如果使用时间序列数据库(timeseries db,
wiki )作为具有统计信息的网站的主要存储库,那么除了解决问题外,您还会头疼。 我正在使用这样的基础的项目中工作,有时将要讨论的InfluxDB完全带来了意想不到的惊喜。
免责声明 :这些问题适用于InfluxDB 1.7.4。
为什么选择时间序列?
该项目将跟踪各种区块链中的交易并显示统计信息。 具体来说,我们研究稳定硬币的发射和燃烧(
wiki )。 基于这些事务,您需要构建图形并显示数据透视表。
在分析事务时,出现了一个想法:使用InfluxDB时间序列数据库作为主要存储。 事务是时间点,非常适合时间序列模型。
另外,聚合函数看起来非常方便-非常适合长时间处理图表。 用户需要一年的图表,并且数据库包含一个具有五分钟时间范围的数据集。 向他发送十万分毫无意义-除了需要长时间的处理外,它们将无法显示在屏幕上。 您可以编写自己的增加时间范围的实现,或者使用Influx内置的聚合功能。 在他们的帮助下,您可以按天分组数据并发送所需的365点。
通常将此类数据库用于收集指标,这令人有些尴尬。 监视服务器,物联网设备,数百万个点均以“倒”的形式从中监视:[<时间>-<度量值>]。 但是,如果数据库能够很好地处理大量数据流,那么为什么少量数据库会引起问题呢? 考虑到这一点,他们让InfluxDB工作。
InfluxDB还有什么方便的
除了提到的聚合功能外,还有另一件事-
连续查询 (
doc )。 这是内置在数据库中的调度程序,可以按调度处理数据。 例如,您可以每隔24小时将一天的所有记录分组一次,计算平均值并在另一张表中写一个新点,而无需编写自己的自行车。
还有
保留策略 (
doc )-在一段时间后设置数据删除。 例如,当您需要将负载在CPU上存储一周并每秒进行一次测量时很有用,但是在几个月的距离内就不需要这种精度了。 在这种情况下,您可以执行以下操作:
- 创建一个连续查询以将数据聚合到另一个表中;
- 对于第一个表,定义一个策略以删除早于该周的指标。
而且Influx将独立减少数据大小并删除不必要的数据。
关于存储的数据
存储的数据很少:大约有7万笔交易和另外100万个包含市场信息的点。 添加新条目-每天不超过3000点。 该站点上也有指标,但是那里的数据很少,并且根据保留策略,它们存储的时间不超过一个月。
问题所在
在服务的开发和后续测试期间,InfluxDB的运行过程中出现了越来越多的关键问题。
1.数据删除
有一系列与交易有关的数据:
SELECT time, amount, block, symbol FROM transactions WHERE symbol='USDT'
结果:
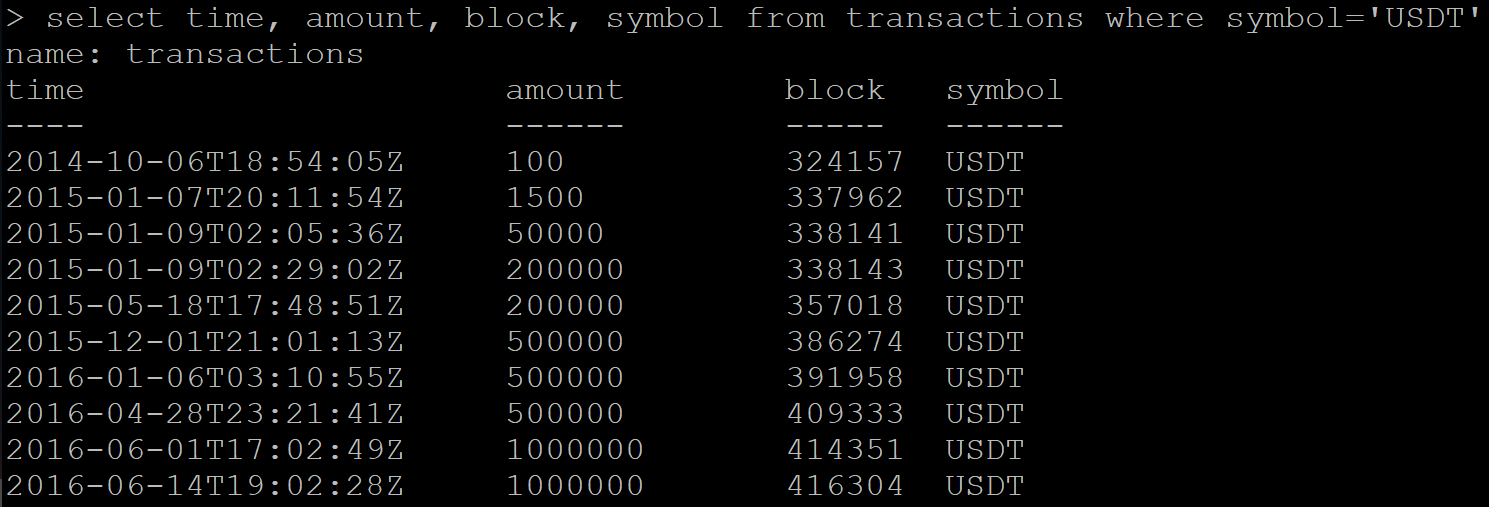
我发送命令删除数据:
DELETE FROM transactions WHERE symbol='USDT'
接下来,我请求接收已经删除的数据。 Influx会返回应该删除的部分数据,而不是一个空的响应。
我尝试删除整个表:
DROP MEASUREMENT transactions
我检查表删除:
SHOW MEASUREMENTS
我没有看到列表中的表格,但是新的数据请求仍会返回同一组交易。
因为删除案例是一个孤立的案例,所以这个问题只对我发生过一次。 但是,数据库的这种行为显然不适合“正确”工作的框架。 稍后在github上,我发现了差不多一年前有关该主题的一张公开
票 。
结果,整个数据库的删除和随后的恢复都有帮助。
2.浮点数
使用InfluxDB中的内置函数进行数学计算会产生准确性错误。 这并不是什么不寻常的事,而是令人不愉快的。
就我而言,数据具有财务成分,因此我希望对其进行高精度处理。 因此,该计划放弃了连续查询。
3.连续查询不能适应不同的时区
该服务有一个表,其中包含每日交易统计信息。 对于每一天,您都需要将当天的所有交易分组。 但是每个用户的一天将在不同的时间开始,因此交易的集合是不同的。 UTC有
37个班次
选项 ,您需要为其汇总数据。
在InfluxDB中按时间分组时,您还可以指定一个班次,例如莫斯科时间(UTC + 3):
SELECT MEAN("supply") FROM transactions GROUP BY symbol, time(1d, 3h) fill(previous)
但是查询结果将不正确。 由于某种原因,按天分组的数据最早可于1677年开始(InfluxDB正式支持从今年开始的时间段):
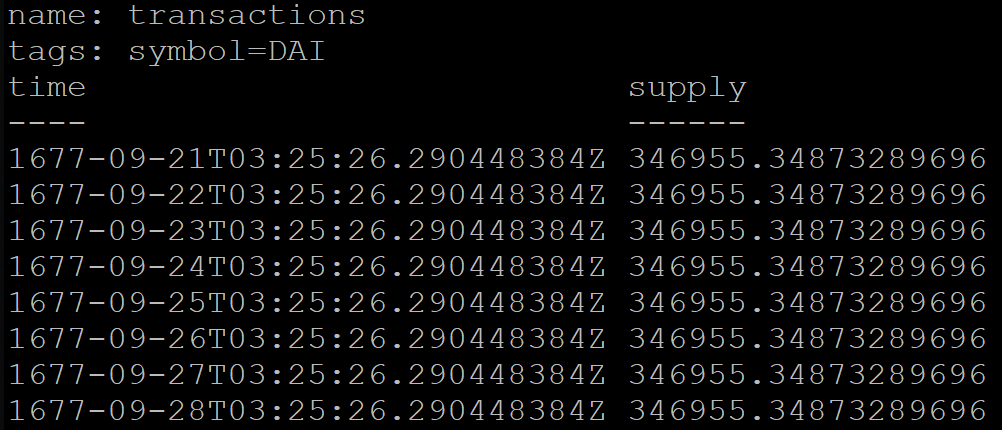
要变通解决此问题,该服务已暂时转移到UTC + 0。
4.表现
Internet上有许多基准,可以比较InfluxDB和其他数据库。 乍一看,它们看起来像是营销材料,但现在我认为它们中有些道理。
我告诉你我的情况。
该服务提供了一种API方法,该方法返回前一天的统计信息。 在计算期间,该方法使用以下查询对数据库进行三次查询:
SELECT * FROM coins_info WHERE time <= NOW() GROUP BY symbol ORDER BY time DESC LIMIT 1
SELECT * FROM dominance_info ORDER BY time DESC LIMIT 1
SELECT * FROM transactions WHERE time >= NOW() - 24h ORDER BY time DESC
解说
- 在第一个查询中,我们使用市场数据获取每个硬币的最后点。 在我的情况下,八枚硬币可获得八分。
- 第二个请求收到一个最新点。
- 第三个请求最后一天的交易列表,可能有数百个。
我将澄清一下,在InfluxDB中,索引是由标签和时间自动建立的,从而加快了查询速度。 在第一个查询中,
symbol是标签。
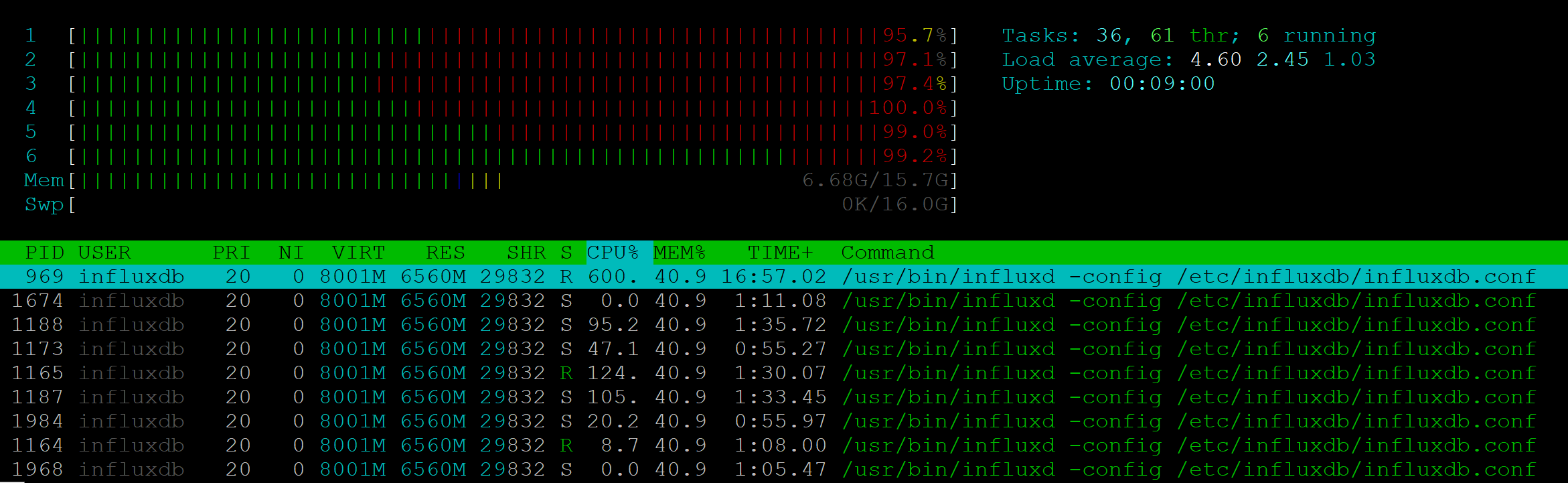
我对此API方法进行了压力测试。 对于25 RPS,服务器显示了六个CPU的满负荷:
同时,NodeJs进程根本没有提供任何负载。
执行速度已经降低了7-10 RPS:如果一个客户端可以在200毫秒内收到响应,则10个客户端应该等待一秒钟。 25 RPS-稳定性受到影响的边界,向客户返回了500个错误。
有了这种性能,就不可能在我们的项目中使用Influx。 此外:在一个需要向许多客户端演示监视的项目中,可能会出现类似的问题,并且度量标准服务器将过载。
结论
从所获得的经验中得出的最重要的结论是,如果不进行充分的分析,就无法将未知的技术带入项目。 在github上对开放式票进行简单筛选可以提供信息,以免将InfluxDB用作主要数据仓库。
InfluxDB应该很适合我的项目任务,但是如实践所示,该数据库无法满足需求,并且混乱很多。
您已经在项目存储库中找到了2.0.0-beta版本,希望在第二个版本中会有重大改进。 同时,我将学习TimescaleDB文档。