
正如Radar Technology文章中提到的那样,Lamoda正在积极向微服务架构迈进。 我们的大多数服务都使用Helm打包并部署到Kubernetes。 这种方法在99%的情况下完全可以满足我们的需求。 当标准的Kubernetes功能不够用时(例如,当您需要为特定事件配置备份或更新服务时),剩余1%。 为了解决这个问题,我们使用运算符模式。 在本系列文章中,I- Gmodory Mikhalkin(拉莫达研发团队的开发人员)将讲述我从使用操作员框架开发K8s操作员的经验中学到的经验教训。
什么是运算符?
扩展Kubernetes功能的一种方法是创建自己的控制器。 Kubernetes中的主要抽象是对象和控制器。 对象描述集群的期望状态。 例如,一个Pod描述了需要启动哪些容器以及启动参数,而ReplicaSet对象告诉您需要启动给定Pod的多少个副本。 控制器基于对象的描述来控制群集的状态,在上述情况下, ReplicationController将支持ReplicaSet中指定的Pod副本的数量。 借助新的控制器,您可以实施其他逻辑,例如发送事件通知,从故障中恢复或管理第三方资源 。
操作员是一个kubernetes应用程序,它包含一个或多个为第三方资源提供服务的控制器。 该概念由CoreOS团队于2016年发明 ,最近,运营商的知名度迅速增长。 您可以尝试在kubedex的列表 (此处列出了100多个公共可用的运算符)以及OperatorHub 上的列表中找到所需的运算符 。 有3种流行的用于操作员开发的工具: Kubebuilder , Operator SDK和Metacontroller 。 在Lamoda中,我们使用Operator SDK,因此稍后再讨论。
运营商SDK
Operator SDK是Operator Framework的一部分,该框架包括两个重要部分:Operator Lifecycle Manager和Operator Metering。
创建一个新项目
一个示例是操作员,该操作员监视资源库中带有config的文件,并在更新后重新启动具有新config的服务的部署。 完整的示例代码可在此处获得 。
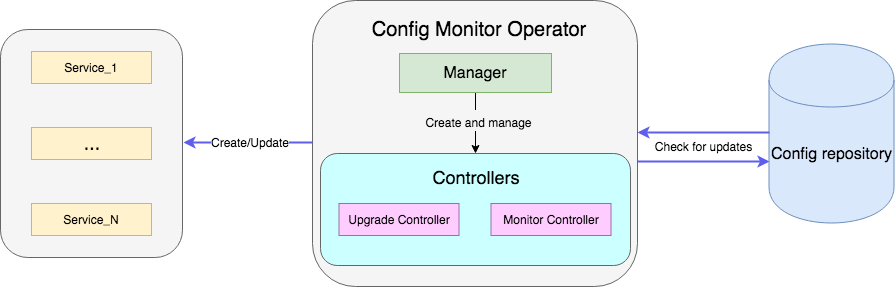
使用新的运算符创建项目:
operator-sdk new config-monitor
代码生成器将为在分配的名称空间中工作的操作员创建代码。 此方法优于提供对整个群集的访问权限,因为在发生错误的情况下,问题将被隔离在同一名称空间内。 可以通过--cluster-scoped添加--cluster-scoped生成cluster-wide运算符。 以下目录将位于创建的项目内:
- cmd-包含
main package ,在该main package中初始化和启动Manager ; - deploy-包含操作员,CRD的声明以及设置RBAC操作员所需的对象;
- pkg-这将是我们新对象和控制器的主要代码。
cmd/manager/main.go只有一个cmd/manager/main.go文件。
程式码片段 // Become the leader before proceeding err = leader.Become(ctx, "config-monitor-lock") if err != nil { log.Error(err, "") os.Exit(1) } // Create a new Cmd to provide shared dependencies and start components mgr, err := manager.New(cfg, manager.Options{ Namespace: namespace, MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort), }) ... // Setup Scheme for all resources if err := apis.AddToScheme(mgr.GetScheme()); err != nil { log.Error(err, "") os.Exit(1) } // Setup all Controllers if err := controller.AddToManager(mgr); err != nil { log.Error(err, "") os.Exit(1) } ... // Start the Cmd if err := mgr.Start(signals.SetupSignalHandler()); err != nil { log.Error(err, "Manager exited non-zero") os.Exit(1) }
在第一行中: err = leader.Become(ctx, "config-monitor-lock") -选择了一个领导者。 在大多数情况下,仅需要一个关于名称空间/集群的活动实例。 默认情况下,Operator SDK使用Leader生命策略-运营商的第一个启动实例将一直保持Leader身份 ,直到将其从集群中删除为止。
在指定该操作员实例为领导者之后,将初始化一个新的Manager - mgr, err := manager.New(...) 。 他的职责包括:
err := apis.AddToScheme(mgr.GetScheme()) -新资源方案的注册;err := controller.AddToManager(mgr) -控制器注册;err := mgr.Start(signals.SetupSignalHandler()) -启动并控制控制器。
目前,我们既没有新资源,也没有注册控制者。 您可以使用以下命令添加新资源:
operator-sdk add api --api-version=services.example.com/v1alpha1 --kind=MonitoredService
此命令会将MonitoredService资源模式定义添加到pkg/apis目录中,并将yaml和CRD定义添加到deploy/crds 。 在所有生成的文件中,您应该只手动更改Monitoredservice_types.go中的架构定义。 MonitoredServiceSpec类型定义资源的所需状态:用户在yaml中使用资源定义指定的内容。 在我们的操作员的上下文中,“ Size字段确定所需的副本数,“ ConfigRepo指示可以从中提取当前配置的位置。 MonitoredServiceStatus确定观察到的资源状态,例如,它存储属于该资源的Pod的名称和当前spec Pods。
编辑方案后,需要运行以下命令:
operator-sdk generate k8s
它将更新deploy/crds的CRD定义。
现在,让我们创建运算符的主要部分,即控制器:
operator-sdk add controller --api-version=services.example.com/v1alpha1 --kind=Monitor
monitor_controller.go文件将出现在pkg/controller monitor_controller.go ,我们在其中添加了所需的逻辑。
控制器开发
控制器是操作员的主要工作单位。 在我们的例子中,有两个控制器:
- 监视控制器监视服务配置更改;
- 升级控制器更新服务并将其维持在所需状态。
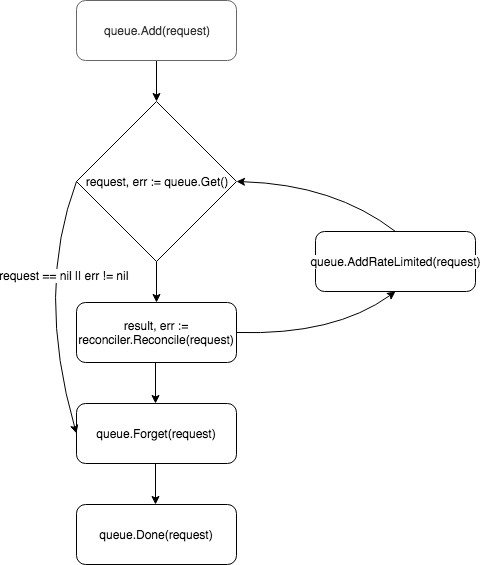
控制器的核心是一个控制循环,它监视队列及其订阅的事件并进行处理:
管理员在add方法中创建并注册了一个新控制器:
c, err := controller.New("monitor-controller", mgr, controller.Options{Reconciler: r})
使用Watch方法,我们将其订阅与创建新资源或现有MonitoredService资源的Spec更新有关的事件:
err = c.Watch(&source.Kind{Type: &servicesv1alpha1.MonitoredService{}}, &handler.EnqueueRequestForObject{}, common.CreateOrUpdateSpecPredicate)
可以使用src和predicates参数配置事件的类型。 src接受Source类型的对象。
apiserver Informer -定期轮询apiserver以查找与过滤器匹配的事件,如果存在此类事件,则将其放入控制器的队列中。 在controller-runtime这是来自client-go的SharedIndexInformer的包装。Kind还是SharedIndexInformer的包装器,但是与Informer不同,它是根据传递的参数(受监视资源的方案)独立创建一个告密实例。chan event.GenericEvent接受chan event.GenericEvent作为参数,通过它传递的事件放置在控制器的队列中。
redicates期望满足Predicate接口的对象。 实际上,这是事件的附加过滤器,例如,在过滤UpdateEvent您可以确切地看到对资源spec进行了哪些更改。
当事件到达时, EventHandler接受它EventHandler方法的第二个参数-它以Reconciler期望的请求格式包装事件:
EnqueueRequestForObject使用导致事件的对象的名称和名称空间创建请求;EnqueueRequestForOwner使用对象的父对象的数据创建请求。 例如,如果已删除资源控制的Pod ,并且您需要开始对其进行替换,则这是必需的。EnqueueRequestsFromMapFunc将接收事件(包装在MapObject )并返回请求列表的map函数作为参数。 一个需要此处理程序的示例 -有一个计时器,您需要为每个滴答计时器拨出所有可用服务的新配置。
请求被放置在控制器队列中,并且其中一个工作器(默认情况下,控制器有一个)将事件从队列中拉出并将其传递给Reconciler 。
协调器仅实现一种方法- Reconcile ,其中包含事件处理的基本逻辑:
和解方法 func (r *ReconcileMonitor) Reconcile(request reconcile.Request) (reconcile.Result, error) { reqLogger := log.WithValues("Request.Namespace", request.Namespace, "Request.Name", request.Name) reqLogger.Info("Checking updates in repo for MonitoredService") // fetch the Monitor instance instance := &servicesv1alpha1.MonitoredService{} err := r.client.Get(context.Background(), request.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } // check if service's config was updated // if it was, send event to upgrade controller if podSpec, ok := r.isServiceConfigUpdated(instance); ok { // Update instance Spec instance.Status.PodSpec = *podSpec instance.Status.ConfigChanged = true err = r.client.Status().Update(context.Background(), instance) if err != nil { reqLogger.Error(err, "Failed to update service status", "Service.Namespace", instance.Namespace, "Service.Name", instance.Name) return reconcile.Result{}, err } r.eventsChan <- event.GenericEvent{Meta: &servicesv1alpha1.MonitoredService{}, Object: instance} } return reconcile.Result{}, nil }
该方法接受带有NamespacedName字段的Request对象,可以通过该对象从缓存中拉取资源: r.client.Get(context.TODO(), request.NamespacedName, instance) 。 在该示例中,使用资源spec ConfigRepo字段引用的服务配置对文件进行请求。 如果配置已更新,则会GenericEvent类型的新事件并将其发送到Upgrade控制器侦听的通道。
处理请求后, Reconcile返回Result和error类型的对象。 如果Result字段为Requeue: true或error != nil ,则控制器将使用queue.AddRateLimited方法将请求返回到队列。 该请求将延迟返回到队列,该延迟由RateLimiter确定。 默认情况下,使用ItemExponentialFailureRateLimiter ,它随着请求“返回”次数的增加而指数增加延迟时间。 如果未设置Requeue字段,并且在处理请求期间未发生错误,则控制器将调用Queue.Forget方法,该方法将从RateLimiter缓存中删除请求(从而重置返回数)。 在请求处理结束时,控制器使用Queue.Done方法将其从队列中删除。
运营商启动
上面描述了操作员的组件,仍然存在一个问题:如何启动它。 首先,您需要确保安装了所有必需的资源(对于本地测试,我建议设置minikube ):
# Setup Service Account kubectl create -f deploy/service_account.yaml # Setup RBAC kubectl create -f deploy/role.yaml kubectl create -f deploy/role_binding.yaml # Setup the CRD kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_crd.yaml # Setup custom resource kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_cr.yaml
满足先决条件后,有两种简单的方法可以运行语句进行测试。 最简单的方法是使用以下命令在集群外部启动它:
operator-sdk up local --namespace=default
第二种方法是在集群中部署操作员。 首先,您需要使用运算符构建Docker映像:
operator-sdk build config-monitor-operator:latest
在deploy/operator.yaml文件中,将REPLACE_IMAGE替换为config-monitor-operator:latest :
sed -i "" 's|REPLACE_IMAGE|config-monitor-operator:latest|g' deploy/operator.yaml
使用以下语句创建部署:
kubectl create -f deploy/operator.yaml
现在,在群集上的Pod列表中,应该显示带有测试服务的Pod ,在第二种情况下-另一个带有操作员的Pod 。
而不是结论或最佳做法
当前,操作员开发的关键问题是工具的文档薄弱以及缺乏既定的最佳实践。 当新开发人员开始开发操作员时,他无处可去实际地研究实现特定需求的示例,因此错误是不可避免的。 以下是我们从错误中学到的一些教训:
- 如果有两个相关的应用程序,则应避免将它们与单个运算符组合的愿望。 否则,将违反松散耦合服务的原则。
- 您需要记住有关关注点分离的问题:您不应尝试在一个控制器中实现所有逻辑。 例如,值得散布监视配置和创建/更新资源的功能。
- 在
Reconcile方法中应避免阻塞调用。 例如,您可以从外部来源提取配置,但是如果操作较长,请为此创建一个goroutine,然后将请求发送回队列,并在响应中Requeue: true 。
在评论中,很高兴听到您在开发操作员方面的经验。 在下一部分中,我们将讨论操作员测试。