从上一篇文章开始,继续考虑加速应用于存储系统的I / O操作的技术,人们不禁会停留在诸如Auto Tiering这样的非常流行的选项上。 尽管此功能的思想与各种存储系统制造商的思想非常相似,但我们将以Qsan 存储系统为例,介绍实现撕裂的功能。
尽管存储在存储器中的数据多种多样,但这些相同的数据仍可以根据它们的相关性(使用频率)分为几组。 流行(“热”)数据对于组织最快的访问极为重要,而流行度较低(“冷”)数据的处理可以较低的优先级执行。
为了组织这样的方案,使用了撕裂功能。 在这种情况下,数据阵列不是由相同类型的磁盘组成,而是由形成不同层存储级别的几组驱动器组成。 使用特殊算法,可以在各个级别之间自动移动数据,以确保最大的最终性能。
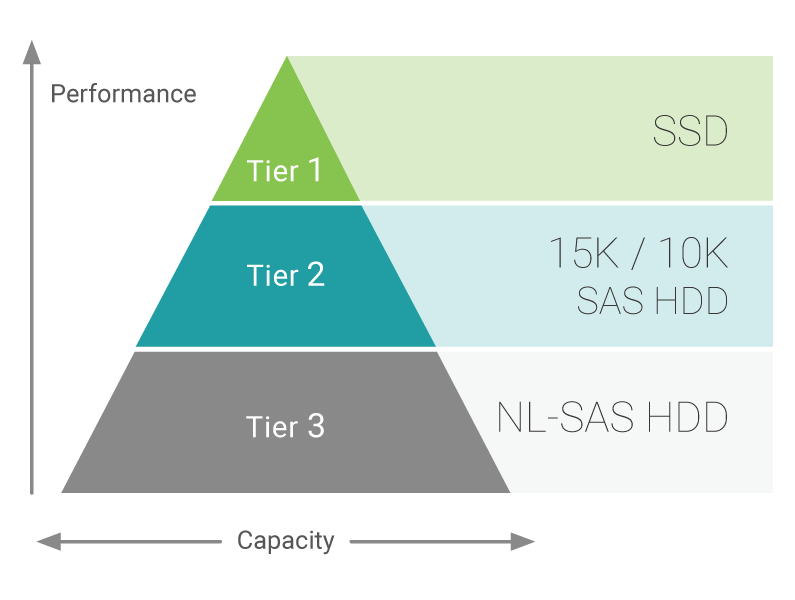
Qsan存储系统最多支持三个存储层:
- 第1层:SSD最高性能
- 第2层:HDD SAS 10K / 15K,高性能
- 第3层:HDD NL-SAS 7.2K,最大容量
自动分层池可以包含所有三个级别,并且只能包含两个级别的任意组合。 在每个层中,驱动器被组合成熟悉的RAID组。 为了获得最大的灵活性,每个层中的RAID级别可能不同。 也就是说,例如,没有什么可以阻止您组织4x SSD RAID10 + 6x HDD 10K RAID5 + 12 HDD 7.2K RAID6这样的结构
在自动分层池上创建卷(虚拟磁盘)后,将开始对所有I / O操作进行统计的后台收集。 为此,将空间“切”为1GB的块(所谓的子LUN)。 每次访问该块时,都会为其分配一个系数1。然后,随着时间的流逝,该系数会减小。 24小时后,在没有本机的输入/输出请求的情况下,该值将等于0.5,并在随后的每个小时内继续下降。
在某个时间点(默认是每天的午夜),将根据子LUN活动的系数对收集的结果进行排序。 基于此,确定要移动的块以及向哪个方向移动。 之后,实际上,各个级别之间存在数据重定位。
Qsan存储系统使用各种参数完美地实现了撕裂过程的控制,这使您可以非常灵活地配置阵列的最终性能。
为了确定数据的初始位置及其移动的优先方向,将使用为每个卷分别设置的策略:
- 自动分层 -默认策略,移动的初始位置和方向是自动确定的,即 “热”数据趋于最高级别,而“冷”数据则下降。 根据每个级别的可用空间选择初始放置。 但是您需要了解,该系统主要旨在最大程度地利用最快的驱动器。 因此,如果有可用空间,则数据将放置在较高级别。 此策略适用于无法提前预测数据需求的大多数情况。
- 从高处开始,然后进行自动分层 -与上一个不同之处仅在于原始数据位置(以最快的级别)
- 最高级别 -数据始终努力占据最快的级别。 如果在此过程中将它们向下移动,则将它们尽快移回。 此策略适用于需要最快访问速度的数据。
- 最低级别 -数据始终努力占据最低级别。 对于很少使用的数据(例如存档),此策略是完美的。
- 不移动 -系统自动确定数据的初始位置,并且不移动它们。 但是,如果随后需要重新分配统计信息,则会继续收集统计信息。
值得注意的是,尽管在创建每个卷时都定义了策略,但可以在系统的生命周期中动态地重复更改策略。
除了用于撕裂机制的策略外,还配置了级别之间数据移动的频率和速度。 您可以设置特定的移动时间:每天或每周的某些天,以及将统计信息收集的间隔减少到几个小时(最小频率为2个小时)。 如果需要限制数据移动操作的执行时间,则可以设置时间范围(移动窗口)。 此外,还显示了重定位速度-3种模式:快,中,慢。
如果需要立即进行数据重定位,则管理员可以随时以手动模式执行它。
显然,在级别之间移动数据的频率越高且速度越快,存储系统将更灵活地适应当前的操作条件。 但与此同时,值得记住的是,移动是一个额外的负载(主要是在磁盘上),因此绝对不需要“驱动”数据而无需极高的需求。 最好在最小负载的时刻计划运动。 如果存储工作始终需要24/7的高性能,则值得将重定位速度降至最低。
丰富的撕裂设置无疑会吸引高级用户。 但是,对于那些初次使用这种技术的人来说,没有什么可担心的。 很有可能相信默认设置(“自动分层”策略,每天晚上以最大速度移动一次),并且随着统计信息的累积,调整某些参数以达到所需的结果。
将对等技术与同样流行的技术(如SSD缓存)进行比较 ,应牢记其算法的不同原理。
| SSD缓存 | 自动分层 |
|---|
| 发病率 | 几乎立即。 但是只有在缓存“预热”(分钟-小时)后,效果才显着 | 收集统计信息(从2个小时开始,最好是一天),再加上移动数据的时间 |
| 效果持续时间 | 直到数据被新的部分代替(分钟-小时) | 尽管对数据的需求是相关的(一天或更长时间) |
| 使用指示 | 在短时间内立即提高生产力(数据库,虚拟化环境) | 长期提高生产率(文件,Web,邮件服务器) |
此外,撕裂的功能之一是不仅可以在“ SSD + HDD”之类的场景中使用它,而且还可以在“快速HDD +慢速HDD”或一般三个级别中使用它,这在原则上是不可能的,如果使用SSD缓存。
测试中
为了测试撕裂算法的操作,我们进行了一个简单的测试。 创建了两个级别的SSD(RAID 1)+ HDD 7.2K(RAID1)的池,在该池上放置了具有“最低级别”策略的卷。 即 数据应始终位于慢速磁盘上。
控制界面清楚地显示了各层之间的数据位置
在用数据填充卷之后,我们将放置策略更改为“自动分层”,并运行了IOmeter测试。
经过几个小时的测试,当系统能够累积统计信息时,重新定位过程开始了。
在数据移动结束时,我们的测试卷完全爬到了较高级别(SSD)。
判决
自动分层是一项了不起的技术,由于更频繁地使用高速驱动器,因此您可以用最少的材料和时间成本来提高存储系统的生产率。 就Qsan而言,唯一的投资是许可证,该许可证一劳永逸地获得,而不受磁盘数量/磁盘架/架子数量等的限制。 此功能具有丰富的设置,可以满足几乎所有业务任务。 界面中流程的可视化将使您有效地管理设备。