您是否曾经想过从内部看Java对象是什么样的?
在猫下,将详细描述java对象标头,其组成以及占用的内存量。
首先,我们回想一下在jvm中,内存中的任何对象都由对象标头和对象变量(链接和原语)组成。 同样,对象的最终大小可以扩展为8个字节的倍数。
每个对象的标题(数组除外)由两个机器字组成- 标记字和类字 。 数组有一个额外的32位来描述数组的长度。
标记字存储身份哈希码,垃圾回收器使用的位以及用于锁定的位。 您始终可以在相应的OpenJDK 排序markOop.hpp中找到更多详细信息。
类字存储指向该类本身的指针,即该数据类型的信息所在的位置的指针:方法,注释,继承等。 始终可以在相应的OpenJDK 类别klass.hpp中找到更多详细信息。
现在,让我们仔细看看对象的标题,特别是标记词
32位JVM

从表中可以看出, 标记词的内容可能会根据对象的当前状态而有很大差异。
对象的正常状态(biased_lock = 0,lock = 01)
- identity_hashcode是懒惰显示的对象的哈希。 如果该对象第一次具有System.identityHashCode(obj)调用,则将计算此哈希并将其写入对象标头。
在其他状态下,当各种流争用一个对象时,identity_hashcode不会存储在对象标头中,而是存储在对象的监视器中。 - 年龄-经历的垃圾收集数量。 当年龄达到最大使用期限数时,
该对象移动到老一代的臀部区域。 - biased_lock-如果为此对象启用了偏向锁定,则包含1,否则为0。
多一点启用“偏置锁定”时,对象将原样移动到捕获其监视器的第一个对象。 随后在同一流中捕获对象会稍快一些。
这是此锁的基本理论先决条件:
- 在对象的整个生命周期中,它主要由一个流拥有。
- 如果线程最近在此对象上使用了锁定,则很有可能处理器缓存将仍然包含重新捕获该对象所需的数据。
自Java 6,-XX以来,默认情况下启用了偏向锁定功能:-UseBiasedLocking
- lock-包含锁定状态代码。 00-轻型锁定,01-解锁或偏置,10-重型锁定,11-标记为垃圾回收。
即,在表中,对象的状态由biased_lock和lock位的组合确定。
偏向锁定模式(biased_lock = 1,锁定= 01)
- 线程-在偏置锁定模式下,假定该对象主要由特定线程拥有,该线程的ID存储在字段中。
- 时代包含一个临时的对象所有权指示符,该线程的ID存储在线程中
轻量级锁定模式(锁定= 00)
在这种模式下,假定该对象通过不同流的捕获时间根本不相交或没有明显的重叠。 在这种模式下,JVM不会使用原子来代替阻塞操作系统。
- ptr_to_lock_record-自旋循环内的CAS(比较并设置)用于设置/等待锁定。
作为参考,在原子的帮助下,最小OS阻塞时间将在大约10毫秒的范围内,流不会进入睡眠状态,而是继续打一个小周期,并且一旦资源释放,原子周期将立即终止,并且流将立即捕获该对象。
重量级锁定模式(锁定= 10)
- ptr_to_heavyweight_monitor-如果此对象在不同流中的捕获时间将明显重叠,则轻量级锁将被重量级锁代替。 指向监视器的指针将被写入ptr_to_heavyweight_monitor。 使用了操作系统锁定。
因此,在32位jvm中,对象的标头由8个字节组成。 数组还具有4个字节。
64位JVM

在64位jvm上,对象标头由16个字节组成。 数组还具有4个字节。
具有指针压缩功能的64位jvm
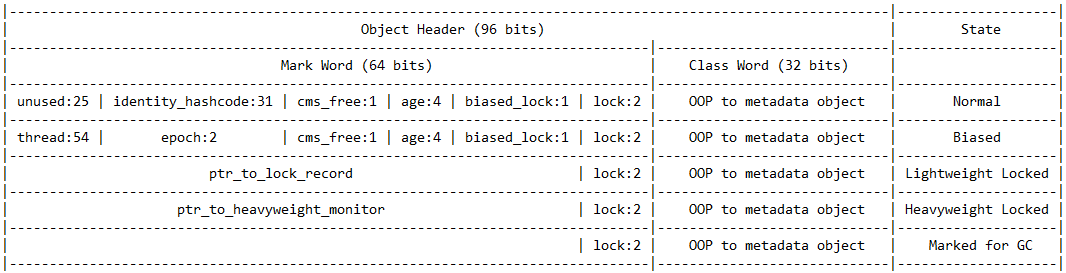
对象标头由12个字节组成。 数组还具有4个字节。
关于指针压缩的一些知识。 对于32位指针,地址空间限制为4GB。 但是,如果我们再次回忆起在jvm中,对象的大小是8字节的倍数,则可以使用伪35位指针,结尾处带有三个零。 因此,已经参考了32GB的内存。 压缩不是免费的,价格是任何调用堆的附加操作(指针<< 3)。
链接到原始文章:
Java对象头
我还要补充一点,这里描述的所有内容都不是教条,也许在其他版本的jvm中,对象的标题会有所不同。 这里描述的内容与openjdk 8有关。