在报告的第一部分中 ,我们概述了如何衡量文档的质量及其开发的有效性。 现在,深入了解计数指标的详细信息。
技术文档开发服务主管Yuri Nikulin说。
首先,让我们定义一下性能。 在传统意义上, 这是产生单位输出所花费的时间或单位时间所产生的输出量 。
例如,这是每月生产的电话数量或生产数千个电话所需的时间。 问题产生了如何衡量我们部门从事的智力劳动。
如果我们使用经典方法评估生产力,则可以计算每天,每周和每月写入多少文档,页面或单词。 这将有助于估计将来制作文档的潜在时间,但不会回答有关生产率的问题。 毕竟,我们绝对不希望通过作家写的字数来评估作家的效能。 因此,我们决定从计划计数的指标要求开始。
我们确定了一些选择指标的标准:
- 透明性 计算指标和解释结果的方法不仅对我们而且对客户也应明确。
- 数据可用性。 包括过去任何时期的数据,以便提出假设并尝试通过历史数据对其进行确认。
- 能够自动计数。 我们绝对不想手工计算指标。
结果,我们意识到,计算性能指标的理想对象是Tracker中的任务。 它符合我们为指标设置的所有要求。
我们的数据源是Yandex.Tracker。 它非常灵活,可以轻松地自定义我们的任务。 它已经具有所有必要的数据,因为我们每天都使用此工具。 而且Tracker还具有API,这意味着您可以使用此信息并自动执行流程。
因此,我们有一个计划进行。
设置队列和任务
您首先需要选择队列,任务层次,它们的类型和状态。
Katya Kunenko在报告“ 准备用户文档的工具 ”中对此进行了详细描述。 我们将简要讨论我们自己使用的排队和任务。
Queue列
我们有三行内容,它们实质上反映了我们的目标受众。

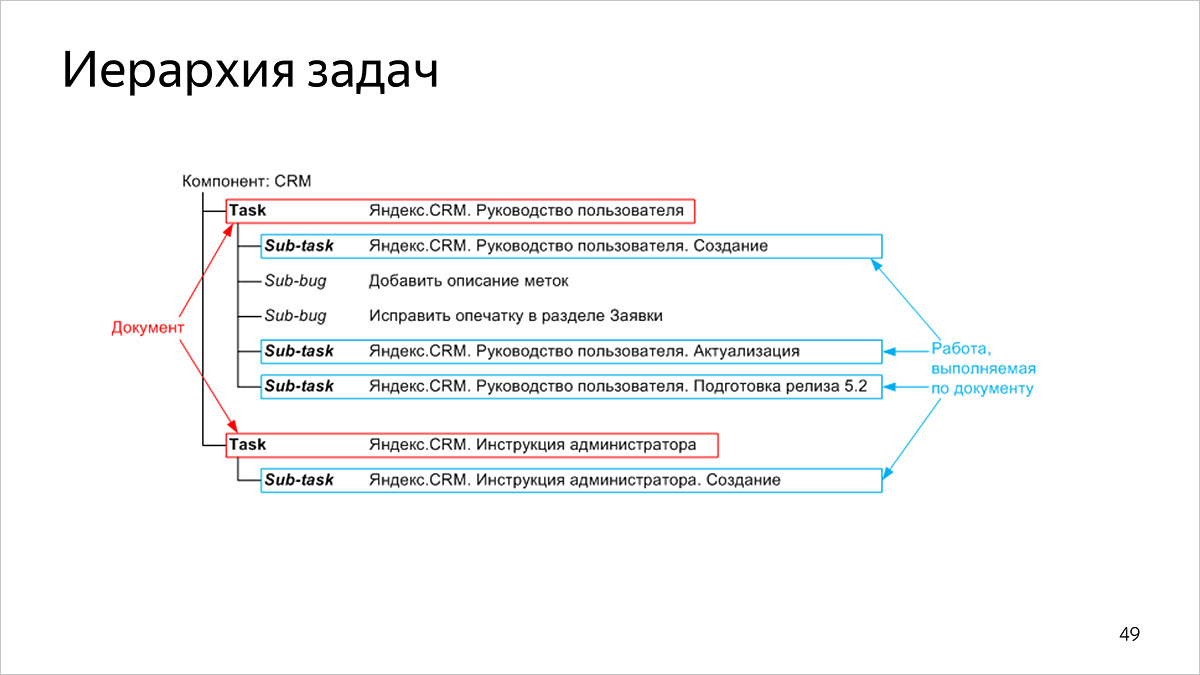
任务层次
我们的任务有两个层次的结构:
- 在最高级别,任务对应于已发布的文档,
- 在较低级别,任务与文档上的工作相对应。
任务的类型和状态
任务的类型和状态不仅使我们能够对工作的类型及其当前状态进行分类,而且还可以将我们的指标与各节一起考虑。
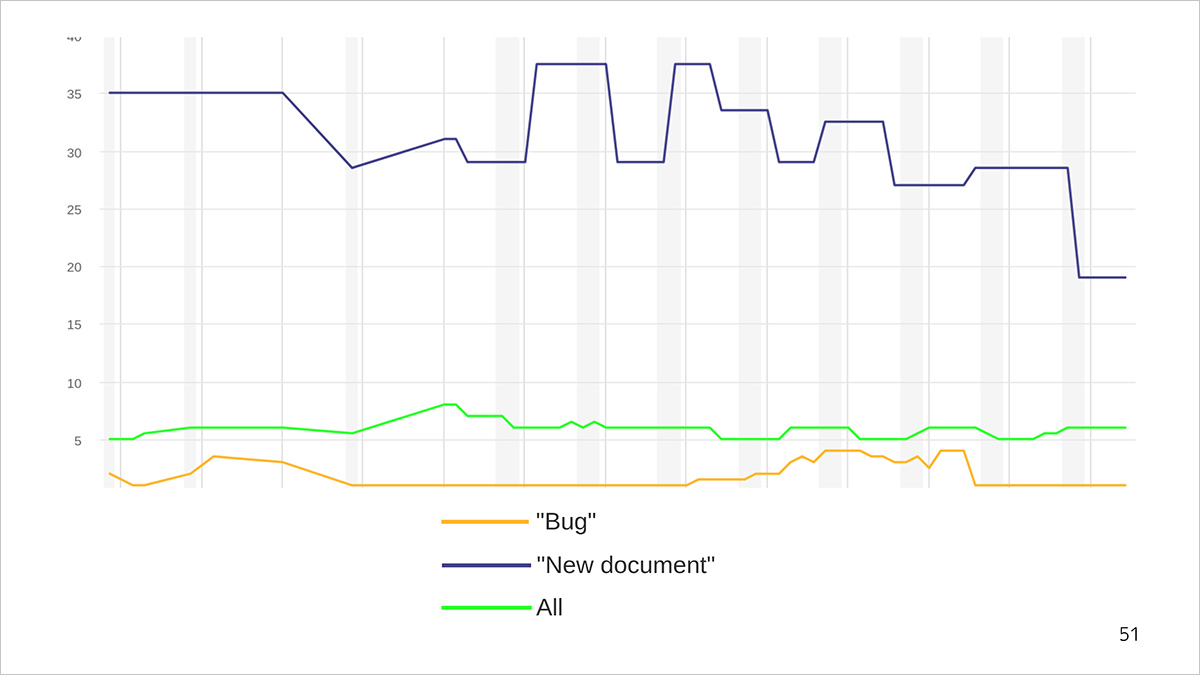
完成任务的时间表。 蓝线是文档的平均生产时间,橙色是修复错误的时间,绿色是完成所有类型任务的平均时间。
我们将以图为例。 例如,一个错误在1-5天内得到修复,并且编写新文档需要30到40天。 同时,我们编写新文档的频率要低于补充旧文档或纠正错误的频率。 因此,任何类型的任务(绿线)的平均执行时间对于bug来说都太长,对于新文档来说太短了。 在它的帮助下,我们对解决问题的速度只有一个一般的认识。
由于我们考虑指标是为了优化流程,因此我们需要研究更精确的内容:例如,解决“错误”或“新文档”问题已有多长时间。 并且可以查看所有类型的平均值以跟踪总体趋势。
我们使用了这类任务集。
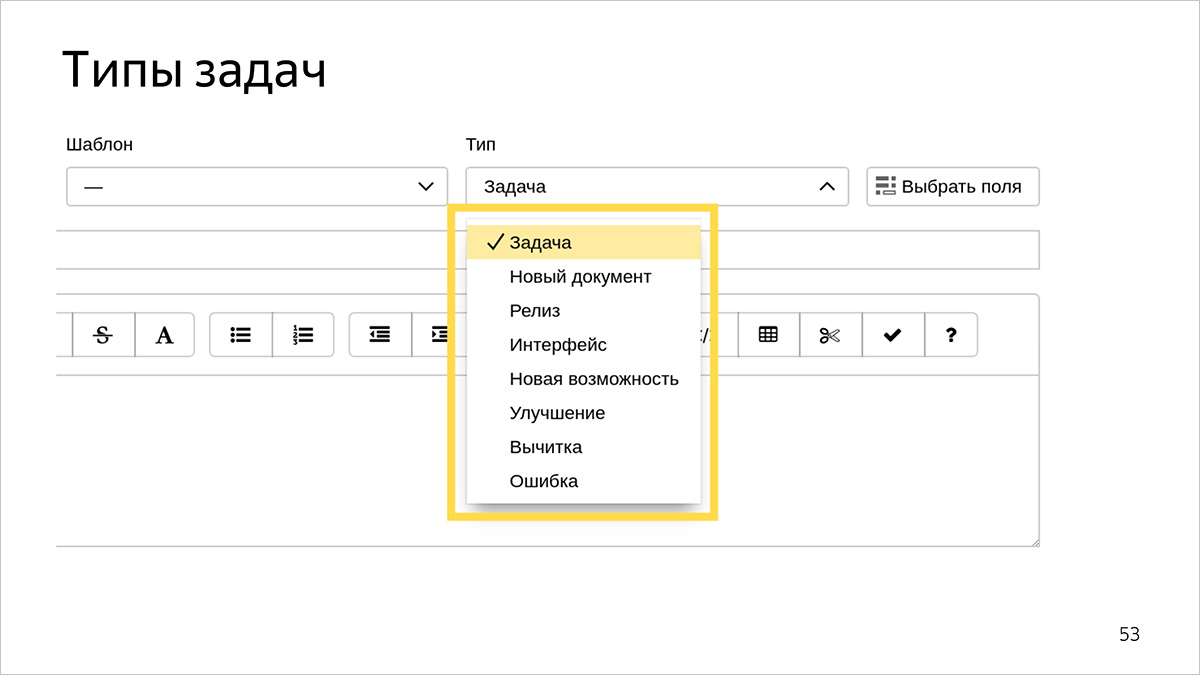
状态多于类型,因为工作流需要这样做。
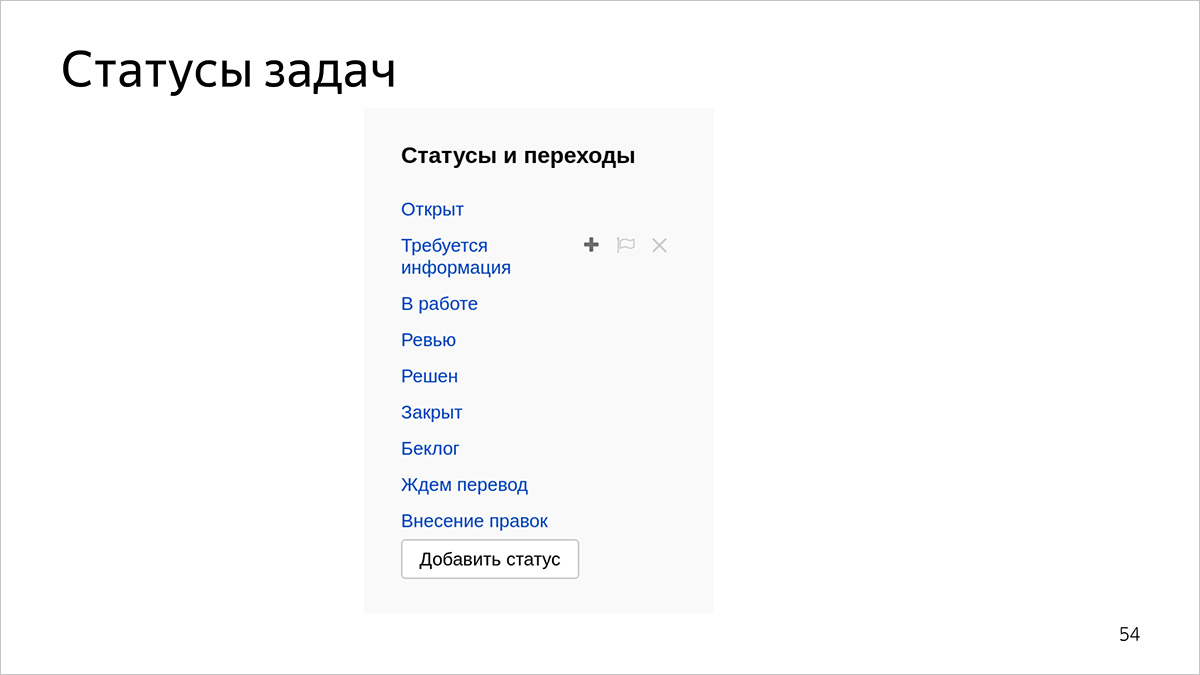
如果类型和状态比较明确,并且类型和状态不太多,则使用它们会更容易。 否则,表演者可能会感到困惑。
如何考虑绩效指标
在最后一部分中,我们说我们进行了一项研究,并从136个文档中选择了20个文档指标。其中六个是性能指标。

计算指标有两个方面。
- 计算切片指标。 上面,我们告诉了它是什么以及为什么对我们很重要。
- 计算平均值。
计算平均值的经典方法是汇总所有指标并除以它们的数量。 这种方法并不总是很好,因为它考虑了退化的情况。 例如,我们知道我们一天中修复的大多数错误。 但是在某些情况下(例如,机票遗失或员工辞职),情况会变得更糟。 假设在审查期间我们有六个错误。 我们决定一天5天,每115天一次。事实证明,平均错误修复时间为20天。 但是这个数字并不能反映现实:我们几乎总是纠正当天的错误,一张长票会严重影响这一指标。
在这种情况下, 百分位数可以解决。 这是最大值(在我们的示例中为指标),适合指定比例的对象。 例如,第80个百分位数的值不超过样本中对象的80%。 在我们的情况下,该值将为1,因为83%的对象未超过该值。
这里出现第三个平面-我们计算指标的时间。 我们几乎所有的指标都在30天内计算在内。

我们考虑如下削减指标:
- 首先所有的线,
- 然后我们轮流切
- 然后我们详细说明:我们为所有类型的任务削减了队列。
度量标准的每个后续部分都会细化前一个部分。 所有队列,任务类型和状态的平均值给出了一个概括的概念。 然后,我们考虑各个队列的值,以了解技术,用户或内部文档的情况。 在最后一个最详细的级别上,我们正在处理“队列+类型和状态”行。
进一步,我们将说明我们如何考虑绩效指标。
已完成任务数

我们考虑:根据间隔[31天前; 昨天]。
工作量
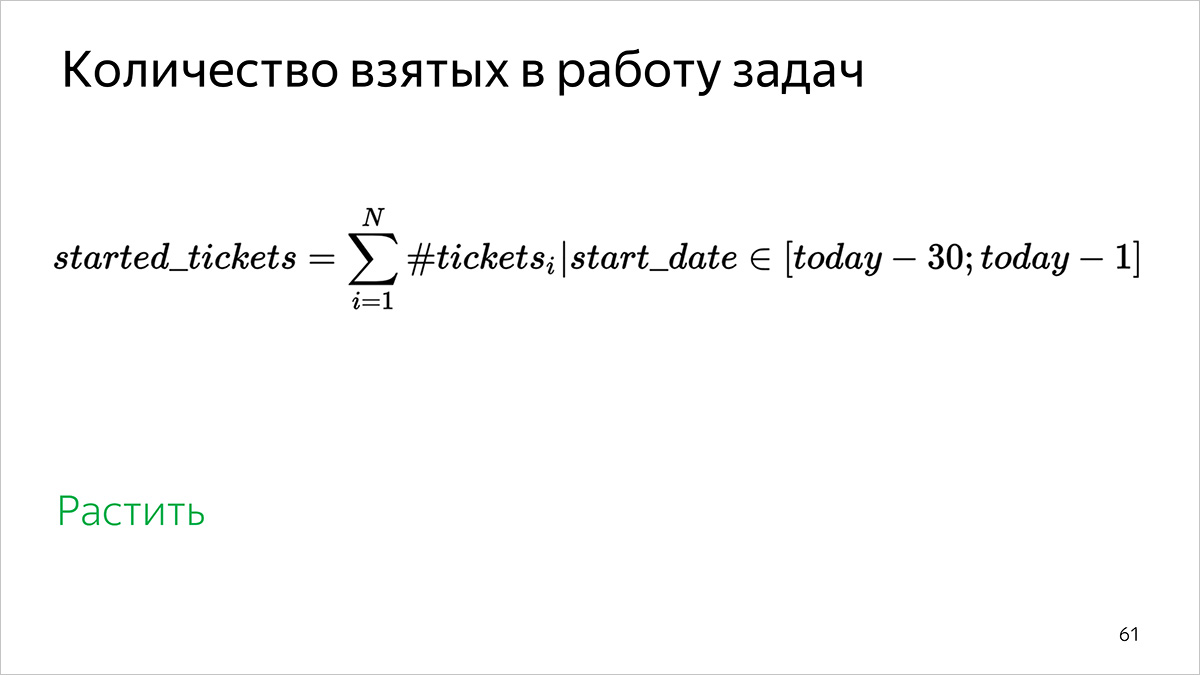
我们考虑:根据开始工作的时间间隔[31天前; 昨天]。
招聘前的天数

我们认为:
- 对于在指定时间段内(在[31天前;昨天]中的跟踪器中的开始日期)在指定时间段内工作的每个任务,我们考虑语句(字段创建日期)与任务开始(字段开始日期)之间经过的整天数。 。
- 我们总结了第一步中获得的所有值。
- 我们将收到的金额除以我们完成第一项任务的数量。
对于百分位,省略第3项,将值按升序排序,并选择与给定百分位相对应的值。
完成天数
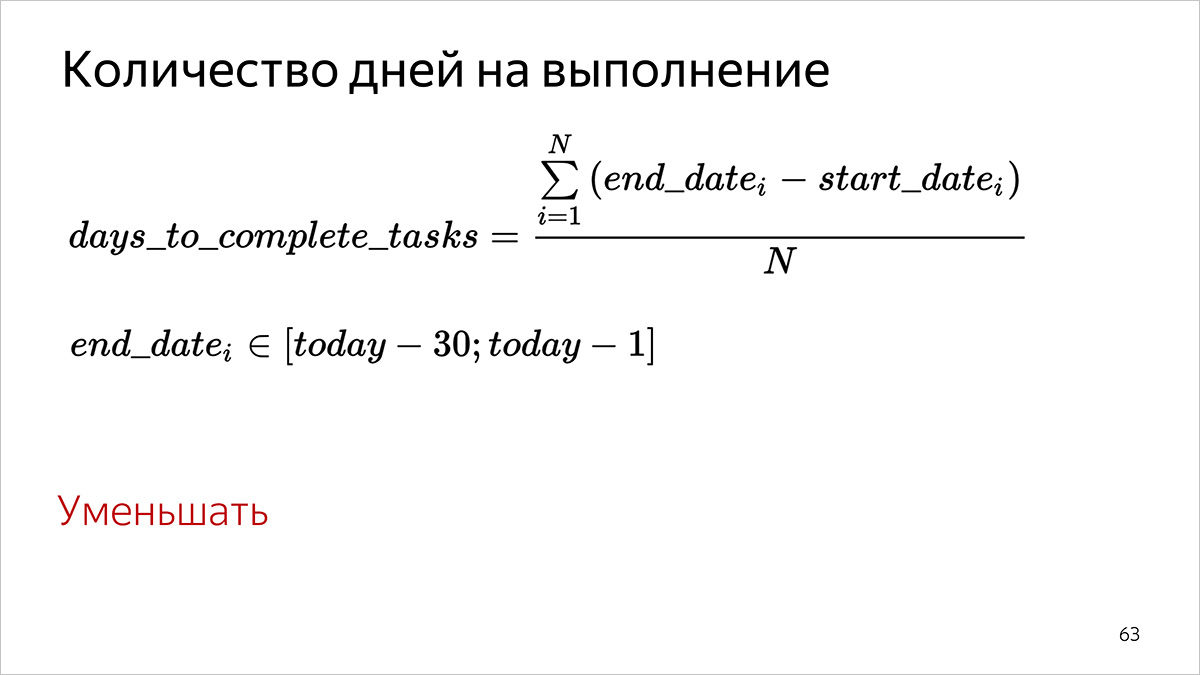
我们考虑。
- 对于在指定时间段内(在[31天前;昨天]间隔内的跟踪器中的结束日期)完成的每个任务,我们考虑工作开始(字段开始日期)与任务(字段结束日期)之间经过的整天数。
- 我们总结了第一步中获得的所有值。
- 我们将收到的金额除以我们完成第一项任务的数量。
对于百分位,省略第3项,将值按升序排序,并选择与给定百分位相对应的值。
无反应的任务数超过14天

我们相信:通过14天以上没有发生任何事情的任务数量。 由“跟踪器”中的更新字段确定:该字段值应小于“昨天-14天”。
技术债务

我们考虑的是:通过在跟踪器中设置了待办事项状态的任务数。
绩效指标计算的技术实施
在顶层,度量标准计数系统由以下组件和信息链接组成。
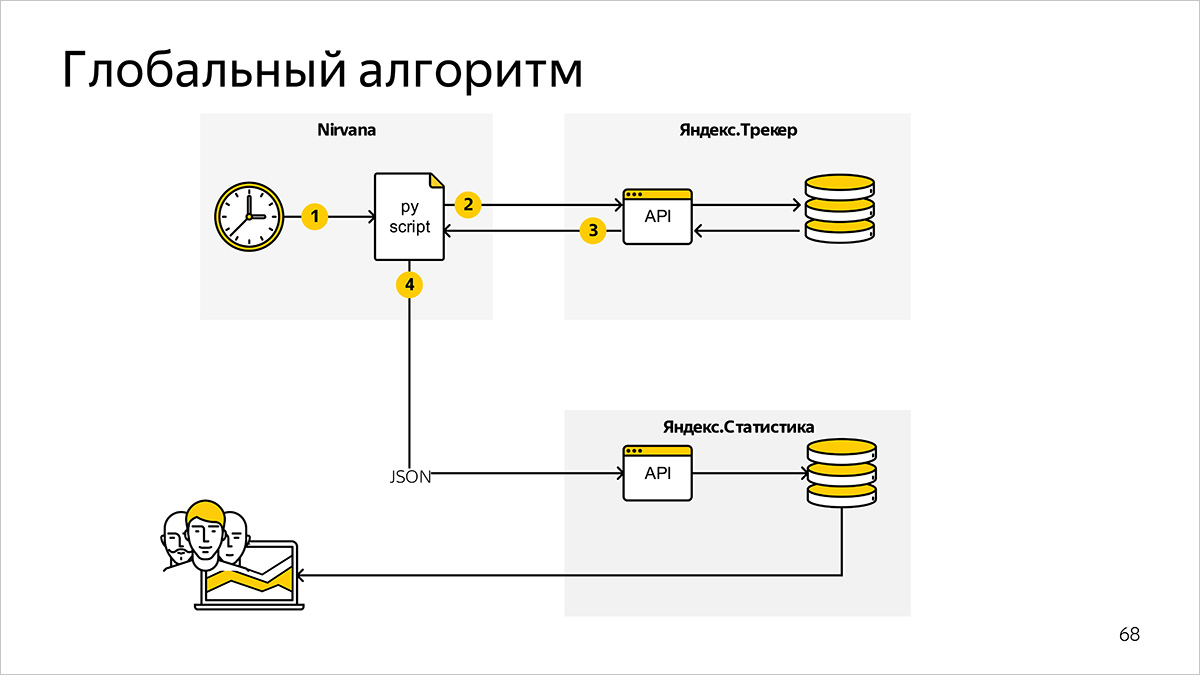
计划的公制计数程序
我们使用Nirvana (通用计算平台)。 它正式描述了进程启动的顺序。 Nirvana与内部调度程序(调度程序)一起用一组bash脚本和cron代替了我们。
用Python编写的程序会定期运行,并请求计算指标所需的数据。
任务设定系统
在我们的案例中,用于计算指标的数据存储在Yandex.Tracker中。 作为数据的接口,我们使用Yandex.Tracker Python API-这是HTTP API的包装,可以更快,更轻松地接收适合进一步处理的数据结构中的信息。
您可以选择具有合适API的便捷系统,例如Jira。
图表准备系统
根据来自Yandex.Tracker的数据计算指标后,我们的程序将生成JSON文件并将其传输到Yandex.Statistics内部服务以绘制图形。
您可以使用某种可以构建图形的JS库。 Habré上提供了一些类似解决方案的概述:
15个最佳JavaScript库
在下一部分中,我们将描述如何考虑用户文档的质量指标。