除了非常保守的领域,现在不使用自然语言处理。 在大多数技术解决方案中,人们早已引入了对``人类''语言的识别和处理方法:这就是为什么通常的具有硬编码响应选项的IVR逐渐成为过去的原因,聊天机器人在没有现场操作员参与的情况下开始更充分地进行通信,邮件过滤器爆炸式地工作等等。 如何识别录制的语音,即文本? 或更确切地说,什么是现代识别和处理技术的基础? 我们今天改编的译文对此做出了很好的回应-在剪切之后,您会发现一种长程骑行,它将弥补NLP基础知识上的空白。 祝您阅读愉快!
什么是自然语言处理?
自然语言处理(以下简称NLP)-自然语言处理是计算机科学和AI的一部分,致力于计算机如何分析自然(人类)语言。 NLP允许将机器学习算法用于文本和语音。
例如,我们可以使用NLP创建系统,例如语音识别,文档概括,机器翻译,垃圾邮件检测,识别命名实体,问题答案,自动完成,预测性文本输入等。
今天,我们许多人都拥有语音识别智能手机-他们使用NLP来理解我们的语音。 另外,许多人在操作系统中使用具有内置语音识别功能的笔记本电脑。
例子
Cortana
Windows具有可识别语音的Cortana虚拟助手。 使用Cortana,您可以创建提醒,打开应用程序,发送信件,玩游戏,查找天气等。
西里
Siri是Apple操作系统的助手:iOS,watchOS,macOS,HomePod和tvOS。 许多功能还可以通过语音控制来实现:呼叫/写人,发送电子邮件,设置计时器,拍照等。
邮箱
著名的电子邮件服务知道如何检测垃圾邮件,以使其不会进入收件箱的收件箱。
对话流程
Google提供的平台,可让您创建NLP机器人。 例如,您可以制作一个
不需要老式IVR的比萨订购机器人
来接受您的订单 。
NLTK Python库
NLTK(自然语言工具包)是用于在Python中创建NLP程序的领先平台。 它具有用于许多
语言公司的易于使用的界面,以及用于分类,标记化,
词干 ,
标记 ,过滤和
语义推理的文字处理库。 好吧,这是一个免费的开源项目,正在社区的帮助下开发。
我们将使用此工具展示NLP的基础知识。 对于所有后续示例,我假定已经导入了NLTK。 这可以通过
import nltkNLP文本基础
在本文中,我们将介绍以下主题:
- 通过报价进行标记化。
- 通过单词进行标记化。
- 文本的合法化和标记 。
- 别说了
- 正则表达式。
- 一袋字 。
- TF-IDF 。
1.按要约令牌化
句子的标记化(有时是分段)是将书面语言分为各个组成部分的过程。 这个想法看起来很简单。 在英语和其他一些语言中,每次找到某个标点符号(一个句点)时,我们都可以隔离一个句子。
但是即使是英语,该任务也不是一件容易的事,因为该点也用缩写表示。 缩写表在字处理过程中可以极大地帮助避免错位句子边界。 在大多数情况下,库是用于此目的的,因此您实际上不必担心实现细节。
一个例子:简短介绍一下步步高棋盘游戏:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
要使用NLTK进行商品标记化,可以使用
nltk.sent_tokenize方法
| text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice." |
| sentences = nltk.sent_tokenize(text) |
| for sentence in sentences: |
| print(sentence) |
| print() |
在出口处,我们得到3个单独的句子:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
2.按词的标记化
根据单词的标记化(有时是分段)是将句子分为组成单词的过程。 在使用一种或另一种拉丁字母版本的英语和许多其他语言中,空格是一个很好的单词分隔符。
但是,如果仅使用空格,则可能会出现问题-在英语中,复合名词的写法不同,有时用空格分隔。 在这里,图书馆再次帮助了我们。
一个例子:让我们以前面示例中的句子为例,然后将
nltk.word_tokenize方法应用于它们
| for sentence in sentences: |
| words = nltk.word_tokenize(sentence) |
| print(words) |
| print() |
结论:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']
3.文本的合法化和盖章
通常,文本包含同一单词的不同语法形式,也可能出现单词单词。 合法化和词干提取旨在将所有出现的单词形式转换为单一的常规词汇形式。
范例:将不同的单词形式带到其中:
dog, dogs, dog's, dogs' => dog
相同,但参考整个句子:
the boy's dogs are different sizes => the boy dog be differ size
引词化和词干化是规范化的特殊情况,它们有所不同。
词干分析是一种粗略的启发式过程,可以消除单词根源中的“多余”,通常会导致失去单词构建后缀。
词法化是一个更细微的过程,它使用词汇和形态分析来最终将词带入其规范形式-外引。
不同之处在于词干(词干提取算法的特定实现-译者注释)在不了解上下文的情况下运行,因此,无法理解根据词性不同而具有不同含义的词之间的差异。 但是,词干提取器有其自身的优势:易于实现且工作更快。 另外,在某些情况下,较低的“准确性”可能并不重要。
范例:- “好”一词是“更好”一词的引理。 Stemmer将看不到此连接,因为在这里您需要查阅字典。
- 文字游戏是文字游戏的基本形式。 在这里,词干和词根化都将应付。
- 根据上下文的不同,单词meeting可以是名词的正常形式,也可以是meet的动词形式。 与词干不同,词根化将尝试根据上下文选择正确的词条。
现在我们知道有什么区别,让我们来看一个示例:
| from nltk.stem import PorterStemmer, WordNetLemmatizer |
| from nltk.corpus import wordnet |
| |
| def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos): |
| """ |
| Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech) |
| """ |
| print("Stemmer:", stemmer.stem(word)) |
| print("Lemmatizer:", lemmatizer.lemmatize(word, pos)) |
| print() |
| |
| lemmatizer = WordNetLemmatizer() |
| stemmer = PorterStemmer() |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB) |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB) |
结论:
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive
4.停用词
停用词是在文本处理之前/之后从文本中抛出的词。 当我们将机器学习应用于文本时,此类单词可能会增加很多噪音,因此您需要摆脱不相关的单词。
停用词通常由不带语义负荷的文章,感叹词,并集等理解。 应当理解,没有通用的停用词列表,这完全取决于特定的情况。
NLTK具有预定义的停用词列表。 在首次使用之前,您需要下载它:
nltk.download(“stopwords”) 。 下载后,您可以导入
stopwords包并查看单词本身:
| from nltk.corpus import stopwords |
| print(stopwords.words("english")) |
结论:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
考虑如何删除句子中的停用词:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [word for word in words if not word in stop_words] |
| print(without_stop_words) |
结论:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
如果您不熟悉列表推导,可以
在这里找到更多
信息 。 这是获得相同结果的另一种方法:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [] |
| for word in words: |
| if word not in stop_words: |
| without_stop_words.append(word) |
| |
| print(without_stop_words) |
但是,请记住,列表理解是因为优化了它们,所以速度更快-解释器在循环期间揭示了一种预测模式。
您可能会问为什么我们将列表转换为
许多 。 集合是一种抽象数据类型,可以按未定义的顺序存储唯一值。 按集合搜索比通过列表搜索要快得多。 对于少量单词,这无关紧要,但是如果我们谈论的是大量单词,则严格建议使用集合。 如果您想更多地了解执行各种操作所花费的时间,请查看
这份出色的备忘单 。
5.正则表达式。
正则表达式(regex,regexp,regex)是定义搜索模式的字符序列。 例如:
- 。 -除换行符外的任何字符;
- w是一个词;
- d-一位;
- s-一个空格;
- \ W是一个非单词;
- \ D-一个非数字;
- S-一个非空格;
- [abc]-查找与a,b或c中的任何一个匹配的指定字符;
- [^ abc]-查找除指定字符外的任何字符;
- [ag]-查找a到g范围内的字符。
摘自
Python文档 :
正则表达式使用反斜杠(\)表示特殊形式或允许使用特殊字符。 这与在Python中使用反斜杠相矛盾:例如,要从字面上指示反斜杠,必须将'\\\\'作为搜索模式编写,因为正则表达式应类似于\\ ,每个反斜杠都必须转义。
解决方案是对搜索模式使用原始字符串表示法。 如果与前缀'r'一起使用,则不会对反斜杠进行特殊处理。 因此, r”\n”是带有两个字符('\' 'n')的字符串,而“\n”是带有一个字符的字符串(换行)。
我们可以使用常规来进一步过滤文本。 例如,您可以删除不是单词的所有字符。 在许多情况下,不需要标点符号,并且在常规人员的帮助下易于删除。
Python中的
re模块代表正则表达式操作。 我们可以使用
re.sub函数用指定的字符串替换所有符合搜索模式的内容。 因此,您可以将所有非单词替换为空格:
| import re |
| sentence = "The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing." |
| pattern = r"[^\w]" |
| print(re.sub(pattern, " ", sentence)) |
结论:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing '
常规是一个功能强大的工具,可用于创建更为复杂的模式。 如果您想了解有关正则表达式的更多信息,那么我可以推荐以下两个Web应用程序:
regex ,
regex101 。
6.一句话
机器学习算法无法直接处理原始文本,因此您需要将文本转换为数字集(向量)。 这称为
特征提取 。
文字袋是在处理文本时使用的一种流行且简单的特征提取技术。 它描述了文本中每个单词的出现。
要使用该模型,我们需要:
- 定义已知单词(标记)的字典。
- 选择著名词的存在程度。
有关单词顺序或结构的任何信息都将被忽略。 这就是为什么它被称为单词袋。 该模型试图了解一个熟悉的单词是否出现在文档中,但是不知道确切的位置。
直觉表明
相似的文件具有
相似的内容 。 另外,由于内容丰富,我们可以了解有关文档含义的信息。
一个例子:考虑创建此模型的步骤。 我们仅使用4个句子来了解模型的工作原理。 在现实生活中,您将遇到更多数据。
1.下载资料
想象一下这是我们的数据,我们想将其作为数组加载:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
为此,只需读取文件并按行划分:
| with open("simple movie reviews.txt", "r") as file: |
| documents = file.read().splitlines() |
| |
| print(documents) |
结论:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']
2.定义字典
我们将从4个加载的句子中收集所有唯一的单词,而忽略大小写,标点符号和一个字符的标记。 这将是我们的字典(著名的词)。
要创建字典,可以使用sklearn库中的
CountVectorizer类。 转到下一步。
3.创建文档向量
接下来,我们需要评估文档中的单词。 在这一步,我们的目标是将原始文本转换为一组数字。 之后,我们将这些集合用作机器学习模型的输入。 最简单的评分方法是注意单词的存在,即,如果有单词,则输入1,如果不存在,则输入0。
现在,我们可以使用上述CountVectorizer类创建一袋单词。
| # Import the libraries we need |
| from sklearn.feature_extraction.text import CountVectorizer |
| import pandas as pd |
| |
| # Step 2. Design the Vocabulary |
| # The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output |
| count_vectorizer = CountVectorizer() |
| |
| # Step 3. Create the Bag-of-Words Model |
| bag_of_words = count_vectorizer.fit_transform(documents) |
| |
| # Show the Bag-of-Words Model as a pandas DataFrame |
| feature_names = count_vectorizer.get_feature_names() |
| pd.DataFrame(bag_of_words.toarray(), columns = feature_names) |
结论:
这些是我们的建议。 现在我们来看看“语言袋”模型的工作原理。
关于这句话的几句话
该模型的复杂性在于如何确定字典以及如何计算单词的出现。
当字典大小增加时,文档向量也会增加。 在上面的示例中,向量的长度等于已知单词的数量。
在某些情况下,我们可以拥有大量的数据,然后向量可以包含成千上万个元素。 而且,每个文档只能包含字典中单词的一小部分。
结果,向量表示中将有许多零。 具有多个零的向量称为稀疏向量,它们需要更多的内存和计算资源。
但是,当使用此模型来减少对计算资源的需求时,我们可以减少已知单词的数量。 为此,您可以使用在创建单词袋之前已经考虑过的相同技术:
- 忽略单词的大小写;
- 忽略标点符号;
- 弹出停用词;
- 减少单词的基本形式(词干和词干);
- 纠正拼写错误的单词。
创建字典的另一种更复杂的方法是使用分组词。 这将调整字典的大小,并为单词袋提供有关文档的更多详细信息。 这种方法称为“
N-gram” 。
N-gram是任何实体(单词,字母,数字,数字等)的序列。 在语言主体的上下文中,N-gram通常被理解为单词序列。 一个字母组合词是一个单词,一个双字母组是两个单词的序列,一个字母组合词是三个单词,依此类推。 数字N表示N-gram中包含多少个分组词。 并非所有可能的N-gram都属于模型,而是仅属于案例中出现的N-gram。
一个例子:考虑以下句子:
The office building is open today
这是他的二重奏:
如您所见,比起一言多语,一袋二元组是更有效的方法。
单词的评估(评分)创建字典时,应评估单词的存在。 我们已经考虑了一种简单的二进制方法(1-有一个单词,0-没有一个单词)。
还有其他方法:
- 数量 计算每个单词出现在文档中的次数。
- 频次 计算每个单词在文本中出现的频率(相对于单词总数)。
7.特遣部队
频率评分有一个问题:频率最高的单词分别具有最高的评级。 用这些词来说,模型
获得的
信息增益可能不如使用频率较低的词那么多。 纠正这种情况的一种方法是降低单词分数,这
在所有相似的文档中都经常发现。 这称为
TF-IDF 。
TF-IDF(术语频率-逆文档频率)的一种统计量度,用于评估单词在集合或语料库中的重要性。
TF-IDF的评分与文档中某个单词出现的频率成正比,但是可以通过包含该单词的文档数量来补偿。
Y文件中X字的评分公式:
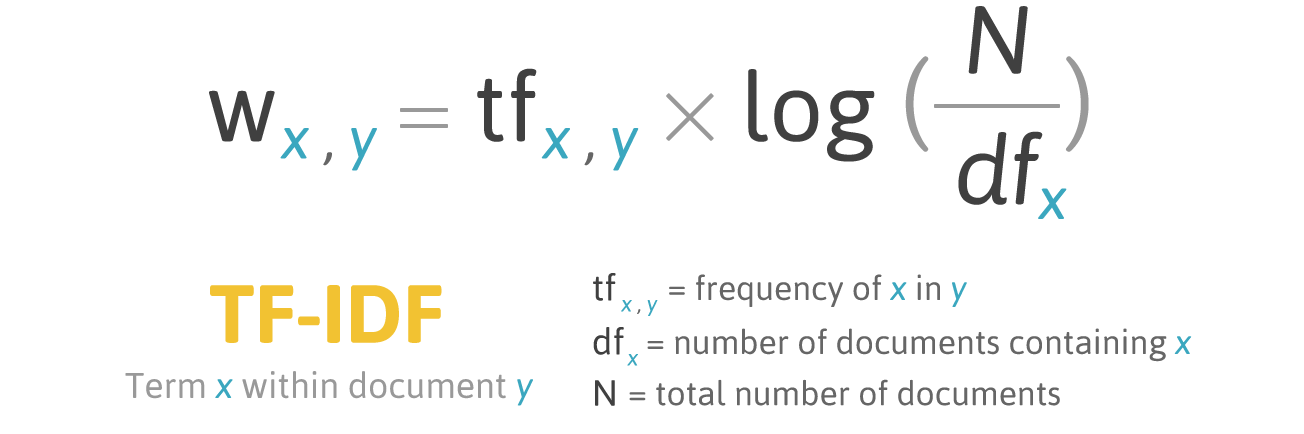 公式TF-IDF。 资料来源: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
公式TF-IDF。 资料来源: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlTF(术语频率)是一个单词出现的次数与文档中单词总数的比率。
IDF(逆文档频率)是单词在收集文档中出现的频率的逆。
结果,单词词的TF-IDF可以计算如下:
一个例子:您可以使用sklearn库中的
TfidfVectorizer类来计算TF-IDF。 让我们用单词袋示例中使用的相同消息来完成此操作。
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
代码:
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import pandas as pd |
| |
| tfidf_vectorizer = TfidfVectorizer() |
| values = tfidf_vectorizer.fit_transform(documents) |
| |
| # Show the Model as a pandas DataFrame |
| feature_names = tfidf_vectorizer.get_feature_names() |
| pd.DataFrame(values.toarray(), columns = feature_names) |
结论:
结论
本文介绍了文本的NLP基础,即:
- NLP允许将机器学习算法用于文本和语音;
- NLTK(自然语言工具包)-用于在Python中创建NLP程序的领先平台;
- 提案标记化是将书面语言分为各个组成部分的过程;
- 词标记化是将句子分为组成词的过程;
- 词法化和词干化的目的是将遇到的所有单词形式转换为单一的常规词汇形式;
- 停用词是在文本处理之前/之后从文本中抛出的词;
- 正则表达式(regex,regexp,regex)是定义搜索模式的一系列字符;
- 一袋单词是在处理文本时使用的一种流行且简单的特征提取技术。 它描述了文本中每个单词的出现。
太好了! 既然您知道了特征提取的基础知识,就可以将特征用作机器学习算法的输入。
如果您想在一个大例子中看到所有描述的概念,那么
这里就是 。