
2月28日,我在我们办公室的SphinxSearch-meetup上做了演讲。 他谈到了我们是如何从常规索引重建到全文搜索,如何将“就地”代码中的更新发送到轨道时间索引以及如何自动同步索引和MariaDB数据库状态的。 可通过链接获得报告的视频录像,对于那些喜欢阅读而不是观看视频的人,我写了这篇文章。
我将从搜索的安排方式以及为什么开始所有这一切开始。
我们的搜索是按照完全标准的方案进行的。
从前端,用户请求到达用PHP编写的应用程序服务器,然后他与数据库(我们有MariaDB)进行通信。 如果需要进行搜索,则应用程序服务器将转向平衡器(我们拥有haproxy),该平衡器将其连接到运行searchd的服务器之一,并且该服务器已经执行了搜索并返回结果。
来自数据库的数据以一种非常传统的方式进入索引:根据时间表,我们每隔几分钟就使用相对较新更新的文档来重建索引,并使用所谓的“存档”文档(即与之相对应的文档)来重建索引。很长时间没有任何反应。 分配了几台机器来建立索引,在该表上按计划运行脚本,该脚本首先生成索引,然后以特殊方式重命名索引文件,然后将其放在单独的文件夹中。 在每一个具有searchd的服务器上,rsync每分钟启动一次,该同步从该文件夹复制到searchd索引文件夹中,然后,如果已复制某些内容,它将执行RELOAD INDEX请求。
但是,对于简历和职位空缺的某些更改,要求它们尽快“达到”索引。 例如,如果从发布中删除了在公共领域中发布的空缺,则可以合理地预期从用户的角度来看,该空缺将在几秒钟内消失,不再出现。 因此,使用UPDATE查询通过searchd直接发送这些类型的更改。 为了将这些更改应用于所有服务器上的所有索引副本,在每个被搜索对象上都建立了分布式索引,该索引将属性更新发送到所有被搜索实例。 应用服务器仍连接到平衡器,并发送一个请求以更新分布式索引; 因此,他既不需要事先知道searchd服务器的列表,也不需要确切地了解到searchd服务器。
所有这些工作都很好,但是存在问题。
- 创建文档(我们有此简历或职位空缺)与将其输入索引之间的平均延迟与它们在数据库中的数量成正比。
- 由于我们使用分布式索引来分发属性更新,因此我们不能保证将这些更新应用于索引的所有副本。
- 在执行
RELOAD INDEX命令时,丢失了在重建索引期间发生的“紧急”更改(仅仅是因为它们尚未在新构建的索引中),并且仅在下一次重新索引之后才进入索引。 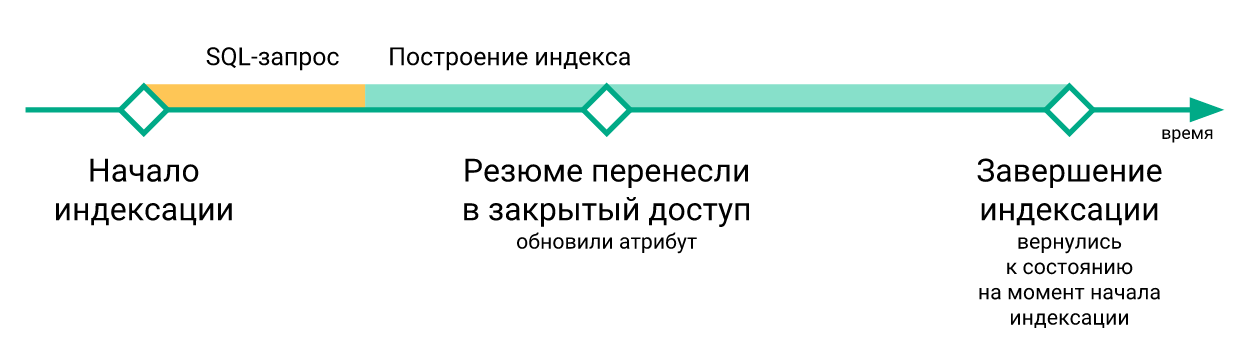
- 用于更新带有searchd的服务器上的索引的脚本是彼此独立执行的,它们之间没有同步。 因此,在不同服务器上更新索引之间的延迟可能达到几分钟。
- 如果需要测试与搜索相关的内容,则在每次更改后都需要重建索引。
这些问题中的每一个都不值得对搜索基础结构进行根本的重新设计,但是将它们放在一起会明显损害生活。
我们决定使用Sphinx实时索引来解决上述问题。 而且,过渡到RT指数对我们来说还不够。 为了最终摆脱任何数据争用,必须确保从应用程序到索引的所有更新都通过同一通道。 另外,有必要在重建索引时将对数据库所做的更改保存在某个地方(因为毕竟,有时有必要重建它,但是该过程不是瞬时的)。
我们决定使用MySQL复制协议(如数据传输通道)进行连接,而MySQL Binlog是在重建索引的同时保存更改的地方。 这种解决方案使我们摆脱了从应用程序代码编写Sphinx的麻烦。 而且由于那时我们已经使用了基于行的复制和全局事务ID,因此可以非常简单地在数据库副本之间进行切换。
直接连接到数据库以从中获取更改以发送到索引的想法当然并不新鲜:2016年,Avito的同事做了一个演讲 ,详细介绍了如何解决在Sphinx中与主数据库同步数据的问题。 我们决定利用他们的经验并为自己创建一个类似的系统,所不同的是我们不是PostgreSQL,而是MariaDB和旧的Sphinx分支(即版本2.3.2)。
我们提供了一项服务,该服务订阅了MariaDB中的更改并更新了Sphinx中的索引。 他的职责如下:
- 通过复制协议连接到MariaDB服务器,并从binlog接收事件;
- 跟踪当前binlog位置和最近完成的交易的数量;
- 过滤binlog事件;
- 找出需要在索引中添加,删除或更新哪些文档,以及对于更新的文档-哪些字段需要更新;
- 从MariaDB请求丢失数据;
- 索引更新请求的生成和执行;
- 必要时重建索引。
我们使用go-mysql库使用复制协议建立了连接。 她负责与MariaDB建立连接,读取复制事件并将其传递给处理程序。 该处理程序以goroutine开始,该程序由库控制,但是我们自己编写处理程序代码。 在处理程序代码中,将使用我们感兴趣的表列表来验证事件,并将对这些表所做的更改发送进行处理。 我们的处理程序还存储交易状态。 这是因为复制协议中的事件是按顺序排列的:GTID(事务开始)-> ROW(数据更改)-> XID(事务结束),并且只有第一个包含有关事务号的信息。 对于我们来说,将交易编号及其完成转移到一起更方便,以便保存有关更改已应用到二进制日志中哪个位置的信息,为此,我们需要记住当前交易在开始至完成之间的编号。
MySQL [(none)]> describe sync_state; +-----------------+--------+ | Field | Type | +-----------------+--------+ | id | bigint | | dummy_field | field | | binlog_position | uint | | binlog_name | string | | gtid | string | | flavor | string | +-----------------+--------+
我们将每台服务器上带有searchd的一个文档中的最后一个完成的交易编号保存在特殊索引中。 在服务启动时,我们验证索引已初始化并具有预期的结构,以及所有服务器上存在的已保存位置与所有服务器上的位置均相同。 然后,如果这些检查成功,并且我们能够从已保存的位置开始读取二进制日志,那么我们将开始同步过程。 如果检查失败,或者无法从已保存的位置开始读取二进制日志,则我们将已保存的位置重置为MariaDB服务器的当前位置,然后重建索引。
处理复制事件首先要确定哪些文档受数据库中的特定更改影响。 为此,在我们的服务配置中,我们做了一些类似的事情,例如路由我们感兴趣的表中的行更改事件,即,用于确定应如何索引数据库中的更改的一组规则。
[[ingest]] table = "vacancy" id_field = "id" index = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"] profession = ["profession"] latitude = ["latitude_deg", "latitude_rad"] longitude = ["longitude_deg", "longitude_rad"] [[ingest]] table = "vacancy_language" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] language_id = ["languages"] level = ["languages"] [[ingest]] table = "vacancy_metro_station" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] metro_station_id = ["metro"]
例如,使用这组规则,对vacancy , vacancy_language和vacancy_metro_station更改应在vacancy索引中。 可以在vacancy表的id字段中获取文档编号,而在另两个表中可以在vacancy_id字段中获取文档编号。 column_map字段是索引字段对不同数据库表的字段的依赖关系的表。
此外,当我们收到受更改影响的文档列表时,需要在索引中更新它们,但我们不会立即进行更新。 首先,我们累积每个文档的更改,并在距该文档的上一次更改很短时间(我们有100毫秒)后将更改发送到索引。
我们决定这样做是为了避免许多不必要的索引更新,因为在许多情况下,对文档的单个逻辑更改是在影响不同表的几个SQL查询的帮助下发生的,有时在完全不同的事务中执行。
我将举一个简单的例子。 假设用户已编辑空缺。 负责保存更改的代码通常是为简化起见而编写的:
BEGIN; UPDATE vacancy SET edited_at = NOW() WHERE id = 123; DELETE FROM vacancy_language WHERE vacancy_id = 123; INSERT INTO vacancy_language (vacancy_id, language_id, level) VALUES (123, 1, "fluent"), (123, 2, "technical"); DELETE FROM vacancy_metro_station WHERE vacancy_id = 123; INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id) VALUES (123, 55); ... COMMIT;
换句话说,首先从链接表中删除所有旧记录,然后插入新记录。 同时,即使文档中没有任何更改,binlog中仍将包含有关这些删除和插入的条目。
为了仅更新所需的内容,我们执行了以下操作:对更改的行进行排序,以便对于每个索引文档对,所有更改都可以按时间顺序检索。 然后,我们将能够依次应用它们,以确定哪些表最终更改了哪些字段,哪些没有更改,然后使用column_map表获取需要针对每个受影响的文档进行更新的字段和索引属性的列表。 此外,与一个文档相关的事件可能不会一个接一个地到达,而是如果它们在不同的事务中执行,就好像是“不同地”到达。 但是,就我们确定哪些文档已更改的能力而言,这不会影响。
同时,如果文本字段中没有更改,则此方法允许我们仅更新索引的属性,以及将更改发送到Sphinx。
因此,现在我们可以找出索引中需要更新的文档。
在许多情况下,binlog中的数据不足以建立更新索引的请求,因此我们从读取Binlog的同一台服务器中获取丢失的数据。 为此,在我们的服务配置中有一个用于接收数据的请求模板。
[data_source.vacancy] # # - id parts = 4 query = """ SELECT vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """
在此模板中,所有字段都标记有特殊别名: [___]:___ 。
它既用于形成接收丢失数据的请求,又用于构建索引(稍后将对此进行详细介绍)。
我们形成这种类型的请求:
SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id WHERE vacancy.id IN (< id , >) GROUP BY vacancy.id
然后,对于每个文档,我们检查它是否是此请求的结果。 如果不是,则意味着它已从主表中删除,因此也可以从索引中删除(我们对此文档执行DELETE查询)。 如果是,则查看是否需要更新此文档的文本字段。 如果文本字段不需要更新,则我们对此文档进行UPDATE查询,否则进行REPLACE 。
值得注意的是,在发生故障的情况下,保持可以从其开始读取二进制日志的位置的逻辑必须很复杂,因为现在有一种情况,我们不应用从二进制日志读取的所有更改。
为了使binlog的继续读取正常工作,我们执行了以下操作:对于数据库中的每个行更改事件,请记住该事件发生时最后完成的事务的ID。 将更改发送给Sphinx之后,我们将更新交易编号,您可以从中安全地开始读取交易编号,如下所示。 如果我们没有处理所有累积的更改(因为某些文档未在队列中“被跟踪”),那么我们将从与尚未设法应用的更改相关的事务中最早的事务处理中取出。 如果碰巧我们应用了所有累积的更改,那么我们只取最后完成的交易的编号。
结果对我们来说很好,但是还有一个更重要的一点:为了使实时索引的性能随着时间的流逝保持在可接受的水平,必须使该索引的“块”的大小和数量保持较小。 为此,Sphinx有一个FLUSH RAMCHUNK请求和一个OPTIMIZE INDEX请求,该请求创建一个新的磁盘块,该请求将所有磁盘块合并为一个。 最初,我们认为我们只会定期执行它,仅此而已。 但是,不幸的是,事实证明,在2.3.2版本中, OPTIMIZE INDEX不起作用(即,很有可能导致searchd下降)。 因此,我们决定每天仅一次完全重建索引,尤其是由于我们仍然需要不时地进行重建(例如,如果索引方案或令牌生成器设置发生更改)。
重建索引的过程分为几个阶段。
我们为索引器生成一个配置
如上所述,服务配置中有一个SQL查询模板。 它还用于形成索引器配置。
同样在配置中,还有其他一些必要的设置来建立索引(令牌设置,字典,各种资源消耗限制)。
保存MariaDB的当前位置
在所有带有searchd的服务器上都可以使用新索引之后,我们将从该位置开始读取binlog。
我们开始索引器
indexer --config tmp.vacancy.indexer.0.conf --all形式的命令,并等待其完成。 此外,如果将索引划分为多个部分,那么我们将并行开始构建所有部分。
我们在服务器上加载索引文件
下载到每个服务器也是并行进行的,但是我们自然要等到所有文件都上传到所有服务器。 要在服务配置中下载文件,有一部分带有用于下载文件的命令模板。
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]
对于每个服务器,我们只需将其名称替换为Host变量并执行结果命令。 我们使用rsync进行下载,但是原则上,任何程序或脚本都可以接受stdin中的文件列表,并将这些文件下载到搜索到的文件夹中,该文件夹希望搜索索引文件。
我们停止同步
我们停止阅读二进制日志,停止goroutine负责累积更改。
用新索引替换旧索引
对于每个具有searchd的服务器,我们进行顺序查询RELOAD INDEX vacancy_plain , TRUNCATE INDEX vacancy_plain , ATTACH INDEX vacancy_plain TO vacancy 。 如果索引分为多个部分,则我们将对每个部分依次执行这些查询。 同时,如果我们处于生产环境中,则在任何服务器上执行这些查询之前,我们会通过平衡器从服务器上消除负载(这样就不会有人对TRUNCATE和ATTACH之间的索引进行SELECT查询)。最后一个ATTACH请求完成后,我们将负载返回到此服务器。
从保存的位置恢复同步
一旦我们用新建索引替换了所有实时索引,便会从索引开始之前保存的位置开始,从二进制日志中恢复读取并同步二进制日志中的事件。
这是来自MariaDB服务器的索引滞后图的示例。

在这里您可以看到,尽管重建后索引的状态会及时返回,但这种情况非常短暂。
现在一切都已准备就绪,该发布了。 我们逐步做到了。 首先,我们在几个服务器上注入了一个实时索引,而当时的其余服务器以相同的方式工作。 同时,“新”服务器上的索引结构与旧服务器上的索引没有什么不同,因此我们的PHP应用程序仍可以连接到平衡器,而不必担心请求是在实时索引还是在普通索引上处理。
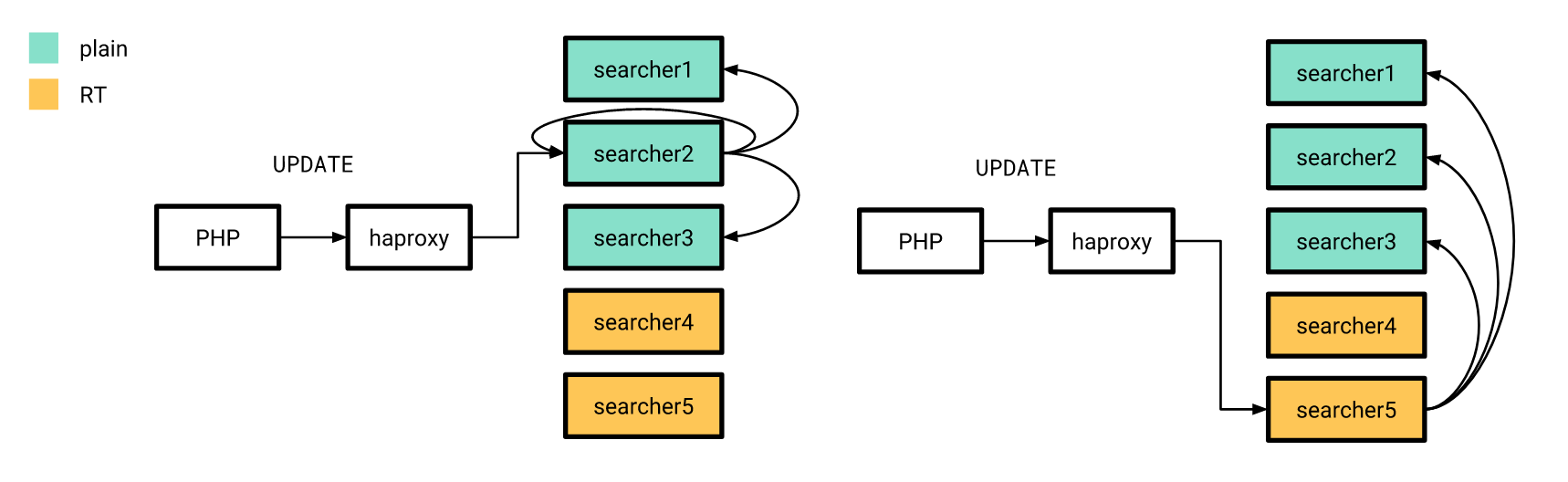
我也曾讨论过,属性更新也是按照旧方案发送的,区别在于所有服务器上的分布式索引都配置为仅向具有普通索引的服务器发送UPDATE查询。 此外,如果来自应用程序的UPDATE请求通过实时索引到达服务器,则它不会在家执行此请求,而是将其发送到以旧方式配置的服务器。
如我们所希望的那样,发布之后,事实证明,它显着减少了数据库中的恢复或空缺更改与相应的更改如何进入索引之间的延迟。
切换到实时索引之后,在测试服务器上进行每次更改后都无需重建索引。 因此,在搜索的参与下相对便宜地编写端到端自动测试成为可能。 但是,由于我们异步处理了二进制日志中的更改(从写入数据库的客户端的角度出发),我们不得不等待直到涉及参与自动测试的文档的更改由我们的服务处理并发送到searchd 。
为此,我们在服务中创建了一个端点,即执行此操作,即等待所有更改应用于指定的交易号。 为此,在对数据库进行必要的更改后,我们立即从MariaDB @@gtid_current_pos请求并将其传输到服务的端点。 如果此时我们已经将所有交易应用到该头寸,则服务会立即答复我们可以继续。 如果不是,则在负责应用更改的goroutine中,我们创建对此GTID的订阅,并且一旦应用了该GTID(或其后的任何一个),我们还允许客户端继续进行自动测试。
在PHP代码中,它看起来像这样:
<?php declare(strict_types=1); use GuzzleHttp\ClientInterface; use GuzzleHttp\RequestOptions; use PDO; class RiverClient { private const REQUEST_METHOD = 'post'; /** * @var ClientInterface */ private $httpClient; public function __construct(ClientInterface $httpClient) { $this->httpClient = $httpClient; } public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void { $masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn(); $this->httpClient->request( self::REQUEST_METHOD, "http://{$riverAddr}/wait", [RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]] ); } }
结果
结果,我们能够显着减少更新MariaDB和Sphinx之间的延迟。


我们也更加自信所有更新都会按时到达我们所有的Sphinx服务器。
此外,搜索测试(手动和自动)变得更加令人愉悦。
不幸的是,这并不是免费提供给我们的:实时索引的性能与普通索引相比表现稍差。
下面显示了搜索查询的处理时间的分布,该时间取决于纯索引的时间。

这是实时索引的相同图表。

您可以看到“快速”请求的份额略有减少,而“缓慢”请求的份额有所增加。
而不是结论
仍然可以说,我们在公共领域发布的本文中描述的服务代码。 不幸的是,目前没有详细的文档,但是如果您愿意,可以通过docker-compose运行使用此服务的示例。
参考文献
- 视频和报告幻灯片
- Andrey Smirnov和Vyacheslav Kryukov的有关Highload ++的视频报告
- Go-mysql库
- 服务代码及用法示例