大家好

我不了解您,但我一直想逆转旧的主机游戏,并且还有一个反编译器。 而现在,我生命中这个快乐的时刻已经来到-GHIDRA已经出来。 我不会写这是什么,您可以轻松地用Google搜索。 而且,评论是如此不同(尤其是逆行),以至于新人甚至都难以决定要创造这个奇迹……这是给你的一个例子:“ 我为创意工作了20年,由于NSA,我非常不信任地看着你的九头蛇,但是当……我将运行它并在实践中进行检查 。“
简而言之-运行Hydra并不可怕。 发行后我们将获得的收益将消除您对无处不在的NSA书签和后门的恐惧。
所以,我在说什么...有这样的前缀: Sony Playstation 1 ( PS1 , PSX , 冰壶 )。 为此创造了许多很酷的游戏,出现了许多特许经营权,这些特许权仍然很受欢迎。 有一天,我想弄清楚它们是如何工作的:有什么数据格式,是否使用了资源压缩,请尝试将某些内容翻译成俄语(我会马上说我还没有翻译任何游戏)。
我首先编写了一个很酷的实用程序,用于与Delphi上的一个朋友一起使用TIM格式(类似于Playstation世界中的BMP ): Tim2View 。 一次享受成功(也许现在享受)。 然后我想更深入地进行压缩。
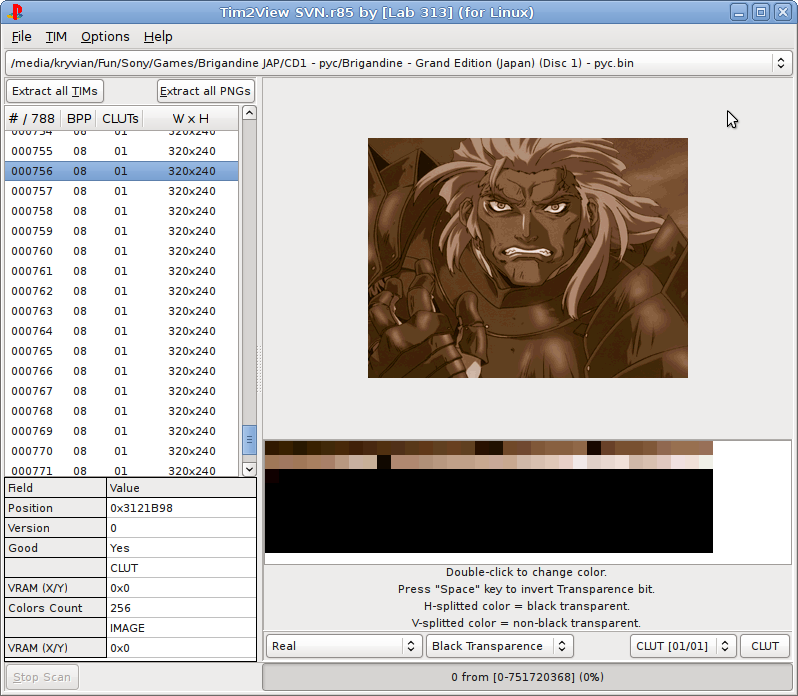
然后问题开始了。 那时我还不熟悉MIPS 。 学习了。 我也不熟悉IDA Pro (我后来在Playstation在Sega Mega Drive上玩反向游戏)。 但是,由于有了Internet,我发现IDA Pro支持下载和分析PS1 : PS-X EXE可执行文件 。 我试图上传一个游戏文件(似乎是Lemmings ),其名称和扩展名很奇怪,例如Ida的SLUS_123.45 ,我得到了一堆汇编代码(幸运的是,由于Windows exe驱动程序支持,我已经知道了它的含义) x86),并开始了解。
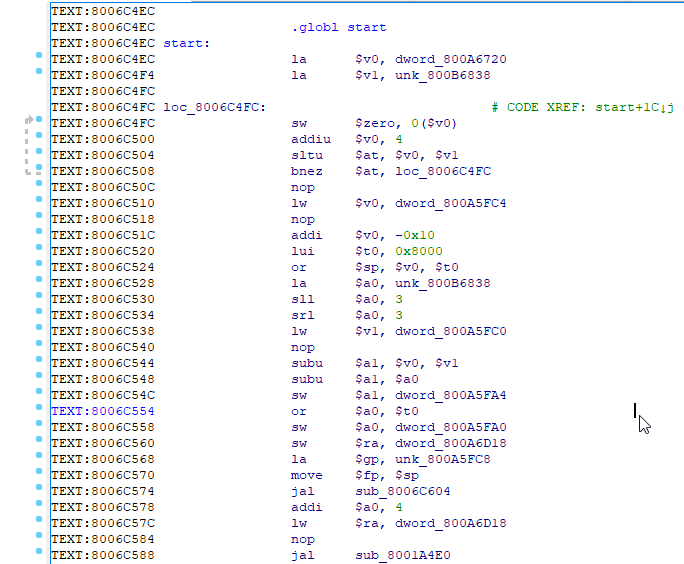
第一个难以理解的地方是组装线。 例如,您看到对某个函数的调用,并且在该函数加载到寄存器后,立即应使用该函数中的参数。 简而言之,在执行任何跳转和函数调用之前,首先执行跳转/调用之后的指令,然后才执行调用或跳转本身。
在经历了所有困难之后,我设法编写了一些游戏资源的打包程序/拆包程序。 但是我从来没有真正学习过代码。 怎么了 好吧,一切都是平庸的:有很多代码,几乎无法理解的BIOS和功能访问权限(它们是库,那时我没有用于卷曲的SDK),同时使用三个寄存器的指令,缺少反编译器。
因此,经过很多年, GHIDRA诞生GHIDRA 。 反编译器支持的平台包括MIPS 。 哦,快乐! 让我们尝试尽快反编译! 但是...我在等一个无赖。 Hydra不支持PS-X EXE 。 没问题,我们会自己写的!
实际上是代码
足够的抒情离题,让我们编写代码。 如何为Ghidra创建自己的下载Ghidra ,我已经对我之前写的内容有所了解。 因此,仅需查找第一个卷发钳的内存映射,寄存器的地址,就可以收集和加载二进制文件。 言归正传。
代码已准备就绪,已添加并识别了寄存器和区域,但是在调用库函数和BIOS函数的地方仍然存在很大空白。 而且,不幸的是,Hydra没有FLIRT支持。 如果没有,让我们添加。
FLIRT签名的格式是已知的,并在pat.txt文件中进行了描述,该文件可在Ida SDK中找到。 Ida还具有专门用于从Playstation库文件创建这些签名的实用程序,称为ppsx 。 我下载了名为PsyQ Playstation Development Kit的PsyQ Playstation Development Kit SDK,在其中找到了lib文件,并尝试从中创建至少一些签名-成功。 结果是一些小文本,其中每一行都有特定的格式。 仍然需要编写将解析这些行并将其应用于代码的代码。
帕帕瑟
由于每一行都有特定的格式,因此编写正则表达式是合乎逻辑的。 原来是这样的:
private static final Pattern linePat = Pattern.compile("^((?:[0-9A-F\\.]{2})+) ([0-9A-F]{2}) ([0-9A-F]{4}) ([0-9A-F]{4}) ((?:[:\\^][0-9A-F]{4}@? [\\.\\w]+ )+)((?:[0-9A-F\\.]{2})+)?$");
好吧,为了突出显示模块偏移量,类型和函数名称,我们编写了一个单独的regexp:
private static final Pattern modulePat = Pattern.compile("([:\\^][0-9A-F]{4}@?) ([\\.\\w]+) ");
现在,让我们分别浏览每个签名的组件:
- 首先是十六进制字节序列( 0-9A-F ),其中一些字节可以是任意字节(点字符“。”)。 因此,我们创建了一个将存储此类序列的类。 我称它为
MaskedBytes :
MaskedBytes.java package pat; public class MaskedBytes { private final byte[] bytes, masks; public final byte[] getBytes() { return bytes; } public final byte[] getMasks() { return masks; } public final int getLength() { return bytes.length; } public MaskedBytes(byte[] bytes, byte[] masks) { this.bytes = bytes; this.masks = masks; } public static MaskedBytes extend(MaskedBytes src, MaskedBytes add) { return extend(src, add.getBytes(), add.getMasks()); } public static MaskedBytes extend(MaskedBytes src, byte[] addBytes, byte[] addMasks) { int length = src.getBytes().length; byte[] tmpBytes = new byte[length + addBytes.length]; byte[] tmpMasks = new byte[length + addMasks.length]; System.arraycopy(src.getBytes(), 0, tmpBytes, 0, length); System.arraycopy(addBytes, 0, tmpBytes, length, addBytes.length); System.arraycopy(src.getMasks(), 0, tmpMasks, 0, length); System.arraycopy(addMasks, 0, tmpMasks, length, addMasks.length); return new MaskedBytes(tmpBytes, tmpMasks); } }
- 从其计算
CRC16的块的长度。 CRC16 ,使用自己的多项式( 0x8408 ):
计数码CRC16 public static boolean checkCrc16(byte[] bytes, short resCrc) { if ( bytes.length == 0 ) return true; int crc = 0xFFFF; for (int i = 0; i < bytes.length; ++i) { int a = bytes[i]; for (int x = 0; x < 8; ++x) { if (((crc ^ a) & 1) != 0) { crc = (crc >> 1) ^ 0x8408; } else { crc >>= 1; } a >>= 1; } } crc = ~crc; int x = crc; crc = (crc << 8) | ((x >> 8) & 0xFF); crc &= 0xFFFF; return (short)crc == resCrc; }
- “模块”的总长度,以字节为单位。
- 全局名称列表(我们需要什么)。
- 其他名称的链接列表(也需要)。
- 尾字节。
模块中的每个名称都有特定的类型和相对于开头的偏移量。 可以通过以下字符之一来表示类型::,^,@,具体取决于类型:
- “ :NAME ”:全局名称。 出于这样的名字,我开始了一切。
- “ :NAME @ ”:本地名称/标签。 它可能没有显示,但请注意;
- “ ^ NAME ”:链接到名称。
一方面,一切都很简单,但是链接很容易不是对函数的引用(因此,跳转是相对的),而是对全局变量的引用。 您说的是什么问题? 就是在PSX中,您无法通过一条指令将整个DWORD推送到寄存器中。 为此,请以两半的形式下载。 事实是,在MIPS指令大小限制为四个字节。 而且,看来,您只需要首先从一条指令中减去一半,然后反汇编下一条即可,然后再获得另一半。 但不是那么简单。 可以将指令5的前半部分加载回去,并且仅在加载后半部分后才能给出模块中的链接。 我不得不编写一个复杂的解析器(可能可以修改)。
结果,我们为三种类型的名称创建enum :
ModuleType.java package pat; public enum ModuleType { GLOBAL_NAME, LOCAL_NAME, REF_NAME; public boolean isGlobal() { return this == GLOBAL_NAME; } public boolean isLocal() { return this == LOCAL_NAME; } public boolean isReference() { return this == REF_NAME; } @Override public String toString() { if (isGlobal()) { return "Global"; } else if (isLocal()) { return "Local"; } else { return "Reference"; } } }
让我们写一个代码,将文本十六进制序列和点转换为MaskedBytes类型:
hexStringToMaskedBytesArray() private MaskedBytes hexStringToMaskedBytesArray(String s) { MaskedBytes res = null; if (s != null) { int len = s.length(); byte[] bytes = new byte[len / 2]; byte[] masks = new byte[len / 2]; for (int i = 0; i < len; i += 2) { char c1 = s.charAt(i); char c2 = s.charAt(i + 1); masks[i / 2] = (byte) ( (((c1 == '.') ? 0x0 : 0xF) << 4) | (((c2 == '.') ? 0x0 : 0xF) << 0) ); bytes[i / 2] = (byte) ( (((c1 == '.') ? 0x0 : Character.digit(c1, 16)) << 4) | (((c2 == '.') ? 0x0 : Character.digit(c2, 16)) << 0) ); } res = new MaskedBytes(bytes, masks); } return res; }
您已经可以想到一个类,该类将存储有关每个单独函数的信息:函数名称,模块中的偏移量以及类型:
ModuleData.java package pat; public class ModuleData { private final long offset; private final String name; private final ModuleType type; public ModuleData(long offset, String name, ModuleType type) { this.offset = offset; this.name = name; this.type = type; } public final long getOffset() { return offset; } public final String getName() { return name; } public final ModuleType getType() { return type; } }
最后,一个类,它将存储pat文件每一行上指示的所有内容,即:bytes,crc,带有偏移量的名称列表:
SignatureData.java package pat; import java.util.Arrays; import java.util.List; public class SignatureData { private final MaskedBytes templateBytes, tailBytes; private MaskedBytes fullBytes; private final int crc16Length; private final short crc16; private final int moduleLength; private final List<ModuleData> modules; public SignatureData(MaskedBytes templateBytes, int crc16Length, short crc16, int moduleLength, List<ModuleData> modules, MaskedBytes tailBytes) { this.templateBytes = this.fullBytes = templateBytes; this.crc16Length = crc16Length; this.crc16 = crc16; this.moduleLength = moduleLength; this.modules = modules; this.tailBytes = tailBytes; if (this.tailBytes != null) { int addLength = moduleLength - templateBytes.getLength() - tailBytes.getLength(); byte[] addBytes = new byte[addLength]; byte[] addMasks = new byte[addLength]; Arrays.fill(addBytes, (byte)0x00); Arrays.fill(addMasks, (byte)0x00); this.fullBytes = MaskedBytes.extend(this.templateBytes, addBytes, addMasks); this.fullBytes = MaskedBytes.extend(this.fullBytes, tailBytes); } } public MaskedBytes getTemplateBytes() { return templateBytes; } public MaskedBytes getTailBytes() { return tailBytes; } public MaskedBytes getFullBytes() { return fullBytes; } public int getCrc16Length() { return crc16Length; } public short getCrc16() { return crc16; } public int getModuleLength() { return moduleLength; } public List<ModuleData> getModules() { return modules; } }
现在最主要的是:我们编写代码来创建所有这些类:
解析pat文件的一行 private List<ModuleData> parseModuleData(String s) { List<ModuleData> res = new ArrayList<ModuleData>(); if (s != null) { Matcher m = modulePat.matcher(s); while (m.find()) { String __offset = m.group(1); ModuleType type = __offset.startsWith(":") ? ModuleType.GLOBAL_NAME : ModuleType.REF_NAME; type = (type == ModuleType.GLOBAL_NAME && __offset.endsWith("@")) ? ModuleType.LOCAL_NAME : type; String _offset = __offset.replaceAll("[:^@]", ""); long offset = Integer.parseInt(_offset, 16); String name = m.group(2); res.add(new ModuleData(offset, name, type)); } } return res; }
解析所有拍拍文件行 private void parse(List<String> lines) { modulesCount = 0L; signatures = new ArrayList<SignatureData>(); int linesCount = lines.size(); monitor.initialize(linesCount); monitor.setMessage("Reading signatures..."); for (int i = 0; i < linesCount; ++i) { String line = lines.get(i); Matcher m = linePat.matcher(line); if (m.matches()) { MaskedBytes pp = hexStringToMaskedBytesArray(m.group(1)); int ll = Integer.parseInt(m.group(2), 16); short ssss = (short)Integer.parseInt(m.group(3), 16); int llll = Integer.parseInt(m.group(4), 16); List<ModuleData> modules = parseModuleData(m.group(5)); MaskedBytes tail = null; if (m.group(6) != null) { tail = hexStringToMaskedBytesArray(m.group(6)); } signatures.add(new SignatureData(pp, ll, ssss, llll, modules, tail)); modulesCount += modules.size(); } monitor.incrementProgress(1); } }
用于创建识别签名之一的函数的代码:
功能创造 private static void disasmInstruction(Program program, Address address) { DisassembleCommand cmd = new DisassembleCommand(address, null, true); cmd.applyTo(program, TaskMonitor.DUMMY); } public static void setFunction(Program program, FlatProgramAPI fpa, Address address, String name, boolean isFunction, boolean isEntryPoint, MessageLog log) { try { if (fpa.getInstructionAt(address) == null) disasmInstruction(program, address); if (isFunction) { fpa.createFunction(address, name); } if (isEntryPoint) { fpa.addEntryPoint(address); } if (isFunction && program.getSymbolTable().hasSymbol(address)) { return; } program.getSymbolTable().createLabel(address, name, SourceType.IMPORTED); } catch (InvalidInputException e) { log.appendException(e); } }
如前所述,最困难的地方是计算到另一个名称/变量的链接(也许代码需要改进):
链接数 public static void setInstrRefName(Program program, FlatProgramAPI fpa, PseudoDisassembler ps, Address address, String name, MessageLog log) { ReferenceManager refsMgr = program.getReferenceManager(); Reference[] refs = refsMgr.getReferencesFrom(address); if (refs.length == 0) { disasmInstruction(program, address); refs = refsMgr.getReferencesFrom(address); if (refs.length == 0) { refs = refsMgr.getReferencesFrom(address.add(4)); if (refs.length == 0) { refs = refsMgr.getFlowReferencesFrom(address.add(4)); Instruction instr = program.getListing().getInstructionAt(address.add(4)); if (instr == null) { disasmInstruction(program, address.add(4)); instr = program.getListing().getInstructionAt(address.add(4)); if (instr == null) { return; } } FlowType flowType = instr.getFlowType(); if (refs.length == 0 && !(flowType.isJump() || flowType.isCall() || flowType.isTerminal())) { return; } refs = refsMgr.getReferencesFrom(address.add(8)); if (refs.length == 0) { return; } } } } try { program.getSymbolTable().createLabel(refs[0].getToAddress(), name, SourceType.IMPORTED); } catch (InvalidInputException e) { log.appendException(e); } }
并且,最后的修饰-应用签名:
applySignatures() public void applySignatures(ByteProvider provider, Program program, Address imageBase, Address startAddr, Address endAddr, MessageLog log) throws IOException { BinaryReader reader = new BinaryReader(provider, false); PseudoDisassembler ps = new PseudoDisassembler(program); FlatProgramAPI fpa = new FlatProgramAPI(program); monitor.initialize(getAllModulesCount()); monitor.setMessage("Applying signatures..."); for (SignatureData sig : signatures) { MaskedBytes fullBytes = sig.getFullBytes(); MaskedBytes tmpl = sig.getTemplateBytes(); Address addr = program.getMemory().findBytes(startAddr, endAddr, fullBytes.getBytes(), fullBytes.getMasks(), true, TaskMonitor.DUMMY); if (addr == null) { monitor.incrementProgress(sig.getModules().size()); continue; } addr = addr.subtract(imageBase.getOffset()); byte[] nextBytes = reader.readByteArray(addr.getOffset() + tmpl.getLength(), sig.getCrc16Length()); if (!PatParser.checkCrc16(nextBytes, sig.getCrc16())) { monitor.incrementProgress(sig.getModules().size()); continue; } addr = addr.add(imageBase.getOffset()); List<ModuleData> modules = sig.getModules(); for (ModuleData data : modules) { Address _addr = addr.add(data.getOffset()); if (data.getType().isGlobal()) { setFunction(program, fpa, _addr, data.getName(), data.getType().isGlobal(), false, log); } monitor.setMessage(String.format("%s function %s at 0x%08X", data.getType(), data.getName(), _addr.getOffset())); monitor.incrementProgress(1); } for (ModuleData data : modules) { Address _addr = addr.add(data.getOffset()); if (data.getType().isReference()) { setInstrRefName(program, fpa, ps, _addr, data.getName(), log); } monitor.setMessage(String.format("%s function %s at 0x%08X", data.getType(), data.getName(), _addr.getOffset())); monitor.incrementProgress(1); } } }
在这里,您可以讨论一个有趣的功能: findBytes() 。 使用它,您可以搜索特定的字节序列,并为每个字节指定位掩码。 该方法的调用方式如下:
Address addr = program.getMemory().findBytes(startAddr, endAddr, bytes, masks, forward, TaskMonitor.DUMMY);
结果,返回从其开始字节的地址,或者返回null 。
编写分析器
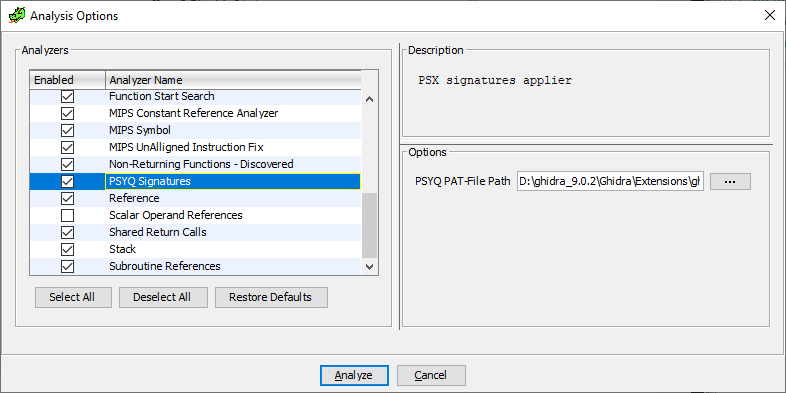
让我们做的漂亮,如果我们不想使用签名,请让用户选择此步骤。 为此,您需要编写自己的代码分析器(您可以在此列表中看到它们-就是这些,是的):
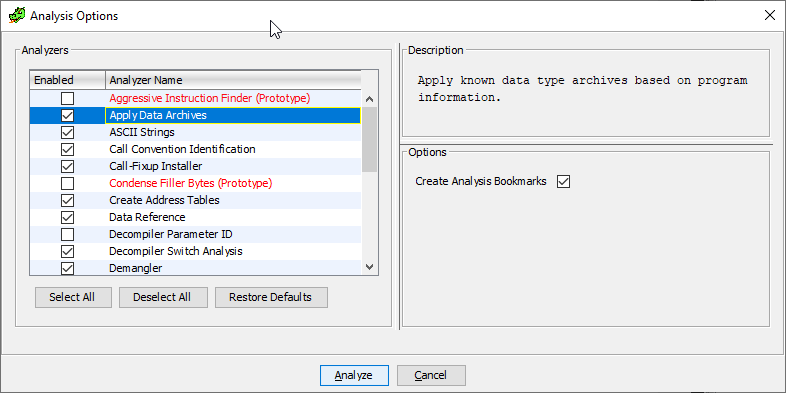
因此,要进入此列表,您将需要继承AbstractAnalyzer类并重写一些方法:
- 构造函数。 它将必须使用名称,分析器的描述及其类型来调用基类的构造函数(稍后将对此进行详细介绍)。 在我看来是这样的:
public PsxAnalyzer() { super("PSYQ Signatures", "PSX signatures applier", AnalyzerType.INSTRUCTION_ANALYZER); }
getDefaultEnablement() 。 确定我们的分析仪是否始终可用,或者仅在满足某些条件(例如,使用我们的装载机)时才可用。canAnalyze() 。 是否可以在可下载的二进制文件上使用此分析仪?
原则上,第2和第3款可以通过一个功能来验证:
public static boolean isPsxLoader(Program program) { return program.getExecutableFormat().equalsIgnoreCase(PsxLoader.PSX_LOADER); }
PsxLoader.PSX_LOADER在其中存储引导加载程序的名称,并在其中进行了定义。
总计,我们有:
@Override public boolean getDefaultEnablement(Program program) { return isPsxLoader(program); } @Override public boolean canAnalyze(Program program) { return isPsxLoader(program); }
registerOptions() 。 完全没有必要重新定义此方法,但是如果我们需要向用户询问一些信息(例如,分析之前pat文件的路径),则最好在此方法中执行此操作。 我们得到:
private static final String OPTION_NAME = "PSYQ PAT-File Path"; private File file = null; @Override public void registerOptions(Options options, Program program) { try { file = Application.getModuleDataFile("psyq4_7.pat").getFile(false); } catch (FileNotFoundException e) { } options.registerOption(OPTION_NAME, OptionType.FILE_TYPE, file, null, "PAT-File (FLAIR) created from PSYQ library files"); }
这里有必要澄清。 Application类的静态方法getModuleDataFile()返回data目录中文件的完整路径,该目录位于我们模块的树中,并且可以存储以后要引用的所有必需文件。
好了, registerOption()方法registerOption()一个选项,该选项具有在OPTION_NAME指定的名称,类型File (即,用户将能够通过常规对话框选择文件),默认值和描述。
下一个 因为 我们以后通常没有机会参考已注册的选项,我们需要重新定义optionsChanged()方法:
@Override public void optionsChanged(Options options, Program program) { super.optionsChanged(options, program); file = options.getFile(OPTION_NAME, file); }
在这里,我们仅根据新值更新全局变量。
added()方法。 现在最主要的是:分析器启动时将调用的方法。 在其中,我们将收到可用于分析的地址列表,但我们只需要包含代码的地址即可。 因此,您需要过滤。 最终代码:
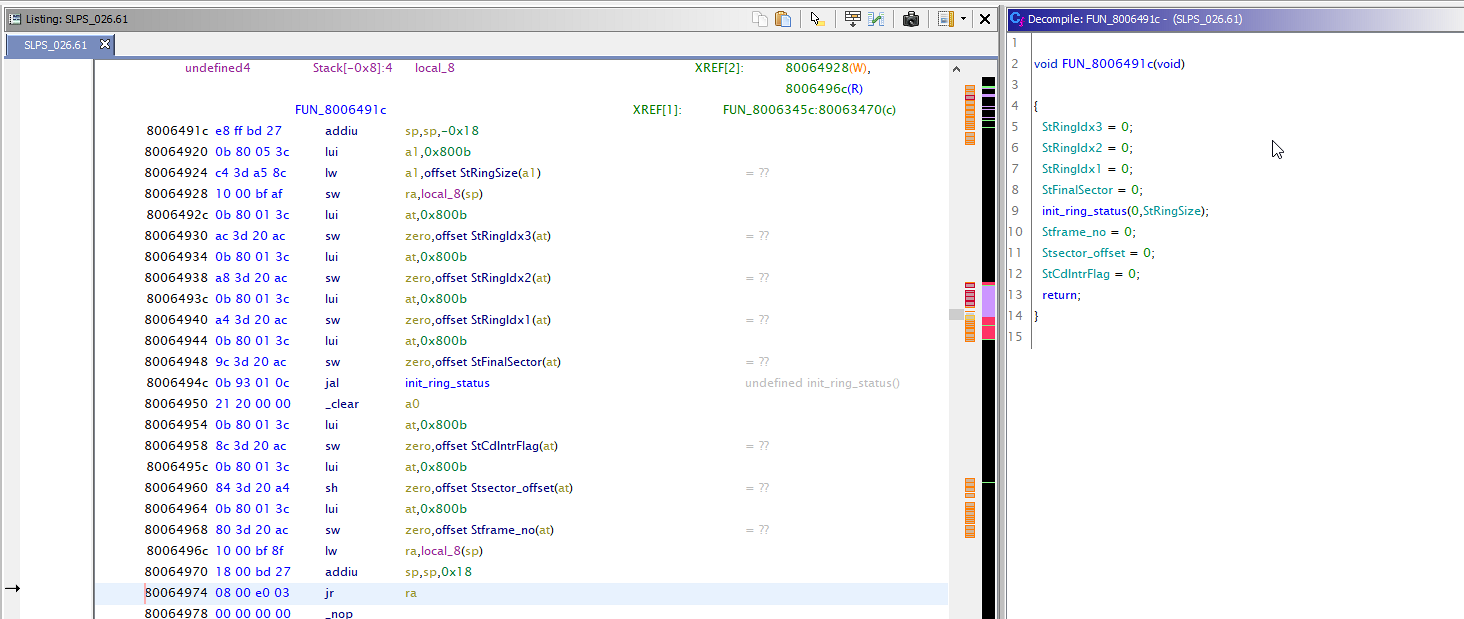
增加()方法 @Override public boolean added(Program program, AddressSetView set, TaskMonitor monitor, MessageLog log) throws CancelledException { if (file == null) { return true; } Memory memory = program.getMemory(); AddressRangeIterator it = memory.getLoadedAndInitializedAddressSet().getAddressRanges(); while (!monitor.isCancelled() && it.hasNext()) { AddressRange range = it.next(); try { MemoryBlock block = program.getMemory().getBlock(range.getMinAddress()); if (block.isInitialized() && block.isExecute() && block.isLoaded()) { PatParser pat = new PatParser(file, monitor); RandomAccessByteProvider provider = new RandomAccessByteProvider(new File(program.getExecutablePath())); pat.applySignatures(provider, program, block.getStart(), block.getStart(), block.getEnd(), log); } } catch (IOException e) { log.appendException(e); return false; } } return true; }
在这里,我们浏览了可执行地址的列表,并尝试在其中应用签名。
结论与结局
像一切。 实际上,这里没有什么超级复杂的。 有例子,社区是活跃的,您可以放心地询问编写代码时不清楚的地方。 底线:适用于Playstation 1可执行文件的引导加载程序和分析器。
所有源代码都在这里可用: ghidra_psx_ldr
在这里发布 : 发布