随着许多不同的神经网络体系结构的出现,许多经典的计算机视觉技术已成为过去。 人们越来越少地使用SIFT和HOG进行对象检测,使用MBH进行动作识别,如果使用它们,则更像是为相应网格制作的手工标志。 今天,我们将探讨经典的CV问题之一,在经典的CV问题中,经典的方法仍然占据主导地位,而DL体系结构则懒洋洋地将它们吸入头部。

光流估计
计算两个图像之间(通常是视频的相邻帧之间)的光流的任务是构造一个矢量场
同样大小
将对应于视在像素位移矢量
从第一帧到第二帧。 通过在视频的所有相邻帧之间构造这样的矢量场,我们可以获得某些对象如何在视频上移动的完整图片。 换句话说,这是跟踪视频中所有像素的任务。 光学流的使用极为广泛-例如,在动作识别任务中,此类矢量场使您可以专注于视频上发生的运动并远离其上下文[7]。 视觉测距,视频压缩,后处理(例如,添加慢动作效果)等更常见的应用。

存在一些模棱两可的余地-从数学的角度来看,什么才算是可见的偏差? 通常,假定像素值从一帧到下一帧没有变化,换句话说:
在哪里
-坐标中的像素强度
然后光流
显示此像素已移至下一个时间点的位置(即下一帧)。
在图片中看起来像这样:


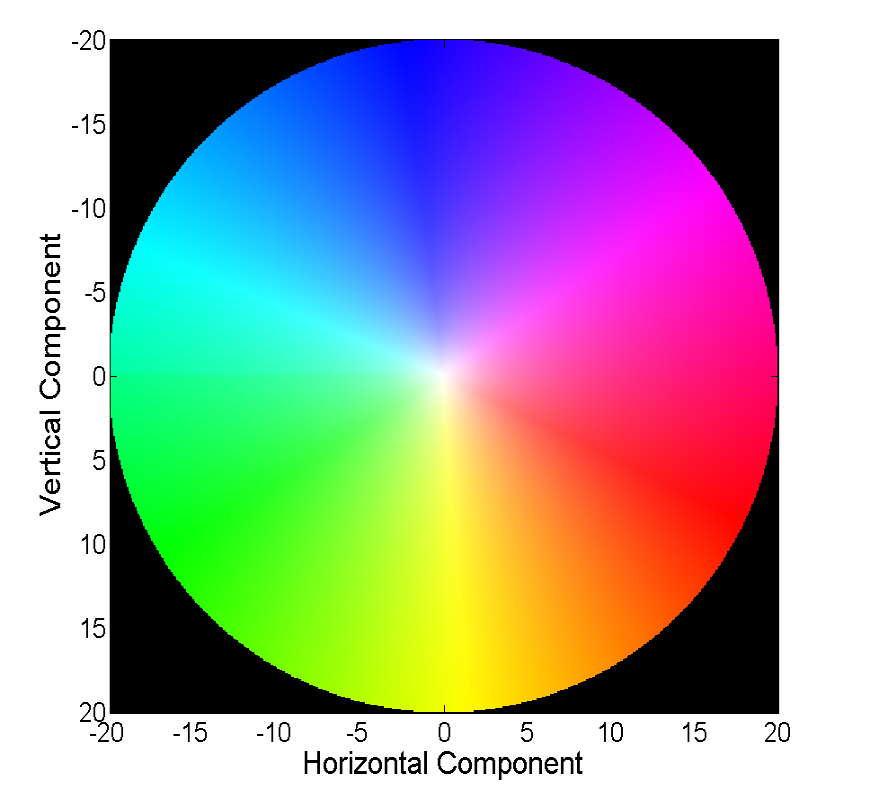
用向量直接可视化向量字段是可视的,但并不总是方便的,因此第二种常见方法是使用颜色可视化:


该图片中的每种颜色编码一个特定的向量。 为简单起见,裁剪了长度超过20的矢量,并且可以通过颜色从下图中恢复矢量本身:
古典方法已经达到了相当好的精度,有时要付出代价。 我们将考虑过去4年中神经网络在解决此问题方面所取得的进展。
数据和指标
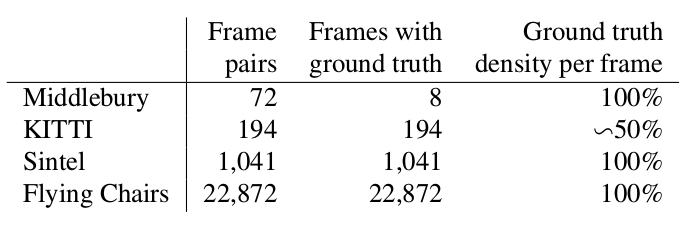
在我们的故事开始时(即2015年),用两个词来说明哪些数据集可用并广受欢迎,以及它们如何衡量所得算法的质量。
米德尔伯里
一个由8对具有小偏移量的图像组成的微小数据集,尽管如此,有时甚至仍在验证算法中使用该数据集来计算光通量。

小猫咪
这是为自动驾驶汽车应用标记的数据集,并使用LIDAR技术进行了组装。 它被广泛用于验证光流计算算法,并且包含许多相当复杂的情况,并且帧之间存在急剧的过渡。

辛特尔
另一个非常常见的基准,是在公开基础上创建的,并以Blender动画片Sintel绘制为两个版本,分别指定为“干净”和“最终”。 第二个要复杂得多,因为 计算光通量的算法包含许多大气效应,噪声,模糊和其他问题。
珍珠棉
光流计算任务的标准误差函数是端点误差或EPE。 这只是在所有像素上平均的计算算法与真实光通量之间的欧几里得距离。
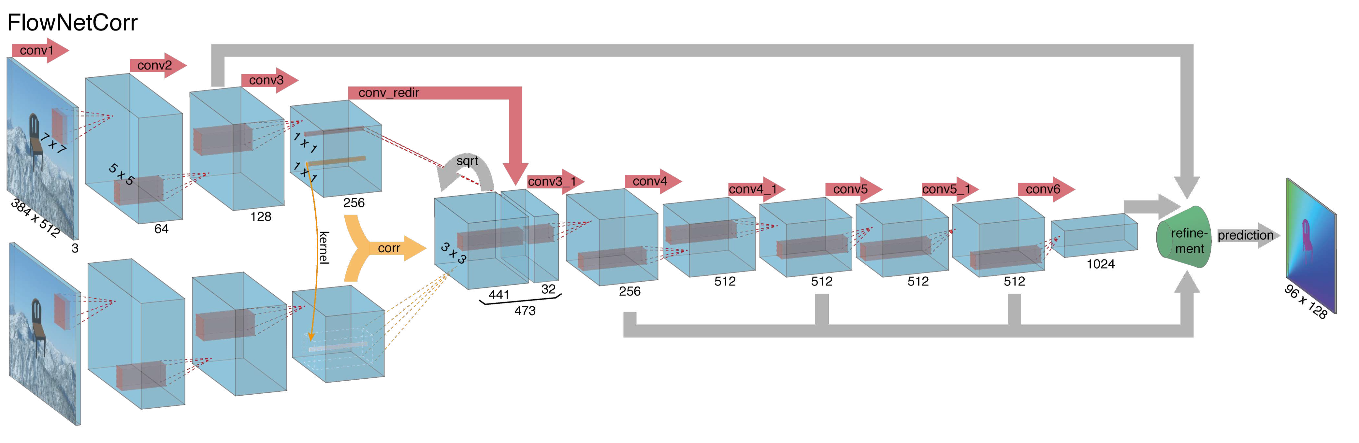
Flownet(2015年)
早在2015年开始为计算光通量而着手构建神经网络架构时,作者(来自慕尼黑大学和弗莱堡大学)就面临两个问题:该任务没有大量标记的数据集,而手动标记则很困难(尝试标记我的移动位置)下一帧图像的每个像素)。 此任务与之前借助CNN架构解决的所有任务有很大不同。 实际上,这是逐像素回归的任务,这使其类似于分割任务(逐像素分类),但是除了一个图像之外,我们有两个输入,直观上,这些符号必须以某种方式显示两个图像之间的差异。 作为第一个迭代,决定简单地弹出两个RGB帧作为输入(实际上已经接收到6通道图像),在这两个帧之间我们要计算光流,并采用U-net作为具有许多更改的体系结构。 该网络称为FlowNetS(S代表简单):
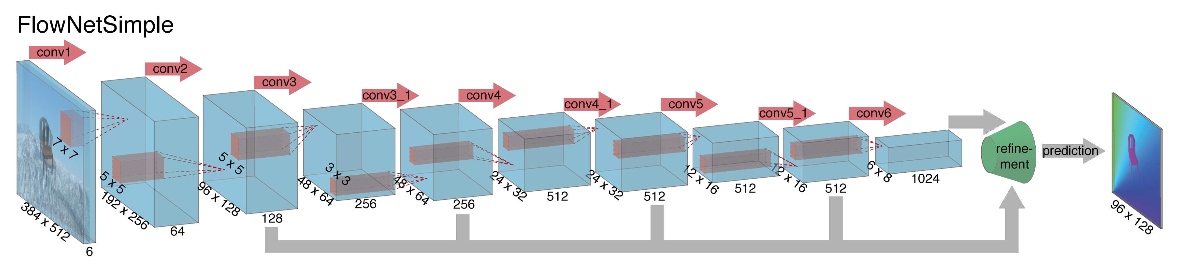
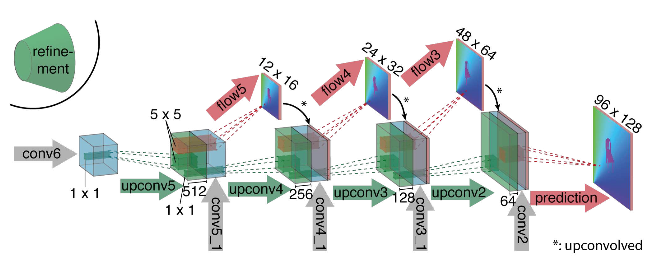
从图中可以看出,编码器并不引人注目,解码器在一些方面与经典选项有所不同:
- 光流的预测不仅从最后一级开始,而且从所有其他水平开始。 为了获得第i级解码器的地面真值,只需将原始目标(即光流)减小(几乎与图像相同)到所需分辨率,并且在第i级获得的谓词就更进一步,t即,它与从该级别出现的功能图串联在一起。 训练损耗的一般功能是解码器所有级别的损耗的加权总和,而权重本身越大,则级别越接近网络输出。 作者没有给出为什么这样做的解释,但是最有可能的原因是这样的事实,即在早期水平上可以更好地检测到尖锐的运动,因此低分辨率光流中的矢量不会太大。
- 该图显示图像的输入分辨率为384x512,而输出则小四倍。 作者注意到,如果通过简单的双线性插值将此输出增加到384x512,则将获得与附加两个以上级别的解码器相同的质量。 您也可以使用变分方法[2],以证明质量(质量表中的+ v)。
- 与在U-net中一样,来自编码器的属性卡被发送到解码器并进行连接,如图所示。

要了解作者如何尝试改善基线,您需要知道图像之间的相关性以及为什么它在计算光通量时有用。 因此,拥有两个图像并知道第二个是相对于第一帧的视频中的下一帧,我们可以尝试将第一帧上该点周围的区域(我们要查找到第二帧的偏移)与第二个图像中相同大小的区域进行比较。 此外,假设每单位时间的偏移量不能太大,则只能在起始点的某个邻域中考虑比较。 为此,使用互相关。 让我们举例说明。
以视频的两个相邻帧为例,我们要确定某个点从第一帧移到第二帧的位置。 假设此点附近的某些区域以相同的方式移动。 实际上,视频中的相邻像素通常会偏移在一起,例如 在视觉上,很可能是一个对象的一部分。 例如,可以在差分方法中积极使用此假设,可以在[5],[6]中更详细地阅读。
fig, ax = plt.subplots(1, 2, figsize=(20, 10)) ax[0].imshow(frame1) ax[1].imshow(frame2);

让我们尝试在小猫爪子的中心点,然后在第二帧找到它。 在其周围占据一些区域。
patch1 = frame1[90:190, 140:250] plt.imshow(patch1);

我们计算该区域(在英国文学中经常从第一张图片写模板或补丁)与第二张图片之间的相关性。 模板将简单地“遍历”第二张图像,并在其自身与第二张图像中相同大小的片段之间计算以下值:
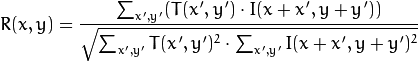
该值的值越大,则模板看起来越像第二张图像中的相应片段。 使用OpenCV,可以这样进行:
corr = cv2.matchTemplate(frame2, patch1, cv2.TM_CCORR_NORMED) plt.imshow(corr, cmap='gray');
更多细节可以在[7]中找到。
结果如下:
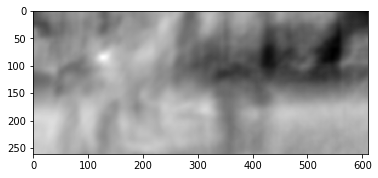
我们看到一个清晰的峰,用白色表示。 在第二帧找到它:
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(corr) h, w, _ = patch1.shape top_left = max_loc bottom_right = (top_left[0] + w, top_left[1] + h) frame2_copy = frame2.copy() cv2.rectangle(frame2_copy, top_left, bottom_right, 255, 2) plt.imshow(frame2_copy);

我们看到正确找到了脚,根据这些数据,我们可以了解脚从第一帧移动到第二帧的方向,并计算出相应的光通量。 另外,事实证明,该操作对光度畸变具有相当的抵抗力,即 如果第二帧的亮度急剧上升,则图像之间的互相关峰值将保持在原位。
考虑到以上所有内容,作者决定将所谓的相关层引入其体系结构,但决定不根据输入图像来考虑相关性,而是根据经过多层编码器后的属性映射来考虑。 出于明显的原因,该层没有学习参数,尽管其本质上与卷积相似,但是在这里我们不使用权重,而是使用第二张图像的某些区域来代替滤镜:
奇怪的是,这个技巧并没有显着改善本文作者的质量,但是,它更成功地应用于了进一步的工作中,在[9]中,作者能够证明通过稍微改变训练参数可以使FlowNetC更好地工作。
作者以一种非常优雅的方式解决了缺少数据集的问题:他们以1024×768的分辨率从Flickr上以主题为“城市”,“风景”,“山”刮下了964张图像,并以512×384的背景作为裁剪背景,然后抛出了一些图像。开放式渲染3D模型中的椅子。 然后,将各种仿射变换独立地应用于椅子和背景,它们用于成对生成第二张图像以及它们之间的光流。 结果如下:

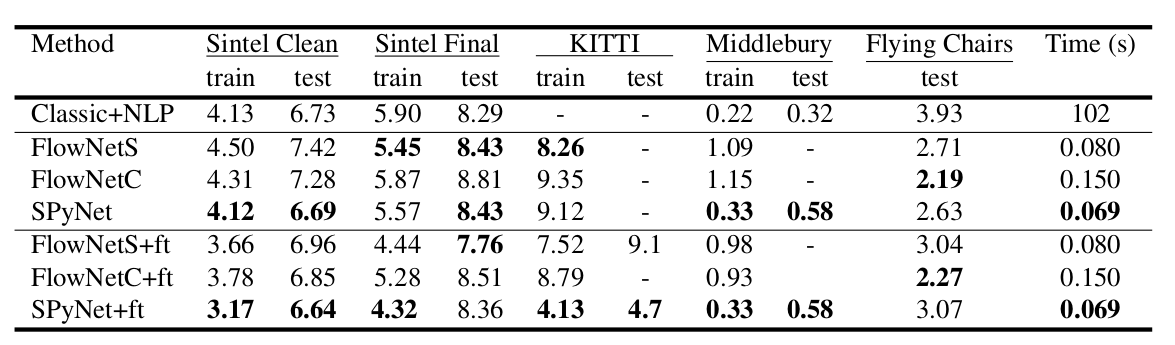
一个有趣的结果是,使用这样的综合数据集可以使来自另一个域的数据获得相对较高的质量。 当然,对相应数据的微调被证明具有更高的质量(下表中的+ ft):
真实视频的结果可以在这里看到:
间谍网(2016)
在随后的许多文章中,作者试图通过解决对突然运动的认识不佳的问题来提高质量。 直观地,如果运动的矢量明显超出激活的接受范围,则该运动将不会被网络捕获。 建议解决此问题的原因有三点:较大的卷积,金字塔和将一个图像从一对“扭曲”到光流中。 一切都井井有条。
因此,如果我们有几个图像中的对象发生了急剧移动(超过10个像素),那么我们可以简单地将图像缩小(减少6倍或更多倍)。 偏移的绝对值将大大降低,并且网络更有可能“捕获”它,尤其是当其卷积大于偏移本身时(在这种情况下,使用7x7卷积)。
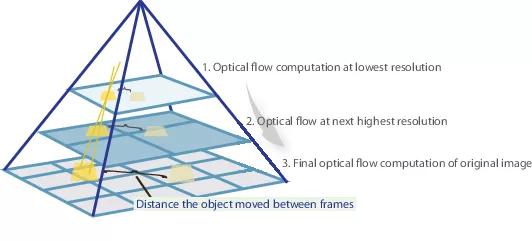
但是,在缩小图像时,我们丢失了许多重要的细节,因此我们应该进入金字塔的下一个层次,在该金字塔中图像的大小已经很大,同时以某种方式考虑了我们在计算较小尺寸的光通量时收到的信息。 这是使用翘曲运算符完成的,该运算符根据可用的光通量近似值(在先前级别获得)重新计数第一张图像。 这种情况下的一种改进是,根据光通量的近似“推”的第一个图像将比原始图像更接近第二个图像,也就是说,我们再次减小了光通量的绝对值,我们需要对其进行预测(回想一下,值较小更好地检测到运动,因为它们完全包含在一个卷积中。 从数学的角度来看,具有位图图像I和光通量V的近似值,翘曲算子可以描述如下:
在哪里
,即 图片中的特定点
-图片本身
-光流
-产生的图像“包裹”在光流中。
如何在CNN架构中应用所有这些? 我们确定金字塔等级
以及将每个后续图像从最后一个图像开始缩小的因子
。 表示为
和
图像或光通量的下采样和上采样功能就是这个因素。
我们还将获得一套CNN-ok {
},每个金字塔等级。 然后
-th网络将接受带有
金字塔能级和光通量
级别(
只会接受零的张量)。 在这种情况下,我们将图像中的一个发送到扭曲层以减小它们之间的差异,并且我们将不会预测此级别的光通量,而是需要将其值添加到前一个级别的增加(上采样)的光通量中以获得该光通量在这个水平上。 在公式中,它看起来像这样:
为了获得光流本身,我们只需添加网络谓词和上一级的增加的流:
要在此级别获得网络的地面真理,我们需要执行相反的操作-从先前的金字塔级别中减去目标的谓词(减少至所需级别)。 从示意图上看,它看起来像这样:

这种方法的优点是我们可以独立地教授每个级别。 作者从0级开始训练,随后的每个网络都使用前一个参数初始化。 由于每个网络
与大图像中光通量的完整计算相比,解决此问题要简单得多,因此可以减少参数。 如此之大,以至于现在整个整体都可以安装在移动设备上:

集成本身如下(一个三层金字塔的示例):
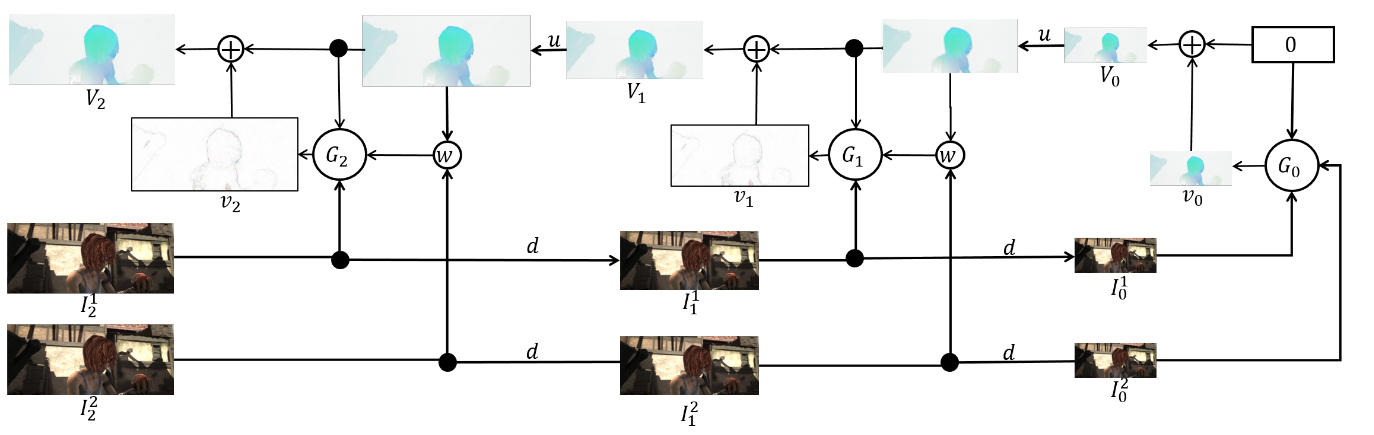
直接谈论架构仍有待探讨
网络并盘点。 每个网络
由5个卷积层组成,每个卷积层都以ReLU激活结束,最后一层除外(预测光流)。 每层过滤器的数量分别为{
}。 神经网络的输入(图像,“包裹”在光流中的第二个图像以及光流本身)仅根据通道的大小进行连接,因此它们的输入张量为8。结果令人印象深刻:
PWC-Net(2018)
受德国同事的成功启发,NVIDIA的员工决定运用他们的经验(和视频卡)进一步改善结果。 他们的工作主要基于先前模型(SpyNet)的思想,因此PWC-Net还将按顺序处理金字塔,但处理卷积金字塔,而不是原始图像。
使用原始像素强度来计算光通量并不总是合理的,因为 亮度/对比度的急剧变化将打破我们的假设,即像素从一帧移至下一帧而不会发生变化,并且算法将无法抵抗这种变化。 在用于计算光通量的经典算法中,使用了各种变换来缓解这种情况,在这种情况下,作者决定为模型提供机会自己学习这种变换。 因此,代替了PWC-Net中的图像金字塔,而是使用了卷积金字塔(因此Pwc-Net中的第一个字母),即 只是来自不同CNN图层的要素地图,在此称为要素金字塔提取器。
然后,一切都几乎像在SpyNet中一样,就在您提交给被称为光流估算器的CNN之前,您需要的一切,即:
- 图片(在这种情况下,是来自要素金字塔提取器的要素地图),
- 在上一级计算的上采样光通量,
- 第二张图像被“包裹”(记住翘曲层,因此是pWc-Net中的第二个字母)进入该光流,
在“包装的”第二帧和通常的第一帧之间(再次提醒您,这里使用带有特征金字塔提取器的功能卡代替原始图像)考虑了所谓的成本量(因此pwC-Net中的第三个字母)先前考虑的两个图像之间的相关性。
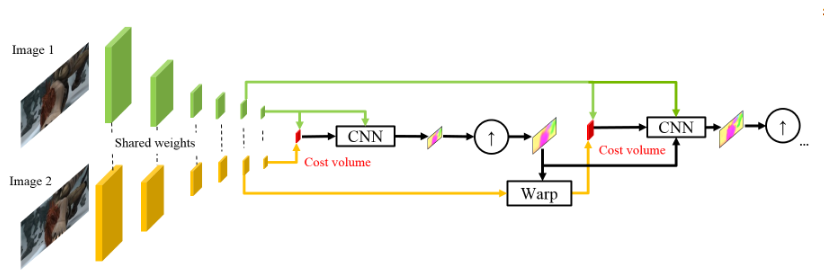
最终的联系是上下文网络,该上下文网络在光流量估算器之后立即添加,并扮演了对计算出的光流进行训练后处理的角色。 可以在扰流板下或原始文章中查看建筑细节。
贴心细节因此,特征金字塔提取器对两个图像具有相同的权重,对于每个卷积,将泄漏ReLU用作非线性。 为了降低每个后续级别的特征图的分辨率,使用了跨度为2的卷积,并且
表示图像特征图
在水平
。

金字塔第二层的光流估算器(例如)。 这里没有什么异常,每个卷积都以泄漏的ReLU结束,除了最后一个可预测光流的ReLU。

上下文网络仍处于金字塔的第二层,该网络使用具有相同泄漏ReLU激活的扩张卷积,但最后一层除外。 它使用相同的光流量估算器从该层的末端接收由光流量估算器计算的光流量以及来自第二层的属性。 每个块中的最后一位数字表示膨胀常数。

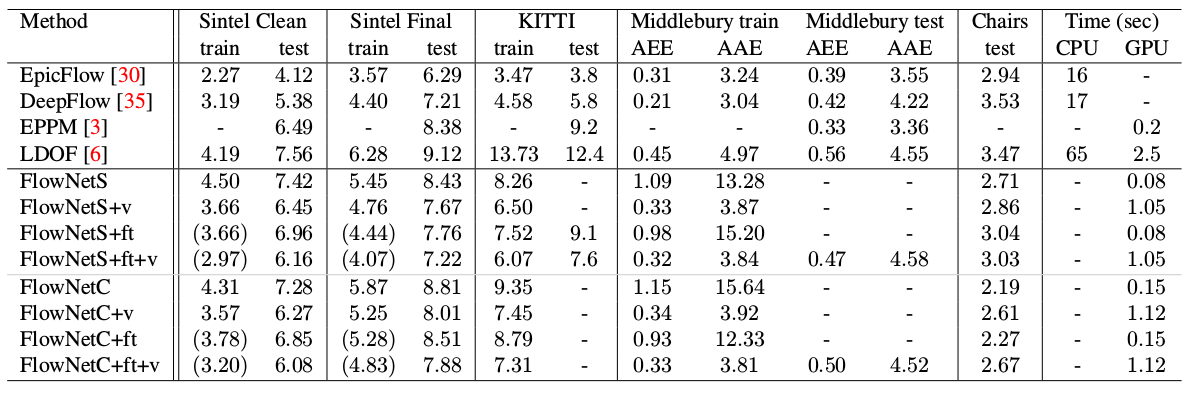
结果更加令人印象深刻:
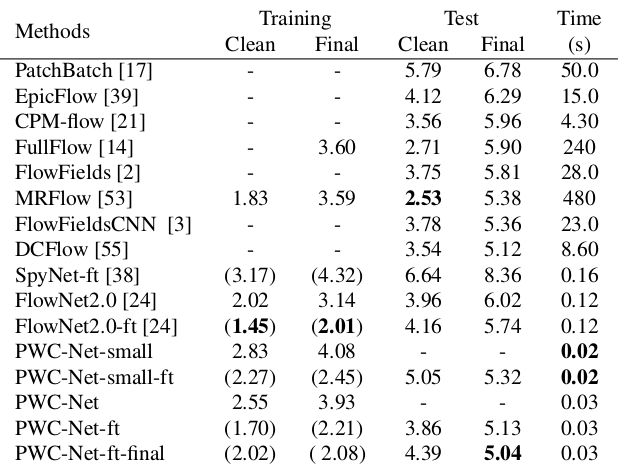
与其他CNN计算光流的方法相比,PWC-Net在质量和参数数量之间取得了平衡:
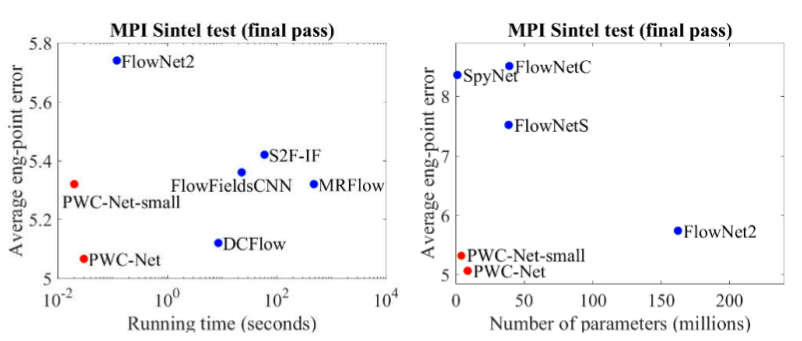
作者自己也做了一个精彩的演讲,他们在讨论模型本身及其实验时:
结论
解决光流计数问题的体系结构的演变是一个很好的例子,说明了CNN体系结构的进步以及如何将它们与经典方法结合起来可以产生最佳效果。 尽管经典的简历方法仍在质量上取胜,但最近的结果使人们希望这是可以解决的...
来源和链接
1. FlowNet:使用卷积网络学习光流:
文章 ,
代码 。
2.大位移光流:变量运动估计中的描述符匹配:
文章 。
3.使用空间金字塔网络进行光流估计:
文章 ,
代码 。
4. PWC-Net:使用金字塔,翘曲和成本量进行光流的CNN:
文章 ,
代码 。
5.您想了解有关光流的知识,但不好意思问:
文章 。
6.通过卢卡斯-加拿大方法计算光通量。 理论:
文章 。
7.与OpenCVP匹配的模板:
dock 。
8. Qu Vadis,动作识别? 新模型和动力学数据集:
文章 。
9. FlowNet 2.0:借助深层网络进行光流估计的演进:
文章 ,
代码 。