我创建了Kube Eagle-Prometheus的出口商。 事实证明这是一件很酷的事情,有助于更好地了解中小型集群的资源。 结果,我节省了一百多美元,因为我选择了正确的计算机类型并为工作负载配置了应用程序资源限制。
我将谈论Kube Eagle的好处,但首先,我将解释为什么大惊小怪,为什么需要质量监控。
我管理了几个4-50个节点的集群。 在每个集群中-多达200个微服务和应用程序。 为了更好地利用可用硬件,大多数部署都配置了可爆RAM和CPU资源。 因此,必要时Pod可以占用可用资源,并且同时不干扰此节点上的其他应用程序。 好吧,不是很好吗?
尽管群集消耗的CPU(8%)和RAM(40%)相对较少,但是当他们尝试分配超出节点可用内存的内存时,我们经常遇到无法解决的问题。 那时我们只有一个面板来监视Kubernetes资源。 这是一个:
仅具有cAdvisor指标的Grafana仪表板
有了这样的面板,占用大量内存和CPU的节点就不成问题。 问题是找出原因。 为了使Pod保持在适当的位置,您当然可以在所有Pod上配置有保证的资源(请求的资源等于限制)。 但这不是最聪明的铁用途。 群集上有数百GB的内存,而有些节点却挨饿,而其他节点则有4-10 GB的备用空间。
事实证明,Kubernetes调度程序在可用资源之间分布不均。 Kubernetes Scheduler考虑了各种配置:亲和力,污点和容忍规则,可以限制可用节点的节点选择器。 但是在我的情况下,没有什么比这更好的了,并且根据每个节点上请求的资源来计划Pod。
对于炉床,选择了一个具有最多可用资源并满足请求条件的节点。 原来,节点上请求的资源与实际使用不匹配,因此,Kube Eagle及其监视资源的能力得以解决。
我几乎所有的Kubernetes集群都仅使用Node exporter和Kube State Metrics进行跟踪。 Node Exporter提供I / O和磁盘,CPU和RAM使用情况的统计信息,而Kube State Metrics显示Kubernetes对象的度量标准,例如对CPU和内存资源的请求和限制。
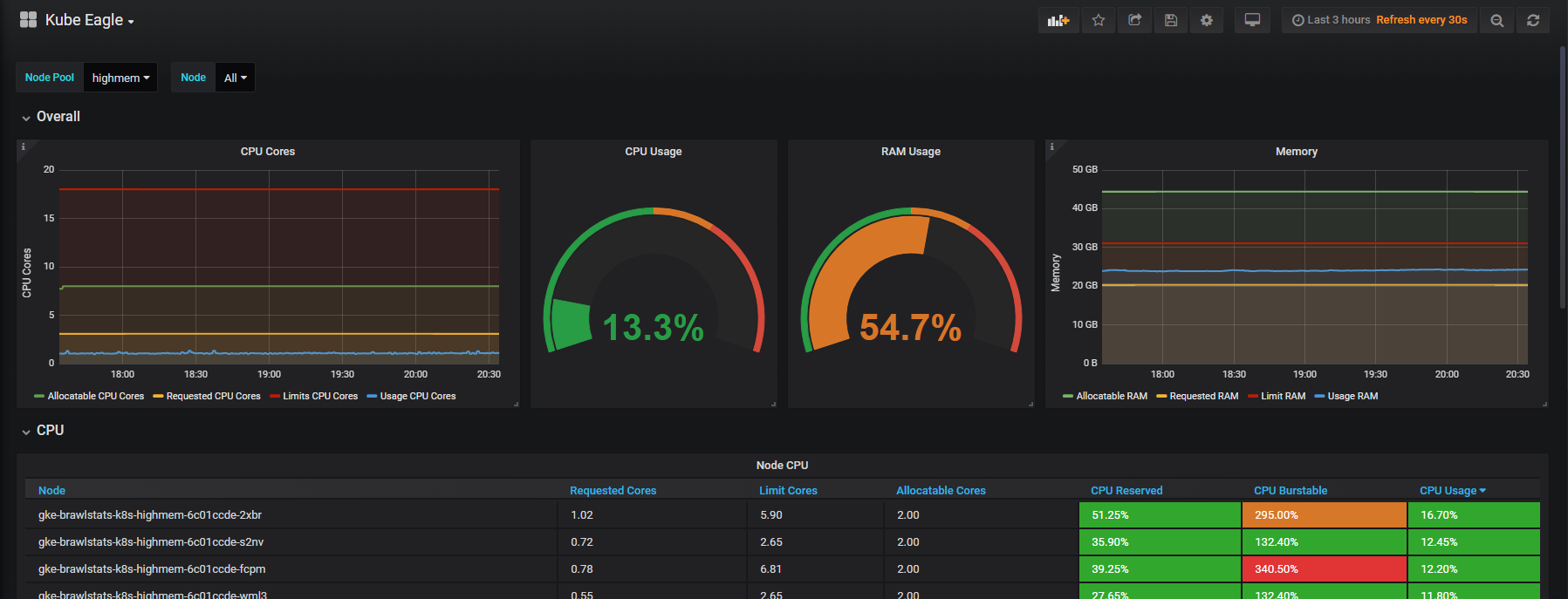
我们需要在Grafana中将使用情况度量与请求和限制度量结合起来,然后获得有关该问题的所有信息。 听起来很简单,但实际上在这两个工具中,标签的名称不同,并且某些指标根本没有元数据标签。 Kube Eagle自行完成所有操作,面板如下所示:
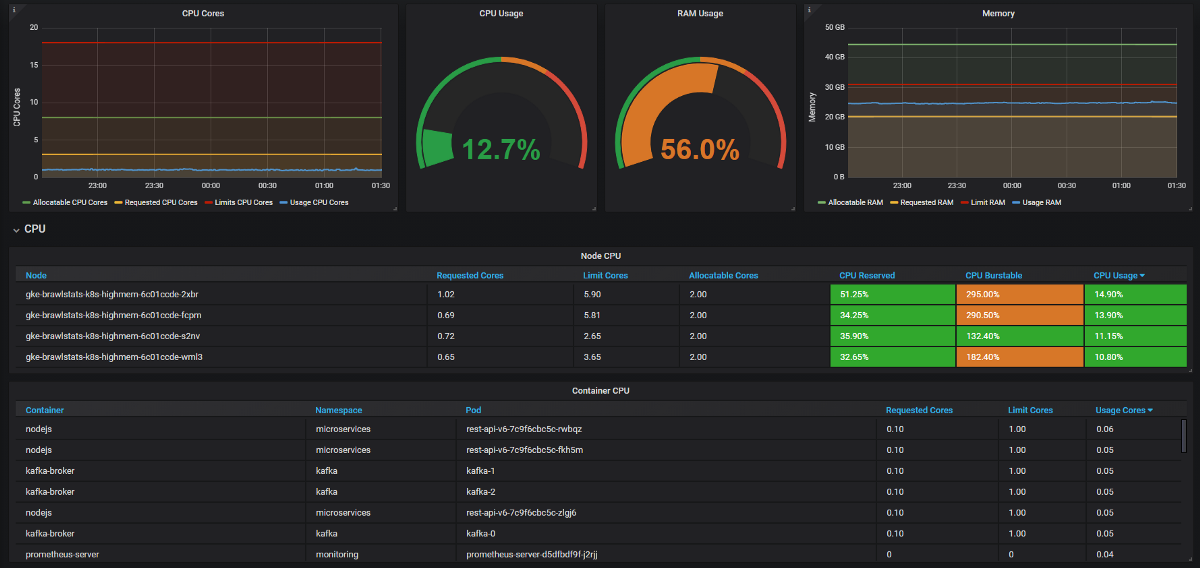
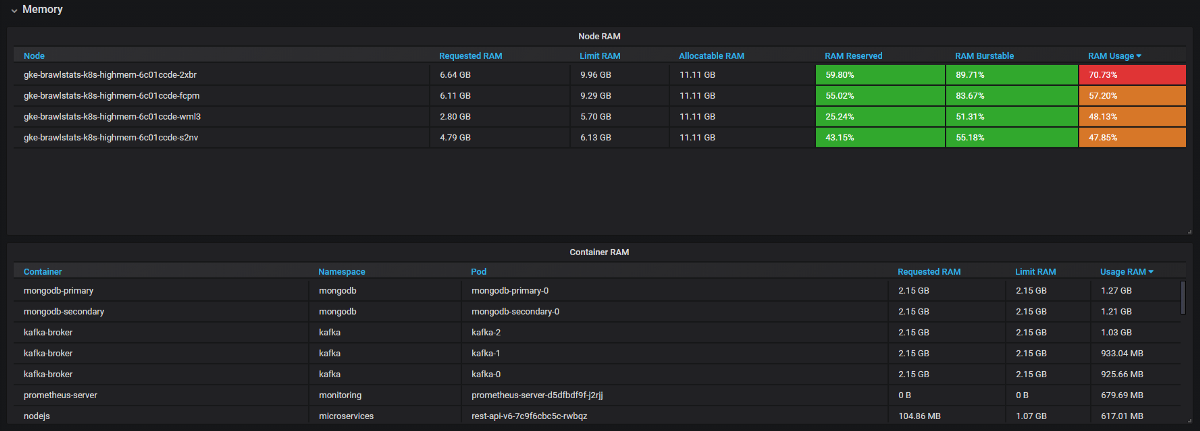
Kube Eagle仪表板
我们设法解决了许多资源问题并节省了设备:
- 一些开发人员不知道微服务需要多少资源(或者根本就不打扰)。 我们没有找到错误的资源请求的方法,为此,我们需要了解消耗量以及请求和限制。 现在,他们可以看到Prometheus指标,监视实际使用情况并微调查询和限制。
- JVM应用程序占用的RAM与其所占用的内存一样多。 仅当涉及到超过75%时,垃圾收集器才会释放内存。 而且由于大多数服务都具有易爆的内存,因此JVM一直都在占用它。 因此,所有这些Java服务消耗的RAM比预期的要多得多。
- 一些应用程序需要太多内存,并且Kubernetes调度程序没有将这些节点分配给其他应用程序,尽管实际上它们比其他节点更自由。 一位开发人员不小心在请求中添加了一个额外的数字,并抓住了一大块RAM:20 GB而不是2 GB。没有人注意到。 该应用程序具有3个副本,因此3个节点受到影响。
- 我们引入了资源限制,用正确的请求重新计划了吊舱,并获得了在所有节点上使用铁的完美平衡。 通常可以关闭几个节点。 然后,我们发现我们使用了错误的机器(面向CPU,而非面向内存)。 我们更改了类型并删除了一些其他节点。
总结
有了集群中的可爆资源,您可以更有效地使用现有硬件,但是Kubernetes调度程序会根据资源请求调度Pod,这很麻烦。 用一块石头杀死两只鸟:为避免问题,并充分利用资源,需要良好的监控。 Kube Eagle (Prometheus出口商和Grafana仪表板)对此很有用。