通常,在神经网络领域尤其是模式识别领域的进步导致了这样一个事实,即创建用于处理图像的神经网络应用程序似乎是一项常规任务。 从某种意义上说,这是-如果您想到了与模式识别有关的想法,请不要怀疑有人已经写过类似的东西。 您所需要做的就是在Google中找到相应的代码,然后由作者“编译”。
但是,我想说,仍然有许多细节使这项任务不是像无聊一样难以解决。 这会花费太多时间,特别是如果您是一个需要领导才能,循序渐进,需要在您眼前进行并从头到尾完成的项目的初学者。 在这种情况下,如果没有通常的做法,“跳过这一明显的部分”就是借口。
在本文中,我们将考虑创建Dog Breed Identifier的任务:我们将创建和训练神经网络,然后将其移植到Android的Java并在Google Play上发布。
如果您想查看完成的结果,则为:Google Play上的
NeuroDog应用 。
使用我的机器人技术的网站(正在进行中):
robotics.snowcron.com 。
程序本身的网站,包括指南:
NeuroDog用户指南 。
这是该程序的屏幕截图:
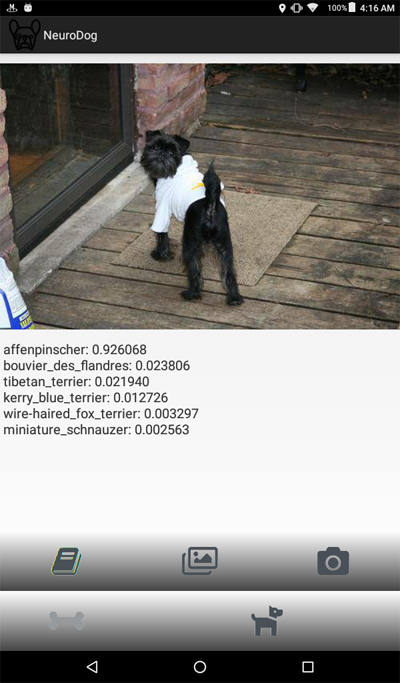
问题陈述
我们将使用Keras:一个用于处理神经网络的Google库。 这是一个高级库,这意味着与我所知道的替代方法相比,它更易于使用。 如果有的话-网络中有很多关于Keras的教科书,质量很高。
我们将使用CNN-卷积神经网络。 CNN(以及基于它们的更高级的配置)是图像识别中的事实上的标准。 同时,训练这样的网络并不总是那么容易:您需要选择正确的网络结构,训练参数(所有这些学习率,动量,L1和L2等)。 该任务需要大量的计算资源,因此,仅通过遍历所有参数来解决该问题将失败。
这是为什么在大多数情况下他们使用所谓的“转移知识”而不是所谓的“香草”方法的几个原因之一。 Transfer Knowlege使用由我们之前的人员(例如Google)训练的神经网络,通常用于完成类似但仍不同的任务。 我们从中获取初始层,用我们自己的分类器替换最终层-它可以工作,并且效果很好。
起初,这样的结果可能令人惊讶:我们如何接受训练有素的Google网络来区分猫和椅子,并为我们识别狗的品种? 要了解这是如何发生的,您需要了解深度神经网络工作的基本原理,包括用于模式识别的原理。
我们“喂食”网络一幅图片(即数字数组)作为输入。 第一层分析图像中的简单图案,例如“水平线”,“弧形”等。 下一层接收这些图案作为输入,并生成二阶图案,例如“毛发”,“眼角” ...最终,我们得到一个难题,可以用来重建狗:羊毛,两只眼睛和人的牙齿。
以上所有操作都是在我们(例如,从Google)获得的预训练图层的帮助下完成的。 接下来,我们添加我们的图层,并教他们从这些模式中提取品种信息。 听起来合乎逻辑。
总而言之,在本文中,我们将创建“原始” CNN和不同类型网络的多个“转移学习”变体。 至于“香草”:我会创建它,但我不打算通过选择参数来配置它,因为训练和配置“预训练”网络要容易得多。
由于我们计划教我们的神经网络识别狗的品种,因此我们必须“展示”各种品种的样本。 幸运的是,
这里为类似的任务创建了一组照片(
原始照片在
这里 )。
然后,我计划为android移植最好的接收网络。 将Kerasov网络移植到android相对简单,形式化,我们将做所有必要的步骤,因此重现这一部分将不难。
然后,我们将所有这些内容发布在Google Play上。 当然,Google会抗拒,因此将使用其他技巧。 例如,我们的应用程序的大小(由于庞大的神经网络)将大于Google Play接受的Android APK的允许大小:我们将不得不使用捆绑软件。 此外,Google不会在搜索结果中显示我们的应用程序,可以通过在应用程序中注册搜索标签来解决此问题,或者只需等待一两个星期。
结果,我们为Android和神经网络获得了功能齐全的“商业”(引号,因为它是免费提供的)应用程序。
开发环境
您可以采用不同的方式为Keras编程,具体取决于所使用的OS(建议使用Ubuntu),是否存在视频卡等等。 除了不是最简单的方法之外,在本地计算机上进行开发(并因此进行其配置)也没有什么不好。
首先,安装和配置大量工具和库需要花费时间,然后在发布新版本时,您将不得不再次花费时间。 其次,神经网络需要大量的计算能力来进行训练。 如果您使用GPU,则可以加快(提高10倍或更多倍)此过程。在撰写本文时,最适合此工作的顶级GPU的价格为2,000美元-7,000美元。 是的,它们也需要配置。
因此,我们将另辟。径。 事实是,Google允许像我们这样的贫穷刺猬免费使用其集群中的GPU,以进行与神经网络有关的计算,它还提供了完全配置的环境,总之称为Google Colab。 该服务使您可以使用python,Keras和许多其他已配置的库访问Jupiter Notebook。 您要做的就是获得一个Google帐户(获得一个Gmail帐户,这将使您能够访问其他所有内容)。
目前,您可以在
此处聘用Colab,但是了解Google,这种情况可以随时更改。 只是谷歌谷歌Colab。
使用Colab的明显问题是它是一个WEB服务。 我们如何访问我们的数据? 训练后保存神经网络,例如,下载特定于我们任务的数据等等?
有几种(在撰写本文时-三种)不同的方式,我们使用一种我认为最方便的方式-我们使用Google云端硬盘。
Google云端硬盘是一种基于云的数据存储,其工作方式与常规硬盘非常相似,并且可以映射到Google Colab(请参见下面的代码)。 之后,您可以像处理本地磁盘上的文件一样使用它。 也就是说,例如,为了访问狗的照片以训练我们的神经网络,我们需要将它们上传到Google云端硬盘,仅此而已。
创建和训练神经网络
下面,我逐个逐节给出Python中的代码(来自Jupiter Notebook)。 您也可以将此代码复制到Jupiter Notebook中并逐块运行它,因为块可以独立执行(当然,在早期块中可能需要在早期块中定义的变量,但这显然是依赖性)。
初始化
首先,让我们挂载Google云端硬盘。 只有两行。 此代码仅应在Colab会话中执行一次(例如,每6小时执行一次)。 如果在会话仍处于“活动”状态时第二次调用它,则由于已安装驱动器,因此将跳过该会话。
from google.colab import drive drive.mount('/content/drive/')
在开始时,将要求您确认您的意图,没有什么复杂的。 看起来是这样的:
>>> Go to this URL in a browser: ... >>> Enter your authorization code: >>> ·········· >>> Mounted at /content/drive/
完全标准的
包含部分; 可能不需要其中包含的某些文件,嗯...抱歉。 另外,由于我将测试不同的神经网络,因此您将必须针对特定类型的神经网络注释/取消注释其中包含的一些模块:例如,要使用InceptionV3 NN,请注释不包括InceptionV3,并注释掉例如ResNet50。 是否:所发生的所有变化仅是所使用的内存大小,并且不是很强。
import datetime as dt import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from tqdm import tqdm import cv2 import numpy as np import os import sys import random import warnings from sklearn.model_selection import train_test_split import keras from keras import backend as K from keras import regularizers from keras.models import Sequential from keras.models import Model from keras.layers import Dense, Dropout, Activation from keras.layers import Flatten, Conv2D from keras.layers import MaxPooling2D from keras.layers import BatchNormalization, Input from keras.layers import Dropout, GlobalAveragePooling2D from keras.callbacks import Callback, EarlyStopping from keras.callbacks import ReduceLROnPlateau from keras.callbacks import ModelCheckpoint import shutil from keras.applications.vgg16 import preprocess_input from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator from keras.models import load_model from keras.applications.resnet50 import ResNet50 from keras.applications.resnet50 import preprocess_input from keras.applications.resnet50 import decode_predictions from keras.applications import inception_v3 from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input as inception_v3_preprocessor from keras.applications.mobilenetv2 import MobileNetV2 from keras.applications.nasnet import NASNetMobile
在Google云端硬盘上,我们为文件创建了一个文件夹。 第二行显示其内容:
working_path = "/content/drive/My Drive/DeepDogBreed/data/" !ls "/content/drive/My Drive/DeepDogBreed/data" >>> all_images labels.csv models test train valid
如您所见,这些狗的照片(从Google云端硬盘上的斯坦福数据集(见上文)复制)首先保存在
all_images文件夹中。 稍后,我们将它们复制到
火车目录
,有效目录和
测试目录中。 我们将训练好的模型保存在
models文件夹中。 至于labels.csv文件,这是带有照片的数据集的一部分,它包含一张图片和狗的品种名称对应的表格。
您可以运行许多测试来了解我们从Google暂时获得的确切信息。 例如:
如您所见,GPU已真正连接,如果未连接,则需要在Jupiter Notebook设置中找到并启用此选项。
接下来,我们需要声明一些常量,例如图像的大小等。 我们将使用大小为256x256像素的图片,这是一个足够大的图像,以免丢失细节,又足够小,以至于所有内容都适合存储在内存中。 但是请注意,我们将使用的某些类型的神经网络期望224x224像素的图像。 在这种情况下,我们评论256而取消评论224。
相同的方法(注释一-取消注释)将应用于我们保存的模型的名称,仅仅是因为我们不想覆盖可能仍然有用的文件。
warnings.filterwarnings("ignore") os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' np.random.seed(7) start = dt.datetime.now() BATCH_SIZE = 16 EPOCHS = 15 TESTING_SPLIT=0.3
资料载入
首先,让我们
上传labels.csv文件并将其分为训练和验证部分。 请注意,目前尚无测试部分,因为我将作弊以获取更多训练数据。
labels = pd.read_csv(working_path + 'labels.csv') print(labels.head()) train_ids, valid_ids = train_test_split(labels, test_size = TESTING_SPLIT) print(len(train_ids), 'train ids', len(valid_ids), 'validation ids') print('Total', len(labels), 'testing images') >>> id breed >>> 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull >>> 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo >>> 2 001cdf01b096e06d78e9e5112d419397 pekinese >>> 3 00214f311d5d2247d5dfe4fe24b2303d bluetick >>> 4 0021f9ceb3235effd7fcde7f7538ed62 golden_retriever >>> 7155 train ids 3067 validation ids >>> Total 10222 testing images
接下来,根据文件名将图像文件复制到training / validation / test文件夹。 以下函数将我们将其名称传输到的文件复制到指定的文件夹。
def copyFileSet(strDirFrom, strDirTo, arrFileNames): arrBreeds = np.asarray(arrFileNames['breed']) arrFileNames = np.asarray(arrFileNames['id']) if not os.path.exists(strDirTo): os.makedirs(strDirTo) for i in tqdm(range(len(arrFileNames))): strFileNameFrom = strDirFrom + arrFileNames[i] + ".jpg" strFileNameTo = strDirTo + arrBreeds[i] + "/" + arrFileNames[i] + ".jpg" if not os.path.exists(strDirTo + arrBreeds[i] + "/"): os.makedirs(strDirTo + arrBreeds[i] + "/")
如您所见,我们仅将每个犬种复制一个文件作为
测试 。 同样,在复制时,我们会创建子文件夹,每个子文件夹一个。 因此,按品种将照片复制到子文件夹中。
这样做是因为Keras可以使用结构相似的目录,可以根据需要而不是一次全部加载图像文件,从而节省了内存。 一次上传所有15,000张图片是一个坏主意。
我们将仅需调用一次此函数,因为它会复制图像-不再需要。 因此,为了将来使用,我们必须对此发表评论:
获取狗的品种列表:
breeds = np.unique(labels['breed']) map_characters = {}
影像处理
我们将使用称为ImageDataGenerators的Keras库功能。 ImageDataGenerator可以处理图像,缩放,旋转等。 它还可以接受可以额外处理图像的
处理功能。
def preprocess(img): img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation = cv2.INTER_AREA)
请注意以下代码:
我们可以在ImageDataGenerator本身中规范化(子数据在0-1范围内,而不是原始的0-255)。 为什么我们需要预处理器? 例如,考虑模糊调用(注释,我不使用它):这是相同的自定义图像操作,可以是任意的。 从HDR到对比度的任何事物。
我们将使用两种不同的ImageDataGenerator,一种用于训练,另一种用于验证。 不同之处在于,对于训练,我们需要轮流和缩放以增加数据的“多样性”,但对于验证,至少不需要这项任务。
train_datagen = ImageDataGenerator( preprocessing_function=preprocess,
创建一个神经网络
如前所述,我们将创建几种类型的神经网络。 每次我们调用另一个函数来创建,包含其他文件时,有时会确定不同的图像大小。 因此,要在不同类型的神经网络之间切换,我们必须注释/取消注释相应的代码。
首先,创建一个“香草” CNN。 它不能很好地工作,因为我决定不浪费时间对其进行调试,但是至少它提供了可以根据需要进行开发的基础(通常这是一个坏主意,因为经过预先培训的网络可以提供最佳结果)。
def createModelVanilla(): model = Sequential()
当我们使用
转移学习创建网络时,过程将更改:
def createModelMobileNetV2():
创建其他类型的网络遵循相同的模式:
def createModelResNet50(): base_model = ResNet50(weights='imagenet', include_top=False, pooling='avg', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)) x = base_model.output x = Dense(512)(x) x = Activation('relu')(x) x = Dropout(0.5)(x) predictions = Dense(NUM_CLASSES, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions)
警告:赢家! 该NN显示出最佳结果:
def createModelInceptionV3():
另一个:
def createModelNASNetMobile():
不同类型的神经网络可用于不同任务。 因此,除了对预测准确性的要求外,大小(移动NN比Inception小5倍)和速度(如果我们需要实时处理视频流,则必须牺牲准确性)也很重要。
神经网络训练
首先,我们正在
试验 ,因此我们应该能够删除已保存但不再使用的神经网络。 以下函数删除NN(如果存在):
我们创建和删除神经网络的方法非常简单明了。 首先,删除。 当调用
delete (仅)时,应牢记Jupiter Notebook具有“运行选择”功能,仅选择要使用的功能,然后运行它。
然后,如果文件不存在,则创建一个神经网络;如果文件存在,则创建一个调用:当然,我们不能调用“ delete”,然后期望NN存在,因此要使用保存的神经网络,请不要调用
delete 。
换句话说,我们可以根据情况和当前正在尝试的内容来创建新的NN,或使用现有的NN。 一个简单的场景:我们训练了一个神经网络,然后去度假。 他们回来了,谷歌确定了会议的内容,因此我们需要加载以前保存的文件:注释掉“删除”,取消注释“加载”。
deleteSavedNet(working_path + strModelFileName)
检查点是我们程序中非常重要的元素。 我们可以创建一个函数数组,每个训练时代结束时应调用这些函数,并将其传递给检查点。 例如,
如果神经网络显示的结果比已保存的结果好,则可以保存该神经网络。
checkpoint = ModelCheckpoint(working_path + strModelFileName, monitor='val_acc', verbose=1, save_best_only=True, mode='auto', save_weights_only=False) callbacks_list = [ checkpoint ]
最后,我们在训练集上教授神经网络:
最佳配置的精度和损耗图如下:
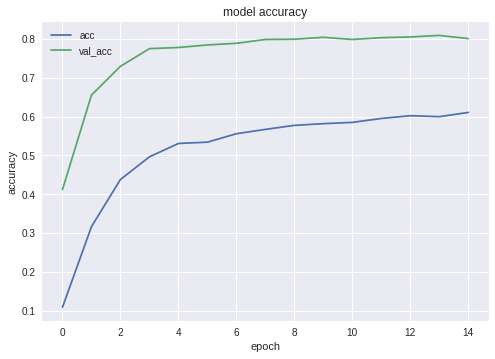

如您所见,神经网络正在学习,而且还不错。
神经网络测试
训练完成后,我们必须测试结果; 为此,NN展示了她以前从未见过的照片-我们复制到测试文件夹中的照片-每个犬种一张。
将神经网络导出到Java应用程序
首先,我们需要从磁盘组织神经网络的加载。 原因很明显:导出是在另一个代码块中进行的,因此很可能我们将神经网络置于最佳状态时分别开始导出。 也就是说,在即将导出之前,在该程序的同一运行中,我们将不会训练网络。 如果使用此处显示的代码,则没有任何区别,因此已为您选择了最佳网络。 但是,如果您学到了一些自己的东西,那么在保存之前重新培训所有内容将浪费时间,如果在此之前您已保存了所有内容。
出于同样的原因-不要跳过代码-我在此处包括了导出所需的文件。 如果您的美感需要,没有人会打扰您将其移至程序的开头:
from keras.models import Model from keras.models import load_model from keras.layers import * import os import sys import tensorflow as tf
加载神经网络后进行的一项小型测试,只是为了确保加载的所有内容都可以正常工作:
img = image.load_img(working_path + "test/affenpinscher.jpg")

接下来,我们需要获取网络输入和输出层的名称(无论是此功能还是创建功能,我们都必须明确地“命名”这些层,而我们没有这样做)。
model.summary() >>> Layer (type) >>> ====================== >>> input_7 (InputLayer) >>> ______________________ >>> conv2d_283 (Conv2D) >>> ______________________ >>> ... >>> dense_14 (Dense) >>> ====================== >>> Total params: 22,913,432 >>> Trainable params: 1,110,648 >>> Non-trainable params: 21,802,784
稍后,当我们将神经网络导入Java应用程序时,我们将使用输入和输出层的名称。
漫游网络以获取此数据的另一个代码:
def print_graph_nodes(filename): g = tf.GraphDef() g.ParseFromString(open(filename, 'rb').read()) print() print(filename) print("=======================INPUT===================") print([n for n in g.node if n.name.find('input') != -1]) print("=======================OUTPUT==================") print([n for n in g.node if n.name.find('output') != -1]) print("===================KERAS_LEARNING==============") print([n for n in g.node if n.name.find('keras_learning_phase') != -1]) print("===============================================") print()
但是我不喜欢他,也不推荐他。以下代码会将Keras神经网络导出为pb格式,这是我们将从Android捕获的格式。 def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True): if os.path.exists(output_dir) == False: os.mkdir(output_dir) out_nodes = [] for i in range(len(keras_model.outputs)): out_nodes.append(out_prefix + str(i + 1)) tf.identity(keras_model.output[i], out_prefix + str(i + 1)) sess = K.get_session() from tensorflow.python.framework import graph_util from tensorflow.python.framework graph_io init_graph = sess.graph.as_graph_def() main_graph = graph_util.convert_variables_to_constants( sess, init_graph, out_nodes) graph_io.write_graph(main_graph, output_dir, name=model_name, as_text=False) if log_tensorboard: from tensorflow.python.tools import import_pb_to_tensorboard import_pb_to_tensorboard.import_to_tensorboard( os.path.join(output_dir, model_name), output_dir)
调用以下函数以导出神经网络:
model = load_model(working_path + strModelFileName) keras_to_tensorflow(model, output_dir=working_path + strModelFileName, model_name=working_path + "models/dogs.pb") print_graph_nodes(working_path + "models/dogs.pb")
最后一行显示了所得神经网络的结构。使用神经网络创建Android应用程序
Android中神经网络的导出已被形式化,不应造成任何困难。和往常一样,有几种方法,我们使用的是最流行的(在撰写本文时)。首先,我们使用Android Studio创建一个新项目。我们将“偷工减料”,因为我们的任务不是android教程。因此,该应用程序将仅包含一个活动。 如您所见,我们添加了“ assets”文件夹并将神经网络复制到其中(我们之前导出的那个)。
如您所见,我们添加了“ assets”文件夹并将神经网络复制到其中(我们之前导出的那个)。摇篮文件
在此文件中,您需要进行一些更改。首先,我们需要导入tensorflow-android库。它用于Java中的Tensorflow(以及相应的Keras):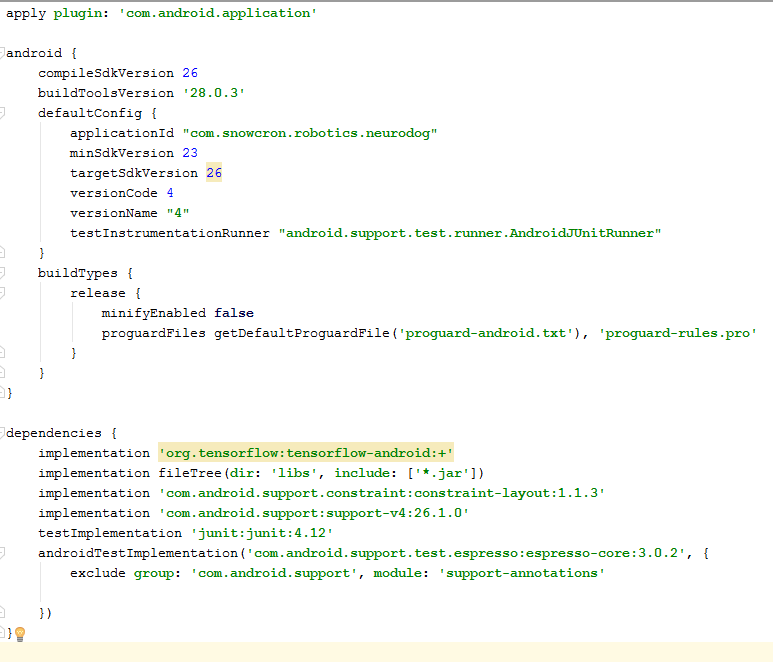 另一个不明显的绊脚石:versionCode和versionName。当应用程序更改时,您将需要在Google Play上上传新版本。如果不更改gdadle中的版本(例如1-> 2-> 3 ...),则无法执行此操作,Google会给出错误消息“此版本已存在”。
另一个不明显的绊脚石:versionCode和versionName。当应用程序更改时,您将需要在Google Play上上传新版本。如果不更改gdadle中的版本(例如1-> 2-> 3 ...),则无法执行此操作,Google会给出错误消息“此版本已存在”。清单
首先,我们的应用程序将是“繁重的”-100 Mb神经网络将很容易装入现代手机的内存中,但是为从Facebook“共享”的每张照片打开单独的实例绝对不是一个好主意。因此,我们禁止创建多个应用程序实例: <activity android:name=".MainActivity" android:launchMode="singleTask">
通过向MainActivity 添加android:launchMode =“ singleTask”,我们告诉Android打开(激活)应用程序的现有副本,而不是创建另一个实例。然后,我们需要将我们的应用程序包含在列表中,当有人“共享”图片时,系统会显示该应用程序: <intent-filter> <action android:name="android.intent.action.SEND" /> <category android:name="android.intent.category.DEFAULT" /> <data android:mimeType="image/*" /> </intent-filter>
最后,我们需要请求应用程序将使用的功能和权限: <uses-feature android:name="android.hardware.camera" android:required="true" /> <uses-permission android:name= "android.permission.WRITE_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.READ_PHONE_STATE" tools:node="remove" />
如果您熟悉Android编程,则此部分不会引起任何问题。布局应用程序。
我们将创建两种布局,一种用于纵向,一种用于横向。这就是Portrait布局的样子。我们将添加的内容:显示图片的大视野(视图),烦人的广告列表(按下带有骨骼的按钮时显示),“帮助”按钮,用于从“文件/图库”下载图片并从相机捕获图片的按钮,最后(最初是隐藏)用于图像处理的“处理”按钮。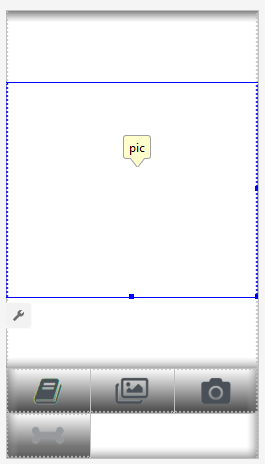 根据应用程序的状态,活动本身包含显示和隐藏以及启用/禁用按钮的所有逻辑。
根据应用程序的状态,活动本身包含显示和隐藏以及启用/禁用按钮的所有逻辑。主要活动
该活动继承(扩展)了标准的Android活动: public class MainActivity extends Activity
考虑负责神经网络操作的代码。首先,神经网络接受位图。最初,这是来自相机或文件(m_bitmap)的大位图(任意大小),然后我们对其进行转换,从而生成标准256x256像素(m_bitmapForNn)。我们还将位图大小(256)存储在一个常量中: static Bitmap m_bitmap = null; static Bitmap m_bitmapForNn = null; private int m_nImageSize = 256;
我们必须告诉神经网络输入和输出层的名称。我们较早收到了它们(请参见清单),但请记住,在您的情况下,它们可能有所不同: private String INPUT_NAME = "input_7_1"; private String OUTPUT_NAME = "output_1";
然后,我们声明一个变量来保存TensofFlow对象。另外,我们存储神经网络文件(位于资产中)的路径:私有TensorFlowInferenceInterface tf;
私有字符串MODEL_PATH =
“文件:////android_asset/dogs.pb”;
我们将狗的品种存储在列表中,以便稍后将它们显示给用户,而不是数组索引: private String[] m_arrBreedsArray;
最初,我们下载了位图。但是,神经网络需要一个RGB值数组,并且其输出是该品种就是图中所示概率的数组。因此,我们需要添加两个以上的数组(请注意,我们的训练数据中存在120个犬种): private float[] m_arrPrediction = new float[120]; private float[] m_arrInput = null;
下载tensorflow推理库: static { System.loadLibrary("tensorflow_inference"); }
由于神经网络操作需要时间,因此我们需要在单独的线程中执行它们,否则我们将有可能收到系统消息“应用程序无响应”,更不用说用户不满意了。 class PredictionTask extends AsyncTask<Void, Void, Void> { @Override protected void onPreExecute() { super.onPreExecute(); }
在MainActivity的onCreate()中,我们需要为“ Process”按钮添加onClickListener: m_btn_process.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { processImage(); } });
这里的processImage()只是调用我们上面描述的线程: private void processImage() { try { enableControls(false);
附加说明
我们不打算讨论Android的UI编程的细节,因为这当然不适用于移植神经网络的任务。但是,有一件事仍然值得一提。当我们阻止创建应用程序的其他实例时,我们也破坏了创建和删除活动(控制流程)的通常顺序:如果您“共享” Facebook中的图片,然后共享另一张图片,则该应用程序将不会重新启动。这意味着在onCreate中捕获传输数据的“传统”方式是不够的,因为不会调用onCreate。解决此问题的方法如下:1.在MainActivity中的onCreate中,调用onSharedIntent函数: protected void onCreate( Bundle savedInstanceState) { super.onCreate(savedInstanceState); .... onSharedIntent(); ....
我们还为onNewIntent添加了一个处理程序: @Override protected void onNewIntent(Intent intent) { super.onNewIntent(intent); setIntent(intent); onSharedIntent(); }
这是onSharedIntent函数本身: private void onSharedIntent() { Intent receivedIntent = getIntent(); String receivedAction = receivedIntent.getAction(); String receivedType = receivedIntent.getType(); if (receivedAction.equals(Intent.ACTION_SEND)) {
现在,我们在onCreate(如果应用程序不在内存中)或onNewIntent(如果它早先启动)中处理传输的数据。祝你好运 如果您喜欢这篇文章,请以所有可能的方式“喜欢”它,网站上也有“社交”按钮。