
SNA Hackathon 2019决赛于4月1日结束,其参与者竞争使用现代机器学习技术,计算机视觉,测试处理和推荐系统对社交网络供稿进行排序。 辛苦的在线选择和为160 GB的数据进行的两天的辛苦工作都是徒劳的:)。 我们将讨论如何帮助参与者取得成功以及其他有趣的观察结果。
关于数据和任务
比赛提供了来自OK社交网络用户准备供稿的机制中的数据,该机制包括三个部分:
- 内容显示登录到用户提要中,其中包含大量描述用户,内容,作者和其他属性的属性;
- 与显示内容有关的文本;
- 内容中使用的图像主体。
数据总量超过160 GB,其中3个以上用于日志,3个用于文本,其余用于图片。 大量数据并没有使参与者感到恐惧:根据ML Bootcamp的统计数据,有将近200人参加了比赛,发送了3,000多个参赛作品,而最活跃的参与者则突破了100个已发送解决方案的标准。 也许他们是受到700,000卢布+ 3枚GTX 2080 Ti显卡的奖池的激励。

比赛的参赛者需要解决对磁带进行排序的问题:对于每个用户,对显示的对象进行排序的方式应使获得“ Class!”标记的对象更接近列表的开头。
ROC-AUC被用作质量评估指标。 同时,该指标并未考虑所有数据的整体情况,而是针对每个用户单独考虑,然后取平均值。 此计算选项值得注意,因为已学会区分许多类用户的算法没有优势。 另一方面,标准Python包中没有这样的选项,它揭示了一些有趣的观点,下面将进行讨论。
关于技术
传统上,SNA Hackathon不仅是算法,而且还是技术-传送的数据量超过160 GB,这使参与者面临着有趣的技术任务。
实木复合地板与 中央电视台
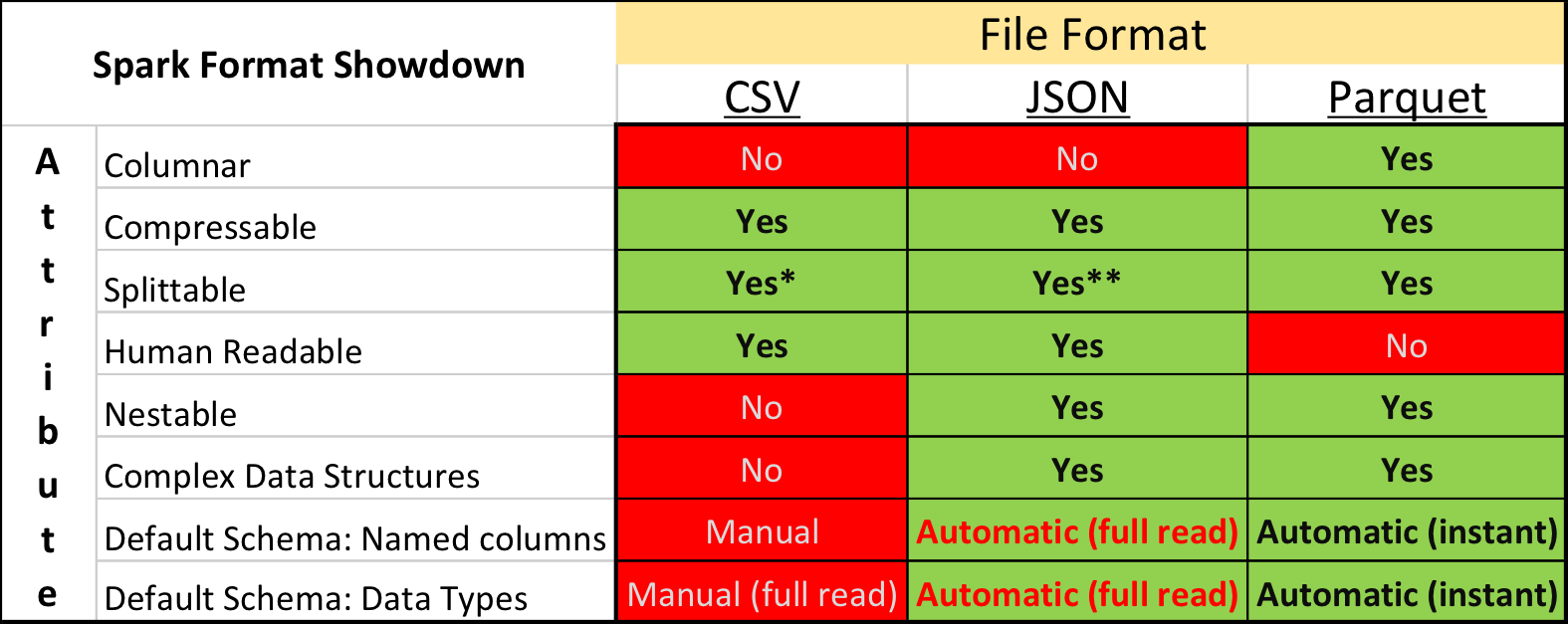
在学术研究和Kaggle中,主要数据格式是CSV以及其他纯文本格式。 但是,该行业的情况有所不同-使用“二进制”存储格式可以显着提高紧凑性和处理速度。
特别是,在基于Apache Spark构建的生态系统中, Apache Parquet是最受欢迎的-一种列数据存储格式,支持许多重要的操作功能:
- 具有演进支持的明确指定的电路;
- 只从磁盘读取必要的列;
- 阅读时对索引和过滤器的基本支持;
- 字符串压缩。
尽管有明显的优势,但以Apache Parquet格式提交比赛数据遭到了一些参赛者的严厉批评。 除了保守主义和不愿意花时间开发新事物外,还有一些非常不愉快的时刻。
首先,对Apache Arrow库中的格式的支持远非完美, Apache Arrow库是使用Python处理Parquet的主要工具。 在准备数据时,所有结构域都必须扩展为平坦的,而且,在阅读文本时,许多参与者仍然遇到错误,并被迫安装旧版本0.11.1库而不是当前版本0.12。 其次,您不会使用简单的控制台实用程序(cat,less等)查看Parquet文件。 然而,该缺点相对容易补偿使用镶木地板工具包装。
但是,最初尝试将所有数据转换为CSV,然后在熟悉的环境中工作的人们最终放弃了这个想法-毕竟,Parquet的工作速度明显更快。
加速和GPU

在圣彼得堡的SmartData会议上,“狭窄的圈子广为人知”,Alexey Natekin在研究CPU / GPU时比较了几种流行的增强工具的性能,得出的结论是GPU并没有带来明显的收益。 但是即使到了那时,这个结论仍然引起了激烈的争论,主要是与家用CatBoost工具的开发者发生了 冲突 。
在过去的两年中,GPU的发展和算法的适应性并没有停止,SNA Hackathon决赛可被视为CatBoost + GPU对的胜利-所有获奖者都使用了它并取消了该指标,主要是因为每单位时间可以种植更多树木的能力。
均值目标编码的集成实现也为基于CatBoost的解决方案取得了很高的成就,但是树的数量和深度却增加了更多。
其他增强工具也朝着相似的方向发展,增加并改善了对GPU的支持。 所以种更多的树!
火花与 皮斯帕克

Apache Spark工具在工业数据科学领域处于领先地位,这在一定程度上要归功于Python API。 但是,使用Python会带来额外的开销,需要在不同的运行时和解释器工作之间进行集成。
如果用户知道额外费用的数量在多大程度上导致了特定的操作,那么这本身就不是问题。 然而,事实证明,尽管参与者没有使用Apache Spark,但仍有许多人没有意识到问题的严重性。 Scala经常出现在黑客马拉松聊天中,从而导致出现相应的已解析帖子 。
简而言之,与通过Scala / Java使用Spark相比,通过Python使用Spark的速度下降可分为以下几类:
- 仅使用Spark SQL API而不使用用户定义函数(UDF)-在这种情况下,实际上没有任何开销,因为整个查询执行计划都是在JVM框架内计算的;
- 在Python中使用UDF而不用C ++代码调用软件包-在这种情况下,计算UDF的阶段的性能下降了7到10倍 ;
- 在Python中使用UDF可以访问C ++包(numpy,sklearn等)-在这种情况下,性能下降10到50倍 。
使用PyPy (适用于Python的JIT)和矢量化UDF可以部分抵消负面影响,但是,即使在这些情况下,性能差异也是多种多样的,并且实现和部署的复杂性带有额外的“好处”。
关于算法
但是,关于数据科学黑客马拉松的最有趣的事情当然不是技术,而是新的和经过验证的新算法。 今年,CatBoost主导了SNA Hackathon,但是有几种替代方法。 我们将讨论它们:)。
可微图

基于资格赛结果的决策的第一批出版物之一不是专门针对树木,而是可微图(也称为人工神经网络)。 作者是OK的雇员,因此他负担不起追逐奖金,而是喜欢在扎实的数学基础上构建有希望的解决方案。
提出的解决方案的主要思想是构建单个计算可微图,该图将可用功能转换为预测,并考虑输入数据的各个方面:
- 对象和用户联合允许您添加经典协作推荐的元素;
- 通过标量嵌入从标量嵌入到聚合的过渡,使您可以添加任意特征;
- query-key-value的关注使该模型能够动态地适应甚至以前不熟悉的用户查看其最近历史的行为。
事实证明,此模型非常适合在线选择,可以解决推荐文本内容的问题,因此,数支球队尝试在决赛中同时播放,但没有成功。 这部分是由于这需要时间和经验,另一部分是由于决赛中的属性数量大得多,并且基于树的方法因此获得了明显的优势。
合作主导

当然,在组织比赛时,我们知道日志中有一个相当强烈的信号,因为在那里收集的标志反映了OK进行的对Feed进行排名的大部分工作。 但是,直到最后,他们希望参与者能够成功应对“第三字符诅咒”。在这种情况下,与开发已经从现有内容(文本和图片)中提取属性的模型相比,投入大量人力和机器资源导致质量获得的收益非常适度准备好的(主要是协作的)特征。
知道了这个问题后,我们在排位赛中将任务最初分为三个阶段,并仅在最后阶段形成了组合数据集,但是在采用固定指标的hackathon格式下,与开发协作模型的团队相比,投资内容模型开发的团队故意陷入了失败部分。
陪审团奖帮助弥补了这种不公正现象。
深层集群

这是因为Facebook再现和测试Deep Cluster算法的工作几乎获得一致认可。 创建簇和图像嵌入的简单且不需要初始标记的方法给新颖的想法和有希望的结果留下了深刻的印象。
该方法的本质非常简单:
- 使用任何有意义的神经网络计算图像的嵌入向量;
- 用k均值将向量聚类在结果空间中;
- 训练神经网络分类器来预测图片集群;
- 重复步骤2-3,直到收敛(如果您有800个GPU)或有足够的时间。
通过最少的努力,我们设法获得了OK图像的高质量聚类,良好的嵌入效果以及三位数的度量增加。
展望未来

在任何数据中,您都可以找到“漏洞”来改善预测。 就其本身而言,这还算不错,如果发现漏洞并且很长一段时间仅以历史数据的验证结果与A / B测试之间的不可理解的差异的形式出现,那就更糟了。
这种漏洞最普遍的漏洞之一就是对未来信息的利用。 此类信息通常是非常强烈的信号,并且如果启用了机器学习算法,则将开始放心地使用它。 在为产品建立模型时,您正在尽一切可能避免将来的信息泄漏,但是在黑客马拉松上,这是一个提高参与者使用的指标的好机会。
最明显的漏洞是这些字段中存在numLikes和numDislikes,并且在显示时对象处的反应计数。 通过比较时间上最接近同一对象的两个事件,可以高精度确定在第一个事件中对对象的反应是什么。 数据中有几个类似的计数器,它们的使用提供了明显的优势。 自然,在实际使用中,此类信息将不可用。
在生活中,类似的问题可能在没有意识到的情况下偶然发现,通常会带来负面结果。 例如,统计标记“ Class!”的数量 根据所有数据获取对象,并将其作为单独的属性。 或者,就像他们在一个参与团队中所做的那样,将对象标识符作为分类属性添加到模型中。 在训练集上,具有这种功能的模型效果很好,但不能推广到测试集。
而不是结论

Mail.ru Cloud中提供了比赛的所有材料,包括参与者的决策数据和演示。 除链接的可用性外,数据可不受限制地供研究项目使用。 对于故事,让我们将决赛桌的指标留在这里,如下:
- 蹲下Scala,隐藏Python- 0.7422,解析解决方案可在此处找到 ,并且代码在此处和此处 。
- 魔术城-0.7256
- 开菲尔-0.7226
- 团队6-0.7205
- 三人同行-0.7188
- 14号馆-0.7167和评审团奖
- 贝兹纳-0.7147
- 庞加-0.7117
- 5队-0.7112
与该系列的先前活动一样,SNA Hackathon 2019在各个方面都是成功的。 我们设法聚集了来自各个领域的优秀专业人才,并度过了充实的时光,在此,我们要感谢参与者们自己以及所有为组织提供帮助的人。
能做得更好吗? 当然可以! 举办的每场比赛都为我们提供了新的经验,我们在准备下一场比赛时会考虑到这一点,并且不会就此止步。 因此,很快就会在SNA Hackathon上见!