业界一直致力于加速矩阵乘法,但是改进搜索算法可以导致更严重的性能提升。

近年来,计算机行业一直在忙于加速人工神经网络所需的计算-既用于培训又用于从其工作中得出结论。 特别是,在特殊铁的开发上投入了大量的精力,可以在这些铁上进行这些计算。 Google开发了
Tensor处理单元 (TPU),该
单元于2016年首次向公众推出。 英伟达随后推出了
V100图形处理单元,并将其描述为专门为训练和使用AI以及其他高性能计算需求而设计的芯片。 充满其他初创公司,专注于其他类型的
硬件加速器 。
也许他们都犯了一个大错误。
这个想法在3月中旬出现在arXiv网站上的
作品中得到了表达。 它的作者,莱斯大学的
Beidi Chen ,
Tarun Medini和
Anshumali Srivastava认为,也许为错误的算法优化了为神经网络的运行而开发的专用设备。
问题在于,神经网络的工作通常取决于设备对于给定的一组输入值,执行用于确定每个人工中子的输出参数的矩阵乘法的速度(即“激活”)。 之所以使用矩阵,是因为将神经元的每个输入值乘以相应的权重参数,然后将它们全部求和-并且这种加法运算是矩阵乘法的基本运算。
赖斯大学的研究人员与其他科学家一样,意识到神经网络特定层中许多神经元的激活作用太小,并且不会影响后续层计算出的输出值。 因此,如果您知道这些神经元是什么,则可以简单地忽略它们。
看来,找出一层中哪些神经元未激活的唯一方法是首先执行该层矩阵乘法的所有操作。 但是研究人员意识到,如果您从另一个角度看问题,您实际上可以决定采用这种更有效的方法。 “我们将这个问题作为解决搜索问题的方法,” Srivastava说。
也就是说,您无需查看矩阵乘法并查看给定输入激活了哪些神经元,而是可以看到数据库中存在哪种神经元。 这种方法在问题中的优点在于,您可以使用计算机科学家长期以来改进的通用策略,以加快数据库中数据的搜索速度:哈希。
散列使您可以快速检查数据库表中是否有值,而不必遍历一行中的每一行。 您使用的哈希值很容易通过将哈希函数应用于所需的值来计算得出,该值指示该值应存储在数据库中的何处。 然后,您只能检查一个位置,以查明此值是否存储在该位置。
研究人员在与神经网络有关的计算中做了类似的事情。 以下示例将帮助说明他们的方法:
假设我们创建了一个可以识别数字手写输入的神经网络。 假设输入是16x16阵列中的灰色像素,即总共256个数字。 我们将这些数据提供给512个神经元的一个隐藏层,其激活结果由10个神经元的输出层提供,每个可能的数目对应一个。
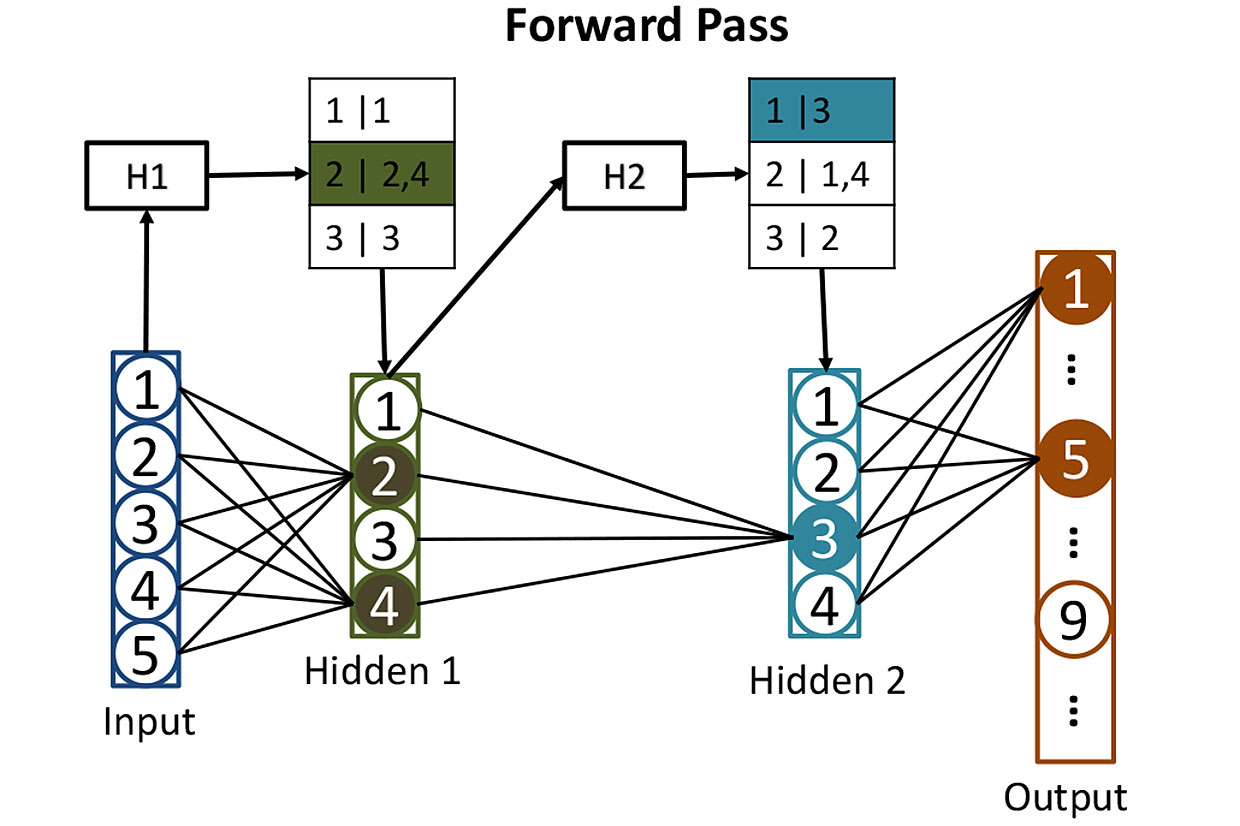 来自网络的表格:在计算隐藏层中神经元的激活之前,我们使用散列来帮助我们确定哪些神经元将被激活。 在此,输入值H1的哈希用于搜索第一隐藏层中的相应神经元-在这种情况下,它将是神经元2和4。第二哈希H2显示了来自第二隐藏层的哪些神经元将起作用。 这样的策略减少了需要计算的激活次数。
来自网络的表格:在计算隐藏层中神经元的激活之前,我们使用散列来帮助我们确定哪些神经元将被激活。 在此,输入值H1的哈希用于搜索第一隐藏层中的相应神经元-在这种情况下,它将是神经元2和4。第二哈希H2显示了来自第二隐藏层的哪些神经元将起作用。 这样的策略减少了需要计算的激活次数。训练这样的网络非常困难,但是现在我们忽略这一刻,并想象我们已经调整了每个神经元的所有权重,以便神经网络能够完美地识别手写数字。 当一个清晰可辨的数字到达她的输入时,其中一个输出神经元(对应于该数字)的激活将接近1。其他9个神经元的激活将接近0。通常,这种网络的操作需要对512个隐藏神经元的每一个进行一个矩阵乘法,每个周末再增加一个-这使我们倍增。
研究人员采取了不同的方法。 第一步是使用“局部敏感哈希”对隐藏层中512个神经元的权重进行哈希处理,其属性之一是相似的输入数据会给出相似的哈希值。 然后,您可以将具有相似哈希值的神经元分组,这意味着这些神经元具有相似的权重集。 每个组可以存储在数据库中,并由将导致该组神经元激活的输入值的哈希值确定。
经过所有这些散列后,事实很容易确定哪些隐藏的神经元将被某些新输入激活。 您需要通过易于计算的哈希函数运行256个输入值,并使用结果在数据库中搜索将被激活的神经元。 这样,您将只需要计算几个重要神经元的激活值。 不必为了发现该层对结果没有贡献而计算该层中所有其他神经元的激活。
这样的神经网络数据的输入可以表示为对数据库的搜索查询的执行,该搜索查询要求找到将通过直接计数激活的所有神经元。 由于使用散列进行搜索,因此您很快就能得到答案。 然后,您可以简单地计算出确实重要的少数神经元的激活。
研究人员已经使用了这种技术(他们称为SLIDE(超深度学习引擎))来训练神经网络,该过程的计算需求比其预期目的要多。 然后,他们将学习算法的性能与使用功能强大的GPU(尤其是Nvidia V100 GPU)的更传统方法进行了比较。 结果,他们得到了令人惊讶的结果:“我们的结果表明,平均而言,在最佳设备上以任何精度实现的CPU SLIDE技术的工作速度都比最佳替代方法快几个数量级。”
现在就这些结果(专家们尚未评估)是否能经受住测试以及是否会迫使芯片制造商对深度学习专用设备的开发采取不同的看法得出结论还为时过早。 但是,这项工作绝对强调了在可能存在新的更好的神经网络算法的情况下,夹带某种铁的危险。