大家好
信息系统安全课程的发布时间越来越短,这就是为什么今天我们继续共享致力于该课程启动的出版物。 顺便说一下,该出版物是这两篇文章的继续:
“ JavaScript引擎基础知识:常规形式和内联缓存。 第1部分“ ”,JavaScript引擎的基础:常规形式和内联缓存。 第二部分“ 。
本文介绍了关键的基础知识。 它们对于所有JavaScript引擎都是通用的,而不仅仅是作者正在使用的
V8 (
Benedict和
Matthias )。 作为JavaScript开发人员,我可以说,对JavaScript引擎如何工作的更深入的了解将帮助您弄清楚如何编写有效的代码。

在
上一篇文章中,我们讨论了JavaScript引擎如何使用表单和内联缓存优化对对象和数组的访问。 在本文中,我们将研究优化管道折衷方案并加快对原型属性的访问。
注意:如果您喜欢观看演示文稿而不是阅读文章,请观看此视频 。 如果不是,则跳过它并继续阅读。
优化和权衡的水平上一次我们发现实际上所有现代JavaScript引擎都具有相同的管道:
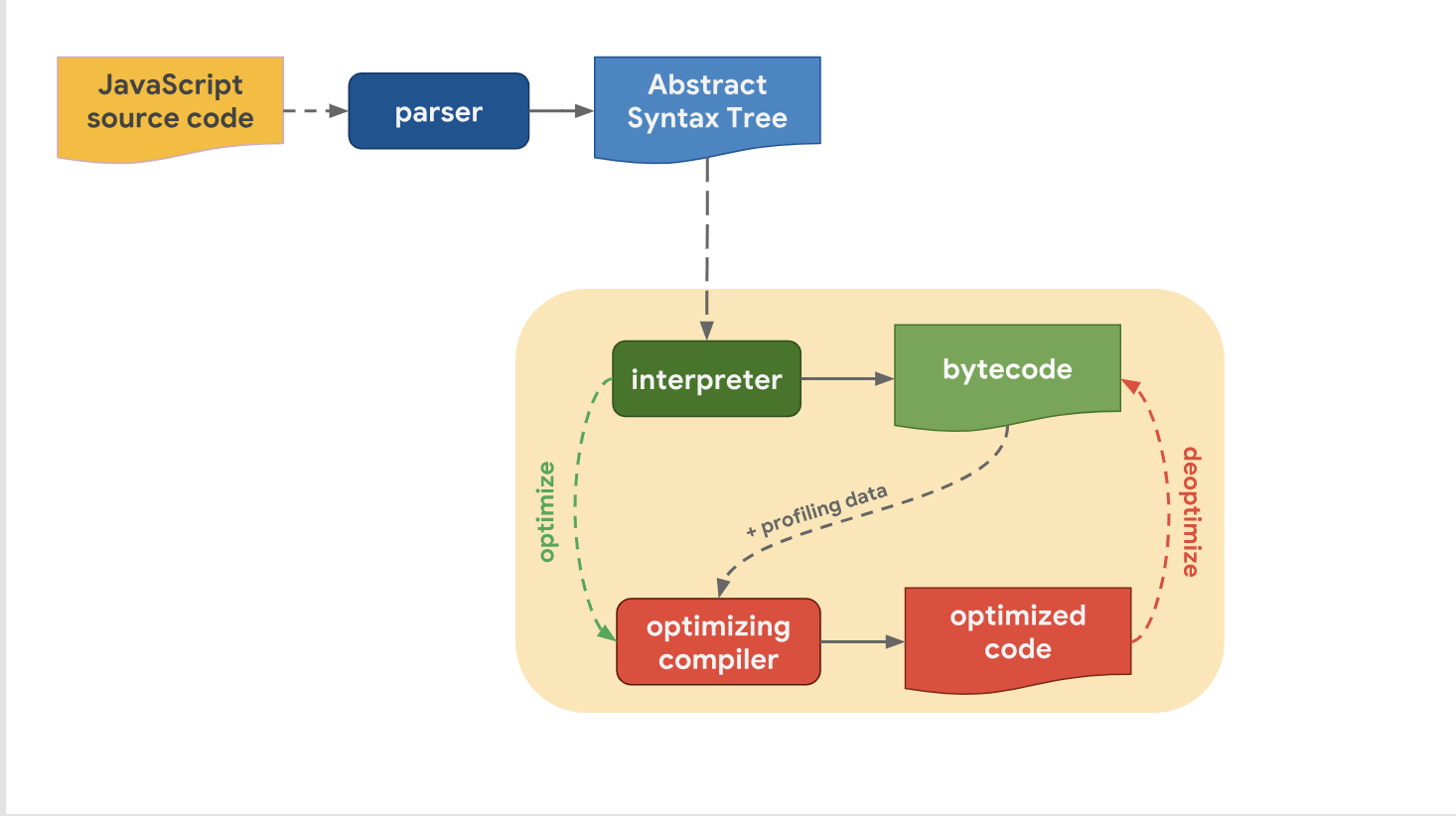
我们还认识到,尽管引擎之间的高级管道在结构上相似,但优化管道还是有所不同。 为什么会这样呢? 为什么某些引擎比其他引擎具有更高的优化级别? 关键是要在快速过渡到代码执行阶段或花费更多时间来以最佳性能执行代码之间做出折衷。

解释器可以快速生成字节码,但是仅字节码在速度方面还不够高效。 使优化的编译器参与此过程会花费一定的时间,但可以使机器代码更有效。
让我们看一下V8是如何处理的。 回想一下,在V8中,解释器称为Ignition,它被认为是现有引擎中最快的解释器(就原始字节码执行速度而言)。 V8中的优化编译器称为TurboFan,正是他生成了高度优化的机器代码。

在启动延迟和执行速度之间进行权衡是某些JavaScript引擎倾向于在步骤之间添加其他优化级别的原因。 例如,SpiderMonkey在其解释器和全面优化的IonMonkey编译器之间添加了一个Baseline层:
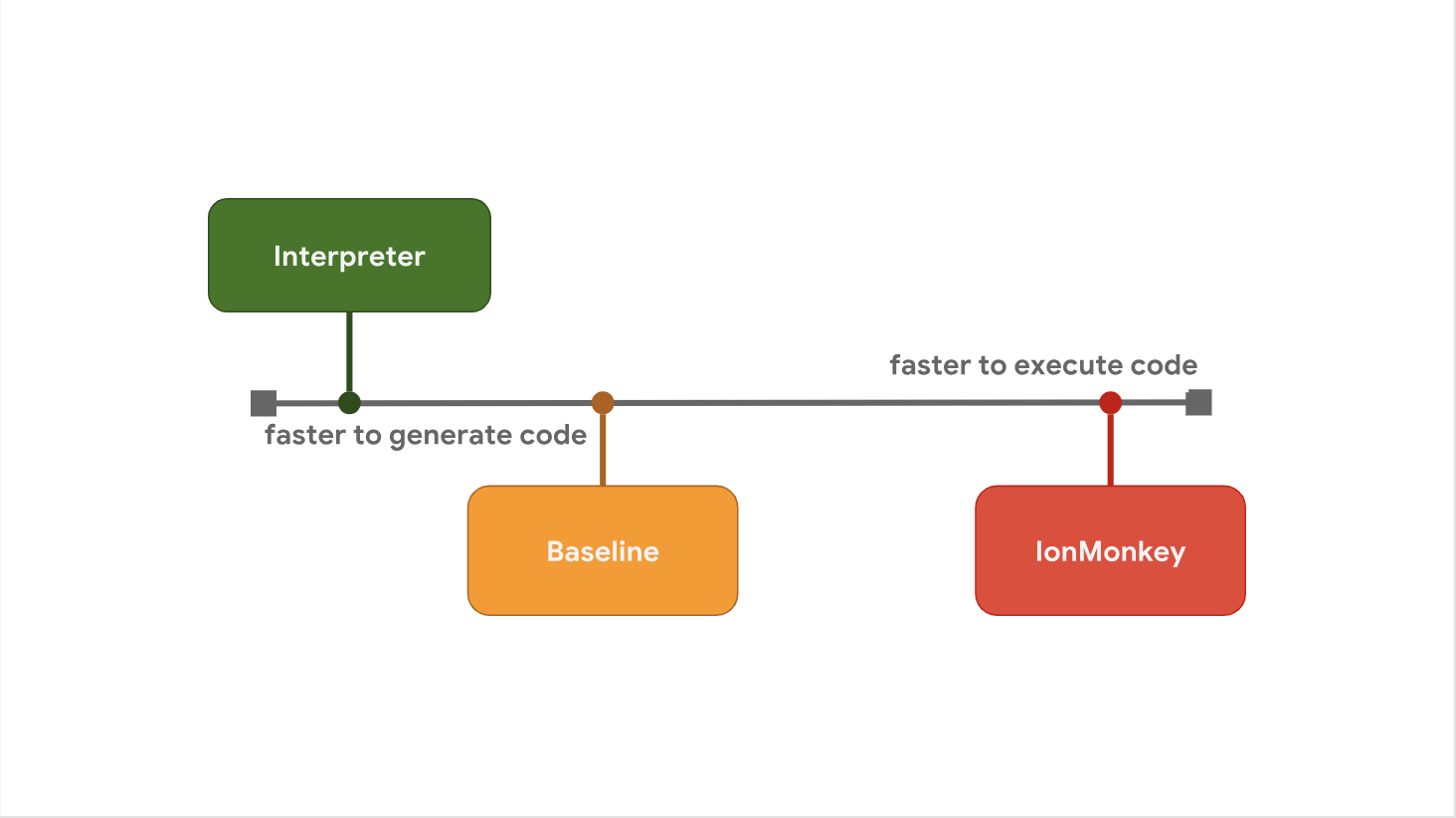
解释器快速生成字节码,但是字节码本身相对较慢。 基准生成代码的时间更长一些,但是在运行时提供了改进的性能。 最后,优化的编译器IonMonkey花费最多的时间来生成机器代码,但是这种代码非常高效。
让我们看一个特定的示例,看看各种引擎的管道如何处理此问题。 在热循环中,通常会重复相同的代码。
let result = 0; for (let i = 0; i < 4242424242; ++i) { result += i; } console.log(result);
V8通过在Ignition解释器中启动字节码开始。 在某个时候,引擎确定代码很热,然后启动TurboFan接口,该接口集成了性能分析数据并构建了代码的基本机器表示。 然后将其发送到另一个线程中的TurboFan优化器以进行进一步改进。

在进行优化的同时,V8继续在Ignition中执行代码。 在某个时候,当优化器完成并且我们已经收到可执行的机器代码时,它会立即进入执行阶段。
SpyderMonkey也开始在解释器中执行字节码。 但是它还有一个附加的基准级别,这意味着热代码首先发送到那里。 Baseline编译器在主线程中生成Baseline代码,并在其生成结束时继续执行。

如果Baseline代码已经运行了一段时间,SpiderMonkey最终将启动IonMonkey接口(IonMonkey前端)并启动优化器,该过程与V8非常相似。 IonMonkey从事优化工作的同时,所有这些工作在Baseline中继续同时进行。 最后,当优化器完成工作时,将执行优化的代码而不是基准代码。
Chakra的体系结构与SpiderMonkey非常相似,但是Chakra试图同时运行更多的进程,以避免阻塞主线程。 Chakra不会在主线程中运行编译器的任何部分,而是复制编译器需要的字节码和配置文件数据,并将其发送到专用的编译器进程。

准备好生成的代码后,引擎将执行此SimpleJIT代码而不是字节码。 FullJIT也会发生相同的情况。 这种方法的优点是复制期间发生的暂停通常比启动成熟的编译器(前端)要短得多。 另一方面,该方法具有缺点。 事实是,复制启发式可以跳过一些优化所需的信息,因此我们可以说,在某种程度上牺牲了代码质量以加快工作速度。
在JavaScriptCore中,所有优化的编译器都可以与JavaScript的基本执行完全并行地工作。 没有复制阶段。 相反,主线程只是开始在另一个线程中进行编译。 然后,编译器使用复杂的锁定方案从主线程访问配置文件数据。

这种方法的优点在于,它减少了优化后在主线程中出现的垃圾数量。 这种方法的缺点是,它需要解决复杂的多线程问题以及各种操作的阻塞成本。
我们讨论了解释器运行时快速代码生成与使用优化编译器快速代码生成之间的权衡。 但是还有另一种折衷,它涉及内存的使用。 为了说明这一点,我编写了一个简单的JavaScript程序,该程序将两个数字相加。
function add(x, y) { return x + y; } add(1, 2);
查看V8中Ignition解释器为add函数生成的字节码。
StackCheck Ldar a1 Add a0, [0] Return
不必担心字节码,您不必能够读取它。 在这里有必要注意它
仅包含
4条指令的事实。
当代码变热时,TurboFan会生成高度优化的机器代码,如下所示:
leaq rcx,[rip+0x0] movq rcx,[rcx-0x37] testb [rcx+0xf],0x1 jnz CompileLazyDeoptimizedCode push rbp movq rbp,rsp push rsi push rdi cmpq rsp,[r13+0xe88] jna StackOverflow movq rax,[rbp+0x18] test al,0x1 jnz Deoptimize movq rbx,[rbp+0x10] testb rbx,0x1 jnz Deoptimize movq rdx,rbx shrq rdx, 32 movq rcx,rax shrq rcx, 32 addl rdx,rcx jo Deoptimize shlq rdx, 32 movq rax,rdx movq rsp,rbp pop rbp ret 0x18
这里确实有很多团队,特别是与我们在字节码中看到的四个团队相比。 通常,字节码比机器代码(尤其是优化的机器代码)具有更大的容量。 另一方面,字节码由解释器执行,而优化的代码可以直接由处理器执行。
这就是JavaScript引擎不仅仅“优化所有内容”的原因之一。 正如我们前面所看到的,生成优化的机器代码需要很多时间,因此需要更多的内存。
 总结:
总结: JavaScript引擎具有不同级别的优化的原因是要在使用解释器的快速代码生成与使用优化的编译器的快速代码生成之间找到折衷方案。 添加更多的优化级别可以使您根据执行过程中额外的复杂性和开销而做出更明智的决策。 此外,在优化级别和内存使用之间需要权衡。 这就是JavaScript引擎仅尝试优化热功能的原因。
优化对原型属性的访问上次我们讨论了JavaScript引擎如何使用表单和内联缓存优化对象属性的加载。 回想一下,引擎将对象的形状与对象的值分开存储。
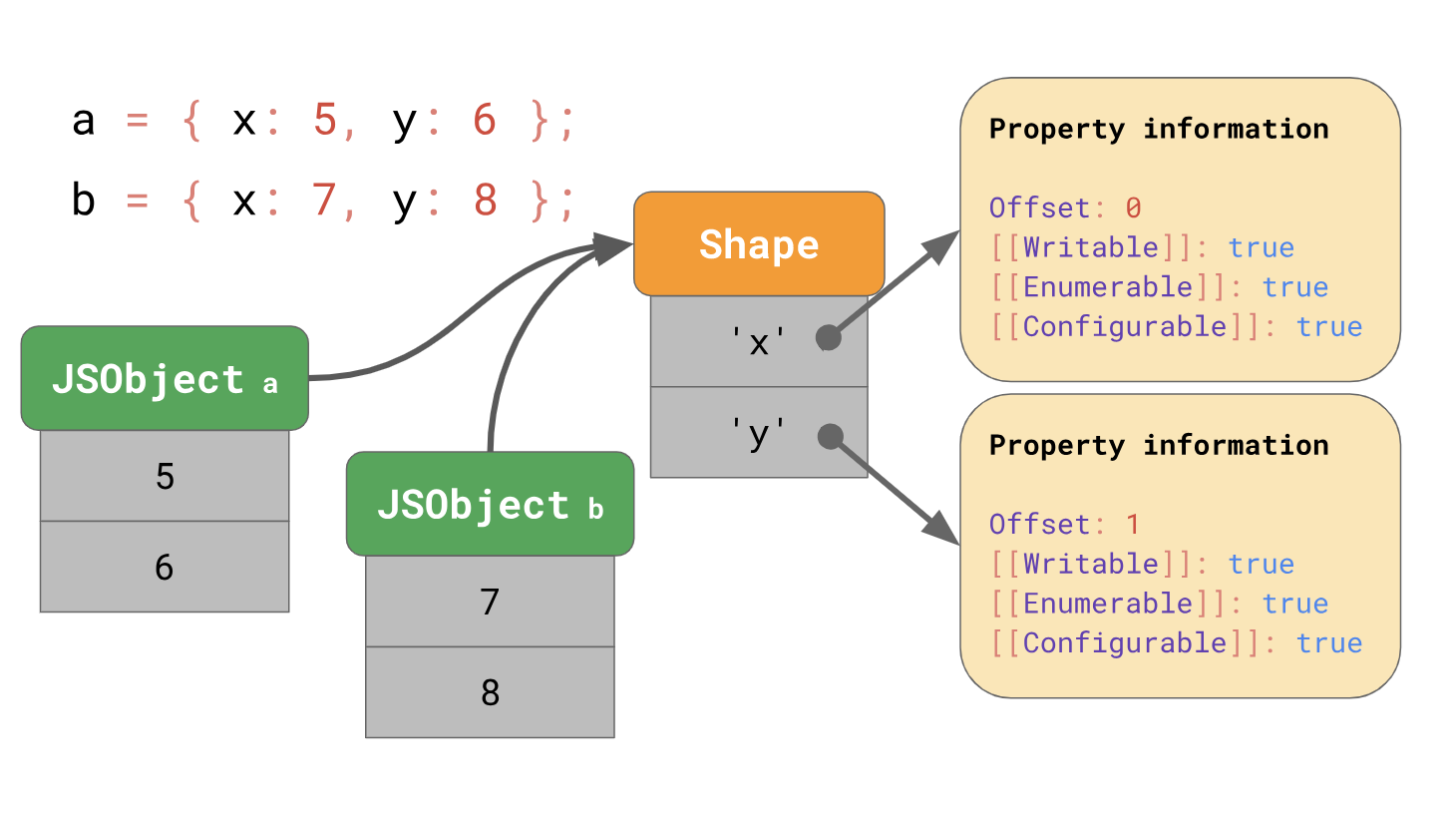
表格使您可以使用内联缓存或缩写的IC进行优化。 一起工作时,表单和IC可以加快从代码中同一位置重复访问属性的速度。
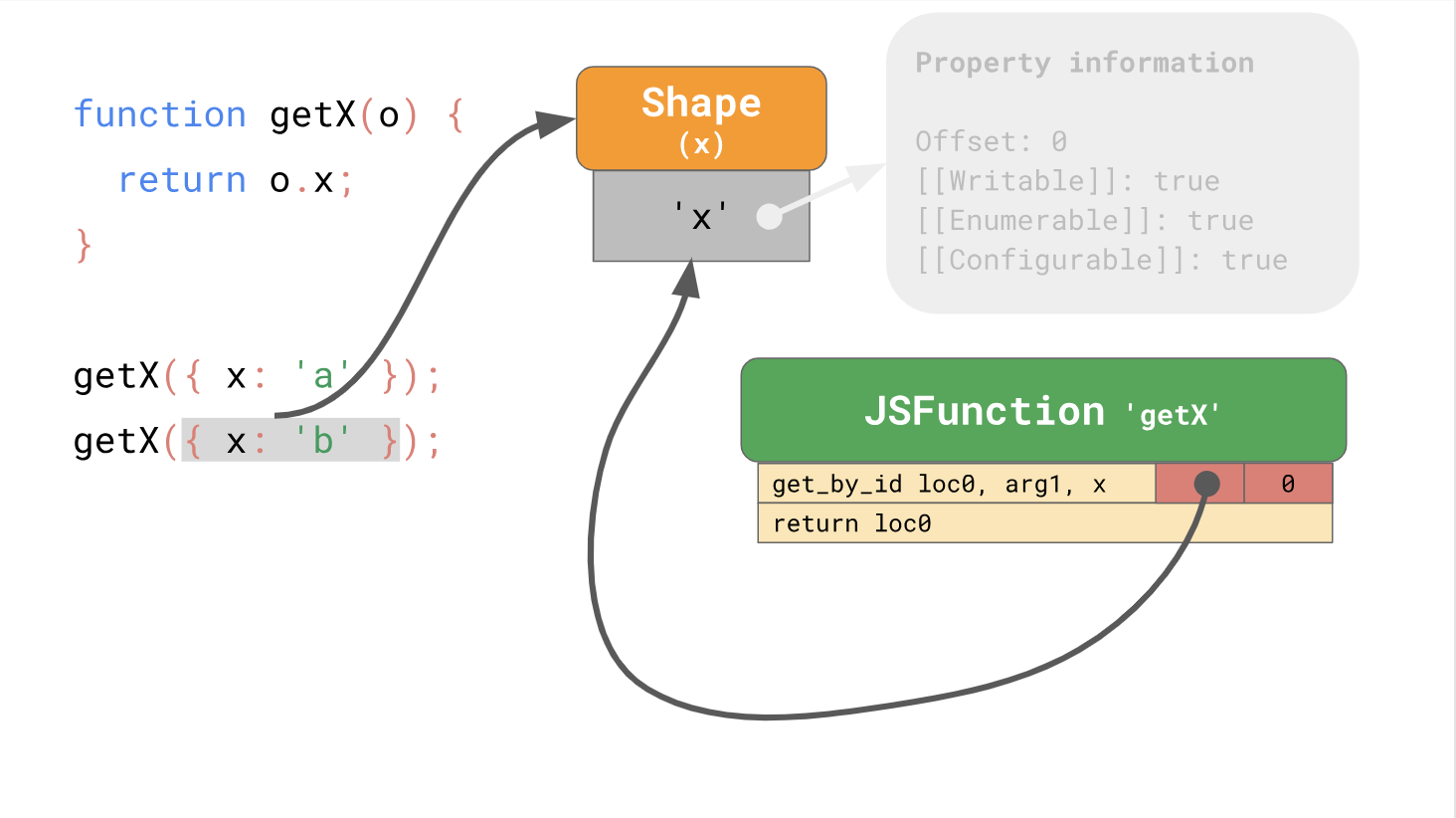
因此,该出版物的第一部分结束了,
第二部分中提供了有关类和原型编程的信息。 传统上,我们在等待您的评论和激烈的讨论,同时也邀请您参加“信息系统安全”课程的
开放日 。