
“如果您用手中的锤子,一切都看起来像钉子”
作为数据的从业者,科学家致力于数据分析,其收集,净化,充实,我们根据数据建立和训练我们周围世界的模型,我们发现数据之间的内部关系和矛盾,有时甚至没有。 当然,这种沉浸感只会影响我们对世界的看法和理解。 职业变形以与其他职业相同的方式出现在我们的职业中,但是它究竟带给我们什么,又如何影响我们的生活?
免责声明
本文并不声称是科学的,没有表达ODS社区的单一观点,而是作者的个人观点。
前言

如果您对我们的大脑如何工作,对周围世界的感知以及我们在这里所做的事情感兴趣,那么本文中描述的许多内容对您来说并不是什么新鲜事物。 以一种或另一种形式,已经从完全不同的角度多次描述了所有这些。 我的任务是尝试从数据分析师的角度看待所有这些问题,并在我们在工作中使用的工具和方法以及在监视器外部的现实生活之间取得相似性。
引言

首先,想象一下稍微简化的设置:
在我们周围,有一个世界可以生存并在其中成功运作,一个人需要了解他(这个世界)代表什么,如何与他互动以及从各种互动中获得什么结果。 也就是说,一个人需要一个能够充分解决其当前任务的周围世界模型 。 关键是“ 当前任务 ”。 当生存任务放在首位时,世界模型首先建立在对危险的快速认识和对危险的充分反应上。 也就是说,那些模式较差的人-无法将其传递下去;模型较好的人-将其传递给后代。 随着生活条件的改善,该模型的重点开始从单纯的生存转变为更加有条理的事物,并且环境越安全,这种“事物”就越多样化。 “某物”的范围非常广泛-从比特币和DS到激进的女权主义和宽容。
大自然创造了我们的大脑来解决资源有限条件下的生存问题-食物不足,没有足够的能量来容纳任何垃圾,因此,为了生存,必须解决两个相互排斥的任务:
- 发现世界,改善模型,增加生存机会(这是一项非常耗能的任务)
- 不要因缺乏精力而死
大自然非常巧妙地解决了这个难题,当能量实际上并没有浪费在解决与外界交互的基本问题上(在当前模型的框架内)时,自然界就向我们的大脑引入了缓存数据流和反应的能力。
您可以在D. Kahneman的出色著作“ 慢慢思考,迅速做出决定 ” [1]和“ 注意力和精力 ” [3]中阅读有关这种缓存方法和“注意力资源理论”的更多信息。
根据D. Kahneman:
心理学家区分两种思维方式,我们将其称为系统1和系统2。
系统1自动且非常快速地工作,无需或几乎不需要任何努力,也不会产生故意控制的感觉
系统2给出了有意识的精神努力所必需的注意力,包括复杂的计算。 系统2的动作通常与活动,选择和专注的主观感觉相关。
从童年到死亡,我们的大脑中的行为,反应和反应模式都被编程(形成并改变世界的模型)。 有两个因素取决于模型形成所处的阶段-接受更改的速率和更改所需的能量。 在儿童时期,当模型变得越来越灵活时,速度很快,能源成本也最小。 模型越密集,更改模型所需的能量就越多。 不仅如此, 还需要能量,以便一个人只想更改模型中的某些内容 。 而且任何能量的浪费都由大脑控制,他太不情愿允许它被消耗了。
更改模型的命令将被大脑拒绝(这仍然很耗能量,但是为什么呢,因为我们一切都很好),直到在旧模型的框架内运行会威胁生存。 好吧,或者直到自发性爆发吸收能量(由于某些东西而受到冲击,心理打击等)
TL / DR:
- 为了生存,一个人在脑海中建立了周围世界的模型,以解决当前的任务
- 解决任何问题时,大脑都会尝试将能量消耗降至最低。
- 在System-1(Kahneman)框架内耗能最少的操作,无法做出更改决策
- 能源消耗最大的是在System-2的框架内运行,做出有关更改模型和更改模型本身的决策

因此,为了与外界互动,一个人在大脑中建立了一个世界模型,并尽可能长地遵循该模型(再次记住要使能源成本最小化)。 但是,一个人不幸或幸运的是,是一种社会动物-我们无法与其他人互动,而且这种互动常常使我们感到困惑。
为了有效地与其他人互动, 我们在脑海中建立了这些人的行为模型 ,即在存在某些数据的情况下他们在特定情况下的行为模型。 也就是说,我们正在建立该特定人员周围世界模型的模型 。
停下来想一想- 一个人的头脑中的世界模型是不完美的,仅满足他自己的充足性和充分性标准 ,因此我们建立了这个(奇怪的)模型的模型,并根据我们的模型与这个人进行交互。 是的, 我们也希望人们按照我们的“他的模型”告诉我们的那样做 。 乐观吗? 是的,不只是...。
要构建和训练适当的模型,我不需要告诉您,您需要大量的时间,精力和数据。 而且我们经常没有一个或另一个,并且模型拥有的自由度(参数)越多,需要的数据就越多-维数的诅咒,还记得吗?
而且生活过得很快,时间很短,因此(System-1可以正常工作),结识一个人,甚至在某些条件下与他沟通,我们都选择了一个预先编译的模型模板,该模板已经存在到头部(“ b子”,“正常孩子”,“ molehill”,“恰好”号; ak等),对于特定情况,可能需要一些提示。
是的,当然,也有例外,有些人在时间或精力上都不会为他们感到抱歉,并且我们一生都知道。 但是在这种情况下,我们只知道此人模型中的那个人。
接下来会发生什么? 一些明显的事情:
好吧, 首先 ,科学家对他人不感到不满的日期。
从字面上完全可以。 在他的词汇中没有“怨恨”一词。 怎么了 一切都很简单-任何侮辱的根源在于我们的误解:
- 他(她)怎么能(说,做,做)?
- 还是不 (说,做,做)?
也就是说,在我们这个人的模型中,他在特定情况下使用特定的信息输入包应该以这种方式起作用,但是他没有这样做。 那个混蛋,是吗? 是的,他不是一个混蛋,但是我们对这个人的模型是错误的。 我们错过了其中的某些内容,或者根本没有针对特定的情况而迷,而只是获取了一个模板,或者当前情况下的输入数据与我们训练模型所依据的不同。
在这种情况下该怎么办? 与往常一样,我们将研究数据中存在的问题,并使用新信息对模型进行过度训练。
其次 ,科学家的约会没有反映“ 互联网上某人错了 ”。
它不仅可以在Internet上运行,而且还可以在工作中,在社会中使用。 如果一个人不了解某件事(在您看来),或者不了解,但不以您的方式理解,那么也许他只是对世界的这一部分拥有完全不同的模型 。 为了说服这一点,即 让他更改自己的模型(尤其是如果他不想这么做)非常困难且非常耗能。 需要吗
一个完全不同的选择是,当一个人准备改变他的模型时,他想要扩展或收紧它,而他为此拥有力量和精力。 您可以帮助-无法帮助-直接向可以的人提供帮助。 您既不能帮助也不能指导-不要干涉 。
下次,如果您认为某人“错”或“不懂某事”,请不要与他激动。 在他的世界模型中,一切都不同。 模型越粗糙,越“简单”,至少使它脱离平衡点所需的能量就越大 ,更不用说更改某些东西了。
第三 ,科学家的约会记住了“ 事物永远不是它们看起来的样子 ”的原理。
了解此系统的工作原理后,就有机会模仿,适应一些基本模板,使其对您当前所处的社会非常熟悉,直到您脱离该模板,一切都会好起来的。 它可以双向工作,所以请不要忘记-“ 猫头鹰不是看起来的样子 。”
“将绳索视为蛇与将绳索视为绳索一样虚假”(C)
模型建立与培训

作为科学家的约会,我们深知建立,训练和不断地重新训练或多或少合适的模型是多么困难。 因此, 科学家的约会冷静而耐心地提及其他人头脑中模型的不完善,并不断完善自己的模型 。 而且由于他仍然是专业人员,所以他完全记得成功建模的基本原则:
发生了什么事情(垃圾进-垃圾出)。
模型的准确性和充分性更取决于数据的纯度,而不是其他任何因素。 我们都知道,我们花费大量时间清理数据,预处理,规范化等等,等等。 输入垃圾模型-结果是可预测的。 喂她清除的归一化数据-并在您的口袋里提供见解。 我们头脑中的模型工作完全相同。 了解了这一点, 我们尝试使用最准确,最干净的数据进行处理和培训,不断地用肉眼分析数据的充分性,并努力防止模型中出现肮脏和嘈杂的信息 。 简而言之-请阅读Habr,不要观看第一个频道。
训练与测试(我们的头痛)之间的区别
科学家理解,该模型的适用性直接取决于该模型所研究和应用的分布的相似性 。 一个社会的行为规则在另一个社会不起作用,一个领域的成功原则不适用于另一个社会,基于我母亲的故事而建立的异性“典型行为模式”突然变得不那么正确,等等。
我们始终考虑到用于训练世界模型的训练数据集与应用模型的实际数据集的可能差异。
简而言之, 我们了解差异的原因,并准备花费精力对模型进行预训练,以使其更接近实际情况。
目标函数的选择和多领域学习
通过更改目标函数,几乎所有任务都可以转移到另一个域。 问题不是作为回归解决吗? 重做类的目标并将其作为分类任务解决。 更好的是,让两个人并列,让一个解决一个问题,第二个重新制定。 在同一数据集上,可以训练两个不同的模型,并在完全不同的事物上进行改进。 请记住,当您的最终目标功能一次涵盖多个领域时 , 最好的选择就是生活中的多领域学习 。 例如,在工作中,您可以赚钱,仍然可以下载专业技能,还可以提高社交互动能力。 与常规模型一样,这种方法最终可以丰富和改进所有多域目标,就像我们单独下载它们一样。 而且不要忘记时间- 三种用于个人目的的模型需要三倍的时间,而在现实生活中并不需要那么多时间 ,而且不幸的是,您无法将训练并行化为十二个或两个TPU。
分块训练(分批学习)
长期以来,分批进行模型训练已被证明是有效的。 如果您不考虑需要在线培训的特定领域,那么仅在经历了整个时代之后才更新权重是没有意义的。 是的,分批训练会产生高频噪声,但这可以被较高的收敛速度和几乎相同的精度所抵消。
这给了我们什么? 理解等待很长时间,然后根据新数据稍微更改您的世界模型是没有意义的。 不用等待整个时代,嗯,我不知道,一年的新工作,一年的新人交往, 更频繁的变化-您会更快地朝着自己的最终目标迈进 ,好吧, 探索会带来更多的机会。 一次事件后喊“一切都丢失了”也是毫无意义的 ,也许只是爆发,也许恒星已经像这样发展了,等到批处理结束,积累错误-然后更改模型。
超参数搜索方法(网格搜索与随机搜索)
有很多关于该主题的文章( 示例 ),当搜索最佳超参数时,随机排序比网格搜索更好。 因此,在我们的情况下, “随机”动作的选择最好是真正进行“伪随机”操作,而不是严格按照某个预定的网格进行 。 严格的方法的拥护者和拥护者现在会践踏我,但认真地说, 机会统治着世界 ,而且奇怪的是,使用这种方法可能更加合理。
当然,更好的是使用贝叶斯优化 。 但是在这里,我不了解如何将其应用于现实生活。 不是使用贝叶斯方法来理解信息,而是选择超参数时的贝叶斯优化 。
合奏
我们都知道集成的力量,其中每个模型都以自己的方式查看数据,从中提取一些信号,并且通过在一级模型之上使用元模型来获得最佳结果。 在生活中,一切都完全一样, 您不仅可以根据自己的经验来建立自己的世界模型,而且可以从他人的世界模型中吸收最好的东西(反之亦然,理解并消除最坏的情况)。 这些模型在书籍,电影中都有描述,只要观察其他人的行为,您就可以了解他们所拥有的模型,采用最佳模型并建立自己。
回想一下“很多事情对我们来说是令人难以理解的,不是因为我们的概念薄弱,而是因为这些东西没有包含在我们的概念圈中。” 科兹马·彼得罗维奇(Kozma Petrovich)理解了有限模型的问题,甚至没有成为科学家的实习日期。 :)
不同的人,不同的环境,不同的数据-不同的模型,甚至是看似显而易见的事物。 如果您在大型公司工作,您可能还记得所有关于行为,沟通规则,骚扰等无休止的培训。 怎么了,你想。 但是不,不是垃圾。 在大型国际公司中(由于文化,思想和价值观的差异),仅需在每位员工的模型中引入一层基本原则,以确保正常的互动和工作。
TL / DR
- 您在这个世界上正在发生的事情,只有您和您的世界模型应该受到指责
- 他人的世界模型不必与您自己的模型相关联
- 您的其他人的世界模型的元模型很可能与现实不符
- 很难在您的头脑中创建一个开放的世界模型,并根据贝叶斯原理为变化做好准备。 终生将其保持在这种开放状态下甚至更加困难。 留一个人很难
幕后花絮
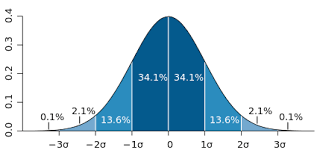
中心极限定理
正如CTC所说,从任何类型的弱相关分布中采样的随机事件的总和本身就是一个随机变量,并且在限制范围内呈正态分布。
我们的一生包括一些随机事件 :电梯或公共汽车在车站的等待时间,您是否错过弯道等等。 您可以有条件地将一天评估为成功还是失败(另一个随机变量),具体取决于我们在最终分布中的位置-中心还是尾部。 在足够大的样本(例如一年)中,可以看出我们的随机变量呈正态分布,以“ 好吧,或多或少一切正常 ”为中心
科学家理解以上所有内容的日期, 如果属于所谓的日期,就不会蒸腾 一切都不好时出现“黑线” -公交车在鼻子下面,倒了咖啡,没有保存代码,等等。 他了解,今天我们有分配的尾巴,我们只需要在这一天生存就可以了 ,明天,也许世界将以稍微不同的方式向我们提供事件采样。
顺便说一下, 过渡到新的事件参考点(一组新的样本)是一个梦想 。 不是日历日,不是午夜,而是醒后的主观新的一天。 我们的祖先直觉地理解了这一点(尽管他们不了解xgboost和keras),而谚语是从这里“ 早上更明智 ”和“ 如果您想工作,上床睡觉,一切都会过去 ”。
— “ ” ( p-value “”), , - ( , ), .
, “ ”. . [1].
, - , . , , , - )
, “ , ”.
(Exploitation vs Exploration)
, , . , , , — “ — ! ”. , , , , - , , , - .
… . - , . ( ), , , - . , “ , ”. , , . . , - , .
“ ” RL( Reinforcement learning ). , , , , , , . , , , , - , , . RL . , ( ) , , , - .
, , , , exploration , .
, , , , - , . , “ — ” “ — ”.
, “” . , , , “ ”, .
, - (, , ..) “”, , , .
- , , -1. , , , , .., .. . , -2. . , , -2 , , .
“ ”
, , , -1 , .
, “ , ” (). . , , - , , , . , , , , , , , .
TL/DR
- ,
- . ,
- (exploration)
- , . , - , 1
结论

, - , , , , , .
- . … . — .: , 2013. — 625 .
- ., ., . : ., : , 2005. — 632 . — [ISBN 966-8324-14-5]
- . / . . . . . — .: , 2006. — 288 .
- . , “ : "