我想告诉您一种使用分布式系统配置的有趣机制。 使用安全类型以编译语言(Scala)直接显示配置。 在本文中,将分析这种配置的示例,并考虑将已编译的配置引入整个开发过程的各个方面。
( 英文 )
引言
构建可靠的分布式系统意味着所有节点都使用与其他节点同步的正确配置。 通常,DevOps技术(terraform,ansible或类似的东西)用于自动生成配置文件(对于每个节点通常都是自己的)。 我们还要确保所有交互节点都使用相同的协议(包括相同的版本)。 否则,不兼容性将嵌入我们的分布式系统中。 在JVM世界中,此要求的一个后果是需要使用包含协议消息的库的相同版本。
分布式系统测试呢? 当然,我们假定在进行集成测试之前为所有组件都提供了单元测试。 (为了使测试结果推断到运行时,我们还必须在测试阶段和运行时提供一组相同的库。)
使用集成测试时,通常到处都容易在所有节点上使用单个类路径。 我们只需要确保运行时包含相同的类路径即可。 (尽管实际上有可能使用不同的类路径运行不同的节点,但这会导致整个配置复杂,并且难以进行部署和集成测试。)作为本文的一部分,我们假设所有节点上都将使用相同的类路径。
配置随应用程序而发展。 为了确定程序发展的各个阶段,我们使用版本。 识别配置的不同版本似乎很合逻辑。 并且配置本身应该放在版本控制系统中。 如果生产中只有一种配置,那么我们可以使用版本号。 如果使用了多个生产实例,那么我们需要几个
配置分支和版本以外的其他标签(例如,分支的名称)。 因此,我们可以唯一地标识确切的配置。 每个配置标识符唯一地对应于分布式节点,端口,外部资源,库版本的某种组合。 在本文的框架中,我们将从只有一个分支的事实出发,我们可以使用三个以点分隔的数字(1.2.3)以通常的方式识别配置。
在现代环境中,很少手动创建配置文件。 它们更多地是在部署期间生成的,并且不再受到影响(以免破坏任何东西 )。 出现一个逻辑问题,为什么我们仍然使用文本格式存储配置? 完全可行的替代方法是使用常规代码进行配置并在编译时从检查中受益的能力。
在本文中,我们只是探讨在已编译工件内部表示配置的想法。
编译配置
本节描述静态编译配置的示例。 实现了两个简单的服务-回显服务和客户端回显服务。 基于这两个服务,将组装两个版本的系统。 在一个实施例中,两个服务都位于同一节点上,在另一实施例中,这两个服务位于不同节点上。
通常,分布式系统包含几个节点。 可以使用某些NodeId类型的值来标识节点:
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
或
case class NodeId(hostName: String)
甚至
object Singleton type NodeId = Singleton.type
节点扮演各种角色,在它们上启动服务,并可以在它们之间建立TCP / HTTP通信。
为了描述TCP通信,我们至少需要一个端口号。 我们还想反映此端口支持的协议,以确保客户端和服务器使用相同的协议。 我们将使用此类描述连接:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
其中Port只是一个整数Int具有一个有效值范围:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
精制类型请参阅精炼库和我的 报告 。 简而言之,该库允许您将在编译时检查的约束添加到类型。 在这种情况下,有效的端口号值为16位整数。 对于已编译的配置,使用精炼库是可选的,但它可以提高编译器验证配置的能力。
对于HTTP(REST)协议,除了端口号,我们可能还需要服务的路径:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
幻影类型为了在编译阶段识别协议,我们使用在类内部未使用的类型参数。 该决定是由于以下事实:在运行时我们不使用协议实例,但是我们希望编译器检查协议兼容性。 由于该协议,我们将无法将不适当的服务作为依赖项进行传输。
一种常见的协议是带有Json序列化的REST API:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
其中RequestMessage是请求的类型, ResponseMessage是ResponseMessage的类型。
当然,您可以使用其他协议描述来提供我们所需的准确性。
出于本文的目的,我们将使用该协议的简化版本:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
这里,请求是添加到url中的字符串,响应是HTTP响应正文中返回的字符串。
服务配置由服务名称,端口和依赖项描述。 这些元素可以通过Scala的几种方式表示(例如, HList ,代数数据类型)。 出于本文的目的,我们将使用Cake Pattern并使用trait表示模块。 (“蛋糕模式”不是所描述方法的必要元素。它只是可能的实现之一。)
服务之间的依赖关系可以表示为返回其他节点的EndPoint端口的方法:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
要创建回显服务,仅端口号和此端口支持回显协议的指示就足够了。 我们无法指定特定的端口,因为 特质允许您声明没有实现的方法(抽象方法)。 在这种情况下,当创建特定配置时,编译器将要求我们提供抽象方法实现并提供端口号。 由于我们实现了该方法,因此在创建特定配置时,我们无法指定其他端口。 将使用默认值。
在客户端配置中,我们声明对echo服务的依赖:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
依赖项与echoService导出的服务具有相同的类型。 特别是,在回显客户端中,我们需要相同的协议。 因此,在连接这两个服务时,我们可以确保一切正常。
服务实施要启动和停止服务,需要一个功能。 (停止服务的能力对于测试至关重要。)同样,实现此功能有多种选择(例如,我们可以根据配置类型使用类型类)。 出于本文的目的,我们将使用蛋糕图案。 我们将使用cats.Resource类表示服务,因为 在此类中,已经提供了在出现问题时可以安全保证释放资源的方法。 为了获得资源,我们需要提供配置和就绪的运行时上下文。 启动服务的功能可能如下所示:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
在哪里
Config此服务的配置类型AddressResolver一个运行时对象,可让您查找其他节点的地址(请参见下文)
和其他来自cats库的类型:
F[_] -效果类型(在最简单的情况下, F[A]可以只是一个函数() => A在本文中,我们将使用cats.IO )Reader[A,B] -或多或少地与函数A => Bcats.Resource可以获取和释放的资源Timer -计时器(允许您入睡一段时间并测量时间间隔)ContextShift - ExecutionContext类似物Applicative -效果类型类,可让您组合各个效果(几乎是monad)。 在更复杂的应用程序中,使用Monad / ConcurrentEffect似乎更好。
使用此功能签名,我们可以实现多种服务。 例如,什么都不做的服务:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(请参阅其他服务的源代码 -echo service , echo client
和生命周期控制器 。)
节点是一个可以启动多个服务的对象(蛋糕模式可确保资源链的启动):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
请注意,我们指出了此节点所需的确切配置类型。 如果我们忘记指定单独服务所需的一种配置类型,则会出现编译错误。 同样,如果我们没有为某些适当类型的对象提供所有必要的数据,我们将无法启动该节点。
主机名解析要连接到远程主机,我们需要一个真实的IP地址。 地址可能比配置的其余部分晚知道。 因此,我们需要一个将节点标识符映射到地址的函数:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
您可以提供几种方法来实现此功能:
- 如果在部署之前我们已经知道地址,则可以使用以下命令生成Scala代码:
地址,然后启动程序集。 这将编译并运行测试。
在这种情况下,该函数将是静态已知的,并且可以在代码中表示为地图显示Map[NodeId, NodeAddress] 。 - 在某些情况下,仅在节点启动后,才知道有效地址。
在这种情况下,我们可以实现“发现服务”(发现),该服务在其他节点之前运行,并且所有节点都将在此服务中注册并请求其他节点的地址。 - 如果我们可以修改
/etc/hosts ,那么我们可以使用预定义的主机名(例如my-project-main-node和echo-backend )并仅绑定这些名称
在部署期间使用IP地址。
在本文的框架中,我们将不更详细地考虑这些情况。 为了我们
在一个玩具示例中,所有节点将具有一个IP地址127.0.0.1 。
接下来,我们考虑分布式系统的两个选项:
- 将所有服务放在一个节点上。
- 并将回显服务和回显客户端放置在不同的节点上。
单个节点的配置:
单节点配置 object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
该对象实现客户端和服务器的配置。 还使用生命周期的配置,以便在lifetime结束后结束程序。 (Ctrl-C也可以正常工作并正确释放所有资源。)
可以使用相同的一组配置特征和实现来创建一个由两个单独的节点组成的系统:
两个节点的配置 object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
重要! 请注意如何执行服务绑定。 我们将一个节点实现的服务表示为另一节点的依赖方法的实现。 依赖项的类型由编译器检查,因为 包含协议的类型。 启动后,依赖项将包含目标节点的正确标识符。 由于采用了这种方案,我们只需一次指定端口号即可,始终保证可以引用正确的端口。
实现两个系统节点对于此配置,我们使用相同的服务实现而不进行更改。 唯一的区别是,现在我们有两个实现不同服务集的对象:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
第一个节点实现服务器,仅需要服务器配置。 第二个节点由客户端实现,并使用配置的另一部分。 两个节点还需要管理生存时间。 服务器节点无限期运行,直到它被SIGTERM停止,并且客户端节点在一段时间后终止。 请参阅启动应用程序 。
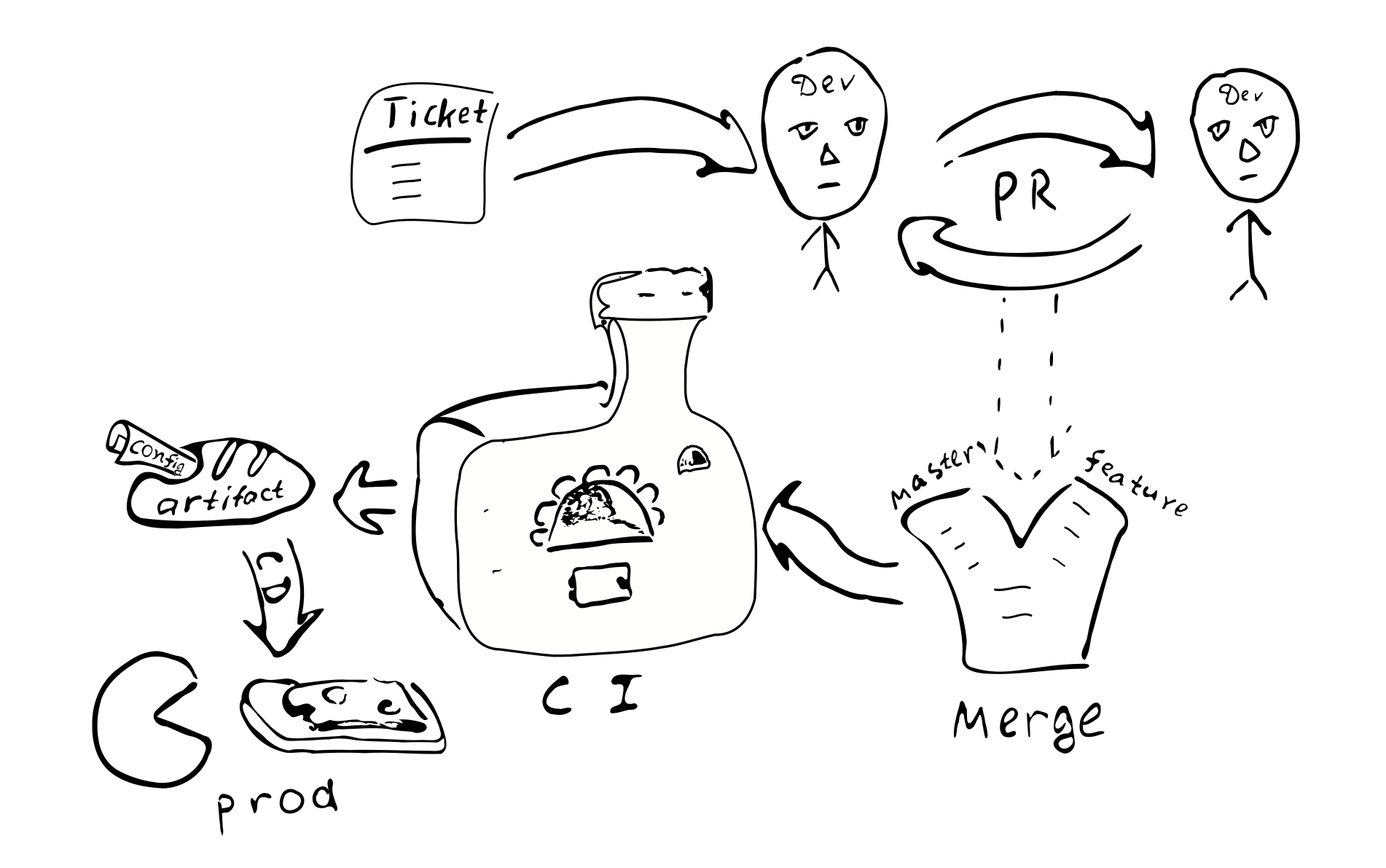
总体开发过程
让我们看看这种配置方法如何影响整个开发过程。
该配置将与其余代码一起编译,并将生成工件(.jar)。 显然,将配置放在单独的工件中很有意义。 这是由于这样的事实,我们可以基于同一代码进行许多配置。 同样,您可以生成对应于不同配置分支的工件。 每当我们决定部署此版本的配置时,连同配置一起,将保留对特定版本库的依赖关系,并将永久保留这些版本。
任何配置更改都将变成代码更改。 因此,每个这样的
更改将包含在常规质量保证流程中:
Bugtracker中的票证-> PR->评论->与相应的分支合并->
集成->部署
实施编译配置的主要结果:
该配置将在分布式系统的所有节点上进行协调。 由于所有节点都从单一来源接收相同的配置。
仅在一个节点中更改配置是有问题的。 因此,“配置漂移”是不可能的。
进行小的配置更改变得更加困难。
大多数配置更改将在整个开发过程中发生,并将进行审查。
我需要一个单独的存储库来存储生产配置吗? 这样的配置可能包含密码和其他机密信息,我们希望限制其访问。 基于此,将最终配置存储在单独的存储库中似乎很有意义。 您可以将配置分为两部分-一部分包含公共配置设置,另一部分包含受限访问设置。 这将使大多数开发人员可以访问公用参数。 使用包含默认值的中间特征可以轻松实现这种分离。
可能的变化
让我们尝试将编译后的配置与一些常见替代方案进行比较:
- 目标计算机上的文本文件。
- 键值集中存储(
etcd / zookeeper )。 - 可以重新配置/重新启动而无需重新启动过程的过程组件。
- 在工件和版本控制之外存储配置。
文本文件在小的更改方面提供了极大的灵活性。 系统管理员可以转到远程节点,对相应的文件进行更改,然后重新启动服务。 但是,对于大型系统,这种灵活性可能是不希望的。 根据所做的更改,其他系统中没有任何痕迹。 没有人评论更改。 很难确定谁进行了更改以及出于何种原因进行了更改。 更改未经测试。 如果系统是分布式的,则管理员可能会忘记在其他节点上进行相应的更改。
(还应注意,使用已编译的配置不会阻止将来使用文本文件的可能性。添加一个解析器和验证器以提供相同类型的Config作为输出就足够了,您可以使用文本文件。随之而来的是,具有已编译配置的系统的复杂性有所提高少于使用文本文件的系统的复杂性,因为文本文件需要其他代码。)
集中式键值存储是一种用于分发分布式应用程序的元参数的好机制。 我们应该确定什么是配置参数,什么是数据。 假设我们有一个函数C => A => B ,其中参数C很少更改,而数据A经常更改。 在这种情况下,我们可以说C是配置参数,而A是数据。 似乎配置参数与数据的不同之处在于,配置参数的更改频率通常小于数据更改的频率。 同样,数据通常来自一个来源(来自用户),而配置参数来自另一个来源(来自系统管理员)。
如果很少更改的参数需要在不重新启动程序的情况下进行更新,则这通常会导致程序复杂化,因为我们将需要以某种方式传递参数,存储,解析和检查,处理不正确的值。 因此,从降低程序复杂性的角度来看,减少在程序期间可以更改的参数数量(或者根本不支持此类参数)是有意义的。
从这篇文章的角度来看,我们将区分静态参数和动态参数。 如果服务逻辑需要在程序中更改参数,则我们将这些参数称为动态参数。 否则,参数是静态的,可以使用编译配置进行配置。 对于动态重新配置,我们可能需要一种机制来使用新参数重新启动程序的各个部分,类似于重新启动操作系统的过程。 (我们认为,随着系统复杂性的增加,建议避免实时重新配置。如果可能的话,最好使用标准OS功能来重新启动进程。)
使用静态配置迫使人们考虑动态重新配置的一个重要方面是配置更新(停机)后系统重新启动所花费的时间。 实际上,如果需要更改静态配置,则必须重新启动系统以使新值生效。 停机时间问题对于不同的系统具有不同的严重性。 在某些情况下,您可以在负载最小时安排重新启动时间。 如果要提供连续服务,则可以实施“排水连接”(AWS ELB连接排水) 。 同时,当我们需要重新引导系统时,我们启动该系统的并行实例,将平衡器切换到该实例,然后等待直到旧的连接完成为止。 所有旧连接完成后,我们关闭旧系统实例。
现在让我们考虑将配置存储在工件内部或外部的问题。 如果我们将配置存储在工件中,那么至少在组装工件时我们有机会确保配置正确。 如果配置不在受控工件的范围内,则很难跟踪谁和为什么对此文件进行了更改。 这有多重要? 我们认为,对于许多生产系统而言,拥有稳定且高质量的配置非常重要。
工件的版本使您可以确定它的创建时间,包含的值,启用/禁用的功能以及负责配置更改的人员。 当然,将配置存储在工件中需要付出一些努力,因此您需要做出明智的决定。
利弊
我想详细介绍所提议技术的优缺点。
好处
以下是已编译的分布式系统配置的主要功能的列表:
- 静态配置检查。 让您确定
配置正确。 - . . Scala , . ,
trait' , , val', (DRY) . ( Seq , Map , ). - DSL. Scala , DSL. , , , . , , .
- . , , , , . , . , .
- . , , .
- . , .
- . , . . ( , , , , -.) — . , , , , .
- . , . , , . . . , production'.
- . , . , , — . production- .
- 测试。 mock-, , .
- . . , , , .
. :
- . production', . . . .
- . , , .
- . , , . / .
- . DevOps . .
- . (CI/CD). .
, :
- , , . , Cake Pattern' , ,
HList (case class') . - , : (
package , import , ; override def ' , ). , DSL. , (, XML), . - .
结论
Scala. xml- . , Scala, ( Kotlin, C#, Swift, ...). , , , , , .
, . .
:
- .
- DSL .
- . , , (1) ; (2) .
, .