
我是Yandex.Money的首席Java开发人员。
在2018年的每个工作早晨,约有30个请求请求都在等待我进行审查,而我一天没有足够的时间对所有请求进行排序。 暑假结束时,我去度假,回到家后,我发现分配给我50个PR。 没必要耙他们,但实际上,这只是我亲眼所见的冰山一角。 那天我决定是时候改变一些东西了。
这是关于我们如何加速代码审查,卸载领先的开发人员并改进我们每天使用的工具的故事。
代码审查1.0。 以前怎么样
在Yandex.Money中,代码审查长期以来一直是强制性的开发阶段,并且每个人都早已习惯了它。 一些人意识到这和测试一样重要。 其他人则认为这是必不可少的弊端,而某人仅在请求请求的作者时遇到过代码审查,但回避了对他人代码的审查。 我认为许多人从最后到第一个依次旅行,这是正常的。
为了进行代码审查,我们从一开始就使用Bitbucket。 对于每个组件存储库,添加了3-4个默认审阅者的列表,这些审阅者已添加到所有PR中。 通常,此列表是由部门负责人编辑和编辑的,有时还会在此添加想要查看特定组件的志愿者。 在库存储库中,它要容易一些-所有库的审阅者列表相同,并且其中包括高级开发人员。
结果,考虑到部门增长到60人,存储库数量增加(60个以上组件,100个以上库)以及CI / CD的加速,几乎所有的负担都落在了高级开发人员中的审阅者身上。高级开发人员逐渐变得不够用了。
除了繁重的工作量和审查者缺乏资源外,还有其他问题:
- 在某些方面,人们可能会期望审核者反应超过一天,
- 被任命为审稿人的人员在多个方面的工作量很大,
- 很难吸引新的评论者,包括由于上一段,
- 如果主要审核者生病或休假,则组件的时间代码审核开始明显增加,
- 指定的审阅者并不总是在组件方面拥有真正的专业知识,因此,代码审阅的质量受到了影响。
解决这些问题之前,您需要确定我们通常对代码审查的期望。
正确的代码审查是如何?
我们在更新的代码审查中确定了四点:
- 验证解决方案体系结构 。 很明显的事情。 我们希望具有此组件专业知识的高级开发人员对此有所期待。
- 技术实施的验证 ,我们也希望具有该组件专业知识的高级和中级专家。
- 知识的转移 ,包括初学者和六月通过代码审查研究业务逻辑和代码库。
- 能够评估开发人员的硬技能 。 我希望为每个开发人员分配一位评估成长,确定开发载体,注意到一些缺点,发表评论等等的导师。 因此,指导者还应该查看其病房的代码。
也许有人看到其他目标或不同意我们的目标-在评论中分享。 同时,我将从拟定目标转向寻找实现目标的方法-我们决定我们要(几乎)立即实现所有目标。
代码审查2.0。 怎么了
我们想到了什么? 我们开始逐步进行推理。
在Yandex.Money中,开发人员在业务领域的团队中工作,通常是团队中的2-4个后端开发人员。
假设我要打开一个请求请求,即我是它的作者 。 我有我的团队 ,他们的开发人员非常了解我正在做的业务逻辑,因为我们所有人都参与共同的项目,通常会同步并且通常会积极地进行交互。 因此,我想首先将它们添加到我的请求中,以便它们至少与我的工作保持最新。
Yandex.Money中的每个组件都有一个负责并在生产中陪同的团队。
如果我修改了另一个团队负责的组件,那么将这个团队的开发人员添加到审阅者中似乎是合乎逻辑的-他们负责该组件,并且必须监视其代码质量。 但是为了不让审稿人超载,我们只从这支团队中随机选一个人-我们认为这已经足够。
负责该组件的团队可能没有足够的专业知识。 当新来者出现在团队中或他们只是在最近才被委托使用此组件时,就会发生这种情况。 但是,我知道我们在该存储库中拥有该公司的真正专家,并且如果其中一位查看我的代码,那就太好了! 当然,我的知识很难形式化,但是您可以获取存储库的历史记录并通过PR和统计信息的数量来计算代码审查,而PR和统计人员对此代码进行了大量工作和/或进行了大量审查。 我们在存储库中计算专业技能指标,选择该指标的顶级开发人员,称他们为专家,然后向审阅者添加一名随机专家。
在2018年,我们在公司中引入了指导老师,因此现在高级开发人员中的一位指导老师正在观察每个团队。 同样,公司的每个新来者都首先有一位私人导师。
让我的导师看我的代码! 如果有代码审查方面的问题,他将能够提供帮助,并且对我在技术技能方面的优缺点有一个了解。
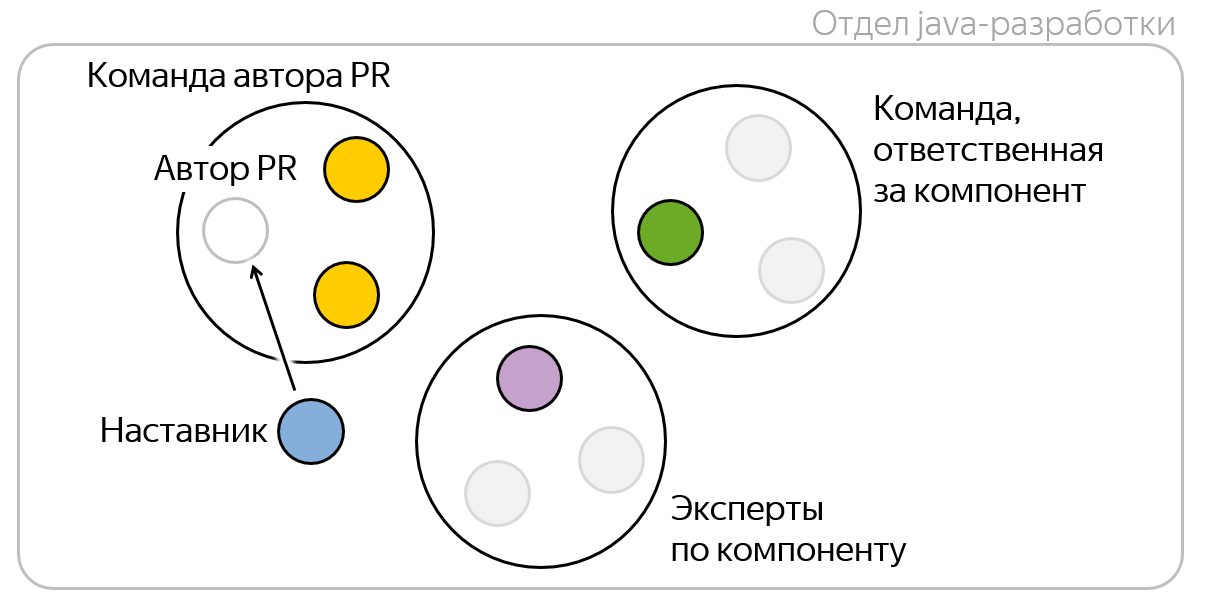
每个拉取请求的审阅者总共可以添加五到六个人。 但实际上,通常它们会稍小一些,因为可以将一个人组合在一起担任不同的角色。 我的导师可以同时是专家,而我的团队可以负责该组件。 从主观上来说,3-4个审阅者对于拉动请求是最佳的。
代码审查2.0。 到底是什么?
重点不大:使其全部正常工作。 这有助于我们所有的阵容都已经在一个单独的系统中进行了设置,该系统提供了用于接收它们的REST API。 因此,在业余时间进行了几周的闲暇开发之后,Bitbucket的第一个插件版本诞生了,该版本逐渐开发并在秋季获得了所有必要的功能。
插件如何工作
通常,在创建PR时,Bitbucket会预填充项目或存储库设置中指定的查看器。 从用户的角度看,这里没有任何变化-打开此页面时,所有审阅者也会预先填充,只是添加了一个字段并描述了哪个审阅者以什么角色被添加。 审稿人的角色如下:
- teammate是PR作者团队的成员,由于REST API具有团队组成,因此很容易添加
- 资源库所有者-负责组件的团队的随机成员; 在存储库设置中,必须有机会选择负责的团队,
- 知识库专家-随机知识库专家; 我稍后会告诉你更多
- 指导者-团队或初学者的指导者,也可以通过REST API从具有团队组成的服务中获得。
仓库专家
我会告诉您更多有关我们如何考虑专家的信息。 每天,插件都会遍历所有存储库,查看去年的所有拉取请求,并考虑两个简单的指标:
- 开发人员创建的拉取请求的数量,
- 他审核并设定的PR数量,需要工作或拒绝的PR。
我们基于以下事实为这些度量标准增加权重:从代码专业知识的角度来看,此代码的改进比审查更重要。 首先,我们估计创建的拉取请求的数量比审阅的重要性大半倍,然后将比率提高到三比一。 我们总结指标乘以指标权重,得出开发者评级。
接下来,我们按评分对所有这些开发人员进行排序,并一路选择前5名,以将评分低于阈值的开发人员排除在外,以减少不经意的路人。 每个存储库通常需要三到五位专家。
上面,我向您介绍了选择和实施审阅者的方法,但是在此过程中,我们一次实施了一些小改进,这使代码审阅过程变得更快,更方便,更愉快。
禁止合并拉取请求,直到在Jira中检查任务为止
如此明显而必要的事情,不幸的是,并非开箱即用。 我们只能在开发人员中获得稳定的代码,这些代码不仅通过了静态检查和开发人员测试,还通过了集成测试以及其他服务。 对我们而言,此类测试的状态仅反映在Jira任务中,因此,在此之前,开发人员必须手动查看是否已检查任务以减慢请求请求的速度。
自动合并拉取请求
拉动请求可以在相当多的时间里度过他的一生,在这种状态下,任何时间都无法阻止他花费时间,但是一个人会忘记这样做或不会立即这样做。 一个引人注目的例子是测试任务的期望,否则我们就不会将其保留在开发人员中。 这是自动合并很方便的地方,它根据一个简单的原理起作用:如果PR可以被冻结,那么我们就可以做到。
合并涵盖了所有必要的合并条件。 我们检查程序集是否成功,测试覆盖范围的水平,是否缺少库的快照依存关系,Jira中任务的状态以及是否存在所有必要的更新。 也就是说,我们拥有使用该功能的所有功能,并且从通过代码审阅并将任务提交给测试的那一刻起就无需考虑PR(除非QA在其中发现问题)。
我们以一种非常方便的方式实现了这一点:我们引入了一个特殊的AutoMergeBot机器人,只需将其添加到审阅者中,以便它可以开始监视此拉取请求并在需要时冻结它。
考虑到没有审稿人
如果组件所有者或专家正在休假或请病假,则审阅者不会将其添加,并且其职位将由在工作场所的人代替。 额外的好处是,离开度假者后,其他人的大量请求不会落在该审阅者身上。 要意识到这一点并不困难,因为事实上,与我们在一起的所有员工短缺都是在Jira提出的。
聘请审核员的会计
有人每天评论十个PR,有五个。 有人已经积累了20个未查看的PR,而有人却几乎没有。 我们将所有这些因素都考虑在内,以便更平均地分配审阅者的工作量。 负载越大,添加到新PR中的次数就越少-一切都很简单。
创建时标记PR尺寸
在拉取请求创建页面上,作者可以选择其近似大小:S,M或L。这有助于审阅者估计他们将花费在代码审阅上的大概时间。 例如,我有5分钟的空闲时间,并且我知道我可以设法看到大小请求拉取请求S.打开M或L没有意义,因为我没有时间观看它们,而下次我将不得不从头开始。
将来,我们希望在计算PR统计信息时考虑这些属性。
标签紧急公关
同样,在创建PR时,作者可以通过在PR名称中添加这样的符号来表明任务非常紧急。 评论者会立即看到它,并将尝试首先看到它。 这似乎是一件小事,但非常有用和方便。
跟踪开始和结束代码审查
如果在改进过程的过程中无法了解它已经改进了多少,那么就没有开始的意义。
代码审查也是如此-我们可以尝试尽可能地对其进行改进,但是如果没有指标和统计数据,我们如何才能确保积极的发展呢? 对于我们而言,这不是最简单的任务-开箱即用,Bitbucket和Jira并没有提供跟踪代码审查时间的机会。 我们仅使用了PR寿命指标,这不太适合我们,因为我们仅在任务测试完成后才请求请求,因此该指标中混合了无关紧要的指标。
Jira存储并允许您上载任务生命周期的所有控制点,因此我们认为用两个附加标签丰富此数据是正确的:代码审查的开始和结束时间。 只需要教Bitbucket插件在Jira中推送这些标签即可。 因此,Jira过去(现在)仍然是该任务的单一事实点,通过此数据集,我们可以将代码检查的时间与测试任务的时间分开。
这里最薄的地方是如何确定何时结束代码审查? 也许是时候获得第一个应用程序,也许是最后一个应用程序,或者这是PR作者最后更改的时间? 我没有这个问题的答案,在这里,我只需要在彼此之间达成共识,然后选择一件事或用指标涵盖所有三个事件并遵循偏差即可。
跟踪审阅者的下载
另一个有用的指标是审阅者的工作量。 正如我在上文所述,在将审阅者分配给新的PR时,我们会考虑到这一点,但我们也会发布此信息,以监视团队,部门或公司的动态。 有时这有助于发现异常情况和潜在问题:如果很明显一个团队中的一个或多个人每天悬挂10个或更多未查看的PR,则有理由找出一切是否正常。
查看Grafana中的指标
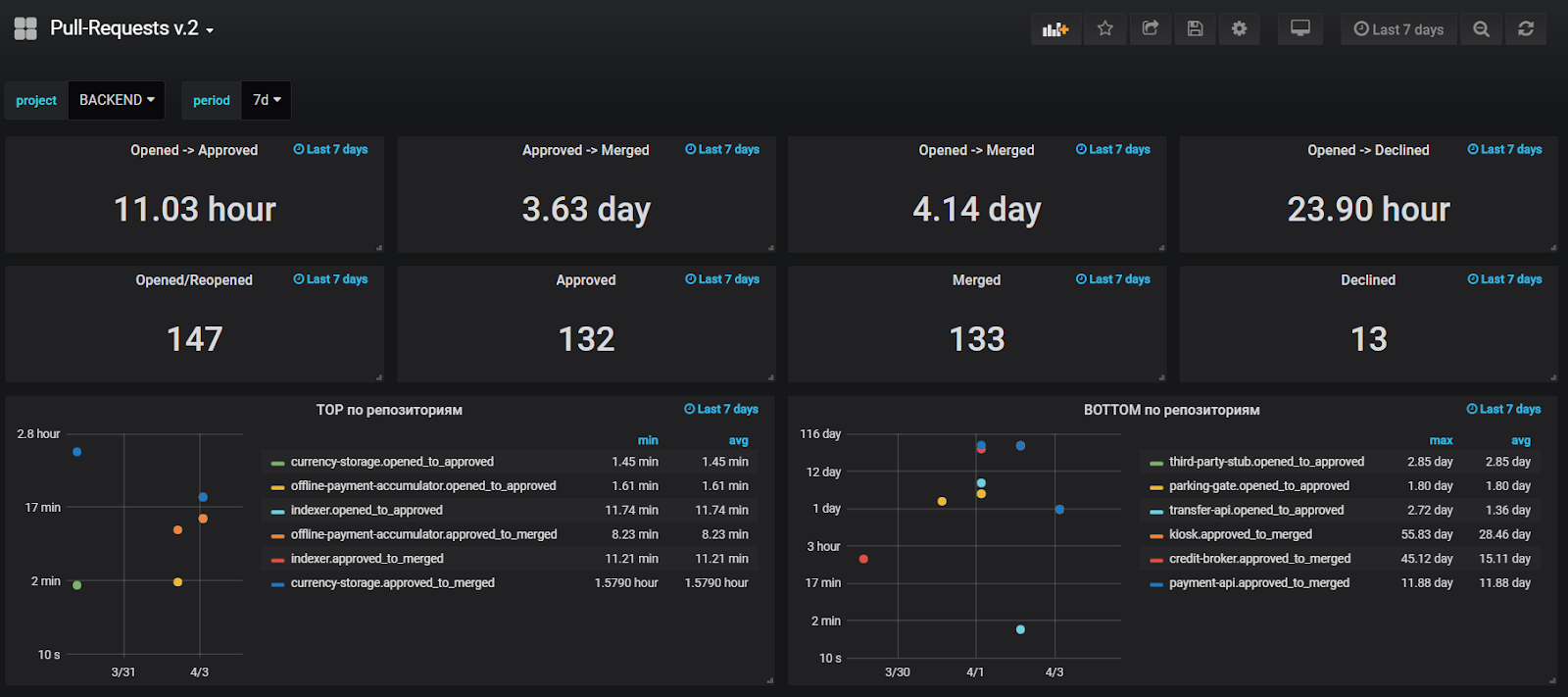
基于Jira的数据生成报告很有用,但不是很方便,因此我们还添加了针对StatsD中主要事件的指标发送,以便在Grafana中基于操作数据构建图形。 我们监控直到第一次测试的平均时间,PR的平均寿命,并查看这些指标的异常值,以便快速发现并解决问题。
在撰写本文时,我们的仪表板如下所示:
你到底得到了什么?
不幸的是,我们都有很强的后见之明,因此我们在流程本身开始变化之前(2018年9月至10月)没有引入上述代码审查指标,但是已经在进行中,因此我们只能可靠地跟踪2018年12月开始的改进或恶化情况。我们设法注意到了什么?
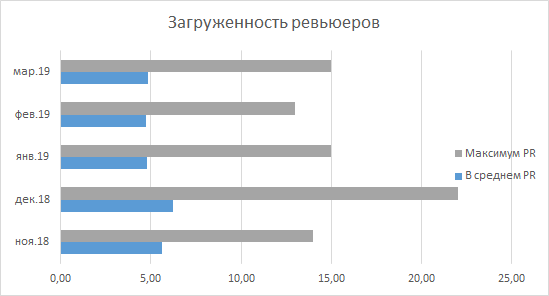
首先引起您注意的是减轻了高级审阅者的负担,我以我自己的榜样感到如此。 正如我已经提到的那样,早上看到大约30个PR是正常的,但是现在这个数字在10到15之间波动。该部门的统计数据证实了这一点:自2018年12月以来,没有人提出等待审查的PR的最大数量高于15。平均而言,我们观察到的图片表明,每个开发人员平均预期早上会有4-5个未查看的PR,这似乎是一个足够的数字。
至于选择审查者和代码审查质量的相关性,我们只能依靠主观指标。 根据同事的民意测验,我们真的开始获得了很多优秀的审稿人,现在没有人需要手动添加,也没有任何PR被遗忘和遗忘。
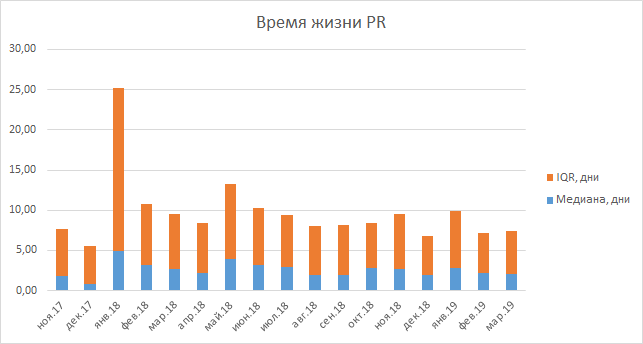
如果我们谈论通过代码审查所花费的时间,那么现在就计算该指标的统计信息还为时过早,因为我们是最近才开始收集它的。 在我们的处置中,只有拉取请求的生命周期,实际上并没有上升或下降。 该指标包括测试任务的时间,因此很难就此得出清晰的结论,此外,更改了审核代码,我们没有将其延长。