Huge Page一起工作一样。 根据基准测试,THP将抽象应用程序加速了10%,您可以在演示文稿中看到更多细节,但实际上一切都不同。 在某些情况下,THP会导致系统中CPU消耗的不合理增加。 有关更多信息,请参见Oracle的建议。
我们去检查我们的参数。 事实证明,THP默认情况下处于打开状态,我们使用以下命令将其关闭:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
我们在关闭THP之前以及之后在负载曲线上通过测试进行确认:
setUp( MainScenario.inject( rampUsers(150) during (200 seconds)), Peak.inject( nothingFor(20 minutes), rampUsers(5000) during (30 minutes)) ).protocols(httpConfig)

我们在关闭THP之前观看了这张照片

关闭THP后,我们可以观察到已经降低了资源利用率。
主要问题是本地化。 原因是默认情况下在操作系统中启用的
透明大页面的机制。 禁用THP选项后,系统模式下的CPU使用率至少降低了2倍,从而为用户模式释放了资源。 在分析主要问题时,还发现了与OS和Redis的网络堆栈交互的“瓶颈”,这是进行更深入研究的原因。 但这是一个完全不同的故事。
结论
总之,我想提供一些成功搜索性能问题的技巧:
- 在研究系统性能之前,请仔细了解其体系结构和组件之间的相互作用。
- 为所有系统组件配置监视并跟踪,如果没有足够的标准指标,请更深入并进行扩展。
- 阅读有关二手系统的手册。
- 检查操作系统和系统组件的配置文件中的默认设置。