
在我们的项目中,我们使用微服务架构。 如果出现性能瓶颈,则会在监视和分析日志上花费大量时间。 在将单个操作的时间记录到日志文件中时,通常很难理解导致这些操作调用的原因,以跟踪操作顺序或不同服务中一个操作相对于另一个操作的时间偏移。
为了最大程度地减少体力劳动,我们决定使用一种跟踪工具。 关于如何使用跟踪以及如何使用跟踪以及如何使用跟踪,我们将讨论本文。
跟踪可以解决什么问题
- 查找单个服务内以及所有参与服务之间的整个执行树中的性能瓶颈。 例如:
- 服务之间的许多短时间连续调用,例如,地理编码或数据库。
- 长时间等待输入输入,例如,通过网络传输数据或从磁盘读取数据。
- 长数据解析。
- 需要cpu的长时间操作。
- 获得最终结果不需要的代码段,可以删除或延迟运行。
- 清楚地了解执行该操作的顺序和顺序。
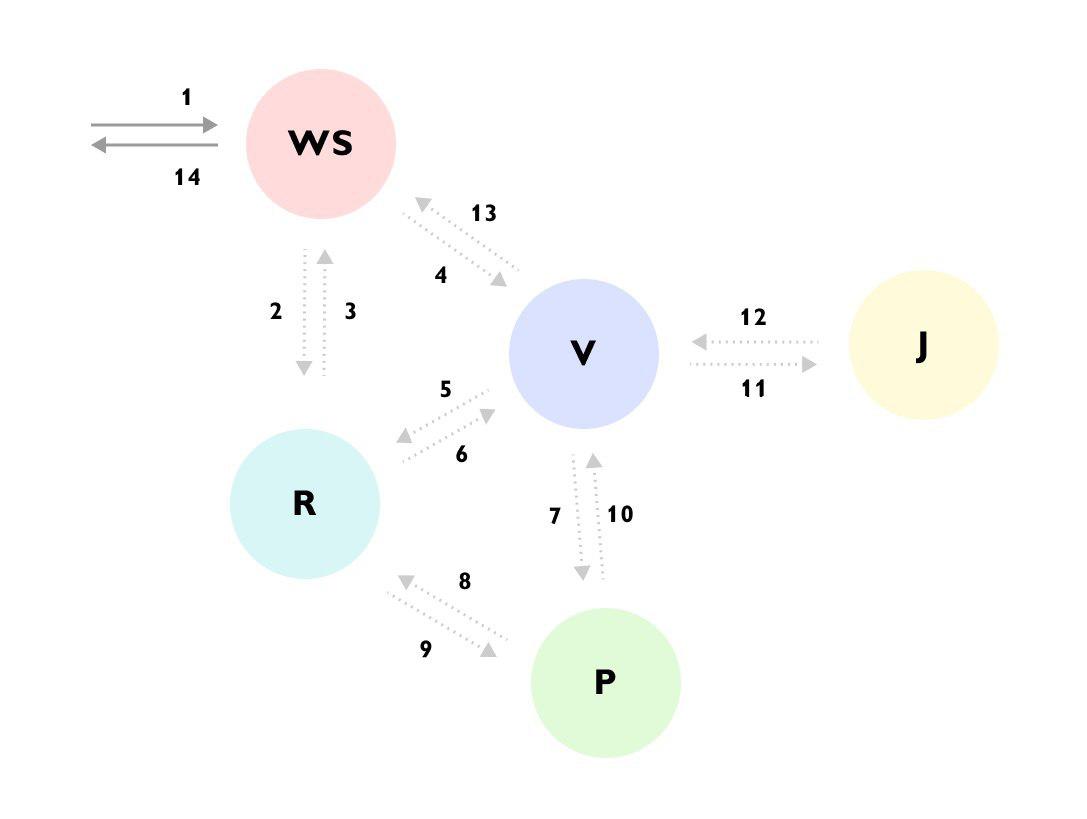
可以看到,例如,请求到达WS服务-> WS服务通过R服务补充了数据->然后将请求发送到V服务-> V服务从R服务加载了很多数据->转到了P服务-> P服务再次关闭服务R->服务V忽略结果,转到服务J->,然后将答案返回给WS服务,同时继续在后台计算其他内容。
在整个过程中,如果没有这样的跟踪或详细的文档,当您第一次查看代码时,很难理解正在发生的事情,并且代码分散在不同的服务中,并隐藏在许多bin和接口后面。
- 收集有关执行树的信息,以用于后续的挂起分析。 在执行的每个阶段,您都可以将信息添加到该阶段可用的跟踪中,然后找出导致类似情况的输入数据。 例如:
- 将跟踪转化为度量的子集,并进一步进行度量分析。
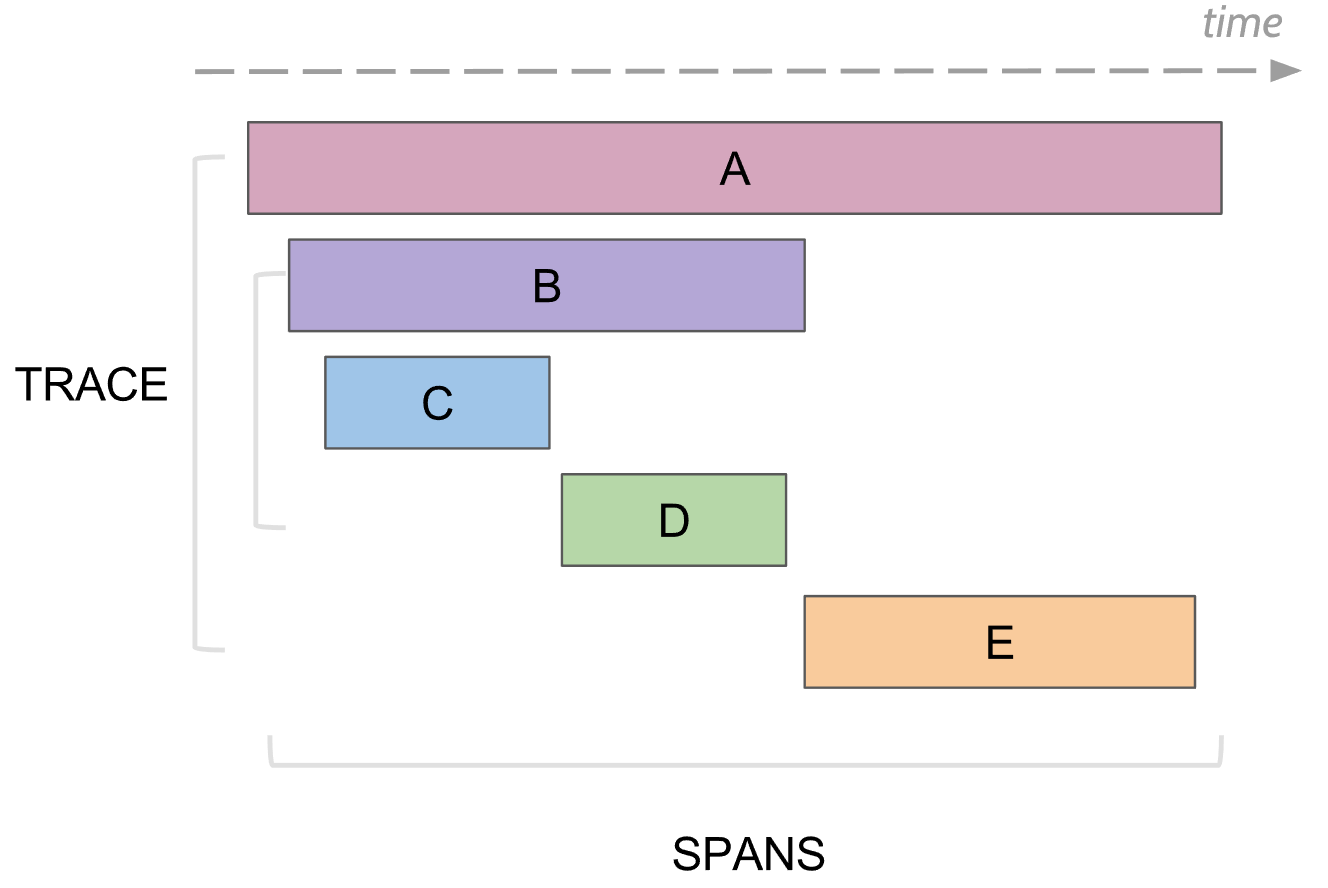
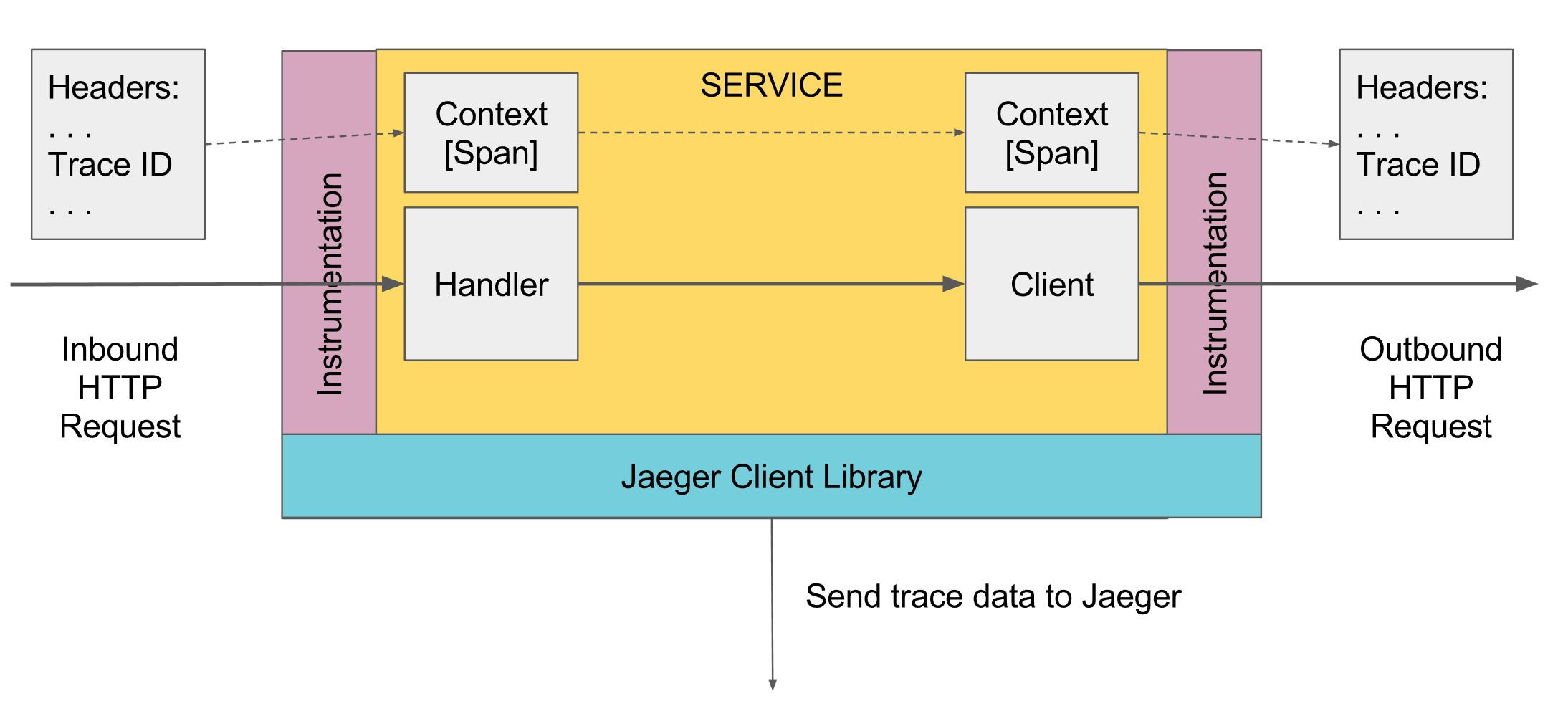
什么可以跟踪日志记录。 跨度
在跟踪中,存在跨度的概念,它类似于控制台的一个日志。 范围具有:
- 名称,通常是执行的方法的名称
- 在其中生成跨度的服务的名称
- 自己的唯一ID
- 以键/值形式的一些元信息,已承诺给它。 例如,方法参数或方法是否以错误结尾
- 该跨度的开始和结束时间
- 父范围ID
每个跨度都将发送到跨度收集器,以便在完成执行后立即保存到数据库以供以后查看。 将来,您可以通过按父ID进行连接来构建所有跨度的树。 例如,在分析中,您可以找到某项服务中所有跨度超过花费时间的跨度。 此外,转到特定跨度,请查看该跨度上下的整棵树。
Opentracing,Jagger以及我们如何在项目中实现它
有一个通用的
Opentracing标准,描述了如何组装以及如何组装而不与任何语言的特定实现绑定。 例如,在Java中,所有与跟踪有关的工作都是通过通用的Opentracing API完成的,例如在其下的Jaeger或不执行任何操作的空默认实现可以被隐藏。
我们将
Jaeger用作Opentracing的实现。 它由几个部分组成:
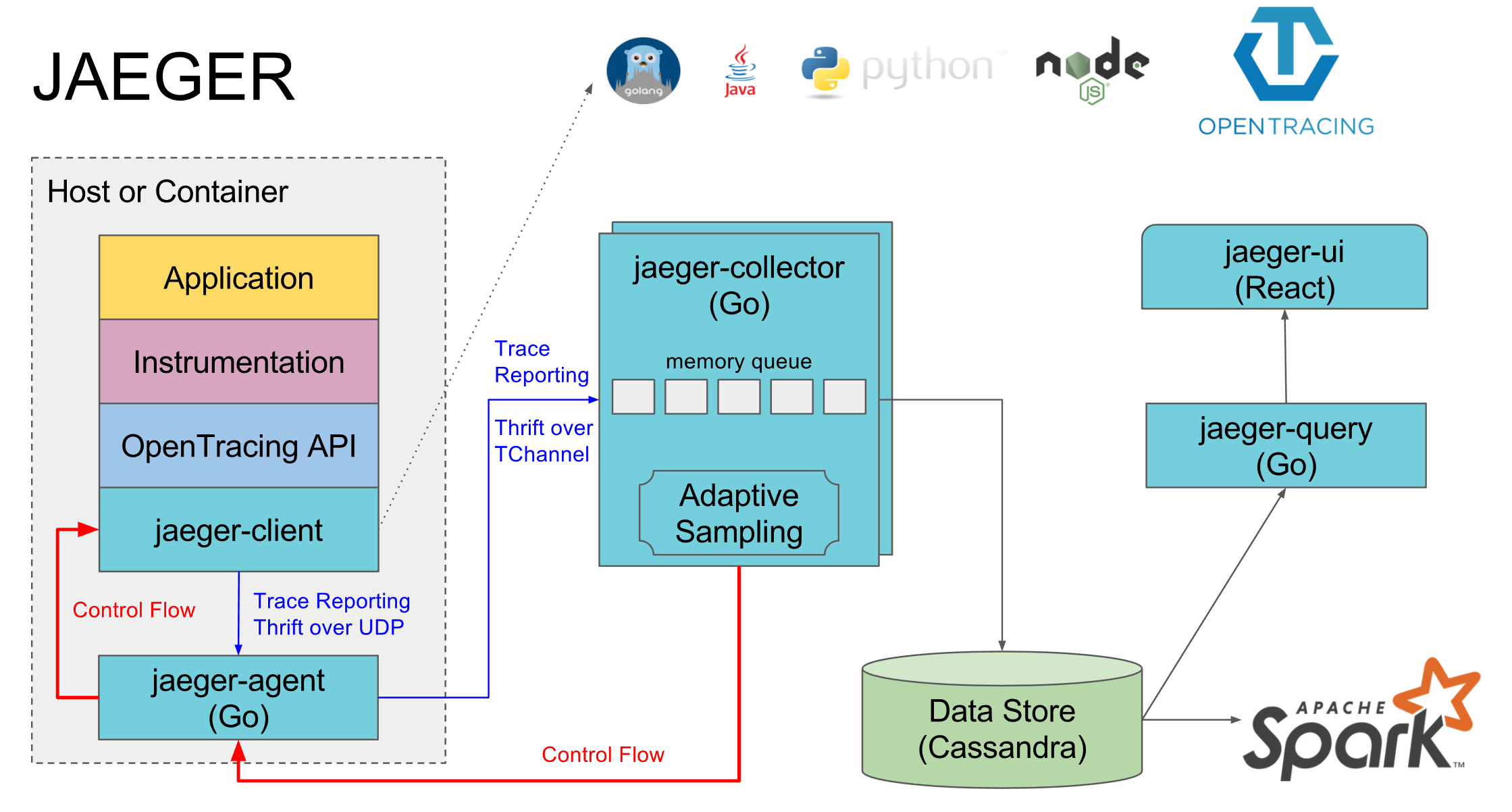
- Jaeger-agent是一个本地代理,通常位于每台计算机上,并且服务会在本地默认端口上登录到该代理。 如果没有代理,则通常会关闭此计算机上所有服务的跟踪
- Jaeger-collector-所有代理都将收集的跟踪发送到该收集器,并将其放入选定的数据库中
- 数据库是他们的首选cassandra,但是我们使用elasticsearch,有一些其他数据库的实现以及内存中的实现,该实现不会将任何内容保存到磁盘
- Jaeger-query是一项服务,可转到数据库并提供已收集的跟踪信息以进行分析
- Jaeger-ui是用于搜索和查看轨迹的Web界面,它转到jaeger-query
一个单独的组件是针对特定语言的opentracing jaeger的实现,通过该跨区将跨度发送到jaeger-agent。
连接Java中的Jagger可以模拟io.opentracing.Tracer接口,之后通过它的所有跟踪信息都将飞向真实的代理。
您还可以连接
opentracing-spring-cloud-starter和Jaeger
opentracing-spring-jaeger-cloud-starter的实现,该实现将自动配置通过这些组件传递的所有内容的跟踪,例如,对控制器的http请求,通过jdbc的数据库请求等
跟踪Java中的日志记录
应该在最高级别的某个位置创建第一个Span,这可以自动完成,例如,在收到请求时由弹簧控制器自动完成,如果没有,则手动创建。 此外,它通过下面的范围传输。 如果下面的某些方法想要添加Span,它将从Scope中获取当前的activeSpan,创建一个新的Span,并说其父级收到了activeSpan,并使新的Span处于活动状态。 调用外部服务时,会将当前活动范围转移到它们,并且这些服务将参考该范围创建新的范围。
所有工作都通过Tracer实例进行,您可以通过DI机制获取它,如果DI机制不起作用,则可以将GlobalTracer.get()作为全局变量获取。 默认情况下,如果未初始化跟踪器,则NoopTracer将返回不执行任何操作。
此外,当前范围是通过ScopeManager从跟踪程序获取的,从当前范围通过新范围的绑定创建一个新范围,然后关闭创建的范围,这将关闭创建的范围并将先前的范围返回到活动状态。 范围与流相关联,因此,在进行多线程编程时,一定不要忘记将活动范围转移到另一个流,以便参考该范围进一步激活另一个流的范围。
io.opentracing.Tracer tracer = ...;
对于多线程编程,还有一个TracedExecutorService和类似的包装器,它们在异步启动任务时自动将当前范围转发到流:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() );
对于外部http请求,有
TracingHttpClient HttpClient httpClient = new TracingHttpClientBuilder().build();
我们面临的问题
采样,存储和查看轨迹
跟踪采样分为三种类型:
- 发送并保存所有跟踪的常量。
- 概率以给定的概率过滤轨迹。
- 速率限制,用于限制每秒的迹线数量。 您可以在jaeger-agent或收集器上的客户端上配置这些选项。 现在,由于没有太多请求,但是我们需要很长时间,因此在评估者堆栈中有const 1。 将来,如果这会对系统造成过大的负担,则可以限制它。
如果使用cassandra,则默认情况下它将仅在两天内存储跟踪。 我们使用
elasticsearch,并且迹线会一直存储,不会被删除。 每天都会创建一个单独的索引,例如jaeger-service-2019-03-04。 将来,您需要配置自动清除旧痕迹。
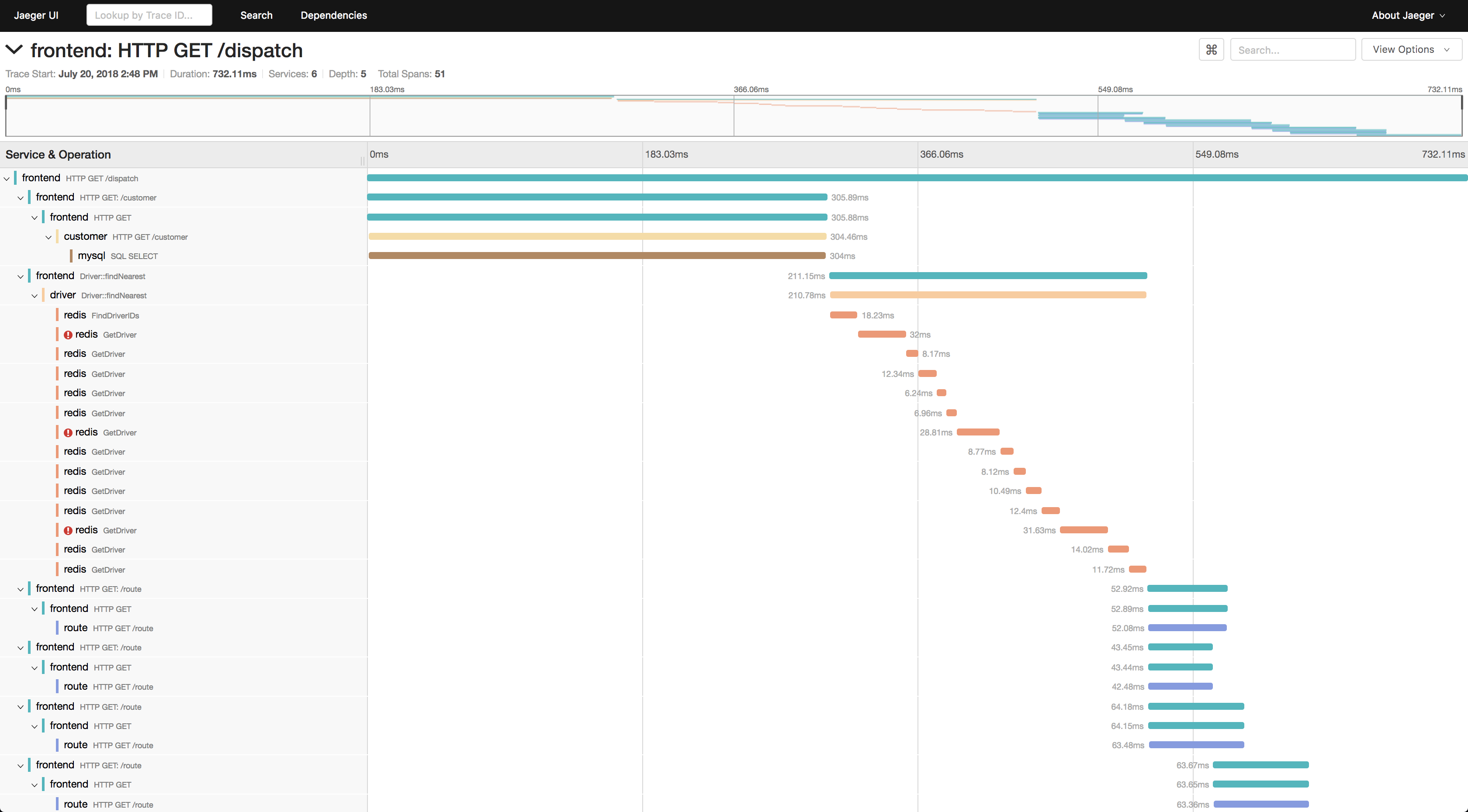
为了观看课程,您需要:
- 选择您要用来过滤跟踪的服务,例如,对于运行在Tomato上并且不能具有名称的服务,例如tomcat7-default。
- 接下来,选择操作,时间间隔和最短操作时间(例如从10秒开始),以仅进行长时间运行。
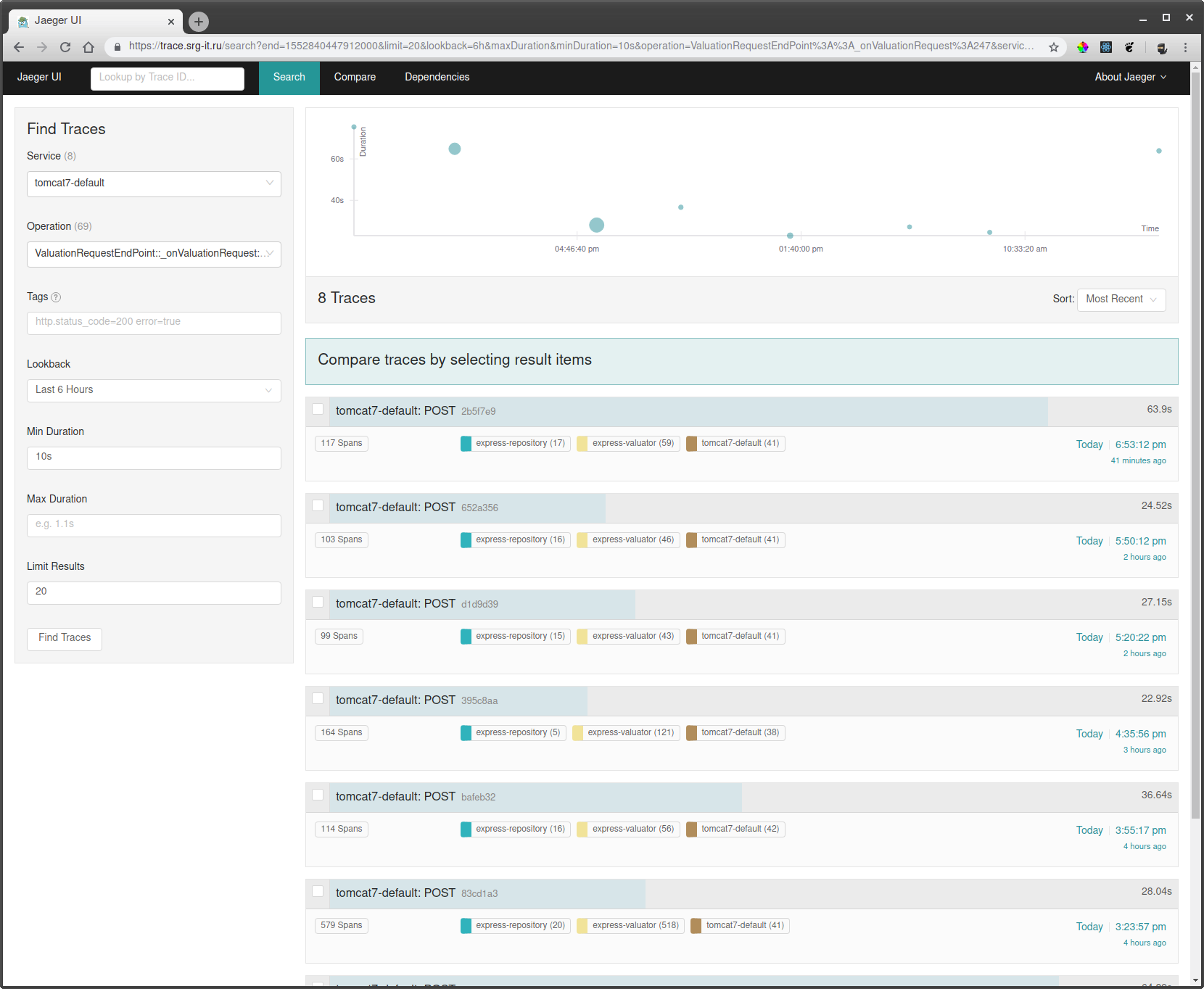
- 转到其中一条轨道,看看那里正在减速。

另外,如果请求的某些ID已知,那么如果该ID记录在跟踪范围内,则可以通过标签搜索通过该ID查找跟踪。
该文件
文章
录影带