没有一个ORM
大家好! 我负责Ostrovok.ru酒店预订服务的合作伙伴发展部。 在本文中,我想谈谈我们如何在一个项目上使用Django ORM 。
实际上,我在欺骗,这个名字应该是“ 不可以 ORM single“。如果您想知道为什么我写这个,以及:
- 您在堆栈上有Django,并且想要从ORM中挤出最大的
Model.objects.all() ,而不仅仅是Model.objects.all() , - 您想将部分业务逻辑转移到数据库级别,
- 还是您想找出为什么B2B.Ostrovok.ru的开发人员最经常的借口是“从历史上讲” ,
...欢迎猫。

2014年,我们推出了B2B.Ostrovok.ru-在线预订服务,为旅游市场的专业人员(旅行代理商,运营商和公司客户)提供酒店,中转,汽车和其他旅行服务。
在B2B中,我们已经设计并成功使用了基于MetaOrder -meta order- MetaOrder的抽象订单模型。
元订单是一个抽象实体,无论它属于哪种类型的订单,都可以使用它:酒店( Hotel ),附加服务( Upsell )或汽车( Car )。 将来可能会出现其他类型。
并非总是如此。 当B2B服务启动时,只能通过它预订酒店,所有业务逻辑都将重点放在这些酒店上。 例如,创建了许多字段来显示销售金额和预订退款金额的汇率。 随着时间的推移,我们意识到在给定元顺序的情况下如何最好地存储和重用此数据。 但是整个代码无法重写,并且部分遗产继承到了新架构中。 实际上,这导致了使用几种类型的订单进行计算的困难。 怎么做-从历史上看 ...
我的目标是在我们的示例中展示Django ORM的功能。
背景知识
为了计划费用,我们的B2B客户确实缺乏有关现在/明天/以后需要支付多少,订单上是否有债务以及债务规模以及在限制范围内可以支出的数量等方面的信息。 我们决定以仪表板的形式显示此信息-这样的简单插座,带有清晰的图表。

(所有值均为测试值,不适用于特定合作伙伴)
乍一看,一切都很简单-我们过滤了合作伙伴的所有订单,进行了汇总并显示。
解决方案选项
关于我们如何进行计算的一些解释。 我们是一家国际公司,来自不同国家/地区的合作伙伴以不同的货币进行经营-购买和转售预订。 此外,他们必须以所选货币(通常是本地货币)接收财务报表。 存储所有货币汇率的所有可能数据是愚蠢且不切实际的,因此您需要选择一种参考货币,例如卢布。 因此,您只能将所有货币的汇率存储到卢布。 因此,当合作伙伴想要接收摘要时,我们将按照销售时设定的汇率转换金额。
“在额头上”
实际上,这是Model.objects.all()并且条件循环:
带条件的Model.objects.all() def output(partner_id): today = dt.date.today()
该查询将返回一个可能包含数百个预订的生成器。 将针对这些预订中的每个预订向数据库发出请求,因此该周期将持续很长时间。
您可以通过添加prefetch_related方法来加快速度:
然后,对数据库的请求将略微减少( GenericForeignKey ),但是最后,我们将停止它们的数目,因为对数据库的请求仍将在循环的每次迭代中进行。
可以(并且应该)缓存output方法,但是第一个调用仍然满足一分钟的顺序,这是完全不可接受的。
这是此方法的结果:
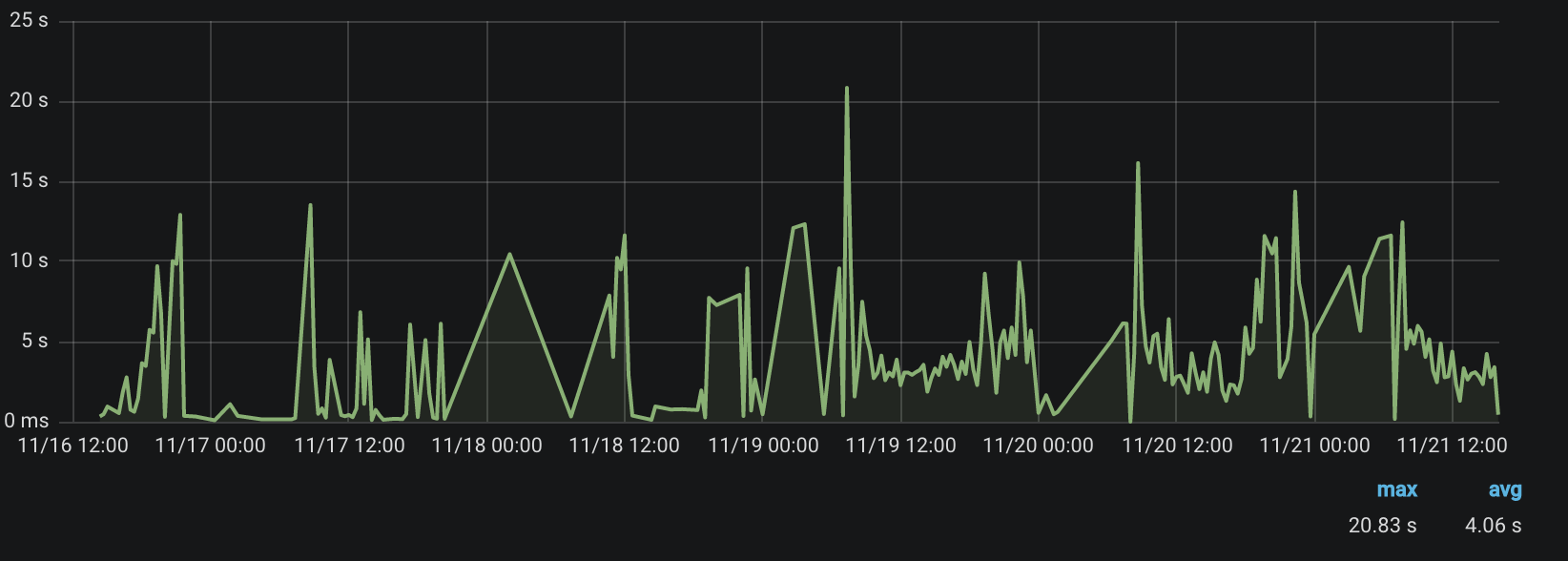
平均响应时间为4秒,峰值达到21秒。 相当长的时间。
我们没有为所有合作伙伴推出仪表板,因此我们对此没有太多要求,但足以理解这种方法是否有效。
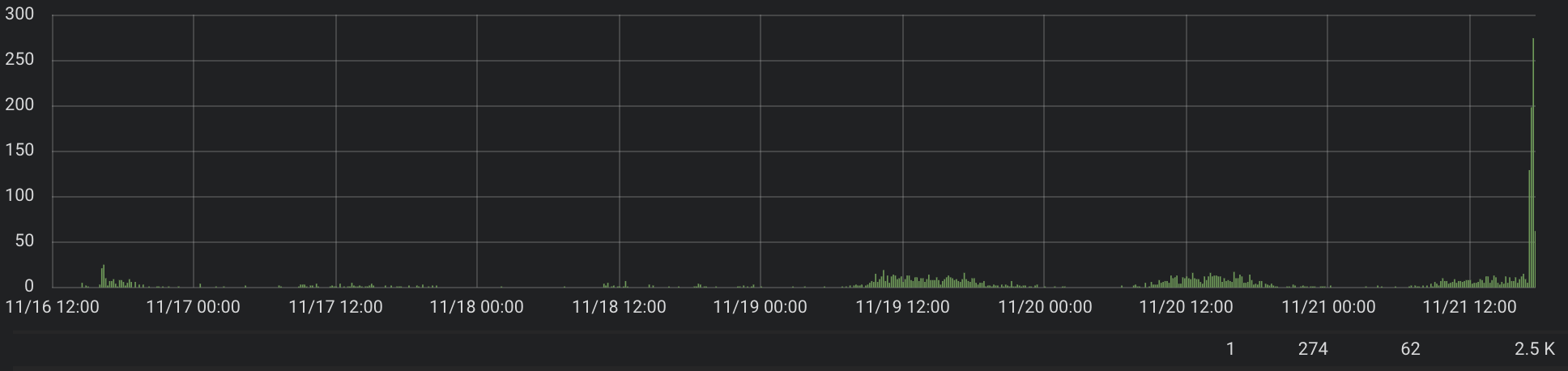
右下角的数字是查询数:最小值,最大值,平均值,总数。
明智地
前额原型可以很好地理解任务的复杂性,但使用起来并非最佳。 我们认为,向数据库中进行几个复杂的查询比许多简单的查询要快得多,所需资源也更少。
申请方案
查询计划的广泛笔触可以这样描述:
- 根据初始条件收集订单,
- 通过
annotate准备要计算的字段, - 计算字段值
- 按数量和数量
aggregate
初始条件
访问该网站的合作伙伴只能在其合同上看到信息。
partner = query_get_one(Partner.objects.filter(id=partner_id))
如果我们不想显示新的订单/预订类型,我们只需要过滤支持的订单/预订:
query = MetaOrder.objects.filter( partner=partner, content_type__in=[ Hotel.get_content_type(), Car.get_content_type(), Upsell.get_content_type(), ] )
订单状态很重要(有关Q更多信息):
query = query.filter( Q(hotel__status__in=['completed', 'cancelled'])
例如,我们还经常使用预先准备好的请求,以排除所有无法付款的订单。 有很多业务逻辑,在本文的框架中对我们来说不是很有趣,但是从本质上讲,这些只是附加的过滤器。 返回准备好的查询的方法可能如下所示:
query = MetaOrder.exclude_non_payable_metaorders(query)
如您所见,这是一个类方法,该方法还将返回QuerySet 。
我们还将准备一些变量,用于条件构造和存储计算结果:
import datetime as dt from typing.decimal import Decimal today = dt.date.today() result = defaultdict(Decimal)
由于必须根据订单类型来引用字段,因此我们将使用Coalesce 。 因此,我们可以将任意数量的新型订单抽象到一个字段中。
这是annotate块的第一部分:
Coalesce在这里大放异彩,因为酒店订单具有几个特殊属性,在所有其他情况下(其他服务和汽车),这些属性对我们而言并不重要。 这就是Value(ZERO)和汇率Value(ONE)的显示方式。 ZERO和ONE均为常数形式的Decimal('0')和Decimal(1) 。 这是一种业余方法,但是在我们的项目中,这种方法是可以接受的。
您可能会有一个问题,为什么不将某些字段按元顺序放在一个级别上? 例如, payment_pending ,到处都是。 的确,随着时间的流逝,我们将此类字段转换为元顺序,但是现在代码运行良好,因此此类任务不再是我们的优先事项。
另一个准备和计算
现在,我们需要使用上一个annotate块中收到的金额进行一些计算。 请注意,这里您不再需要受定单类型的约束(一个例外除外)。
该区块最有趣的部分是_reporting_currency_rate字段,即出售时相对于参考货币的汇率。 有关酒店订单的所有货币对参考货币的汇率数据存储在currency_data 。 这只是JSON。 我们为什么要保留这个? 历史上就是这种情况 。
在这里看来,为什么不使用F替代合同货币的价值呢? 也就是说,如果您可以这样做,那将很酷:
F(f'currency_data__{partner.reporting_currency}')
但是f-strings不支持f-strings F 尽管Django ORM已经可以访问嵌套的json字段,这一事实非常令人愉快F('currency_data__USD') 。
最后一个annotate块是_payable_in_cur计算,它将对所有订单进行汇总。 此值必须以合同货币表示。
.annotate( _payable_in_cur=( F('_payable_base') / F('_reporting_currency_rate') ) )
annotate方法的独特之处在于,它生成了很多不与请求直接相关的SELECT something AS something_else构造的SELECT something AS something_else 。 可以通过卸载SQL query.__str__()来看到。
这是 Django ORM为base_query_annotated生成的 SQL代码的base_query_annotated 。 您必须经常阅读它,以了解可以在哪里优化查询。
最终计算
将有一个小包装来封装aggregate ,以便将来如果合作伙伴需要其他指标,可以轻松添加。

def _get_data_from_query(query: QuerySet) -> Decimal: result = query.aggregate( _sum_payable=Sum(F('_payable_in_cur')), ) return result['_sum_payable'] or ZERO
还有一件事-这是根据业务状况进行的最后过滤,例如,我们需要所有需要尽快支付的订单。

before_payment_pending_query = _get_data_from_query( base_query_annotated.filter(_payment_pending__gt=today) )
调试与验证
验证所创建请求的正确性的一种非常方便的方法是将其与更易读的计算版本进行比较。
for morder in query: payable = morder.get_payable_in_cur() payment_pending = morder.get_payment_pending() if payment_pending > today: result['payment_pending'] += payable
您知道“额头”方法吗?
最终代码
结果,我们得到如下内容:
最终代码 def _get_data_from_query(query: QuerySet) -> tuple: result = query.aggregate( _sum_payable=Sum(F('_payable_in_cur')), ) return result['_sum_payable'] or ZERO def output(partner_id: int): today = dt.date.today() partner = query_get_one(Partner.objects.filter(id=partner_id)) query = MetaOrder.objects.filter(partner=partner, content_type__in=[ Hotel.get_content_type(), Car.get_content_type(), Upsell.get_content_type(), ]) result = defaultdict(Decimal) query_annoted = query.annotate( _payment_pending=Coalesce( 'hotel__payment_pending', 'car__payment_pending', 'upsell__payment_pending', ), _payment_due=Coalesce( 'hotel__payment_due', 'car__payment_due', 'upsell__payment_due', ), _refund=Coalesce( 'hotel__refund', Value(ZERO) ), _refund_currency_rate=Coalesce( 'hotel__refund_currency_rate', Value(Decimal('1')) ), _sell=Coalesce( 'hotel__sell', Value(ZERO) ), _sell_currency_rate=Coalesce( 'hotel__sell_currency_rate', Value(Decimal('1')) ), ).annotate(
现在是这样的:
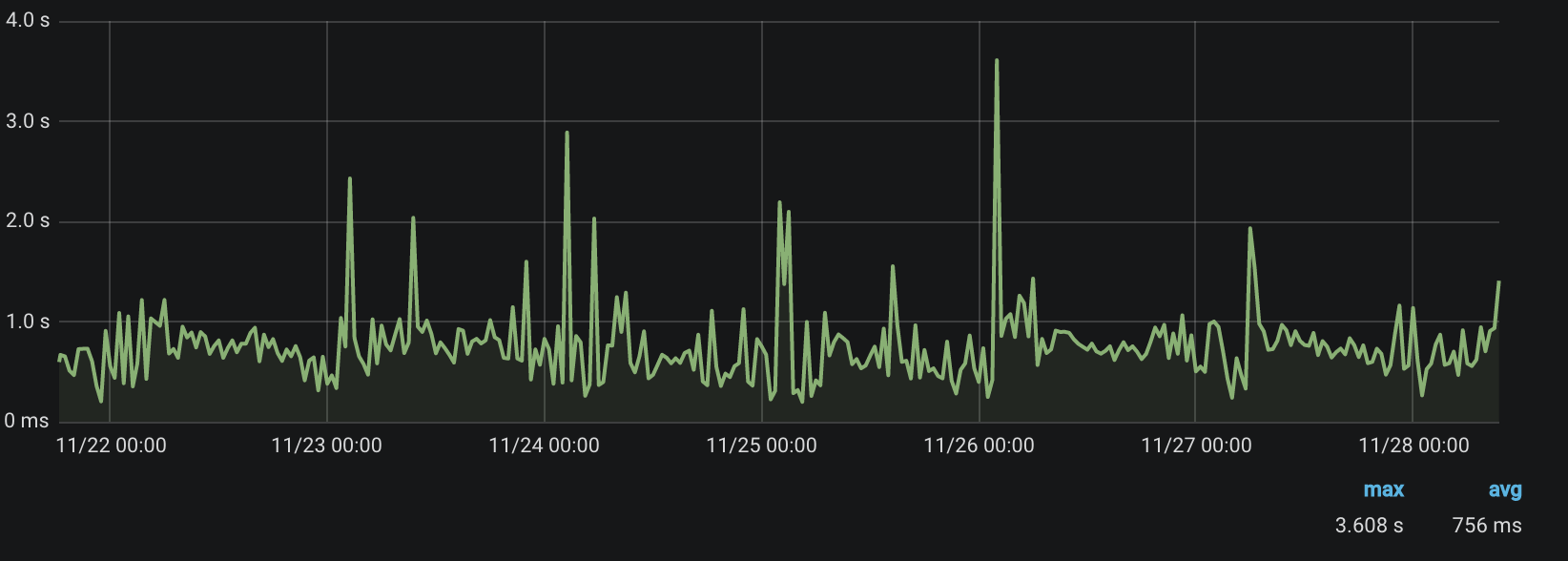

结论
重写并优化逻辑之后,我们设法相当快地处理会员指标,并大大减少了对数据库的查询数量。 事实证明该解决方案很好,我们将在项目的其他部分重用此逻辑。 ORM是我们的一切。
发表评论,提出问题-我们将尽力回答! 谢谢你