你好 去年年底,我们开始自动在Avito公告卡中的照片上隐藏车牌号。 关于我们为什么这样做,以及解决此类问题的方法有哪些,请阅读本文。

挑战赛
2018年在Avito售出250万辆汽车。 每天将近7000。 所有待售广告都需要插图-汽车照片。 但是通过状态编号,您可以找到许多有关汽车的信息。 我们的一些用户尝试自行关闭车牌。
用户想要隐藏车牌号的原因可能有所不同。 就我们而言,我们希望帮助他们保护数据。 并且我们尝试改善用户的买卖过程。 例如,匿名号码服务已经与我们合作了很长时间:当您出售汽车时,会为您创建一个临时的手机号码。 好吧,为了保护车牌上的数据,我们将照片匿名化。

解决方案概述
要自动化保护用户照片的过程,可以使用卷积神经网络来检测带有车牌的多边形。
现在,为了检测对象,使用了两组的体系结构:两级网络,例如Faster RCNN和Mask RCNN。 单级(单快照)-SSD,YOLO,RetinaNet。 检测物体是导出感兴趣物体所刻入的矩形的四个坐标。
上面提到的网络能够在图片中找到许多不同类别的对象,这对于解决车牌搜索问题已经是多余的,因为我们通常在图片中只有一辆汽车(人们拍摄他们所售汽车及其随机邻居的照片时会有例外。 ,但这种情况很少发生,因此可以忽略)。
这些网络的另一个功能是,默认情况下,它们会生成一个边界框,其边界平行于坐标轴。 发生这种情况是因为使用了一组称为锚框的预定义类型的矩形框架进行检测。 更准确地说,首先使用卷积网络(例如resnet34),从图片中获取属性矩阵。 然后,对于使用滑动窗口获得的每个属性子集,都会进行分类:是否有第k个锚框的对象,并对框架的四个坐标进行回归,从而调整其位置。
在此处阅读有关此内容的更多信息。
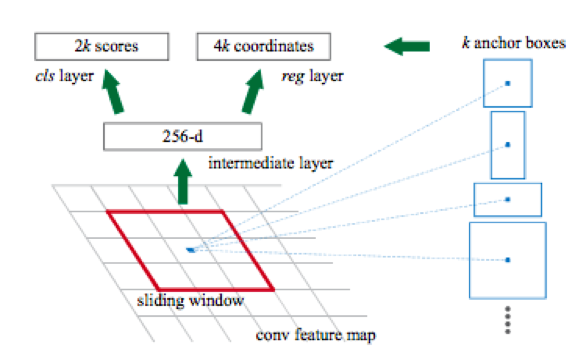
此后,还有两个负责人:
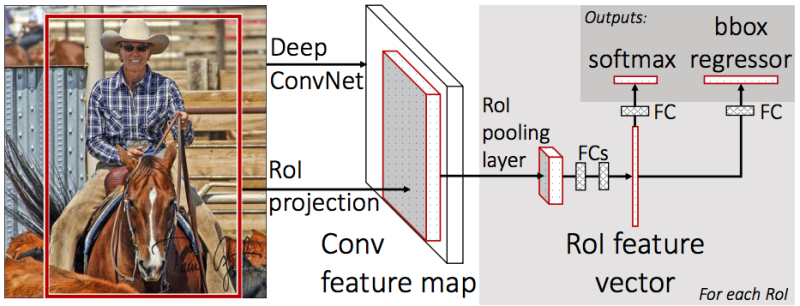
一个分类对象(狗/猫/植物等),
第二个(bbox回归器)-用于回归上一步中获得的框架的坐标,以增加对象的面积与框架的面积之比。
为了预测旋转的拳击框,您需要更改bbox回归器,以便获得框架的旋转角度。 如果不这样做,它将以某种方式出现。

除了两阶段的Faster R-CNN,还有一阶段的检测器,例如RetinaNet。 它与以前的体系结构的不同之处在于,它可以立即预测类和帧,而无需提议可能包含对象的图片部分。 为了预测旋转的蒙版,还必须更改box子网的头部。
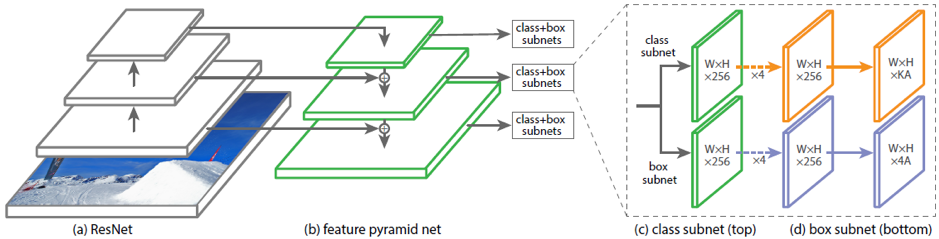
DRBOX是用于预测旋转边界框的现有体系结构的一个示例。 该网络未使用该地区提案的初步阶段,如Faster RCNN;因此,它是对一阶段方法的修改。 为了训练该网络,使用以特定角度旋转的K边界框(rbox)。 网络预测每个K rbox包含目标对象,坐标,bbox大小和旋转角度的概率。

修改架构并使用旋转的边界框对数据中考虑的网络之一进行重新训练是一项可实现的任务。 但是我们的目标可以轻松实现,因为我们拥有的网络范围要狭窄得多-仅用于隐藏车牌。
因此,我们决定从一个简单的网络开始,以预测数字的四个点,随后便有可能使体系结构复杂化。
资料
数据集的组装分为两个步骤:收集汽车图片并在上面标有车牌的区域。 我们的基础架构已经解决了第一个任务:我们仔细存储了放置在Avito上的所有广告。 为了解决第二个问题,我们使用Toloka。 在
toloka.yandex.ru/requester上,我们创建一个任务:
任务给了汽车的照片。 必须使用四边形突出显示汽车的车牌。 在这种情况下,状态编号应尽可能准确地分配。

使用Toloka,您可以创建用于标记数据的任务。 例如,评估搜索结果的质量,标记不同类别的对象(文本和图片),标记视频等。 它们将由Toloka用户执行,需要您付费。 例如,在我们的案例中,驾车者必须在照片中突出显示带有汽车牌照的垃圾填埋场。 通常,标记大型数据集非常方便,但是获得高质量非常困难。 人群中有很多机器人,它们的任务是通过随机给出答案或使用某种策略从您那里赚钱。 为了对抗这些机器人,有一套规则和检查系统。 主要检查是控制问题的混合:您可以使用Toloki界面手动标记部分任务,然后将其混合到主要任务中。 如果标记经常被误认为是控制问题,则可以将其阻止,而不考虑标记。
对于分类任务,确定标记是否错误非常简单,对于突出显示区域的问题,并不是那么简单。 经典方法是计算IoU。
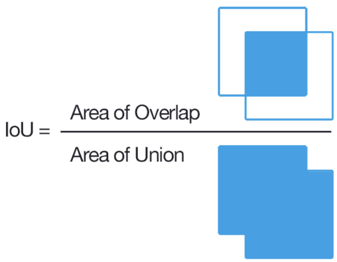
如果该比率小于几个任务的某个特定阈值,则将阻止该用户。 但是,对于两个任意的四边形,计算IoU并不是那么简单,尤其是因为在Tolok中必须在JavaScript中实现它。 我们进行了一次小小的尝试,我们相信,如果在一个小社区中,对于源多边形的每个点,都有一个标有划线的点,那么用户就不会错。 还有一条快速响应规则,可阻止响应用户过快,验证码,与大多数意见不符等。 设置了这些规则后,您可以期望获得不错的标记,但是如果您确实需要高质量和复杂的标记,则需要专门聘请自由职业者-书写者。 结果,我们的数据集总计有4k个标记图像,在Tolok的价格均为28美元。
型号
现在,让我们建立一个网络来预测该区域的四个点。 我们将使用resnet18来获得标志(resnet34的参数为11.7M,resnet34的参数为21.8M),然后我们将头回归到四个点(八个坐标),并对图片中是否有车牌进行分类。 需要第二个标题,因为在销售汽车的广告中,并非所有带有汽车的照片。 照片可能是汽车的细节。

当然,与我们相似,没有必要进行检测。
我们通过将没有边界框(0,0,0,0,0,0,0,0,0,0)目标的牌照照片和分类器“带有/不带有牌照的图片”的值添加到数据集中来同时训练两个目标。 1)。
然后,您可以为两个目标创建单个损失函数,作为以下损失的总和。 为了回归到车牌多边形的坐标,我们使用平滑的L1损失。
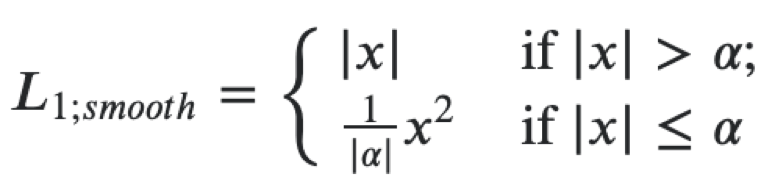
它可以解释为L1和L2的组合,当自变量的绝对值较大时,其行为类似于L1;当自变量的值接近零时,其行为与L2相同。 对于分类,我们使用softmax和交叉熵损失。 特征提取器是resnet18,我们使用ImageNet上预先训练的权重,然后我们将进一步训练数据集中的提取器和头部。 在此问题中,我们使用了mxnet框架,因为它是Avito中用于计算机视觉的主要框架。 通常,微服务体系结构允许您不受特定框架的束缚,但是当您拥有大量代码库时,最好使用它,而不必再次编写相同的代码。
在我们的数据集上获得可接受的质量后,我们求助于设计师为我们获取带有Avito徽标的车牌。 当然,起初我们尝试自己动手做,但是看起来并不漂亮。 接下来,您需要使用牌照将Avito牌照的亮度更改为原始区域的亮度,然后可以将徽标覆盖在图像上。

在产品中启动
结果的可再现性,项目的支持和开发的问题在后端和前端开发的世界中以一定的错误解决,但在使用机器学习模型的地方仍然存在。 您可能必须了解遗留代码模型。 如果自述文件具有该解决方案所基于的文章或开源资源库的链接,那将是一个很好的选择。 开始重新训练的脚本可能会因错误而失败,例如,cudnn版本已更改,并且该版本的tensorflow不再适用于此版本的cudnn,并且cudnn不适用于此版本的nvidia驱动程序。 也许为了进行培训,我们根据数据使用了一个迭代器,而在生产中测试了另一个迭代器。 这可以持续相当长的时间。 通常,存在再现性问题。
我们尝试使用nvidia-docker环境中的训练模型删除它们,它具有suda的所有必需依赖关系,并且我们还在其中安装了python依赖关系。 根据数据,扩充和推理模型,带有迭代器的库版本在训练/实验阶段和生产中很常见。 因此,为了在新数据上训练模型,您需要将存储库泵送到服务器,运行将收集docker环境的shell脚本,jupyter笔记本将在其中存储。 在内部,您将拥有所有用于培训和测试的笔记本,由于环境的原因,这些笔记本当然不会因错误而失败。 当然,最好有一个train.py文件,但是实践表明,您始终需要目睹模型所提供的功能并在学习过程中进行某些更改,因此最终您仍将运行jupyter。
模型权重存储在git lfs中-这是一种用于在git中存储大文件的特殊技术。在此之前,我们使用了人工制品,但使用git lfs更为方便,因为使用该服务下载存储库后,您可以立即获得秤的最新版本,就像在生产中一样。 自动测试是为模型推断而编写的,因此您将无法推出权重无法通过的服务。 服务本身是在kubernetes集群上的微服务基础架构内的docker中启动的。 为了监控性能,我们使用了grafana。 滚动之后,我们使用新模型逐渐增加服务实例的负载。 推出新功能时,我们会根据统计测试创建/ b测试,并对功能的未来命运做出判断。
结果是:我们为私人交易者在自动类别的广告中启用了数字修饰,一幅图像隐藏数字的处理时间的95%为250毫秒。