在本文的
第一部分中 ,我们使用Ghidra自动分析了一个简单的破解程序(该程序是从cramess.one下载的)。 我们在反编译器清单中找出了如何重命名“难以理解”的函数,并且还了解了“顶层”程序的算法,即 这是由
main()完成的。
正如我所承诺的那样,在这一部分中,我们将分析
_construct_key()函数,我们发现该函数负责读取传输到程序的二进制文件并检查读取的数据。
第5步-_construct_key()函数概述
让我们立即查看此功能的完整清单:
清单_construct_key()char ** __cdecl _construct_key(FILE *param_1) { int iVar1; size_t sVar2; uint uVar3; uint local_3c; byte local_36; char local_35; int local_34; char *local_30 [4]; char *local_20; undefined4 local_19; undefined local_15; char **local_14; int local_10; local_14 = (char **)__prepare_key(); if (local_14 == (char **)0x0) { local_14 = (char **)0x0; } else { local_19 = 0; local_15 = 0; _text(&local_19,1,4,param_1); iVar1 = _text((char *)&local_19,*(char **)local_14[1],4); if (iVar1 == 0) { _text(local_14[1] + 4,2,1,param_1); _text(local_14[1] + 6,2,1,param_1); if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) { local_30[0] = *local_14; local_30[1] = *local_14 + 0x10c; local_30[2] = *local_14 + 0x218; local_30[3] = *local_14 + 0x324; local_20 = *local_14 + 0x430; local_10 = 0; while (local_10 < 5) { local_35 = 0; _text(&local_35,1,1,param_1); if (*local_30[local_10] != local_35) { _free_key(local_14); return (char **)0x0; } local_36 = 0; _text(&local_36,1,1,param_1); if (local_36 == 0) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x104) = (uint)local_36; _text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1); sVar2 = _text(local_30[local_10] + 1); if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) { _free_key(local_14); return (char **)0x0; } local_3c = 0; _text(&local_3c,1,1,param_1); local_3c = local_3c + 7; uVar3 = _text(param_1); if (local_3c < uVar3) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x108) = local_3c; _text(param_1,local_3c,0); local_10 = local_10 + 1; } local_34 = 0; _text(&local_34,4,1,param_1); if (*(int *)(*local_14 + 0x53c) == local_34) { _text("Markers seem to still exist"); } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } return local_14; }
使用此函数,我们将与以前使用
main()一样进行操作 -首先,我们将遍历“隐藏的”函数调用。 不出所料,所有这些功能均来自标准C库,我将不再描述重命名功能的过程-如有必要,请返回本文的第一部分。 重命名的结果是“发现”了以下标准功能:
- 恐惧()
- strncmp()
- 惊呆了()
- ftell()
- fseek()
- 放入()
我们通过添加索引2重命名了代码中的相应包装函数(反编译器无耻地隐藏在
_text后面的包装函数)(这样就不会与原始C函数混淆)。 这些功能几乎全部用于处理文件流。 毫不奇怪-快速浏览一下代码足以了解它从文件中顺序读取数据(文件的描述符作为唯一参数传递给函数)并将读取的数据与
local_14字节的某些二维数组进行
比较 。
假设此数组包含用于密钥验证的数据。 调用它,说出
key_array 。 由于Hydra不仅允许您重命名函数,而且还可以重命名变量,因此我们将使用此名称,并将难以理解的
local_14重命名为更易于理解的
key_array 。 此操作与功能相同:通过鼠标右键菜单(
Rename local )或键盘上的
L键。
因此,在声明局部变量之后,立即
调用某个函数
_prepare_key() :
key_array = (char **)__prepare_key(); if (key_array == (char **)0x0) { key_array = (char **)0x0; }
我们将返回
_prepare_key() ,这是调用层次结构中的第三层嵌套:
main()-> _construct_key()-> _prepare_key() 。 同时,我们接受它创建并以某种方式初始化此“测试”二维数组。 并且只有当该数组不为空时,该函数才能继续其工作,如上述条件之后立即由
else块所证明的那样。
接下来,程序从文件中读取前4个字节,并与
key_array数组的相应部分进行比较。 (下面的代码是重命名后的代码,包括
local_19变量
,我将其重命名为
first_4bytes 。)
first_4bytes = 0; fread2(&first_4bytes,1,4,param_1); iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4); if (iVar1 == 0) { ... }
因此,仅在前4个字节重合时(请记住),才会执行进一步的执行。 然后,我们从文件中读取2个2字节的块(并将相同的
key_array用作写入数据的缓冲区):
fread2(key_array[1] + 4,2,1,param_1); fread2(key_array[1] + 6,2,1,param_1);
再说一次-该功能仅在下一个条件为true时才起作用:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) {
很容易看出,上面读取的2字节块中的第一个应为数字5,第二个应为数字4(
short型数据类型在32位平台上仅占用2个字节)。
接下来是这个:
local_30[0] = *key_array;
在这里,我们看到
local_30数组(声明为char * local_30 [4])包含
key_array指针的偏移量。 也就是说,
local_30是标记行的数组,可能会将文件中的数据读取到其中。 在此假设下,我将
local_30重
命名为
markers 。 在这部分代码中,只有最后一行看起来有些可疑,其中最后一个偏移量的分配(索引为0x430,即1072)不是由下一个
markers元素执行,而是由单独的
local_20变量(
char * )执行。 但是我们会找出答案的,但是现在-让我们继续吧!
接下来,我们等待一个周期:
i = 0;
即 从0到4(含4)仅进行5次迭代。 在循环中,立即开始读取文件并检查是否符合我们的
markers数组:
char c_marker = 0;
即,将文件中的下一个字节读入
c_marker变量(在原始反编译代码中为
local_35 ),并检查是否与ith
markers元素的第一个字符
相符 。 如果不匹配,则将
key_array数组清零,并返回一个空的双指针。 沿着代码进一步,我们看到只要读取的数据与验证数据不匹配,就会完成此操作。
但是在这里,正如他们所说,“狗被埋了”。 让我们仔细看看这个周期。 我们发现,它有5次迭代。 您可以通过查看汇编代码来检查是否需要:


确实,CMP命令将
local_10变量的值(我们已经有了
i )与数字4进行比较,如果该值
小于或等于 4(JLE命令),则转换为标签
LAB_004017eb ,即 循环的开始。 即
i = 0、1、2、3和4时将满足条件-仅5次迭代! 一切都会好起来,但是
标记也会通过循环中的该变量索引,毕竟,此数组仅用4个元素声明:
char *markers [4];
因此,显然有人试图欺骗某人:)还记得吗,我说这句话值得怀疑吗?
local_20 = *key_array + 0x430;
就这样! 只需查看函数的整个清单,然后尝试找到至少一个对
local_20变量的引用。 她不在那里! 我们由此得出结论:该偏移量也应存储在
markers数组中,并且数组本身应包含5个元素。 让我们修复它。 转到变量声明,
按Ctrl + L (重新输入变量),然后将数组的大小更改为5:
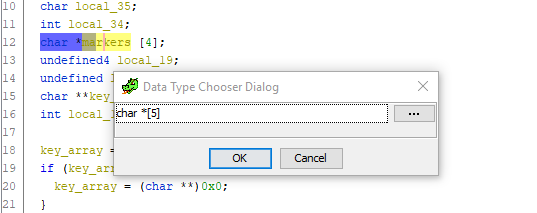
做完了 向下滚动到将指针偏移量分配给
标记的代码,然后-lo和瞧瞧! -难以理解的额外变量消失了,一切都准备就绪:
markers[0] = *key_array; markers[1] = *key_array + 0x10c; markers[2] = *key_array + 0x218; markers[3] = *key_array + 0x324; markers[4] = *key_array + 0x430;
我们返回
while循环 (在源代码中,这很可能是
针对的 ,但我们不在乎)。 接下来,再次读取文件中的字节并检查其值:
byte n_strlen1 = 0;
确定,此
n_strlen1必须为非零。 怎么了 您现在将看到,但是同时您将理解为什么我给此变量指定以下名称:
*(uint *)(markers[i] + 0x104) = (uint)n_strlen1; fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1); n_strlen2 = strlen2(markers[i] + 1);
我添加了一些注释,所有内容都应该清楚。 从文件中读取
N_strlen1个字节,并将其作为字符序列(即字符串)保存到
标记[i]数组中-即,在相应的“停止符号”之后,这些标记已从
key_array写入那里。 在
标记[i]中将值
n_strlen1保存在偏移量0x104(260)处在这里没有任何作用(请参见上面代码的第一行)。 实际上,可以按以下方式优化此代码(当然,在源代码中就是这种情况):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1); n_strlen2 = strlen2(markers[i] + 1); if (n_strlen2 != (size_t) n_strlen1) { ... }
它还检查读取行的长度是否为
n_strlen1 。 鉴于此参数已传递给
fread函数,这似乎是不必要的,但是
fread读取的字节数不超过指定的字节数,并且读取的字节数可以少于指示的字节数,例如在满足文件结束标记(EOF)的情况下。 也就是说,所有内容都是严格的:文件中指出了行的长度(以字节为单位),然后行本身就行了-恰好是5次。 但是我们正在超越自己。
进一步灌入此代码(我也立即评论了):
uint n_pos = 0;
这里仍然更简单:我们从文件中取出下一个字节,加7,然后将结果值与
ftell()函数获得的文件流中的当前光标位置进行比较。
n_pos的值必须不小于光标位置(即距文件开头的字节偏移量)。
循环的最后一行:
fseek2(param_1,n_pos,0);
即 通过
fseek()函数将文件光标(从头开始)重新排列到
n_pos指示的位置。 好的,我们在循环中执行所有这些操作5次。
_construct_key()函数
以以下代码
结尾 :
int i_lastmarker = 0;
因此,文件中的最后一个数据块应为4字节整数值,并且应等于
key_array [0] [1340]中的值 。 在这种情况下,我们将在控制台中收到祝贺消息。 否则,空数组仍会返回而没有任何赞赏:)
步骤6-__prepare_key()函数概述
我们只剩下一个未汇编的函数
__prepare_key() 。 我们已经猜到,验证数据是以
key_array数组的形式生成的,然后在
_construct_key()函数中使用它来验证文件中的数据。 仍然需要找出那里的数据!
我将不详细分析此函数,并在所有必要的变量重命名后立即给出带有注释的完整列表:
__Prepare_key()函数清单 void ** __prepare_key(void) { void **key_array; void *pvVar1; key_array = (void **)calloc2(1,8); if (key_array == (void **)0x0) { key_array = (void **)0x0; } else { pvVar1 = calloc2(1,0x540); *key_array = pvVar1; pvVar1 = calloc2(1,8); key_array[1] = pvVar1; *(undefined4 *)key_array[1] = 0x404024; *(undefined2 *)((int)key_array[1] + 4) = 5; *(undefined2 *)((int)key_array[1] + 6) = 4; *(undefined *)*key_array = 0x62; *(undefined4 *)((int)*key_array + 0x104) = 3; *(undefined *)((int)*key_array + 0x218) = 0x57; *(undefined *)((int)*key_array + 0x324) = 0x70; *(undefined *)((int)*key_array + 0x10c) = 0x6c; *(undefined *)((int)*key_array + 0x430) = 0x98; *(undefined4 *)((int)*key_array + 0x53c) = 0x462; } return key_array; }
唯一值得考虑的地方是此行:
*(undefined4 *)key_array[1] = 0x404024;
我如何理解这是“ VOID”行? 事实是0x404024是指向
.rdata节的程序地址空间中的地址。 双击该值,我们可以清楚地看到其中的内容:

顺便说一句,可以从此行的汇编代码中理解相同的内容:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
对应VOID行的数据在
.rdata节的最开始(相对于相应地址的零偏移)。
因此,在此函数的出口处,应使用以下数据形成一个二维数组:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
步骤7-为破解准备二进制文件
现在我们可以开始合成二进制文件了。 我们手中的所有初始数据:
1)验证数据(“停止符号”)及其在验证数组中的位置;
2)文件中的数据顺序
让我们根据
_construct_key()函数的算法恢复要查找的文件的结构。 因此,文件中的数据顺序如下:
档案结构- 4个字节== key_array [1] [0 ... 3] ==“ VOID”
- 2个字节== key_array [1] [4] == 5
- 2个字节== key_array [1] [6] == 4
- 1个字节== key_array [0] [0] =='b'(令牌)
- 1个字节==(下一行长度)== n_strlen1
- n_strlen1个字节==(任何字符串)== n_strlen1
- 1个字节==(+7 ==下一个令牌)== n_pos
- 1个字节== key_array [0] [0] =='l'(令牌)
- 1个字节==(下一行长度)== n_strlen1
- n_strlen1个字节==(任何字符串)== n_strlen1
- 1个字节==(+7 ==下一个令牌)== n_pos
- 1个字节== key_array [0] [0] =='W'(令牌)
- 1个字节==(下一行长度)== n_strlen1
- n_strlen1个字节==(任何字符串)== n_strlen1
- 1个字节==(+7 ==下一个令牌)== n_pos
- 1个字节== key_array [0] [0] =='p'(令牌)
- 1个字节==(下一行长度)== n_strlen1
- n_strlen1个字节==(任何字符串)== n_strlen1
- 1个字节==(+7 ==下一个令牌)== n_pos
- 1个字节== key_array [0] [0] == 152(令牌)
- 1个字节==(下一行长度)== n_strlen1
- n_strlen1个字节==(任何字符串)== n_strlen1
- 1个字节==(+7 ==下一个令牌)== n_pos
- 4个字节==(key_array [1340])== 1122
为了清楚起见,我在Excel中使用所需文件的数据制作了这样的平板电脑:

在第7行-字符本身和数字形式的数据本身,在第6行-十六进制表示形式,在第8行-每个元素的大小(以字节为单位),在第9行-相对于文件开头的偏移量。 此视图非常方便,因为 允许您在以后的文件中输入任何行(用黄色填充标记),而这些行的长度值以及下一个停止符号的位置偏移是根据程序算法要求通过公式自动计算的。 上方(第1-4行)
显示了
key_array检查数组的结构。
excel本身以及该文章的其他源材料都可以
在这里下载。
二进制文件生成和验证
剩下的唯一事情就是以二进制格式生成所需的文件,并将其提供给我们的破解程序。 为了生成文件,我编写了一个简单的Python脚本:
生成文件的脚本 import sys, os import struct import subprocess out_str = ['!', 'I', ' solved', ' this', ' crackme!'] def write_file(file_path): try: with open(file_path, 'wb') as outfile: outfile.write('VOID'.encode('ascii')) outfile.write(struct.pack('2h', 5, 4)) outfile.write('b'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[0]))) outfile.write(out_str[0].encode('ascii')) pos = 10 + len(out_str[0]) outfile.write(struct.pack('B', pos - 6)) outfile.write('l'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[1]))) outfile.write(out_str[1].encode('ascii')) pos += 3 + len(out_str[1]) outfile.write(struct.pack('B', pos - 6)) outfile.write('W'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[2]))) outfile.write(out_str[2].encode('ascii')) pos += 3 + len(out_str[2]) outfile.write(struct.pack('B', pos - 6)) outfile.write('p'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[3]))) outfile.write(out_str[3].encode('ascii')) pos += 3 + len(out_str[3]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('B', 152)) outfile.write(struct.pack('B', len(out_str[4]))) outfile.write(out_str[4].encode('ascii')) pos += 3 + len(out_str[4]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('i', 1122)) except Exception as err: print(err) raise def main(): if len(sys.argv) != 2: print('USAGE: {this_script.py} path_to_crackme[.exe]') return if not os.path.isfile(sys.argv[1]): print('File "{}" unavailable!'.format(sys.argv[1])) return file_path = os.path.splitext(sys.argv[1])[0] + '.dat' try: write_file(file_path) except: return try: outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT) print(outputstr.decode('utf-8')) except Exception as err: print(err) if __name__ == '__main__': main()
该脚本将破解的路径作为单个参数,然后使用相同目录中的密钥生成一个二进制文件,并使用相应的参数调用破解,将程序输出转换为控制台。
要将文本数据转换为二进制,请使用
struct包。
pack()方法允许您以指示数据类型的格式(“ B” =“字节”,“ i” = int等)来写入二进制数据,还可以指定序列(“>” =“ Big -endian“,” <“ =” Little-endian“)。 默认顺序是小端。 因为 我们已经在第一篇文章中确定这正是我们的情况,然后仅指出类型。
所有代码作为一个整体重现了我们发现的程序算法。 作为成功打印的行,我指定“我解决了这个问题!” (您可以修改此脚本,以便可以指定任何行)。
检查输出:

万岁,一切正常! 因此,我们花了点功夫并整理了几个功能,便能够完全恢复程序算法并对其进行“破解”。 当然,这只是一个简单的破解程序,一个测试程序,甚至是第二个难度级别(该站点提供的5个难度级别)。 实际上,我们将处理复杂的调用层次结构,其中包括数十种功能-数百种功能,在某些情况下-数据的加密部分,垃圾代码和其他混淆技术,直至内部虚拟机和P代码的使用……但是正如他们所说,这已经一个完全不同的故事。
文章的材料。