不久前,我遇到了一个相当简单且有趣的任务:在Web应用程序中实现只读终端。 对任务的兴趣来自三个重要方面:
在本文中,我将讨论如何实现以及如何对其进行优化。
免责声明:我不是一位经验丰富的Web开发人员,因此某些事情对您来说似乎很明显,并且结论或决定是错误的。 对于更正和澄清,我将不胜感激。
为什么要这样
整个任务如下:脚本在服务器上运行(bash,python等),并将一些内容写入stdout。 这个结论必须在到达时显示在网页上。 同时,它在终端上应该看起来像(带有格式化,光标转移等)。
我不以任何方式控制脚本本身及其输出,并以纯格式显示它。
当然,在Web界面和脚本之间应该有一个中介-Web服务器。 而且,如果不拆卸,我已经有一个Web应用程序和一个服务器,并且可以正常工作。 该方案如下所示:

但是在此之前,服务器负责处理和格式化。 我出于很多原因希望对其进行改进:
- 双重数据处理-首先在服务器上解析,然后在客户端上转换为html组件
- 由于为客户准备了数据,导致非最佳算法
- 服务器上的负载很重-处理单个脚本的输出可能会完全在服务器上加载单个线程
- 对ANSI Escape序列的不完全支持
- 细微的错误
- 客户甚至无法显示10k格式化的行
因此,决定将整个解析逻辑转移到Web应用程序,而只将流原始数据留给服务器。
问题陈述
文本的一部分到达客户端。 客户端必须将它们解析为以下组件:纯文本,换行符,回车符和特殊的ANSI命令。 部件的完整性无法保证-一个命令或一个单词可以放在不同的包装中。
ANSI命令可能会影响文本的格式(颜色,背景,样式),光标的位置(应显示后续文本的位置)或清除屏幕的一部分。
外观示例:

另外,文本中可能还存在一些需要识别和突出显示的URL。
我们拿完图书馆,然后...
我知道正确和快速处理所有命令不是一件容易的事。 因此,我决定寻找现成的图书馆。 而且, 瞧 ,我立即偶然发现了xterm.js 。 终端的现成组件已在许多地方使用,此外, “确实非常快,它甚至包括GPU加速的渲染器” 。 后者对我来说是最重要的,因为 我终于想得到一个非常快的客户。
尽管我喜欢写自己的自行车,但我感到非常高兴的是,我不仅可以节省时间,而且可以免费获得许多有用的功能。
我花了下午2点才能尝试连接终端,但我无法应付。 绝对是
不同的行高,弯曲的选择,终端的自适应大小,非常奇怪的API,缺乏理智的文档...
但是我仍然有一点启发,我相信我可以解决这些问题。
直到我将我的测试10k线喂给终端为止……他死了。 并把我的希望遗留下来。
最终算法的说明
首先,我复制了当前在python中实现的算法,并将其改编为javascript(只是删除了花括号,另一个删除了语法)。
我知道旧算法的所有主要优点和缺点,所以我只需要改善其中无效的地方。
经过深思熟虑,反复试验后,我决定使用以下选项:将算法分为2个部分:
- 文本和存储“终端”当前状态的模型
- 将模型转换为HTML的映射
模型(结构和算法)
- 所有行都存储在一个数组中(行号=数组中的索引)
- 文本样式存储在单独的数组中。
- 当前光标位置已存储,可以通过命令更改
- 该算法本身逐个字符地检查输入数据:
- 如果这只是文本,请添加到当前行
- 如果换行,则增加当前行索引
- 如果这是命令字符之一,那么我们将其放在命令缓冲区中,然后等待下一个字符
- 如果命令缓冲区正确,则运行此命令,否则我们将此缓冲区写为文本
- 该模型会在传入文本处理后通知侦听器有关哪些行已更改的信息
在我的实现中,算法的复杂度为O( n log n ),其中log n是准备更改的行以进行通知(唯一性和排序)。 在撰写本文时,我意识到,在特殊情况下,您可以摆脱log n ,因为通常将行添加到末尾。
展示架
- 将文本显示为HTML元素
- 如果字符串已更改,请完全替换字符串的所有元素
- 根据样式中断每一行:每个风格化的细分都有自己的元素
通过这样的结构,测试是一个相当简单的任务-我们将文本传输到模型中(以单个包或部件的形式),并仅检查其中所有线条和样式的当前状态。 并且只显示一些测试,因为 它总是重新绘制更改的线条。
一个重要的优点是显示器的一定惰性。 如果在一段文本中我们覆盖了同一行(例如进度条),那么在模型工作后,为了显示,它看起来就像是一条更改过的行。
DOM与画布
尽管目标是性能,但我想介绍为什么选择DOM。 答案很简单-懒惰。 对我来说,独自在Canvas中渲染所有内容似乎是一项艰巨的任务。 在保持可用性的同时:突出显示,复制,调整屏幕大小,看起来整洁等。 xterm.js示例清楚地向我表明,这一点都不容易。 他们在画布上的渲染远非理想。
另外,在浏览器中调试DOM树和覆盖单元测试的能力是一个重要的优势。
最后,我的目标是5万行,并且我知道DOM必须根据旧算法的工作来解决这一问题。
最佳化
该算法已准备就绪,已调试,并且运行缓慢但确实有效。 是时候打开分析器并进行优化了。 展望未来,我会说大多数优化对我来说都是一个惊喜(通常会发生这种情况)。
对10k行进行分析,每行包含样式化元素。 DOM元素的总数约为100k。
没有使用特殊的方法和工具。 仅Chrome开发工具和每次测量的几次启动。 实际上,在发射中,仅测量的绝对值(完成多少秒)有所不同,而方法之间的百分比没有差异。 因此,我认为该技术有条件地足够。
下面,我将更详细地介绍最有趣的改进。 对于初学者来说,这是一个图形:

所有性能分析图形都是在实现后通过从内存中优化代码来构建的。
字符串
首先,我遇到了一个难以理解的string.trim,它消耗了非常可观的CPU数量(在我看来,这大约是10-20%)

trim()是语言的基本功能。 为什么使用某种库? 即使是某种形式的polyfill,为什么还要打开最新版本的chrome?
进行一些谷歌搜索并找到答案: https : //babeljs.io/docs/en/babel-preset-env 。 默认情况下,它为相当多的浏览器启用polyfill,并在编译阶段执行此操作。 我的解决方案是指定'targets': '> 0.25%, not dead'
但是最后,由于不必要,我完全删除了trim调用。
Vue.js
去年,我将终端组件转移到了Vue.js。 现在,我不得不将其传输回Vanilla,原因在下面的屏幕截图中(请参阅涉及Vue.js的行数):
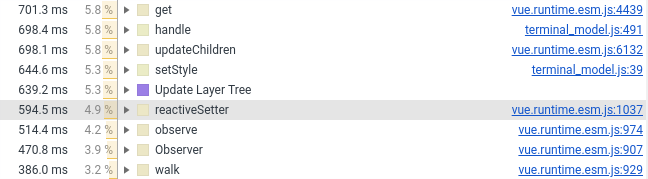
我在Vue组件中只保留了包装,样式和鼠标处理。 与创建DOM元素相关的所有内容都放入纯JS,它作为普通字段(不受框架监视)连接到Vue组件。
created() { this.terminalModel = new TerminalModel(); this.terminal = new Terminal(this.terminalModel); },
我不认为这是Vue.js的缺点或缺陷。 只是框架和性能本身不能很好地融合在一起。 好吧,当您将成千上万个对象放到反应式框架中时,很难期望在几毫秒内就可以对其进行处理。 老实说,我甚至对Vue.js表现出色感到惊讶。
新增项目
这里的一切都很简单-如果您有数千个新元素,并且想要将它们添加到父组件中,那么执行appendChild并不是一个好主意。 浏览器必须多做一点处理,并花费更多时间进行渲染。 在我的案例中,副作用之一是自动滚动速度变慢,因为 它强制重新计算所有添加的组件。

为了解决该问题,有一个DocumentFragment。 首先,将所有元素添加到其中,然后将其添加到父组件中。 浏览器将处理内联的传入组件。
这种方法减少了浏览器花在渲染和安排元素上的时间。
我还尝试了其他方法来加快添加项目的速度。 他们都无法在DocumentFragment之上添加任何内容。
跨度与div
实际上,这可以称为display:inline (span)vs display:block (div)。
最初,我跨度中的每一行都以换行符结束。 但是,就性能而言,这不是很有效:浏览器必须找出元素开始和结束的位置。 使用display:块,这样的计算要简单得多。
替换div可以将渲染速度提高近2倍。
不幸的是,在display:block的情况下display:block突出显示多行文本看起来更糟:

很长时间以来,我无法确定哪个更好-额外的2秒钟渲染或人工选择。 结果,实用性击败了美丽。
10级CSS向导
另外约10%的渲染时间被CSS“优化”所截断,我使用它来格式化文本。
网站开发经验不足以及对基本知识的理解对我不利。 我认为选择器越准确越好,但是就我而言,情况并非如此。
为了格式化终端中的文本,我使用了以下选择器:
#script-panel-container .log-content > div > span.text_color_green,
但是(在Chrome中),以下选项要快一些:
span.text_color_green
我不太喜欢这个选择器,因为 太全球化了,但是性能更昂贵。
string.split
如果您由于前面的观点之一而受到拒绝,则为假。 这次不是关于polyfill,而是关于chrome中的标准实现:

(我在defSplit中包装了string.split,以便该功能显示在探查器中)
1%是琐事。 但是我心中的理想主义者却被困扰。 就我而言,拆分总是一次只完成一个字符,而没有任何常规。 因此,我实现了一个简单的选项。 结果如下:

快速拆分 function fastSplit(str, separatorChar) { if (str === '') { return ['']; } let result = []; let lastIndex = 0; for (let i = 0; i < str.length; i++) { const char = str[i]; if (char === separatorChar) { const chunk = str.substr(lastIndex, i - lastIndex); lastIndex = i + 1; result.push(chunk); } } if (lastIndex < str.length) { const lastChunk = str.substr(lastIndex, str.length - lastIndex); result.push(lastChunk); } return result; }
我相信在此之后,他们必须不带采访就带我去Google Chrome团队。
优化,后记
优化是一个没有止境的过程,可以无限地改进某些东西。 特别是考虑到不同的用例需要不同的(和相互冲突的)优化。
对于我的情况,我选择了主要用例并将其运行时间从15秒优化为5秒。 我决定停下来。

我还计划改善几个地方,但这要归功于所获得的经验。
红利 变异测试。
碰巧的是,在过去的几个月中,我经常碰到“突变测试”这个词。 而且我认为这项任务是尝试这种野兽的好方法。 特别是在我没有在Webstorm中获得代码覆盖率之后,无法进行业力测试。
由于技术和库对我来说都是新手,所以我决定稍加努力:只测试一个组件-模型。 在这种情况下,您可以清楚地指出我们正在测试哪个文件,以及打算使用哪个测试套件。
但是无论怎么说,我都必须花很多时间才能实现与业力和Webpack的集成。
最终,一切开始了,半小时后,我看到了可悲的结果:大约一半的突变体得以幸存。 我立即杀死了一部分,留给了将来的一部分(当我实现丢失的ANSI命令时)。
此后,懒惰获胜,目前结果如下(对于128个测试):
Ran 79.04 tests per mutant on average. ------------------|---------|----------|-----------|------------|---------| File | % score | # killed | # timeout | # survived | # error | ------------------|---------|----------|-----------|------------|---------| terminal_model.js | 73.10 | 312 | 25 | 124 | 1 | ------------------|---------|----------|-----------|------------|---------| 23:01:08 (18212) INFO Stryker Done in 26 minutes 32 seconds.
总的来说,这种方法对我来说非常有用(显然比代码覆盖范围要好)并且很有趣。 唯一的缺点是时间太长-每堂课30分钟太长了。
最重要的是,这种方法使我再次考虑了100%的覆盖率以及是否值得通过测试来覆盖所有内容:现在,在回答这个问题时,我的观点甚至接近“是”。
结论
在我看来,性能优化是学习更多知识的好方法。 这对大脑也是很好的锻炼。 非常不幸的是,很少真正需要这样做(至少在我的项目中如此)。
与往常一样,“先分析然后优化”的方法要比直觉好得多。
参考文献
旧的实现:
新的实现:
不幸的是,没有Web组件演示,因此您将无法戳它。 所以我先道歉
谢谢您的宝贵时间,我将很乐意提出意见,建议和合理的批评!