在2019年2月至3月,举行了比赛以对SNA Hackathon 2019社交网络供稿进行排名,其中我们的团队获得了第一名。 在本文中,我将讨论比赛的组织,我们尝试的方法以及大数据培训的加速设置。

SNA Hackathon
这个名字下的黑客马拉松赛第三次举行。 它分别由ok.ru社交网络组织,任务和数据直接与此社交网络相关。
在这种情况下,最好将SNA(社交网络分析)理解为不是对社交图的分析,而是对社交网络的分析。
- 2014年的任务是预测该帖子将获得的喜欢人数。
- 在2016年,VVZ的目标(也许是您熟悉的)更加接近社会图的分析。
- 在2019年-按用户喜欢该帖子的可能性对用户的供稿进行排名。
我不能说2014年,但是在2016年和2019年,除了具有分析数据的能力外,还需要处理大数据的技能。 我认为正是机器学习和大数据处理任务的结合才吸引了我参加这些竞赛,这些领域的经验也为我赢得了胜利。
mlbootcamp
在2019年,比赛在https://mlbootcamp.ru平台上组织。
比赛于2月7日在网上开始,共有3项任务。 每个人都可以在该网站上注册,下载基线并上载汽车几个小时。 3月15日,在线阶段结束时,每场演出的前15名都应邀到Mail.ru办公室参加离线阶段,该阶段于3月30日至4月1日举行。
挑战赛
源数据提供用户标识符(userId)和帖子标识符(objectId)。 如果向用户显示了一个帖子,则数据包含一行,其中包含userId,objectId,用户对此帖子的反应(反馈)以及一组各种符号或指向图片和文字的链接。
| userId | objectId | ownerId | 意见回馈 | 图片 |
|---|
| 3555 | 22 | 5677 | [喜欢,点击] | [hash1] |
| 12842 | 55 | 32144 | [不喜欢] | [hash2,hash3] |
| 13145 | 35 | 5677 | [点击,转发] | [hash2] |
测试数据集包含类似的结构,但是缺少反馈字段。 目的是预测反馈字段中是否存在“喜欢的”反应。
提交文件具有以下结构:
| userId | SortedList [objectId] |
|---|
| 123 | 78.13.54.22 |
| 128 | 35.61.55 |
| 131 | 35,68,129,11 |
指标-用户的平均ROC AUC。
可以在完善网站上找到有关数据的更详细说明。 您也可以在那里下载数据,包括测试和图片。
在线舞台
在在线阶段,任务分为3个部分
- 协作系统 -包括所有标志,但图像和文字除外;
- 图片 -仅包含有关图片的信息;
- 文本 -仅包含有关文本的信息。
离线阶段
在离线阶段,数据包含所有属性,而文本和图像则稀疏。 数据集中的行多于1.5倍,其中已经有很多行。
解决问题
由于我在从事简历工作,因此我以“图片”任务开始了自己的比赛。 提供的数据包括userId,objectId,ownerId(发布该帖子的组),创建和显示该帖子的时间戳,当然还有该帖子的图像。
在基于时间戳生成了多个特征之后,下一个想法是采用在imagenet上预先训练的神经元的倒数第二层,并将这些嵌入发送出去以增强效果。
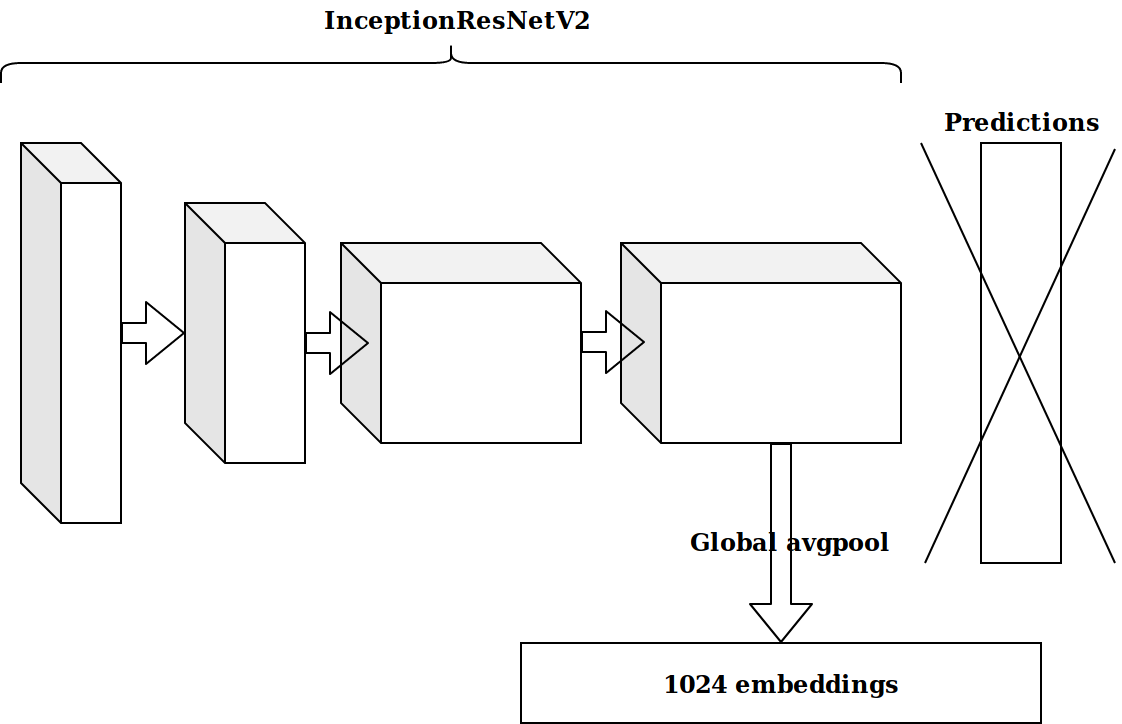
结果并不令人印象深刻。 我想,来自imagenet神经元的嵌入无关紧要,我需要提交自动编码器。
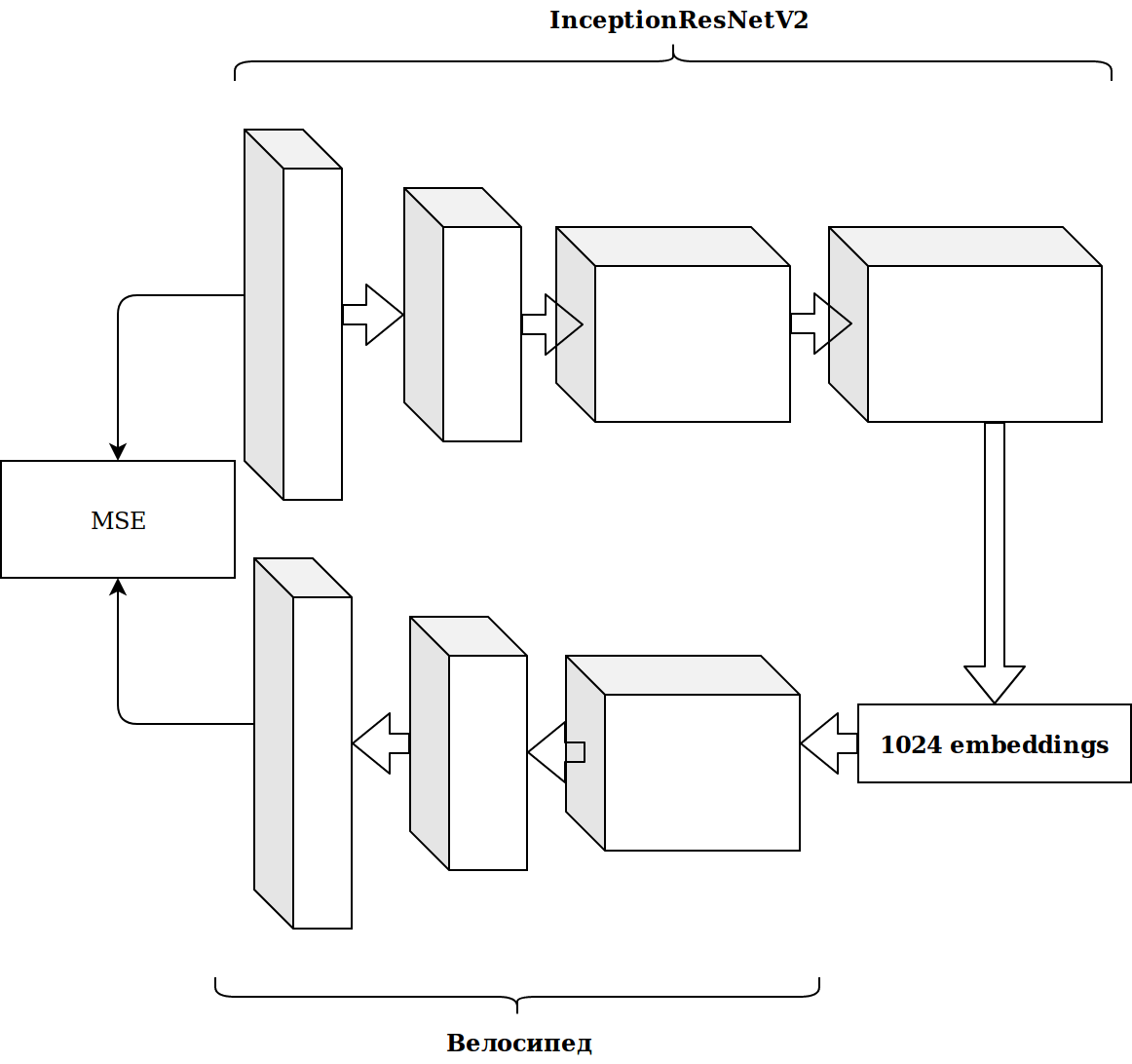
花了很多时间,结果没有改善。
特征生成
使用图像需要花费很多时间,因此我决定做一些简单的事情。
正如您马上看到的,数据集中有几个分类符号,为了不打扰我,我只加了升压。 该解决方案非常出色,没有任何设置,我立即进入了排行榜的第一行。
有很多数据,它们以镶木地板格式布置,因此,我三思而后行,开始使用scala并开始编写所有内容。
最简单的功能,比图像嵌入带来了更多的增长:
- 数据中的objectId,userId和ownerId满足多少次(应与受欢迎程度相关);
- ownerId看到多少个userId帖子(应该与用户对该组的兴趣相关);
- ownerId观看了多少不重复的userId(反映了该组受众的人数)。
从时间戳可以获取用户观看录像带的一天中的时间(早晨/白天/晚上/晚上)。 通过组合这些类别,您可以继续生成功能:
- 晚上userId登录了多少次;
- 该帖子通常显示什么时间(objectId),依此类推。
所有这些逐渐改善了指标。 但是训练数据集的大小约为2000万条记录,因此添加功能会大大减慢学习速度。
我重新定义了数据使用方法。 尽管数据是随时间变化的,但是以后我还没有看到任何明显的信息泄漏,但是,以防万一,我像这样破坏了它:
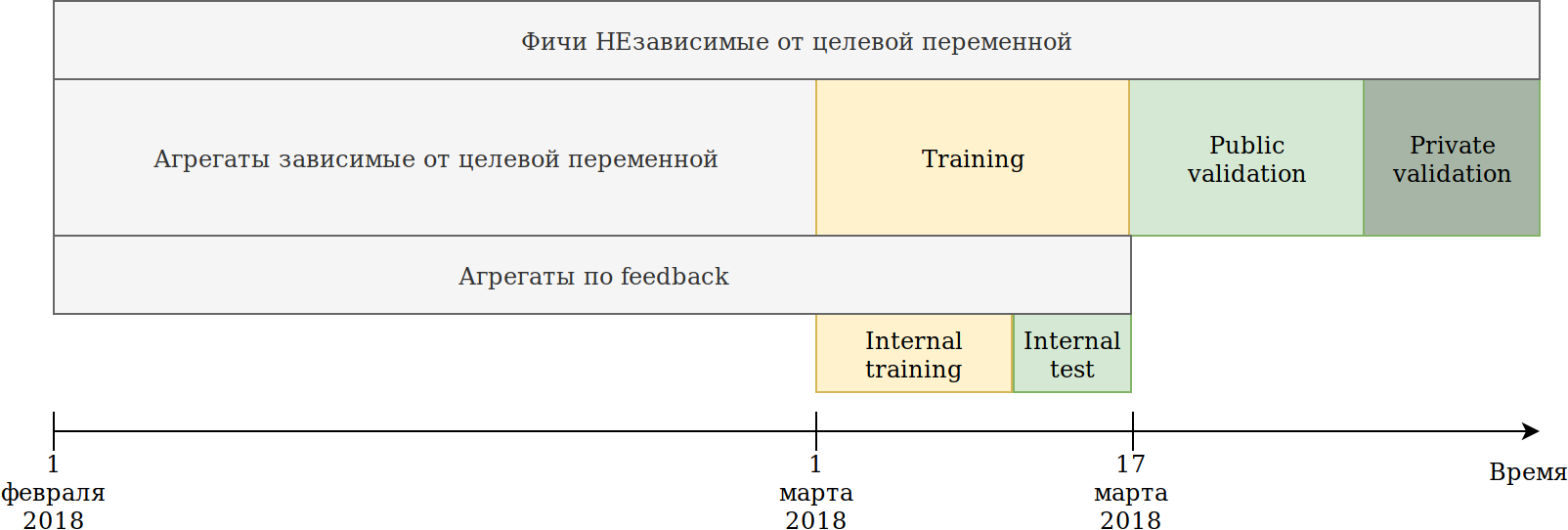
提供给我们的培训集(2月和3月2日)分为两部分。
根据最近N天的数据,他训练了模型。 上述汇总是基于包括测试在内的所有数据构建的。 同时,出现了可以建立目标变量的各种编码器的数据。 最简单的方法是重用已经创建新功能的代码,并简单地为其提供将不会训练且目标= 1的数据。
因此,我们得到了类似的功能:
- userId在ownerId组中看到过一次帖子的次数;
- userId喜欢发给ownerId的帖子有多少次;
- userId喜欢ownerId的帖子的百分比。
也就是说,根据分类特征的各种组合,结果证明了数据集部分的平均目标编码 。 原则上,catboost还会建立目标编码,从这个角度来看没有好处,但是,例如,可以计算出喜欢该组帖子的唯一用户的数量。 同时,主要目标得以实现-我的数据集减少了数倍,并且有可能继续生成要素。
虽然catboost只能根据喜欢的反应来构建编码器,但反馈还有其他反应:重新共享,不喜欢,有区别,被点击,被忽略,这可以手动完成。 我重述了各种聚合并筛选出低重要性的特征,以免膨胀数据集。
到那时,我已经遥遥领先。 唯一的尴尬是图像的嵌入几乎没有带来任何好处。 这个想法使一切都变得强大起来。 对Kmeans图像进行聚类,并获得新的分类特征imageCat。
这是手动过滤和合并从KMeans获得的群集之后的一些类。

基于imageCat我们生成:
- 新的分类功能:
- 什么imageCat最常显示为userId;
- 哪个imageCat最经常由ownerId显示;
- 哪个imageCat最喜欢userId;
- 各种柜台:
- 多少个唯一的imageCat看了userId;
- 如上所述,大约有15个相似的功能以及目标编码。
文字
图片比赛的结果适合我,因此我决定尝试自己的文章。 以前,我对文本的处理不多,并且由于愚蠢,我在tf-idf和svd上杀死了一天。 然后我看到了doc2vec的基线,它可以满足我的需求。 稍微调整了doc2vec的参数后,我收到了文本嵌入。
然后,他只是简单地为图像重用了代码,在其中他用文本嵌入替换了图像嵌入。 结果,我在文字竞赛中获得了第二名。
协同系统
我还没有“戳竹竿”的比赛,但是根据排行榜上的AUC判断,这项特殊比赛的结果很可能会影响离线阶段。
我采用了源数据中的所有符号,选择了分类符号,并计算了与图像相同的聚合,但图像本身的特征除外。 只是把它放到了推特上,我就获得了第二名。
优化Catboost的第一步
一等奖和二等奖让我感到高兴,但据了解,我没有做任何特别的事情,这意味着我们可以预期会失去位置。
竞赛的任务是在用户的框架内对帖子进行排名,而这一次我一直在解决分类问题,也就是说,我优化了错误的指标。
我将举一个简单的例子:
| userId | objectId | 预言 | 基本事实 |
|---|
| 1个 | 10 | 0.9 | 1个 |
| 1个 | 11 | 0.8 | 1个 |
| 1个 | 12 | 0.7 | 1个 |
| 1个 | 13 | 0.6 | 1个 |
| 1个 | 14 | 0.5 | 0 |
| 2 | 15 | 0.4 | 0 |
| 2 | 16 | 0.3 | 1个 |
我们做一个小的排列
| userId | objectId | 预言 | 基本事实 |
|---|
| 1个 | 10 | 0.9 | 1个 |
| 1个 | 11 | 0.8 | 1个 |
| 1个 | 12 | 0.7 | 1个 |
| 1个 | 13 | 0.6 | 0 |
| 2 | 16 | 0.5 | 1个 |
| 2 | 15 | 0.4 | 0 |
| 1个 | 14 | 0.3 | 1个 |
我们得到以下结果:
| 型号 | 澳柯 | User1 AUC | User2 AUC | 平均AUC |
|---|
| 选项1 | 0.8 | 1,0 | 0,0 | 0.5 |
| 选项2 | 0.7 | 0.75 | 1,0 | 0.875 |
如您所见,改善整体AUC指标并不意味着改善用户内部的平均AUC指标。
Catboost 可以开箱即用地优化排名指标 。 我阅读了有关使用Catboost时排名指标, 成功案例的信息 ,并设置了YetiRankPairwise进行夜间学习。 结果并不令人印象深刻。 决定自己学得不好后,我将错误函数更改为QueryRMSE,根据catboost的文档判断,该函数收敛速度更快。 结果,我得到了与分类训练期间相同的结果,但是这两个模型的合奏得到了很好的提高,这使我在所有三场比赛中均排名第一。
在协作系统竞赛在线阶段结束前5分钟,Sergey Shalnov将我带到了第二名。 我们一起走的另一条路。
为离线阶段做准备
在RTX 2080 TI视频卡上我们获得了在线阶段的胜利,但是总奖金为300,000卢布,甚至最终的第一名也迫使我们不得不花了2周的时间。
事实证明,谢尔盖还使用了助推器。 我们交换了想法和功能,我发现了Anna Veronika Dorogush的报告,其中回答了我的许多问题,甚至还回答了我尚未出现的问题。
查看报告使我想到有必要将所有参数恢复为默认值,并且必须非常仔细地并且仅在固定一组符号之后才能微调设置。 现在,一次训练花费了大约15个小时,但是一种模型设法获得了比集合排名更高的速度。
特征生成
在“协作系统”竞赛中,大量功能对于该模型很重要。 例如, auditweights_spark_svd是最重要的属性,并且没有关于其含义的信息。 我认为值得根据重要迹象来计算各种单位。 例如,每个用户,每个组,每个对象的平均auditweights_spark_svd。 可以根据未执行训练且目标= 1的数据(即,每个用户所喜欢的对象的平均auditweights_spark_svd)来计算出相同的值。 除了auditweights_spark_svd之外,还有几个重要标志。 以下是其中一些:
- 审计权重
- auditweightsCtrHigh
- userOwnerCounterCreateLikes
例如,事实证明,由userId组成的auditweightsCtrGender平均值以及由userId + ownerId组成的userOwnerCounterCreateLikes平均值都是一个重要功能。 这应该使我们考虑如何理解这些字段的含义。
其他重要功能包括auditweightsLikesCount和auditweightsShowsCount 。 一分为二,获得了更为重要的功能。
资料外泄
竞争和生产模型是非常不同的任务。 在准备数据时,很难考虑所有细节并且不传递有关测试目标变量的一些重要信息。 如果创建生产解决方案,则在训练模型时将尝试避免使用数据泄漏。 但是,如果我们想赢得比赛,那么数据泄漏就是最好的功能。
检查数据后,您可以看到根据objectId, auditweightsLikesCount和auditweightsShowsCount的值发生了变化,这意味着这些符号的最大值之比将比转换后的比率更好地反映后期转换。
我们发现的第一个泄漏是auditweightsLikesCountMax / auditweightsShowsCountMax 。
但是,如果您更仔细地查看数据怎么办? 按交货日期排序并获得:
| objectId | userId | auditweightsShowsCount | auditweightsLikesCount | 目标(喜欢) |
|---|
| 1个 | 1个 | 12 | 3 | 可能不是 |
| 1个 | 2 | 15 | 3 | 可能是 |
| 1个 | 3 | 16 | 4 | |
当我找到第一个这样的例子时,令人惊讶的是,事实证明我的预言没有实现。 但是,鉴于这些符号在对象框架内的最大值有所增加,我们并不太懒惰,因此决定查找auditweightsShowsCountNext和auditweightsLikesCountNext ,即下一个时刻的值。 新增功能
(auditweightsShowsCountNext-auditweightsShowsCount)/(auditweightsLikesCount-auditweightsLikesCountNext),我们全天候进行了大幅跃升。
如果在userId + ownerId中找到userOwnerCounterCreateLikes的以下值,例如,在objectId + userGender中找到auditweightsCtrGender,则可以使用类似的泄漏。 我们找到了6个相似的领域,其中有泄漏,并尽可能从中提取信息。
到那时,我们已经从协作属性中榨取了最多的信息,但没有回到图像和文字竞赛中。 有一个好主意要检查:在相应的比赛中,功能直接赋予图像或文字有多少?
在图像和文本竞赛中没有泄漏,但是到那时,我已经返回了catboost的默认参数,对代码进行了梳理并添加了一些功能。 总结果:
| 解决方案 | 速度 |
|---|
| 图片最大 | 0.6411 |
| 最多无图像 | 0.6297 |
| 第二名结果 | 0.6295 |
| 解决方案 | 速度 |
|---|
| 含文字的最大值 | 0.666 |
| 不含文字的最大值 | 0.660 |
| 第二名结果 | 0.656 |
| 解决方案 | 速度 |
|---|
| 协作最大 | 0.745 |
| 第二名结果 | 0.723 |
很明显,很多文本和图像不太可能被挤出,在尝试了几个最有趣的想法之后,我们停止了与它们的合作。
协作系统中功能的进一步生成并没有带来增长,因此我们开始进行排名。 在在线阶段,分类和排名的合集给了我一点点增长,结果是因为我的分类训练不足。 包括YetiRanlPairwise在内的所有错误函数都没有给出LogLoss给出的接近结果(0.745对0.725)。 希望无法启动QueryCrossEntropy。
离线阶段
在离线阶段,数据结构保持不变,但是有一些小的变化:
- 标识符userId,objectId,ownerId已重新随机化;
- 删除了一些标志,并重命名了一些标志;
- 数据已经增加了约1.5倍。
除了列出的困难外,还有一个很大的好处:将具有RTX 2080TI的大型服务器分配给团队。 我很喜欢htop了很长时间。
这个想法是一个-只是复制已经存在的东西。 花了几个小时在服务器上设置环境之后,我们逐渐开始验证结果是否正在复制。 我们面临的主要问题是数据量的增加。 我们决定稍微减少负载,并设置参数catboost ctr_complexity = 1。 这稍微降低了速度,但是我的模型开始起作用,结果很好-0.733。 与我不同,Sergei并未将数据分为两部分,也没有对所有数据进行训练,尽管这在联机阶段提供了最佳结果,但在脱机阶段存在很多困难。 如果我们采用已经生成的所有功能,并尝试将其放到“额头上”,那么在在线阶段就不会发生任何事情。 Sergey进行了类型优化,例如,将float64类型转换为float32。 在本文中,您可以找到有关优化熊猫记忆的信息。 结果,Sergey在CPU上训练了所有数据,结果约为0.735。
这些成绩足以赢得胜利,但是我们掩盖了真实的速度,无法确定其他球队是否也没有做到这一点。
战斗到最后
调整助推器
我们的解决方案被完全复制,我们添加了文本数据和图像的功能,因此剩下的只是调整catboost参数。 Sergey在CPU上进行了少量迭代研究,而在ctr_complexity = 1的情况下进行了研究。 仅剩一天,如果您仅添加迭代或增加ctr_complexity,那么在早晨,您甚至可以得到更快的速度,并整日走路。
在离线阶段,仅通过选择不是站点上最佳的解决方案就可以很容易地隐藏分数。 我们希望在提交结束之前的最后几分钟内,排行榜会发生重大变化,因此决定不停止。
从安娜的视频中,我了解到要提高模型的质量,最好选择以下参数:
- learning_rate-根据数据集的大小计算默认值。 随着learning_rate的降低,有必要增加迭代次数以保持质量。
- l2_leaf_reg-正则化系数,默认值为3,最好从2到30。值的减小导致过拟合的增加。
- bagging_temperature-将随机化添加到所选对象的权重中。 默认值为1,从指数分布中选择权重。 值的减小导致过拟合的增加。
- random_strength-影响特定迭代的分割选择。 random_strength越高,选择低重要性分割的机会就越高。 在每个后续迭代中,随机性降低。 值的减小导致过拟合的增加。
其他参数对最终结果的影响较小,因此我没有尝试选择它们。 在ctr_complexity = 1的情况下,对我的GPU数据集进行了一次培训迭代,耗时20分钟,并且在简化数据集上选择的参数与整个数据集上的最佳参数略有不同。 结果,我对10%的数据进行了约30次迭代,然后对所有数据又进行了约10次迭代。 结果大致如下:
- 我将默认的学习率提高了40%;
- l2_leaf_reg保持不变;
- bagging_temperature和random_strength降低至0.8。
我们可以得出结论,在使用默认参数的情况下,模型训练不足。
当我在排行榜上看到结果时,我感到非常惊讶:
| 型号 | 模型1 | 模型2 | 模型3 | 合奏 |
|---|
| 没有调音 | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| 随着调整 | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
我自己得出结论,如果您不需要快速应用模型,那么最好用未优化参数上的多个模型的集合代替参数选择。
Sergey致力于优化数据集的大小以在GPU上运行它。 — , :
- ( ), ;
- ;
- userId, ;
- userId, .
— .
, 0,742. ctr_complexity=2 30 5 . 4 , , 0,7433.
, , . predict(prediction_type='RawFormulaVal') scale_pos_weight=neg_count/pos_count.
.
. , , , 2 .
结论
:
- , target encoding, catboost.
- , , learning_rate iterations. — .
- GPU. Catboost GPU, .
- rsm~=0.2 (CPU only) ctr_complexity=1.
- , . . , , .
- , .
- , .

, .