在整个Yandex.Taxi汽车订购周期中都使用了机器学习,并且由于ML而工作的服务组件数量也在不断增长。 为了以统一的方式构建它们,我们需要一个单独的过程。 机器学习和数据分析服务主管Roman Khalkachev谈到了数据预处理,模型在生产中的使用,原型服务和相关工具。
-我认为,以一些简单的例子来讲述某些新事物时,它们会更容易感知。 因此,为了使报告不枯燥,我决定谈论我们正在解决的任务之一。 通过她的例子,我将说明为什么我们要采取这种方式。
让我们提出问题。 有些出租车用户需要从A点到达B点,有些驾驶员愿意为从A点到B点的这些用户提供一定的费用。该用户有多种情况。 他叫出租车,选择A点,B点,票价等,然后使出租车降落,乘车,最后降落。 今天,我想谈谈开车和可能出现的问题。

通常,这些问题与一个人需要选择出租车应该去的地方有关。 这里有很多困难。 这些困难与幻灯片上列出的四件事有关。
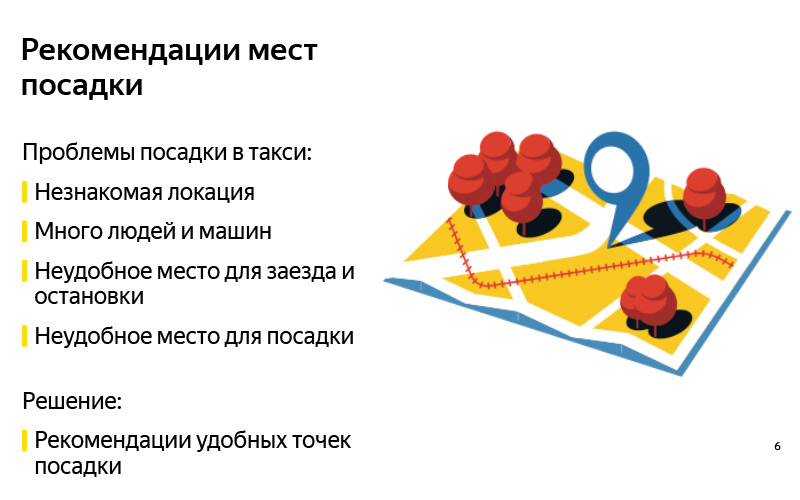
首先,用户可能不熟悉该位置。 例如,您可以想象自己曾经来过一些不常去的大型购物中心。 您想离开,而您实际上并不知道在这里可以打出租车,汽车可以在哪里打车,但是由于障碍而不能在哪里打车。 在某些地方有很多人,很多汽车的事实存在问题,您很难找到自己的汽车。 通常会有人们上车的地方,去那里比较容易。 而且,您可能不知道在新的地方,不一定在购物中心里的确切降落地点。 驾驶员可能无法开车前往您叫出租车的地方,这可能会带来困难:他被禁止旅行,购物中心有一些大出口,对面您不能停车等。
另一方面,您作为用户可能会遇到问题。 司机到了,一切都很好,但是您坐下来不舒服,因为所有人都挖了。 您要求驾驶员开车到其他地方。 还有其他原因。
最典型的例子是以上所有方面的精髓,就是机场,几乎所有事情都在其中完成。 即使您经常飞出谢列梅捷沃(Sheremetyevo),对于您来说,它仍然是一个陌生的地方,因为很多事情经常在那里发生变化。 有很多人,很多汽车,有方便的着陆点,有一些不舒服的地方,但是通常,我们没人记得这一点。
解决方案是从幻灯片标题中读取的。 让我们向用户推荐一些我们认为可以方便登陆的地方。 这个想法似乎很明显,但是这里有很多细微差别。
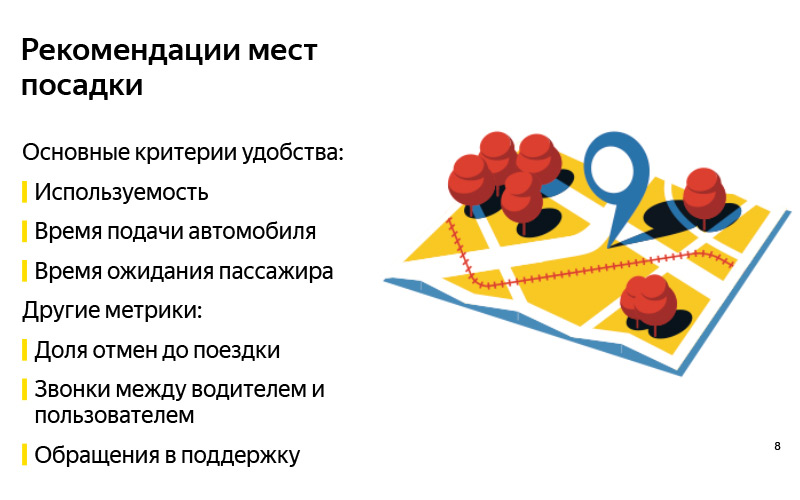
对于初学者来说,“便捷”是一个主观的概念。 看来在解决问题之前,有必要针对将正确解决问题的事实制定一些标准。 我们为自己制定了三个主要原则。 第一个标准与建议的任何任务一样:如果使用建议,那么建议可能是好的。 如果我们显示用户真正会离开的这些点-这些可能是好的点。 但是,这当然还不是全部,因为您可以学习推荐,展示,鼓励用户使用它,但是却无法获得任何有形的利润(我们不会获得系统,用户,驱动程序的支持)。 因此,查看其他指标非常重要。 我们选择了两个。
如果我们告诉您驾驶员可以轻松驾车到达的降落地点,则应减少车辆的送货时间。 另一方面,如果用户在该位置更容易找到汽车,则更容易着陆,则应该减少驾驶员对驾驶员的等待时间。 这是我们的一些假设,这是理所当然的,这些是我们提出这些建议时要考虑的指标。 但是,当然,这些并不是要查看的唯一指标。 您可以提出更多的建议。 我认为你们每个人都可以提出一百个这样的指标。
这里还有更多示例。 这可能是旅行前取消预订的比例。 从理论上讲,如果用户更容易着陆,则应该减少该距离。 传统上,这些是当用户呼叫驾驶员试图找到他时的呼叫,或者相反,驾驶员在旅程开始之前呼叫用户。 这种呼吁得到了支持,并得到了许多其他支持。
我们已经解决了这个问题。 我们大致了解可以解决此问题的标准。 现在,考虑如何解决此问题。 首先想到的是:推荐任何此类经过验证且可以理解的着陆点。 幻灯片上是欧洲购物中心的一个示例。 而且我们可以肯定的是,您可以开车到这个购物中心的出口,这是一些指南,用户可以借助它找到司机。 它可以是任何组织。 某购物中心的ABC Taste有一个例子。 我认为这是埃里温广场。 这也是针对用户和驱动程序的某种指南,我们知道您可以在那里开车。
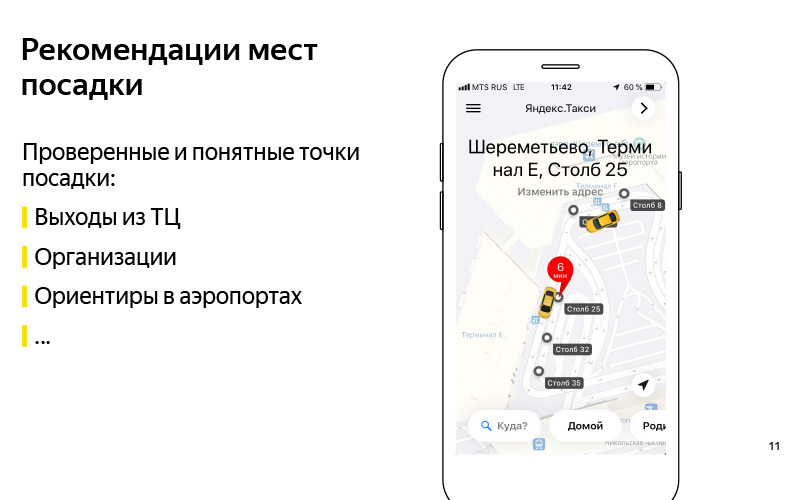
这些可能是我所说的机场的地标。 按照惯例,在谢列梅捷沃(Sheremetyevo)中有带数字的极点。 叫出租车上车很方便。 一个好的解决方案,但是有一个缺点,那就是它的伸缩性不是很好。 我们有许多国家/地区,数百个城市,大量不同的购物中心,机场,困难的交汇处,陌生的地方,这些地方很难手动设定,而要使其保持最新状态则更加困难。 正是在这里,我们被大声称为“人工智能”。 我更喜欢将其称为数据挖掘或机器学习。
机器学习需要某种数据,而我们实际上拥有这些数据。 自动解决问题的另一种方法是使用此数据。 高层的想法是,我们拥有有关GPS的数据,应用程序日志,并有一个路线图。 而且我们可以了解用户实际进入汽车的位置。 不是他们叫车的地方,而是他们着陆的地方。 基于此,执行类似的操作。

这些已经自动发送到我们的Yandex.Taxi团队目前所在的Aurora商务中心。
我高级别地谈到了我们的任务。 现在,让我们更详细地讨论解决此问题的阶段。 显然,有一个数据准备阶段。

我们有什么数据? 首先,我们有用户的GPS数据和驾驶员的GPS数据。 当他们使用我们的应用程序时,我们知道用户的大概位置。 显然,GPS的误差很大,大约在13至15米之间,但是还是有些误差。 其次,我们在应用程序日志中包含有关驱动程序何时从状态“我正在等待用户”切换到状态“我正在吸引用户”的信息。 可以假设,大约在这个时候,驾驶员等待着用户,用户上了车,然后他们开车了。 在这个地方附近,降落了。 我们有一个路线图。 道路图不仅是一组边线,街道,而且还包括其他元信息:障碍,停车信息等。基于此数据,您已经可以获取某种自动点。
这是源数据。 在出口处,我们想要两件事。 这些是一些所谓的着陆点候补。 它们是如何产生的? 很遗憾,无法播放视频。 大约发生以下情况。 我们有许多GPS点,我们知道驾驶员已经从“等待乘客”状态切换为“我们出发”状态。 我们可以有条件地将它们绘制到图上,也就是将它们投影到道路图上,因为通常汽车会从某个道路开始行驶。 在此图上,对这些点执行某种聚类。 为了吸引大量的候选人-这些是一些用户上车的地方,对他们来说这是正常的,方便的。 不是他们打电话到的地方,而是他们最终坐在那里的地方。
此后,当我们有很多候选人并且我们有一些在线用户时,我们知道他的位置,因此他打开了应用程序并想打车,然后我们可以从大量候选人中选择最佳的五个,并向他们展示。 最好的五个由机器学习模型确定,该模型学习根据当前用户当前的可能性(考虑到他的位置并考虑到他的旅行历史)对所有候选者进行最方便的离职排名。 大约以这种方式,我们可以自动生成这些点。 而且,如果他们在某个时候有条件地在某个地方挖车,也就是说,打电话叫出租车变得不舒服,或者在他们禁止停车的标志上某个地方,而驾驶员和使用者确实停止在该地方着陆,那么在某个地方一旦算法将了解这一点,数据将被更新。
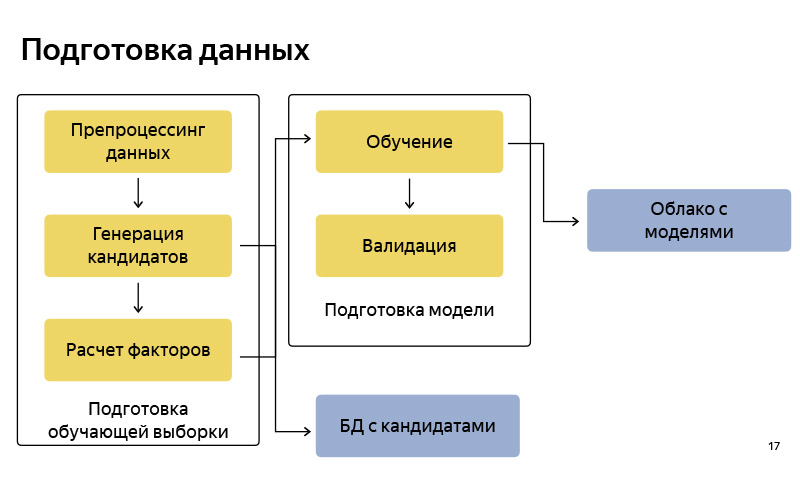
这大约是我们如何准备数据的框图。 因此,就像在任何机器学习管道中一样,这都是相当标准的。 有数据准备,根据算法有候选人的生成,我告诉了简化版。 我们将这些候选者存储在某个数据库中。 此后,我们准备一些用于训练的池(训练样本),其中有条件地包含用户,时间,元信息,一组候选者,并且知道用户最终从哪一点离开。 在此我们训练分类模型。 然后,根据概率的预测,对候选者进行排名。 模型准备好后,我们将其上传到存储良好的云中。
在准备数据时我们使用什么工具? 基本上,我们使用Python堆栈上的Python编写的所有数据准备工作:这些是标准的NumPy,Pandas,Scikit-learn等。我们有很多数据。 我们每个月有数百万次旅行。 有关GPS的大量数据,有关驱动程序的轨迹,应用程序日志的信息,因此我们需要在集群上对它们进行相同的处理。 为此,我们使用内部Yandex版本的MapReduce(称为YT),并且有一个用Python编写的库,该库允许启动某些映射器和化简器,并在大型集群上进行一些计算。
最后,当管道准备就绪时,我们需要对其进行自动化,以便数据是最新的,为此,我们使用诸如Nirvana和Hitman之类的东西。 这也是Yandex内部的开发。 Nirvana是一个集群计算管理框架。 实际上,她知道如何运行几乎任何程序,可以容错,可以跨DC(00:14:53)。 而且,如果发生故障,她知道如何重新启动它,以便在发生任何事件时创建启动。 等

这大致就是我们的MapReduce集群的Web界面。 在这里可以看出,我们有很多机器,在这些机器上执行计算。
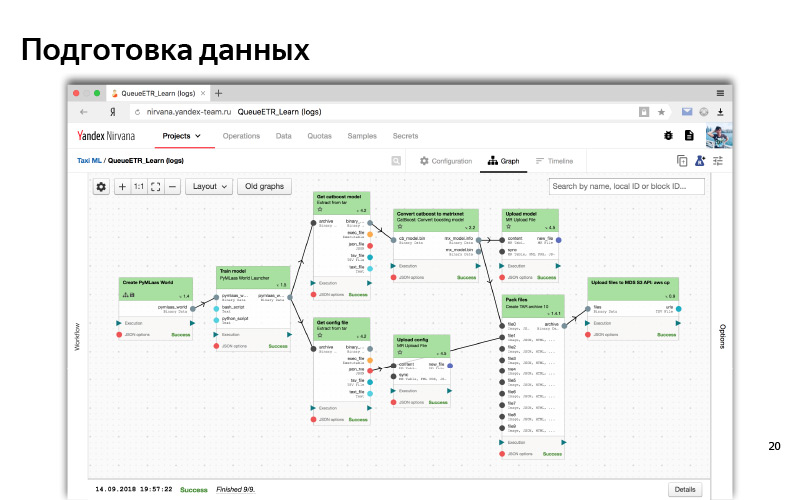
因此,在Web界面中,通常会进行某种类型的数据预处理和模型训练。 这是一个依赖图。 当一个部分(一个多维数据集)正在等待来自另一个多维数据集的数据时,依赖性就像数据。 和逻辑依赖性(首先我们准备了所有数据,然后开始训练)。 这是某种自动化系统。 为此,我们通常使用Python。
我们制定了问题,制定了成功标准,学会了以某种方式离线解决问题,甚至建立了某种模型,而且它似乎可以根据某些离线指标进行工作-它确实可以预测用户离开的要点,并找到这些要点看来,这应该减少等待时间和汽车交付。

让我们尝试这些模型,使用这些数据。 为此,请想象一下Yandex.Taxi服务是什么。
一个非常肤浅的图看起来像这样。 有用户,有一个应用程序,有驱动程序,还有一个称为“ Taximeter”的应用程序。 这些应用程序以某种方式与后端进行通信,而后端是一组相互通信的微服务-Ilya
谈到了这一点。 微服务之一是我们的服务,我们的团队做到了,它被称为ML即服务MLAaS。

您只需要了解他就是用C ++编写的MLaaS,它基于所谓的Fastcgi Daemon。 这是一个开放源代码库,大致来说,它是用于编写可获取和发布请求的Web服务器的框架,所有内容都是标准的。 它曾经是用Yandex编写的,并以开源的形式进行布局。 我们使用多色版本。 该服务可以做什么? 他知道如何使用模型:将它们应用,保留在家里甚至有时进行更新,转到这朵奇妙的云,在该云中定期更新,保存和下载模型。
每种功能,例如这些着陆点-在我们内部称为拾取点-或例如Ilya谈到的点B的提示,并且在上一份报告中不断提到,每种此类功能(其中存在某种机器学习)对应处理程序,它存储接收请求,生成机器学习因素,应用模型以及生成响应的逻辑。 当然,该服务不是孤立的,能够访问一些其他数据源,数据库和其他一些微服务。
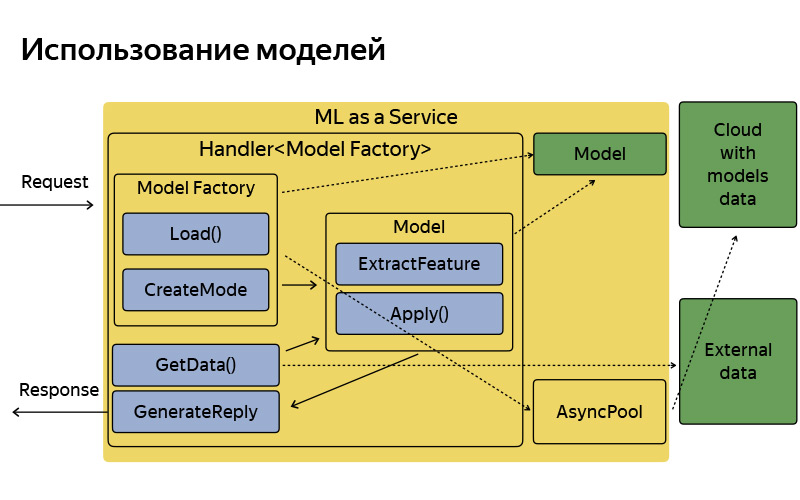
它是这样安排的,它具有相当简单的体系结构。 我不想详细介绍这张幻灯片,我只是想说,按照惯例,该体系结构非常简单。 请求到达时,有一些模型工厂,有时会从云中下载这些模型。 它们在内存中存储在一个副本中。 对于每个请求,都会创建一个相当轻量的模型对象,该对象将提取特征,应用并生成响应。

但是目前我们有什么? 我已经告诉过您,我们有数据准备,培训,各种研究,实验,所有这些都是用Python Stack编写的,还有一些用C ++编写的产品,仅仅是因为我们对效率和生产力有很高的要求。 当您生活在这样的生态系统中时,会出现两个问题。
首先,这是一个实验问题。 例如,在我们团队中工作的一位数据科学家就知道了。 如果运行参数稍有不同的某种聚类或分类算法,则可以获得更好的质量。 他试图离线测试其假设,并将其内置到我们的Python流程中,对其进行了计算,结果确实如此。 现在他要进行一次AB实验,也就是说,部分用户展示了新算法并测量了一些已经在线的指标:时间真的在减少吗? 为此,他有条件地拥有自己算法的五个版本,他认为其中有五个版本可以脱机提供良好的质量:用C ++实现并进行AB实验。 在进行该AB实验之后,也许所有这五个都将被浪费掉,也就是说,它们在网上的质量将比离线时还要差,也就是说,比生产中要差。 也就是说,由于有条件地使用两种不同的语言,两种不同的技术,因此实验过程需要很长时间。
这是针对现有功能的。 并且有新的。 一旦这些接载点也是我想快速检查的想法。 不要花两个月的开发时间-建议在三周内得到一些东西。 创建这样的原型非常费力。 首先,用Python编写功能的提取,只是因为它很方便-就像他们所说的那样快速移动。 您可以用Python建立任何原型,有许多资料分析库。 您在笔记本电脑上进行了实验,现在想检查一下用户。 要使原型变得非常困难。 我们得出的结论是,我们需要一些额外的服务,以便有条件地,在一周甚至一天内快速组装此类原型,并进行AB实验。
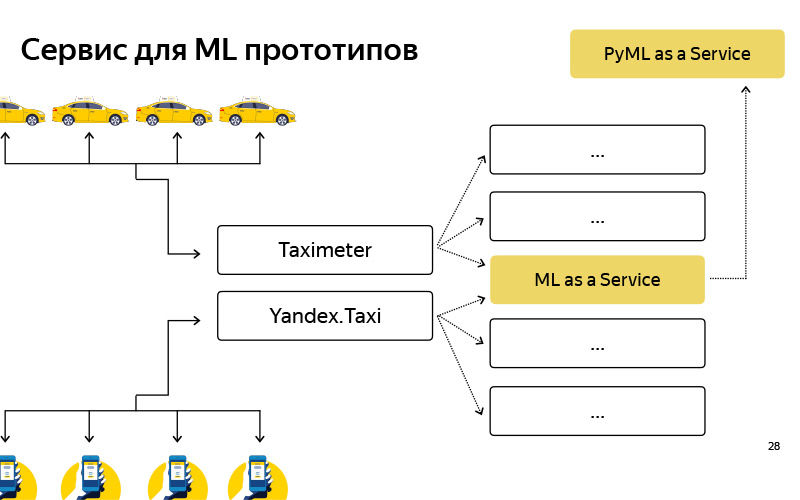
我们创建了这样的服务,称为PyMLaaS。 他是什么样的人? 实际上,这是MLaaS的完全类似物,我之前已经谈到过,但是它是基于Flask,nginx和Gunicorn的Python编写的。 该体系结构非常简单,与MLaaS相同,但是有机会从您的离线实验中快速挖掘出一些原型。 此外,我们在nginx级别上安排了此类代理,因此,有条件地,我们有机会将部分负载从MLaaS转发到PyMLaaS,从而进行实验。

也就是说,我们移动了一些参数,并希望检查它如何影响用户。 我们开始在PyMLaaS上加载了5%的负载,然后我们将看看实验中会发生什么。 最后,创建原型很方便。 我创建了一些新功能的原型,在PyMLaaS中看到了它,您可以立即在生产中对其进行测试。
我们非常喜欢它,以至于提出了这个主意-为什么不一直使用它? 因为有条件地存在某些功能,这些功能要求大的负载,1000 RPS和大的内存需求。 我想要一个相当灵活的并行性。 但是对于某些功能,某些对负载,性能,RPS等要求不高的产品或服务,我们已经相当成功地使用了该服务。

总结一下。 , . . . , - , , , -, - . - PyMLaaS, AB-, . , MLaaS, , .
pickup points — . . , . 30% , . .