通常,Nginx使用商业产品或开源替代产品(例如Prometheus + Grafana)来监视和分析Nginx的性能。 这对于监视或实时分析是一个不错的选择,但对于历史分析而言却不太方便。 在任何流行的资源上,nginx日志中的数据量都在迅速增长,因此使用更专业的工具来分析大量数据是合乎逻辑的。
在本文中,我将以Nginx为例,介绍如何使用Athena分析日志,并展示如何使用开源cube.js框架从此数据编译分析仪表板。 这是完整的解决方案架构:

TL:DR;
链接到完成的仪表板 。
我们使用Fluentd收集信息,使用AWS Kinesis Data Firehose和AWS Glue进行处理,使用AWS S3进行存储。 使用此捆绑包,您不仅可以存储nginx日志,还可以存储其他事件以及其他服务的日志。 您可以将某些部分替换为堆栈中的相似部分,例如,您可以直接从nginx将日志写入kinesis,绕过fluentd,或使用logstash做到这一点。
收集Nginx日志
默认情况下,Nginx日志如下所示:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-" 4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
可以解析它们,但是修复Nginx配置要容易得多,以便它以JSON显示日志:
log_format json_combined escape=json '{ "created_at": "$msec", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"request": "$request", ' '"status": $status, ' '"bytes_sent": $bytes_sent, ' '"request_length": $request_length, ' '"request_time": $request_time, ' '"http_referrer": "$http_referer", ' '"http_x_forwarded_for": "$http_x_forwarded_for", ' '"http_user_agent": "$http_user_agent" }'; access_log /var/log/nginx/access.log json_combined;
S3用于存储
要存储日志,我们将使用S3。 由于Athena可以直接使用S3中的数据,因此您可以在一个地方存储和分析日志。 在本文后面的内容中,我将告诉您如何正确折叠和处理日志,但是首先我们需要在S3中有一个干净的存储桶,该存储桶中不会存储其他任何内容。 提前考虑在哪个区域创建存储桶是值得的,因为Athena并非在所有区域都可用。
在Athena控制台中创建图表
在Athena中创建一个用于日志的表。 如果您打算使用Kinesis Firehose,则写作和阅读都需要它。 打开Athena控制台并创建一个表:
SQL表创建 CREATE EXTERNAL TABLE `kinesis_logs_nginx`( `created_at` double, `remote_addr` string, `remote_user` string, `request` string, `status` int, `bytes_sent` int, `request_length` int, `request_time` double, `http_referrer` string, `http_x_forwarded_for` string, `http_user_agent` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 's3://<YOUR-S3-BUCKET>' TBLPROPERTIES ('has_encrypted_data'='false');
创建Kinesis Firehose流
Kinesis Firehose将以选定的格式将从Nginx接收的数据写入S3,并分成YYYY / MM / DD / HH格式的目录。 这在读取数据时很有用。 当然,您可以从fluentd直接写入S3,但是在这种情况下,您必须编写JSON,由于文件大而效率低。 此外,在使用PrestoDB或Athena时,JSON是最慢的数据格式。 因此,打开Kinesis Firehose控制台,单击“创建交付流”,在“交付”字段中选择“直接PUT”:
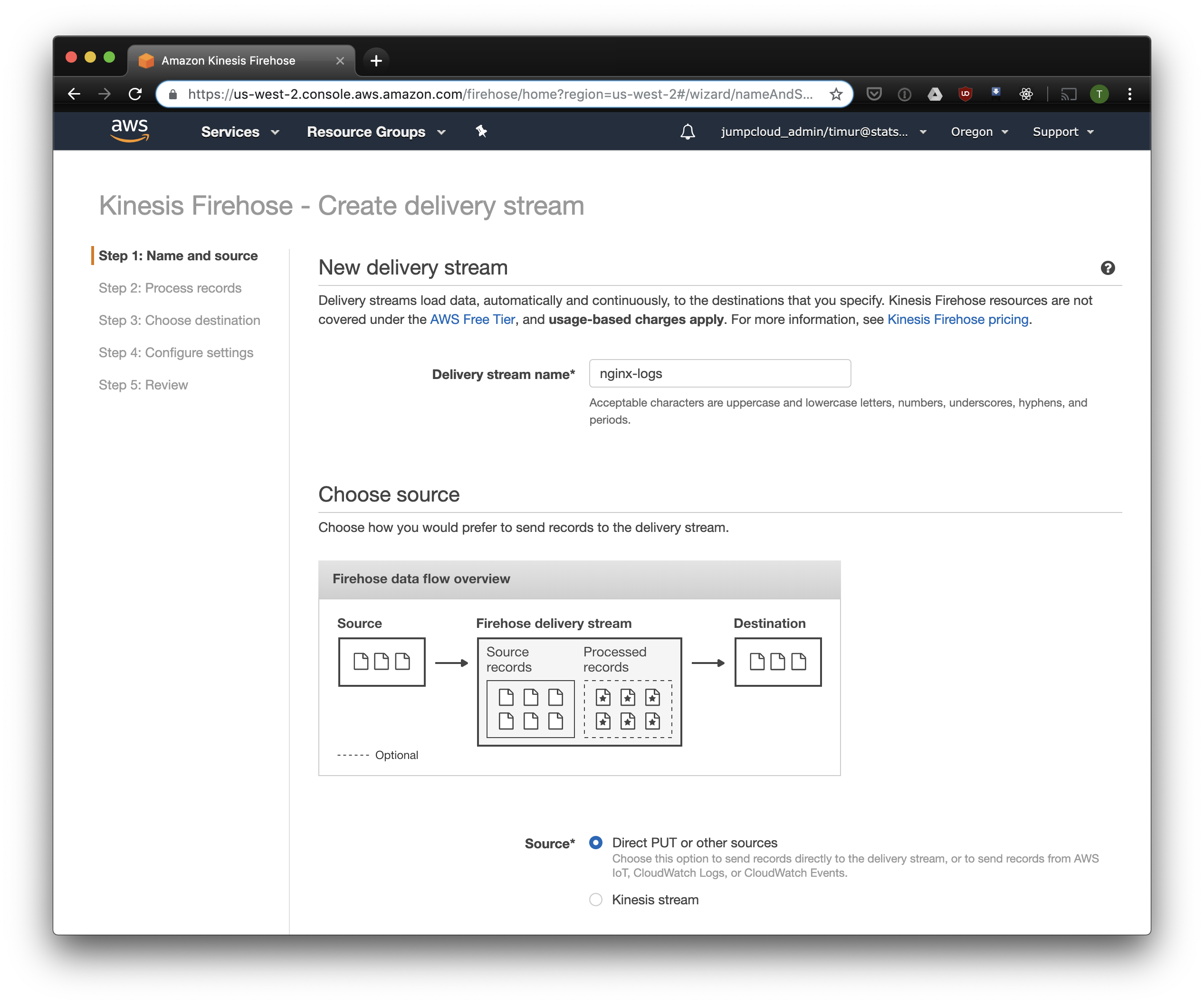
在下一个标签中,选择“记录格式转换”-“启用”,然后选择“ Apache ORC”作为记录格式。 根据Owen O'Malley的说法,这是PrestoDB和Athena的最佳格式。 作为图表,我们指出了我们在上面创建的表。 请注意,您可以在运动学中指定任何S3位置,仅使用表中的方案。 但是,如果指定另一个S3位置,则无法从该表读取这些记录。
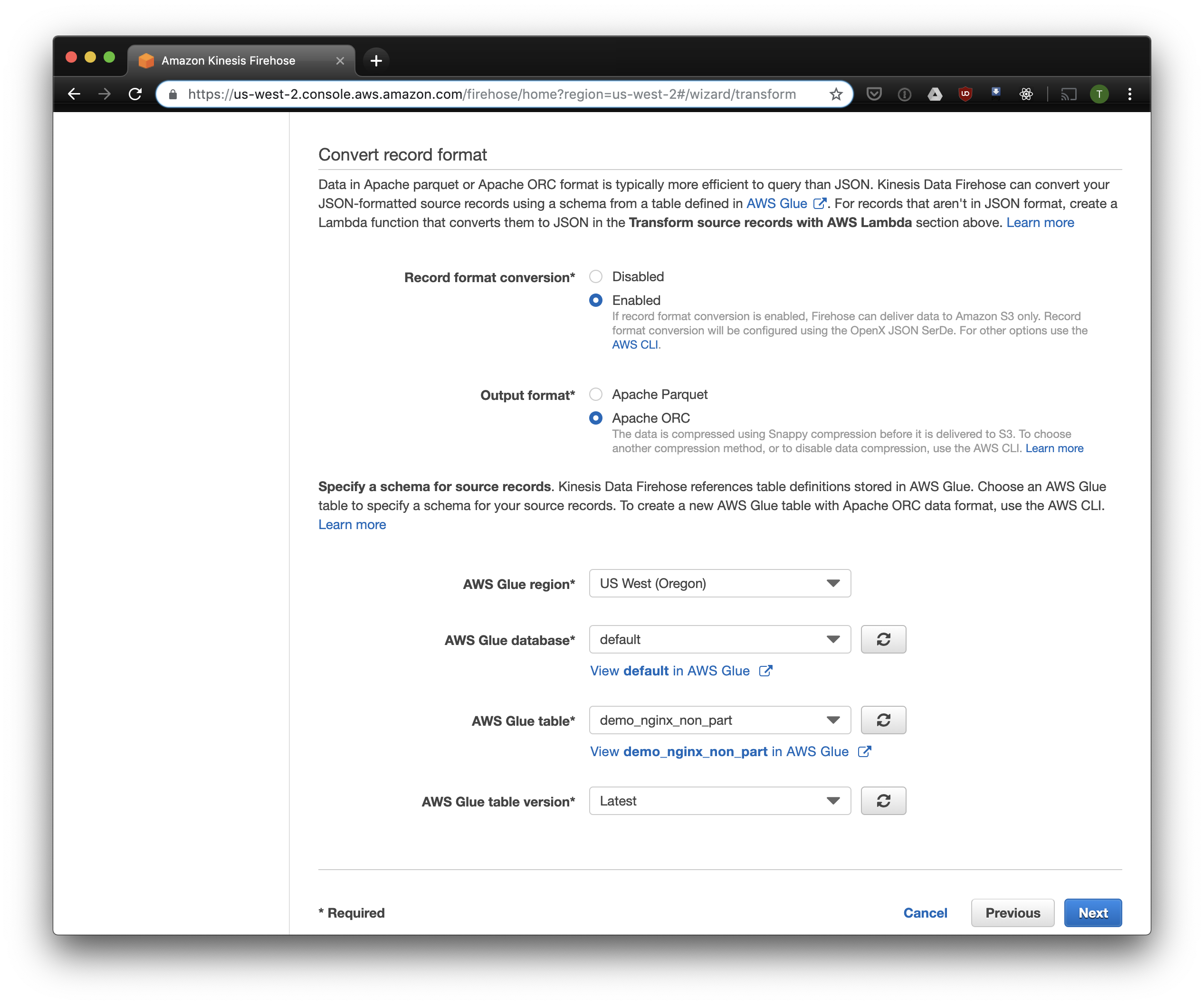
我们选择S3进行存储,并选择之前创建的存储桶。 我将在稍后讨论的Aws Glue Crawler不知道如何在S3存储桶中使用前缀,因此将其留空很重要。

其余选项可以根据您的负载进行更改,我通常使用默认选项。 请注意,S3压缩不可用,但是ORC默认使用本机压缩。
流利的
现在我们已经配置了日志的存储和接收,您需要配置发送。 因为我喜欢Ruby,所以我们将使用Fluentd ,但是您可以使用Logstash或将日志直接发送到kinesis。 您可以通过几种方式启动Fluentd服务器,我将讨论docker,因为它既简单又方便。
首先,我们需要fluent.conf配置文件。 创建它并添加源:
向前输入
端口24224
绑定0.0.0.0
现在您可以启动Fluentd服务器。 如果您需要更高级的配置,则Docker Hub会提供详细的指南,包括如何组装映像。
$ docker run \ -d \ -p 24224:24224 \ -p 24224:24224/udp \ -v /data:/fluentd/log \ -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd \ -c /fluentd/etc/fluent.conf fluent/fluentd:stable
此配置在发送前使用/fluentd/log路径缓存日志。 您可以不这样做,但是随后重新启动时,您可能会丢失过多劳力所缓存的所有内容。 也可以使用任何端口,24224是默认的Fluentd端口。
现在我们已经运行了Fluentd,我们可以在此处发送Nginx日志了。 我们通常在Docker容器中运行Nginx,在这种情况下,Docker具有Fluentd的本机日志驱动程序:
$ docker run \ --log-driver=fluentd \ --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>\ --log-opt tag=\"{{.Name}}\" \ -v /some/content:/usr/share/nginx/html:ro \ -d \ nginx
如果以其他方式运行Nginx,则可以使用日志文件,Fluentd具有文件尾插件 。
将上面配置的日志解析添加到Fluent配置中:
<filter YOUR-NGINX-TAG.*> @type parser key_name log emit_invalid_record_to_error false <parse> @type json </parse> </filter>
并使用kinesis firehose插件将日志发送到Kinesis:
<match YOUR-NGINX-TAG.*> @type kinesis_firehose region region delivery_stream_name <YOUR-KINESIS-STREAM-NAME> aws_key_id <YOUR-AWS-KEY-ID> aws_sec_key <YOUR_AWS-SEC_KEY> </match>
雅典娜
如果正确配置了所有内容,则过一会儿(默认情况下,Kinesis会每10分钟写入一次接收到的数据),您应该会在S3中看到日志文件。 在Kinesis Firehose的“监视”菜单中,您可以查看向S3写入了多少数据以及错误。 不要忘记为Kinesis角色授予对S3存储桶的写访问权限。 如果Kinesis无法解析某些内容,他将在同一存储桶中添加错误。
现在您可以在Athena中查看数据。 让我们找到一些错误的新查询:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;
扫描每个请求的所有记录
现在,我们的日志已在ORC中的S3中进行处理和堆叠,压缩并准备进行分析。 Kinesis Firehose甚至每小时都将它们放在目录中。 但是,在不对表进行分区的情况下,Athena会为每个查询加载所有时间的数据(极少数例外)。 这是一个大问题,原因有两个:
- 数据量在不断增长,减慢了查询速度;
- 雅典娜是根据扫描的数据量计费的,每个请求至少10 MB。
为了解决这个问题,我们使用AWS Glue Crawler,它将扫描S3中的数据并将分区信息记录在Glue Metastore中。 这将使我们能够将分区用作Athena中请求的筛选器,并且仅扫描请求中指定的目录。
自定义Amazon Glue Crawler
Amazon Glue Crawler扫描S3存储桶中的所有数据并创建分区表。 从AWS Glue控制台创建一个Glue Crawler,然后添加存储数据的存储桶。 您可以将一个搜寻器用于多个存储桶,在这种情况下,它将在指定的数据库中创建名称与存储桶名称匹配的表。 如果您打算一直使用此数据,请确保调整Crawler启动时间表以适合您的需求。 我们对所有表使用一个Crawler,该表每小时运行一次。
分区表
首次启动搜寻器后,每个已扫描存储区的表应出现在设置中指定的数据库中。 打开Athena控制台,找到带有Nginx日志的表。 让我们尝试阅读一些内容:
SELECT * FROM "default"."part_demo_kinesis_bucket" WHERE( partition_0 = '2019' AND partition_1 = '04' AND partition_2 = '08' AND partition_3 = '06' );
该查询将选择2019年4月8日上午6点至上午7点收到的所有记录。 但是,比仅从非分区表中读取数据更有效? 让我们通过按时间戳过滤找到并选择相同的记录:
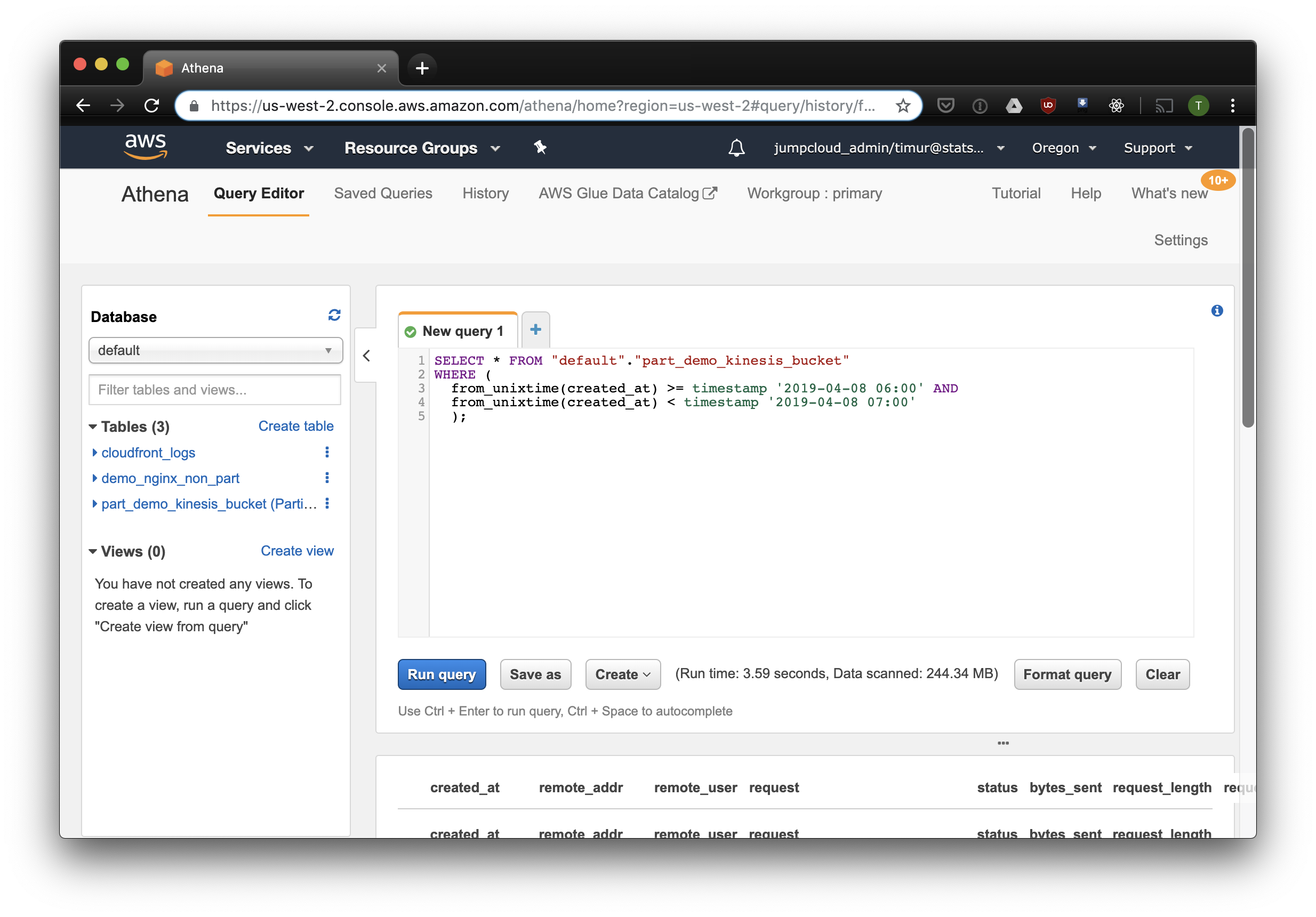
数据集上的数据只有3.59秒和244.34兆字节,其中只有一个星期的日志。 让我们尝试按分区进行过滤:
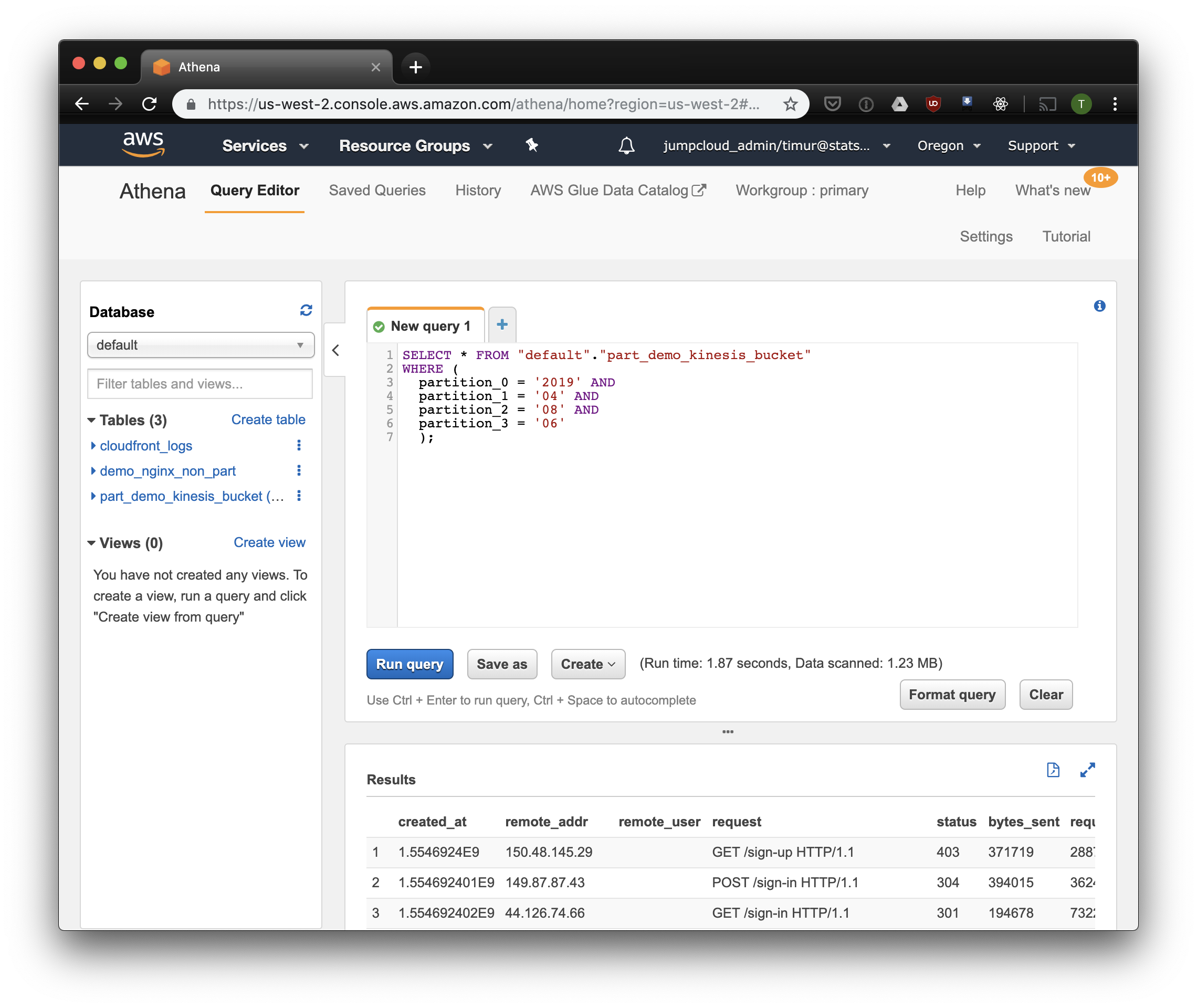
更快一点,但最重要的是-只有1.23兆字节的数据! 如果价格不低于每个请求10兆字节,则价格会便宜得多。 但无论如何还是要好得多,在大型数据集上,差异将更加明显。
使用Cube.js构建仪表板
要构建仪表板,我们使用Cube.js分析框架。 它具有很多功能,但我们感兴趣的是两个:在分区上自动使用过滤器和预先聚合数据的功能。 它使用用Javascript编写的数据模式来生成SQL并执行数据库查询。 我们所要做的就是指示如何在数据模式中使用分区过滤器。
让我们创建一个新的应用程序Cube.js。 由于我们已经使用过AWS堆栈,因此使用Lambda进行部署是合乎逻辑的。 如果计划在Heroku或Docker中托管Cube.js后端,则可以使用express模板进行生成。 该文档描述了其他托管方法 。
$ npm install -g cubejs-cli $ cubejs create nginx-log-analytics -t serverless -d athena
环境变量用于在cube.js中配置对数据库的访问。 生成器将创建一个.env文件,您可以在其中指定Athena的密钥。
现在我们需要一个数据方案,在其中可以指示日志的存储方式。 您可以在此处指定如何读取仪表板的指标。
在schema目录中,创建Logs.js文件。 这是nginx的示例数据模型:
型号代码 const partitionFilter = (from, to) => ` date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') ` cube(`Logs`, { sql: ` select * from part_demo_kinesis_bucket WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)} `, measures: { count: { type: `count`, }, errorCount: { type: `count`, filters: [ { sql: `${CUBE.isError} = 'Yes'` } ] }, errorRate: { type: `number`, sql: `100.0 * ${errorCount} / ${count}`, format: `percent` } }, dimensions: { status: { sql: `status`, type: `number` }, isError: { type: `string`, case: { when: [{ sql: `${CUBE}.status >= 400`, label: `Yes` }], else: { label: `No` } } }, createdAt: { sql: `from_unixtime(created_at)`, type: `time` } } });
在这里,我们使用FILTER_PARAMS变量来生成带有分区过滤器的SQL查询。
我们还指定了要显示在仪表板上的指标和参数,并指定了预聚合。 Cube.js将使用预聚合的数据创建其他表,并将在数据可用时自动更新。 这不仅加快了请求的速度,而且降低了使用Athena的成本。
将此信息添加到数据模式文件:
preAggregations: { main: { type: `rollup`, measureReferences: [count, errorCount], dimensionReferences: [isError, status], timeDimensionReference: createdAt, granularity: `day`, partitionGranularity: `month`, refreshKey: { sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) => `select CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now() THEN date_trunc('hour', now()) END` ) } } }
在此模型中,我们指出有必要为所有使用的指标预先汇总数据,并使用每月分区。 对预聚合进行分区可以大大加快数据收集和更新的速度。
现在我们可以组装一个仪表板了!
Cube.js后端为流行的前端框架提供了REST API和一组客户端库。 我们将使用客户端的React版本来构建仪表板。 Cube.js仅提供数据,因此我们需要一个可视化库-我喜欢recharts ,但是您可以使用任何一个。
Cube.js服务器接受JSON格式的请求,该请求指示必要的指标。 例如,要计算Nginx每天给出的错误数量,您需要发送以下请求:
{ "measures": ["Logs.errorCount"], "timeDimensions": [ { "dimension": "Logs.createdAt", "dateRange": ["2019-01-01", "2019-01-07"], "granularity": "day" } ] }
通过NPM安装Cube.js客户端和React组件库:
$ npm i --save @cubejs-client/core @cubejs-client/react
我们导入cubejs和QueryRenderer组件以卸载数据,并收集仪表板:
仪表板代码 import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) }
仪表板源位于CodeSandbox上 。