我们尽可能地开发了DevOps。 我们共有8个人,而Vasya是Windows上最酷的。 突然,Vasya离开了,我的任务是提出一个新项目,该项目可以进行Windows开发。 当我将整个Windows开发堆栈放到桌子上时,我意识到这种情况很痛苦...
因此,开始了
DevOpsConf上的
Alexander Sinchinov的故事。 当领先的Windows专家离开公司时,亚历山大想知道现在该怎么做。 当然,切换到Linux! 亚历山大将以一个已完成的100,000个最终用户的项目为例,讲述他如何树立先例并将Windows开发的一部分转换为Linux。

如何使用TFS,Puppet,Linux .NET核心轻松,轻松地将项目交付到RPM? 如果开发人员首先听到Postgres和Flyway字样以及后天的截止日期,那么如何维护项目数据库的版本? 如何与Docker集成? 如何激励.NET开发人员放弃Windows和冰沙而转而使用Puppet和Linux? 如果没有力量,没有欲望,没有资源为生产中的Windows服务,如何解决思想冲突? 关于这一点,以及有关Web Deploy,测试,CI,在现有项目中使用TFS的实践,以及有关在解码亚历山大报告中的broken脚和可行的解决方案的问题。
因此,Vasya离开了,任务对我来说,开发人员正期待着
干草叉 。 当我最终意识到Vasya无法归还时,我开始做生意。 首先,我估算了我们园区中Win VM的百分比。 该分数不支持Windows。
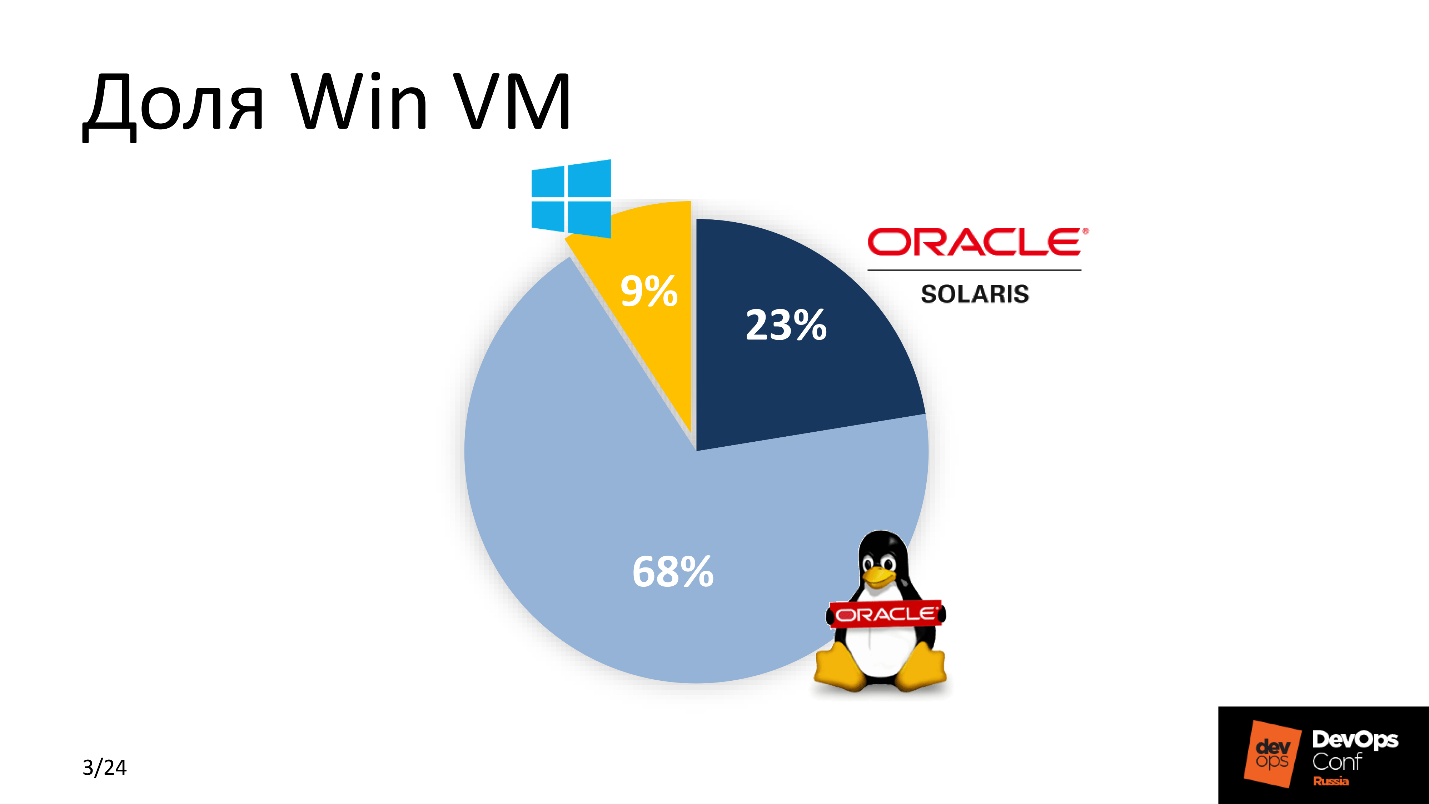
由于我们正在积极开发DevOps,因此我意识到在开发新应用程序的方法中需要进行一些更改。 解决方案是一种-如果可能,将所有内容都转移到Linux。 Google帮了我-当时.Net已经移植到Linux上,我意识到这个解决方案!
为什么.NET core与Linux捆绑在一起?
有几个原因。 在“付钱”和“不付钱”之间,大多数人会选择第二个-就像我一样。 MSDB的许可证费用约为1,000美元;维护Windows虚拟机机队的费用为数百美元。 对于一家大公司而言,这是一笔不小的支出。 因此,
节省是
首要原因 。 不是最重要的,而是最重要的之一。
Windows虚拟机比Linux兄弟占用更多的资源-
它们很沉重 。 考虑到大型公司的规模,我们选择了Linux。
该系统可以简单地集成到现有CI中 。 我们认为自己是渐进的DevOps,我们使用Bamboo,Jenkins和GitLab CI,因此我们的大部分工作都在Linux上进行。
最后一个原因是
方便陪同。 我们需要降低“护送”的准入门槛-了解技术部分的人员,确保从第二行开始不间断的操作和服务。 他们已经熟悉Linux堆栈,因此,与花费额外的资源来处理Windows平台软件的类似功能相比,他们更容易理解,维护和维护新产品。
要求条件
首先,
对于开发人员而言,新解决方案的
便利性 。 并非所有人都准备好进行更改,尤其是在使用Linux这个词之后。 开发人员希望他们心爱的Visual Studio TFS具有构建测试和冰沙。 生产中交货的方式-他们不在乎。 因此,我们决定不更改常规过程,并保留Windows开发的所有内容。
新项目需要
嵌入现有的CI中 。 导轨已经在那儿了,所有工作都必须考虑到配置管理系统的参数,公认的交付标准和监控系统。
支持和操作要简单 ,这是来自不同部门和支持部门的所有新参与者的最低进入门槛的条件。
截止日期-昨天 。
赢发展集团
Windows团队当时从事什么工作?

现在,我可以自信地说,
IdentityServer4是具有类似功能的ADFS的免费替代品,或者
Entity Framework Core是开发人员的天堂,在这里您不必费心编写SQL脚本,而可以用OOP术语描述数据库中的查询。 但是,随后,在讨论行动计划时,我将此堆栈看作是苏美尔楔形文字,只能识别PostgreSQL和Git。
那时,我们积极地使用
Puppet作为配置管理系统。 在我们的大多数项目中,我们使用
GitLab CI ,
Elastic ,使用
HAProxy的平衡高负载服务,使用
Zabbix ,一堆
Grafana和
Prometheus ,
Jaeger监视所有内容,并且所有这些都在
VMware硬件上与
HP硬件一起运行。 人人都知道-经典的流派。

让我们看看并尝试了解在开始所有这些干预之前发生了什么。
那是什么
TFS是一个功能非常强大的系统,它不仅可以将代码从开发人员交付到最终的生产机器,而且还具有一套与各种服务进行非常灵活集成的功能-在跨平台级别提供CI。

以前,这些是坚固的窗户。 TFS使用了几个Build代理,这些代理收集了很多项目。 每个代理都有3-4个工作人员-a,以便并行执行任务和优化流程。 此外,根据发布计划,TFS将新鲜出炉的Build交付给Windows应用程序服务器。
我们想来的
为了进行交付和开发,我们使用TFS,然后在Linux Application Server上启动该应用程序,它们之间存在某种魔术。 这个
魔术盒是即将到来的作品的精髓。 在分拆它之前,我将走到一边,对应用程序说两个字。
专案
该应用程序提供了用于处理预付卡的功能。
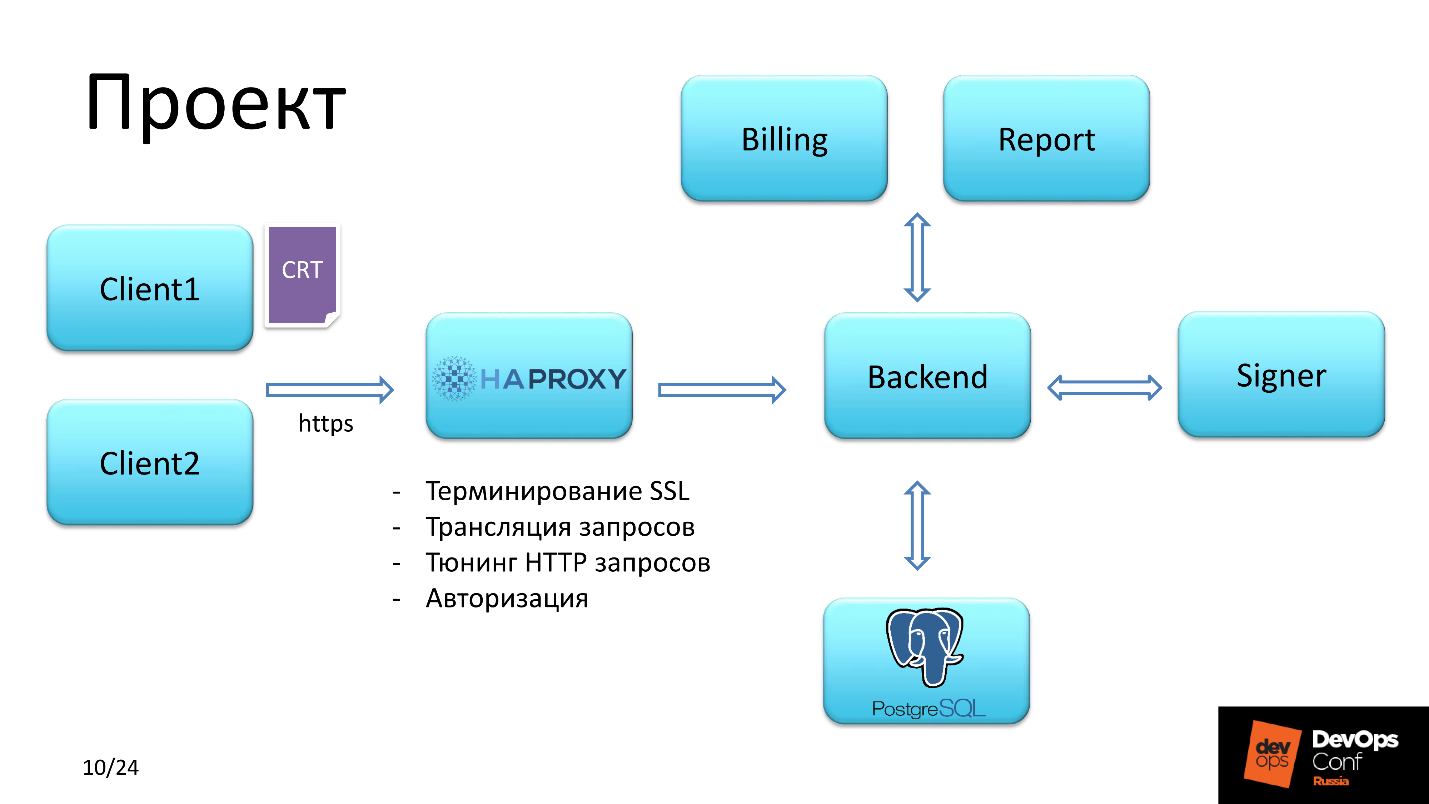
委托人
有两种类型的用户。
第一个通过使用SSL SHA-2证书登录获得访问权限。
第二个可以通过登录名和密码访问。
HAProxy
此外,客户端请求属于HAProxy,它解决了以下任务:
客户证书的验证贯穿整个链。 我们是
权威 ,我们负担得起,因为我们自己向服务客户颁发证书。
注意第三点,稍后我们将返回到第三点。
后端
他们计划在Linux上做一个后端。 后端与数据库进行交互,加载必要的特权列表,然后根据授权用户所拥有的特权,提供对财务文档进行签名并发送它们以执行或生成某种报告的访问权限。
使用HAProxy保存
除了每个客户端过去要经历的两个上下文之外,还有一个身份上下文。
IdentityServer4只允许您登录,它是
ADFS -
Active Directory联合 身份验证服务的免费而强大的模拟。
身份请求经过几个步骤进行处理。 第一步-
客户端 进入后端 ,
后端与该服务器交换数据并检查客户端是否存在令牌。 如果找不到该请求,则该请求将返回到它所来自的上下文中,但是具有重定向,并且具有指向身份的重定向。
第二步-请求转到
IdentityServer中的身份验证页面,在该
页面中注册了客户端,并且等待已久的令牌出现在IdentityServer数据库中。
第三步-
客户端重定向回他来自的上下文。
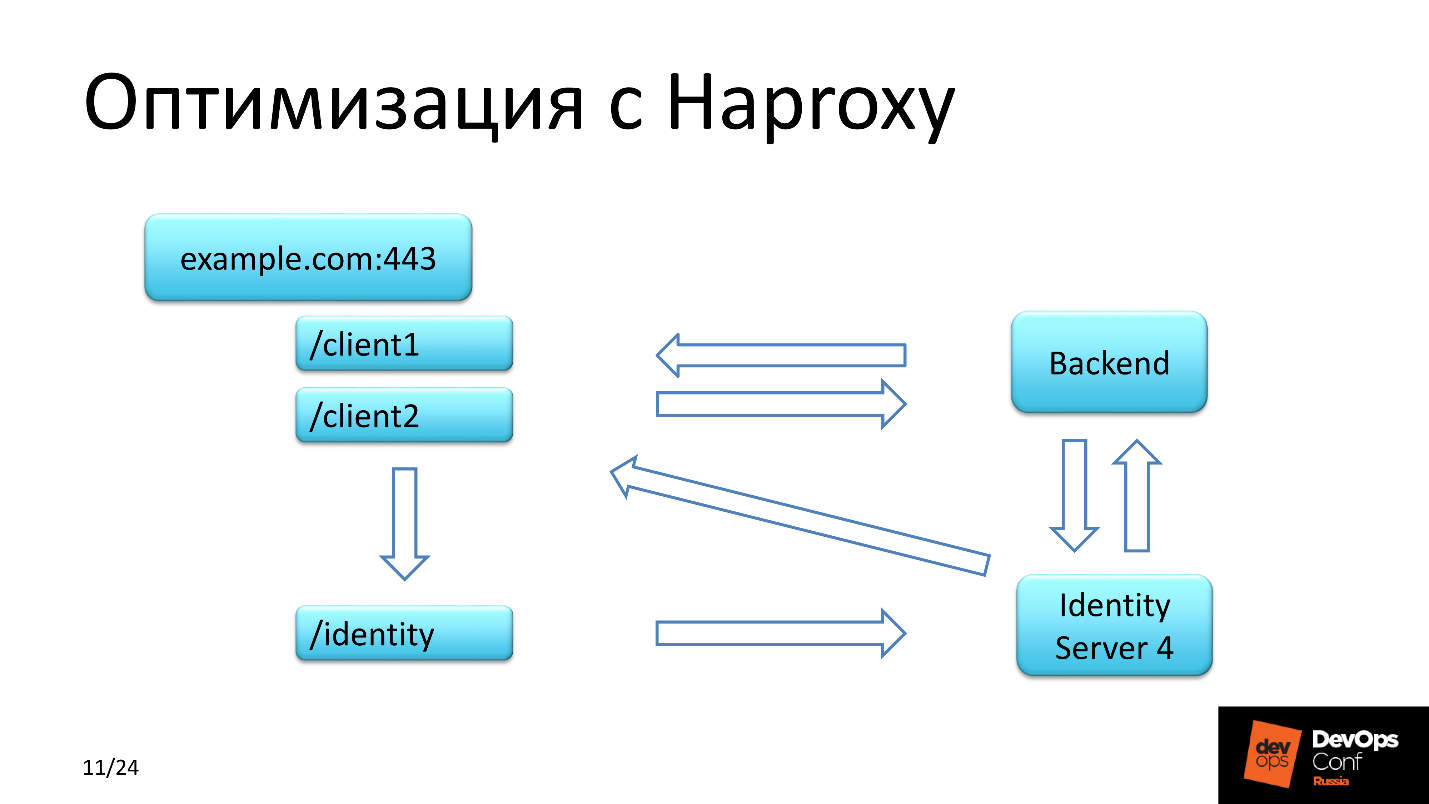
IdentityServer4具有一个特殊性:
它通过HTTP返回对返回请求的响应 。 无论我们如何为服务器设置而苦苦挣扎,无论我们如何对文档有所了解,每次我们收到带有通过HTTPS发出的URL的初始客户端请求时,IdentityServer都返回相同的上下文,但是使用HTTP。 我们感到震惊! 所有这些都通过身份上下文传输到HAProxy,并且在标头中,我们必须将HTTP协议修改为HTTPS。
有什么改进?它们在哪里保存?
我们使用免费的解决方案授权一组用户和资源节省了资金,因为我们没有将IdentityServer4作为单独的注释放在单独的段中,而是将它与后端一起在应用程序后端旋转的同一台服务器上使用。
它应该如何工作
所以,正如我所承诺的-魔术盒。 我们已经了解到我们一定会向Linux迈进。 让我们制定需要解决方案的特定任务。
 木偶显现。
木偶显现。 为了交付和管理服务和应用程序的配置,您必须编写出色的配方。 铅笔卷雄辩地展示了这样做的速度和效率。
交付方式。 标准是RPM。 每个人都知道在Linux中没有它是不可能的,但是组装后的项目本身就是一组可执行DLL文件。 其中大约有150个,该项目相当困难。 唯一和谐的解决方案是将这些二进制文件打包到RPM中,并从中部署应用程序。
版本控制 我们不得不经常发布,并且我们必须决定如何形成软件包的名称。 这是TFS集成级别的问题。 我们在Linux上有一个构建代理。 当TFS将任务发送给处理程序(工作程序)至Build代理时,它还会向其发送一堆属于处理程序进程环境的变量。 这些环境变量将传递给名称Build,版本名称和其他变量。 在“组装RPM软件包”一节中了解有关此内容的更多信息。
设置TFS归结为设置管道。 以前,我们在Windows代理上收集了所有Windows项目,现在有一个Linux代理-一个Build代理,需要将其包含在程序集组中,其中包含一些工件,可以告诉您将在该Build代理上构建哪种类型的项目,并以某种方式修改管道。
IdentityServer。 ADFS不是我们的方法,我们为开源而淹没。
让我们看一下这些组件。
魔术盒
包括四个部分。
 Linux构建代理。
Linux构建代理。 因为我们进行编译,所以Linux是合乎逻辑的。 此部分分三个步骤进行。
- 配置工作人员和多个工作人员 ,因为假定该工作是在项目上进行的。
- 安装.NET Core1.x。 当标准存储库中已有2.0版本时,为什么要使用1.x? 因为当我们开始开发时,稳定的版本是1.09,因此决定为此做项目。
- Git2.x。
RPM存储库。 RPM软件包需要存储在某个地方。 假定我们将使用可用于所有Linux主机的相同公司RPM存储库。 因此,他们做到了。 在存储库服务器上配置了一个
Webhook ,该
Webhook从指定位置下载了所需的RPM软件包。 该软件包的版本已由Build代理报告给webhook。
Gitlab 注意! 在这里,开发人员不是使用GitLab,而是由运营部门使用GitLab来控制应用程序版本,程序包版本,监视所有Linux机器的状态并存储配方-所有Puppet清单。
Puppet-解决了所有有争议的问题,并准确地提供了我们希望从Gitlab获得的配置。
我们开始潜水。 DLL如何在RPM中传递?
DDL交付到RPM
假设我们有一个.NET开发的明星。 它使用Visual Studio并创建发布分支。 之后,它将其加载到Git中,这里的Git是一个TFS实体,即开发人员使用的应用程序存储库。
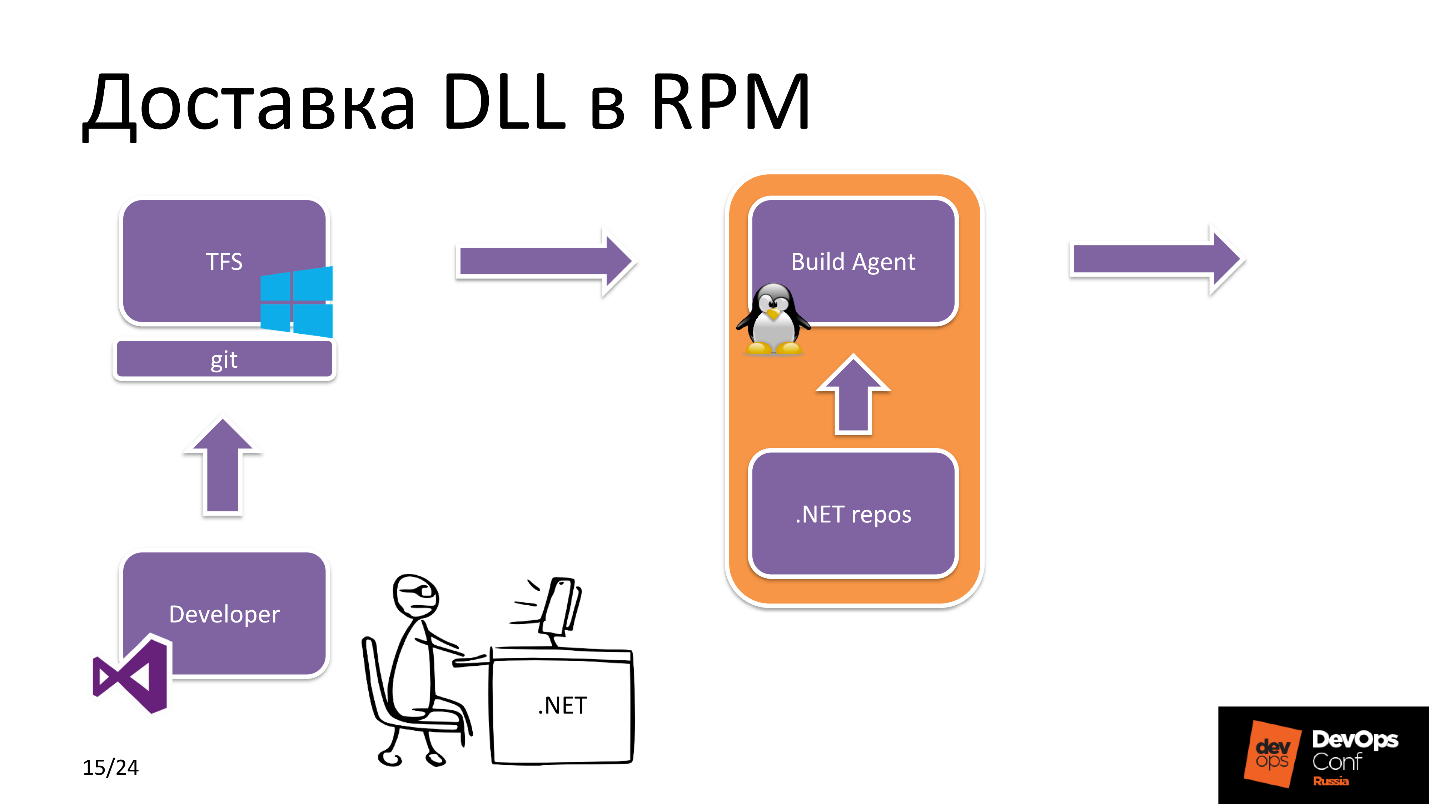
之后,TFS看到新的提交已到达。 哪个应用程序? 在TFS设置中,有一个有关特定Build代理拥有哪些资源的标签。 在这种情况下,他看到我们正在构建.NET Core项目,并从池中选择Linux构建代理。
构建代理接收源,从.NET,npm存储库等下载必要的
依赖项 。 在构建应用程序本身并进行后续打包之后,它将RPM软件包发送到RPM存储库。
另一方面,发生以下情况。 维护工程师直接参与了项目的开发:它在存储应用程序配方的存储库中的
Hiera中更改了软件包的版本,然后Puppet触发了
Yum ,从存储库中获取了新的软件包,并且可以使用新版本的应用程序了。

换句话说,一切都很简单,但是在构建代理本身内部会发生什么?
打包RPM DLL
来自TFS的项目资源和构建任务已收到。 构建代理
将从源开始构建项目 。 组装后的项目以许多
DLL文件的形式提供,这些
文件打包在zip归档文件中,以减少文件系统上的负载。
ZIP归档文件将
放入RPM软件包的build目录中。 接下来,Bash脚本初始化环境变量,找到Build版本,项目版本,build目录的路径,然后启动RPM-build。 在程序集的最后,程序包将发布到
本地资源库 ,该
资源库位于Build代理上。
此外,带有版本名称和版本的
JSON请求从Build代理
发送到RPM存储库中的服务器。 我之前谈到的Webhook,是从Build代理的本地存储库下载相同的程序包,并使新程序集可用于安装的。

为什么采用这种方案将软件包交付到RPM存储库? 为什么我不能立即将组装好的包裹寄到仓库? 事实是,这是安全的条件。 这种情况限制了外部人员未经授权将RPM软件包下载到所有Linux机器都可以访问的服务器的可能性。
数据库版本控制
在与开发人员进行磋商时,事实证明,他们更接近于MS SQL,但是在大多数非Windows项目中,我们已经使用PostgreSQL和may and main。 由于我们已经决定放弃所有付费方式,因此我们在这里开始使用PostgreSQL。

在这一部分中,我想谈谈我们如何实现数据库版本控制以及如何在Flyway和Entity Framework Core之间进行选择。 考虑他们的利弊。
缺点
飞路只有一种方式,我们
不能后退 -这是一个很大的缺点。 从开发人员的便利性角度出发,可以根据其他参数与Entity Framework Core进行比较。 您还记得我们把它放在了最前列,主要标准是不要为Windows开发更改任何内容。
对于Flyway,我们
需要某种包装器,以便这些人不编写
SQL查询 。 就OOP而言,它们更接近于操作。 我们编写了有关使用数据库对象的说明,形成了SQL查询并执行了。 数据库的新版本已准备就绪,可以运行-一切正常,一切正常。
Entity Framework Core有一个缺点-在重负载下,它
不能构建最佳的SQL查询 ,并且数据库耗用可能很大。 但是由于我们没有高负载服务,因此我们无法以数百个RPS来计算负载,因此我们承担了这些风险,并将问题委托给了我们。
优点
Entity Framework Core
开箱即用,易于开发 ,并且Flyway
无缝集成到现有CI中 。 但是我们为开发人员方便地做到了:)
汇总程序
Puppet看到软件包的版本有所变化,其中一个负责迁移。 首先,它将安装一个软件包,其中包含与数据库绑定的迁移脚本和功能。 之后,将重新启动与数据库一起使用的应用程序。 接下来是其余组件的安装。 Puppet清单中描述了安装软件包和启动应用程序的顺序。
应用程序使用敏感数据,例如令牌,数据库的密码,所有这些数据都通过Puppet主服务器放入配置中,并以加密形式存储在其中。
TFS问题
在我们决定并意识到一切对我们真正有用之后,我决定查看WinFS开发部门在其他项目中整体使用TFS中的程序集的情况-快或慢,我们要发布/发布,并发现速度方面的重大问题。
其中一个主要项目将花费12至15分钟的时间-很长一段时间,您不能那样生活。 快速分析显示I / O严重下降,而且阵列上也是如此。
在进行了成分分析之后,我确定了三个焦点。 第一个是
Kaspersky antivirus ,它会扫描所有Windows Build代理上的源代码。 第二个是
Windows Indexer。 它并未断开连接,并且在构建代理程序上实时对所有内容进行了索引。
第三是
Npm安装。 事实证明,在大多数管道中,我们都使用了这种特定方案。 他为什么不好? 当在
package-lock.json中形成依赖关系树时,
Npm安装过程开始,其中用于构建项目的软件包版本已固定。 缺点是Npm install每次都会从Internet上获取最新版本的软件包,对于大型项目而言,这是相当长的时间。
开发人员有时会在本地计算机上进行实验,以测试单个零件或整个项目的运行情况。 有时,事实证明,在本地所有事物都很酷,但是组装,发布却没有效果。 我们开始了解问题所在-是的,依赖包的不同版本。
解决方案
npm ci的优势在于,我们
一次收集了依赖关系树 ,并有机会向开发人员提供
软件包的最新列表,以便他可以在本地进行尽可能多的试验。 这
为编写代码的开发人员
节省了时间 。
构型
现在介绍一下存储库配置。 从历史上看,我们一直在使用
Nexus来管理存储库,包括
内部REPO 。 我们用于内部目的的所有组件(例如,自写监视)都交付给该内部存储库。

我们还使用
NuGet ,因为它比其他程序包管理器更好地缓存。
结果
在我们优化了构建代理之后,平均构建时间从12分钟减少到7分钟。
如果我们计算一下所有可以用于Windows的机器,但在该项目中转移到Linux上,我们节省了大约10,000美元,而这仅是基于许可证,并考虑了内容-还要更多。
计划
下个季度,该计划确定了优化代码交付的工作。
过渡到预构建的Docker映像 。 TFS有很多插件,可以使您集成到Pipeline中,这很酷,包括根据触发器进行的组装,例如Docker映像。 我们要在同一
package-lock.json上创建此触发器。 如果用于构建项目的组件的组成以某种方式改变,我们将拥有一个新的Docker映像。 以后将其用于与已编译的应用程序一起部署容器。 现在不是,但是我们计划在Kubernetes中切换到微服务架构,该架构在我们公司中正在积极开发,并且长期为生产解决方案提供服务。
总结
我敦促所有人扔掉Windows,但这不是因为我不知道如何烹饪。 原因是大多数开源解决方案都是
Linux堆栈 。 您会
很好地节省资源 。 在我看来,未来将取决于拥有强大社区的开源Linux解决方案。
演讲者Alexander Sinchinov 在GitHub上的个人资料。DevOps Conf是针对专业人士的开发,测试和运营流程集成的会议。 这就是为什么亚历山大谈到的项目? 实施和工作,并在演出当天成功发布了两个版本。 在5月27日至28日举行的RIT ++ DevOps Conf上 ,从业者还会收到更多此类案例。 您仍然可以跳上最后一辆马车并提交报告,也可以花些时间预订机票。 在斯科尔科沃见我!