你好 我叫Ibadov Ilkin,我是乌拉尔联邦大学的学生。
在本文中,我想谈谈我使用Google验证码自动解决方案“ reCAPTCHA”的经验。 我想提前警告读者,在撰写本文时,原型无法像标题所示那样高效地工作,但是,结果表明所采用的方法能够解决问题。
可能他一生中的每个人都遇到过验证码:从图片中输入文字,解决简单的表达式或复杂的方程式,选择汽车,消火栓,行人过路处...保护资源免受自动化系统的侵害是必要的,并且在安全性方面发挥着重要作用:验证码可防御DDoS攻击,自动注册和发布,解析,可防止为帐户选择垃圾邮件和密码。
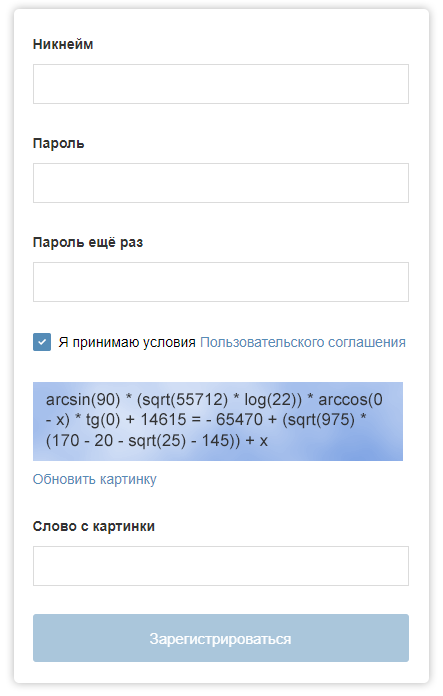 “Habré”上的注册表格可能带有这样的验证码。
“Habré”上的注册表格可能带有这样的验证码。随着机器学习技术的发展,验证码的性能可能会受到威胁。 在本文中,我描述了一个程序的关键点,该程序可以解决在Google reCAPTCHA中手动选择图像的问题(很幸运,到目前为止并不总是如此)。
要获得验证码,必须解决以下问题:确定所需的验证码类别,检测和分类对象,检测验证码单元,模拟人类活动来解决验证码(光标移动,单击)。
为了搜索图像中的对象,使用了经过训练的神经网络,可以将其下载到计算机并识别图像或视频中的对象。 但是要解决验证码,仅检测对象是不够的:您需要确定单元格的位置并找出要选择的单元格(或根本不选择单元格)。 为此,使用了计算机视觉工具:在这项工作中,这是著名的
OpenCV库 。
为了在图像中找到对象,首先,图像本身是必需的。 我使用
PyAutoGUI模块获得了屏幕一部分的屏幕截图,其尺寸足以检测对象。 在屏幕的其余部分,我显示用于调试和监视程序过程的窗口。
物体检测
对象的检测和分类是神经网络的作用。 允许我们使用神经网络的库称为“
Tensorflow ”(由Google开发)。 如今,
有许多不同的训练有素的模型供您选择,
以使用不同的数据 ,这意味着它们都可以返回不同的检测结果:有些模型可以更好地检测物体,有些模型可以更好地检测物体。
在本文中,我正在使用ssd_mobilenet_v1_coco模型。 所选模型在
COCO数据集上进行了训练,该数据集突出显示了90种不同的类别(从人和汽车到牙刷和梳子)。 现在,还有其他模型在相同的数据上训练,但参数不同。 此外,该模型具有最佳性能和精度参数,这对于台式计算机很重要。 消息人士说,一帧300 x 300像素的处理时间为30毫秒。 在“ Nvidia GeForce GTX TITAN X”上。
神经网络的结果是一组数组:
- 带有检测到的对象的类别列表(它们的标识符);
- 带有检测到的物体等级的列表(百分比);
- 以及检测到的对象的坐标列表(“框”)。
这些数组中元素的索引彼此对应,即:对象类别数组中的第三个元素对应于检测到的对象“盒子”数组中的第三个元素和对象评级数组中的第三个元素。
 所选模型可让您实时检测90种类别的对象。
所选模型可让您实时检测90种类别的对象。细胞检测
“ OpenCV”使我们能够使用称为“
circuits ”的实体进行操作:只能通过“ OpenCV”库中的“ findContours()”函数来检测它们。 有必要将二进制图像提交到此类函数的输入,可以
通过阈值转换函数获得 :
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY) contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
设置阈值变换函数的参数的极值后,我们还摆脱了各种噪声。 同样,为了使不必要的小元素和噪音最小化,可以应用
形态转换 :侵蚀(压缩)和积聚(膨胀)功能。 这些功能也是OpenCV的一部分。 转换后,选择轮廓的顶点数为四个的轮廓(之前已对轮廓执行了
逼近功能)。
 在第一个窗口中,阈值转换的结果。 第二个是形态转换的例子。 在第三个窗口中,已经选择了单元格和验证码上限:以编程方式突出显示颜色。
在第一个窗口中,阈值转换的结果。 第二个是形态转换的例子。 在第三个窗口中,已经选择了单元格和验证码上限:以编程方式突出显示颜色。经过所有转换后,不是单元的轮廓仍会落入带有单元的最终阵列中。 为了滤除不必要的噪声,我根据轮廓的长度(周长)和面积值进行选择。
实验表明,感兴趣的电路的值在360至900单位范围内。 在屏幕上以15.6英寸的对角线和1366 x 768像素的分辨率选择此值。 此外,可以根据用户屏幕的大小来计算轮廓的指示值,但是在创建的原型中没有这样的链接。
所选择的检测单元格方法的主要优点是,我们不必关心网格的外观以及验证码页面上将显示多少个单元格:8、9或16。
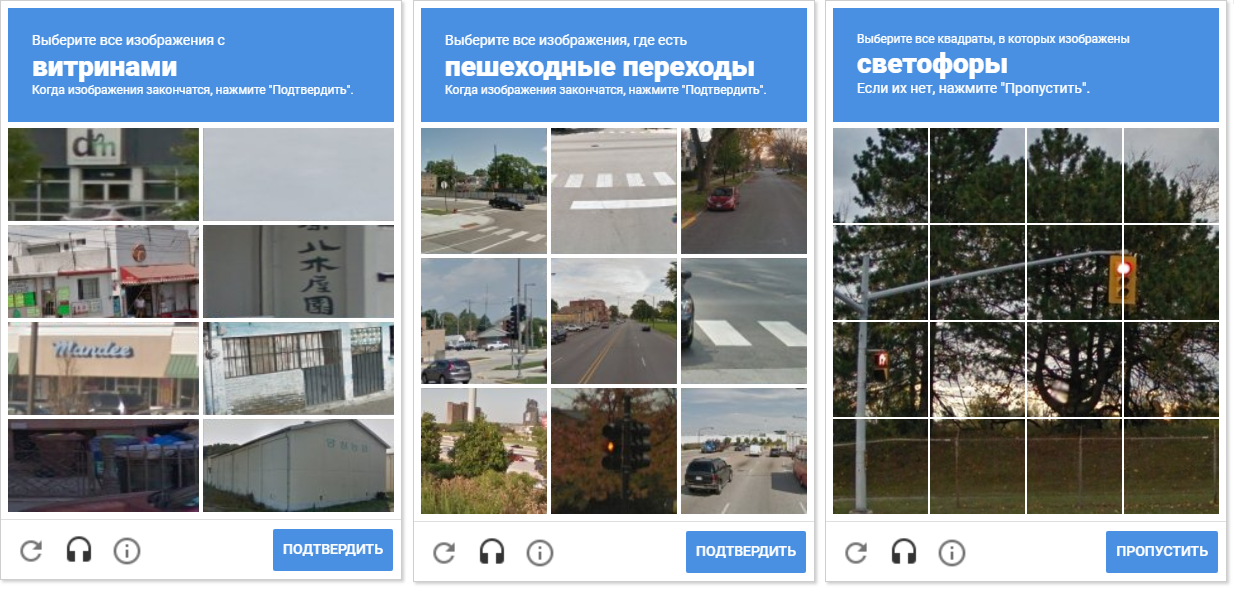 该图显示了各种验证码网。 请注意,单元之间的距离不同。 将细胞彼此分离允许形态压缩。
该图显示了各种验证码网。 请注意,单元之间的距离不同。 将细胞彼此分离允许形态压缩。检测轮廓的另一个优点是OpenCV允许我们检测其中心(我们需要它们来确定运动和鼠标单击的坐标)。
选择要选择的单元格
有了一个具有清晰的CAPTCHA细胞轮廓的阵列而没有不必要的噪声电路,我们可以遍历每个CAPTCHA细胞(术语“ OpenCV”中的“电路”),并检查它是否与从神经网络接收到的物体的“盒子”相交。
为了确定这一事实,使用了将检测到的“盒子”转移到类似于电池的电路的方法。 但是这种方法被证明是错误的,因为当对象位于像元内部时,这种情况不被视为相交。 自然,这种细胞在验证码中并不突出。
通过将每个单元格的轮廓(用白色填充)重新绘制到黑色板上可以解决该问题。 以类似的方式,获得具有对象的框架的二进制图像。 提出了一个问题-现在如何确定单元与对象的阴影框相交的事实? 在具有单元格的数组的每次迭代中,对两个二进制图像执行析取运算(逻辑或)。 结果,我们得到了一个新的二进制图像,其中相交的区域将被突出显示。 即,如果存在这样的区域,则对象的单元格与框架相交。 以编程方式,可以使用“
.any() ”方法进行这种检查:如果数组中至少有一个等于1的元素,则返回“ True”;如果没有单位,则返回“ False”。
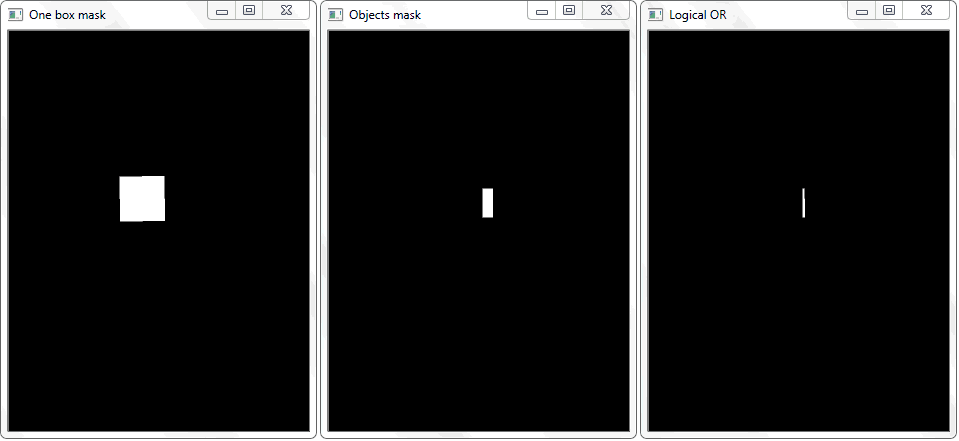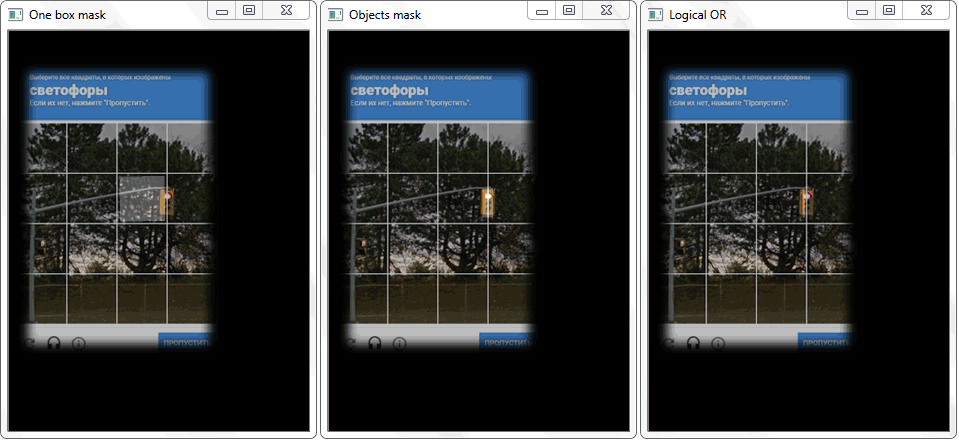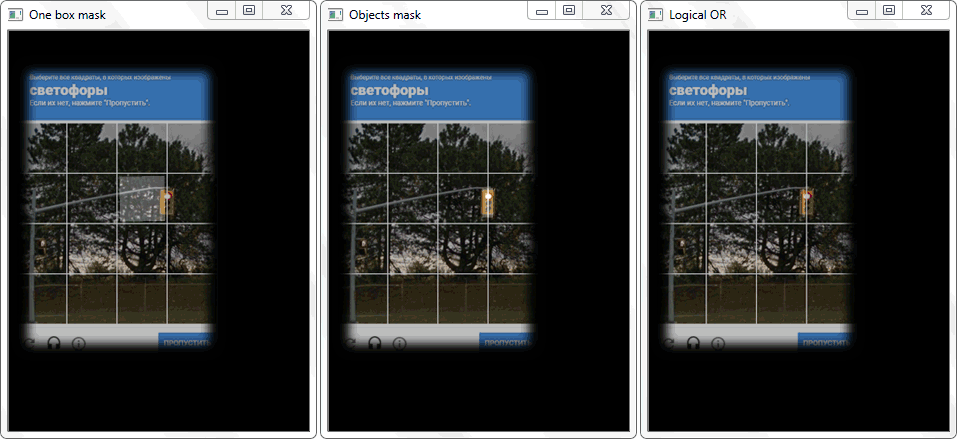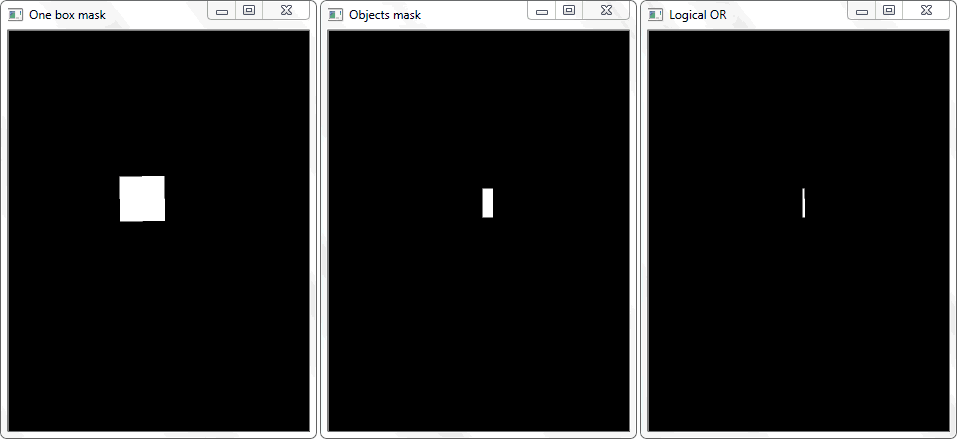 在这种情况下,图像“逻辑或”的函数“ any()”将返回true,从而确定像元与被检测对象的框区域相交的事实。
在这种情况下,图像“逻辑或”的函数“ any()”将返回true,从而确定像元与被检测对象的框区域相交的事实。管理学
多亏了“ win32api”模块,“ Python”中的光标控制才可用(但是,后来证明已经导入到项目中的“ PyAutoGUI”也知道如何执行此操作)。 按下和释放鼠标左键,以及将光标移动到所需的坐标是由win32api模块的相应功能执行的。 但是在原型中,它们被包装在用户定义的函数中,以提供对光标移动的视觉观察。 这会对性能产生负面影响,仅用于演示。
在开发过程中,出现了以随机顺序选择细胞的想法。 这很可能没有意义(出于明显的原因,Google不会给我们提供有关验证码操作机制的评论和说明),但是以一种混乱的方式在单元格中移动光标看起来会更有趣。
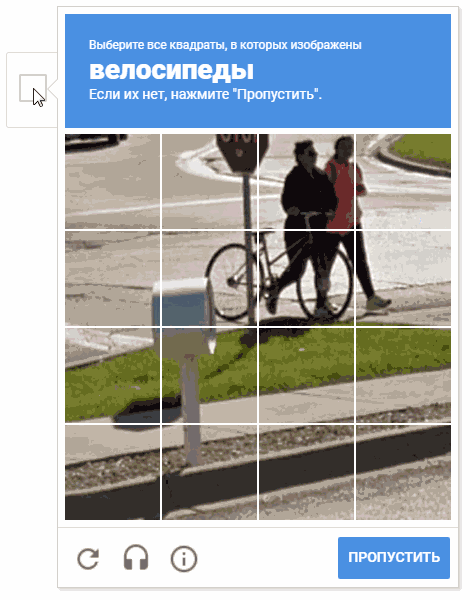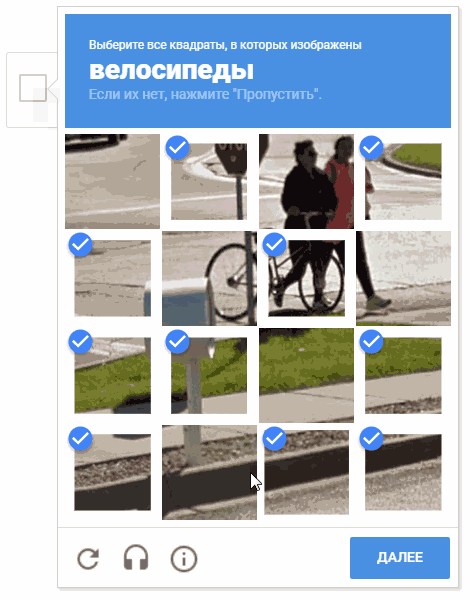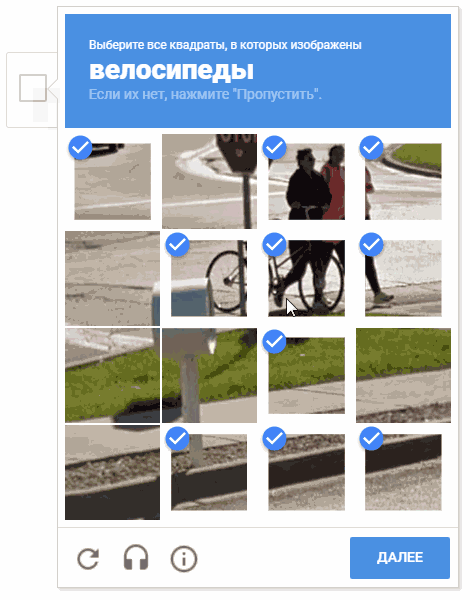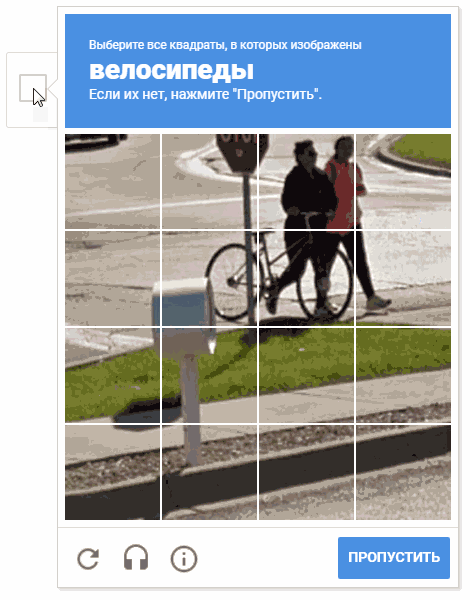 在动画上,结果是“ random.shuffle(boxesForSelect)”。
在动画上,结果是“ random.shuffle(boxesForSelect)”。文字识别
为了将所有可用的开发组合成一个整体,还需要一个链接:一个验证码所需的类别识别单元。 我们已经知道如何识别和区分图像中的不同对象,我们可以单击任意的验证码单元格,但是我们不知道要单击哪个单元格。 解决此问题的方法之一是从验证码标题中识别文本。 首先,我尝试使用光学字符识别工具“
Tesseract-OCR ”实现文本识别。
在最新版本中,可以直接在安装程序窗口中安装语言包(以前是手动完成的)。 将Tesseract-OCR安装并导入到我的项目中后,我尝试从验证码头中识别文本。
不幸的是,结果根本没有打动我。 我决定将标题中的文本突出显示为粗体并进行合并是有原因的,因此我尝试对图像进行各种转换:二值化,缩小,扩展,模糊,失真和调整大小操作。 不幸的是,这并没有给出很好的结果:在最佳情况下,仅确定了部分班级字母,当结果令人满意时,我应用了相同的转换,但对其他大写字母(具有不同的文本)进行了转换,结果再次变得很糟糕。
 Tesseract-OCR瓶盖的识别通常导致效果不理想。
Tesseract-OCR瓶盖的识别通常导致效果不理想。不可能明确地说“ Tesseract-OCR”不能很好地识别文本,事实并非如此:该工具可以更好地处理其他图像(而不是验证码)。
我决定使用第三方服务,该服务提供免费使用它的API(需要注册和接收电子邮件地址的密钥)。 该服务每天最多只能识别500个,但是在整个开发期间,我都没有遇到任何限制方面的问题。 相反:我将标头的原始图像提交给服务(不进行任何绝对转换),结果给我留下了深刻的印象。
该服务中的单词几乎没有错误地返回(通常甚至是小写的单词)。 而且,它们以非常方便的格式返回-由换行符和换行符分隔。 在所有图像中,我只对第二行感兴趣,因此我直接访问了它。 这不禁让我们感到高兴,因为这种格式使我无需准备一行:我不必剪切整个文本的开头或结尾,进行“修剪”,替换,使用正则表达式并在线执行其他操作(旨在突出一个单词) (有时是两个!)-一笔不错的奖金!
text = serviceResponse['ParsedResults'][0]['ParsedText']
能够识别文本的服务几乎永远不会对类名犯错误,但是我仍然决定保留部分类名以免出现可能的错误。 这是可选的,但我注意到“ Tesseract-OCR”在某些情况下会错误地识别出从中间开始的单词结尾。 此外,这种方法消除了使用长类名或两个单词名的情况下的应用程序错误(在这种情况下,该服务将返回3行,而不是3行,而在第二行中找不到该类的全名)。
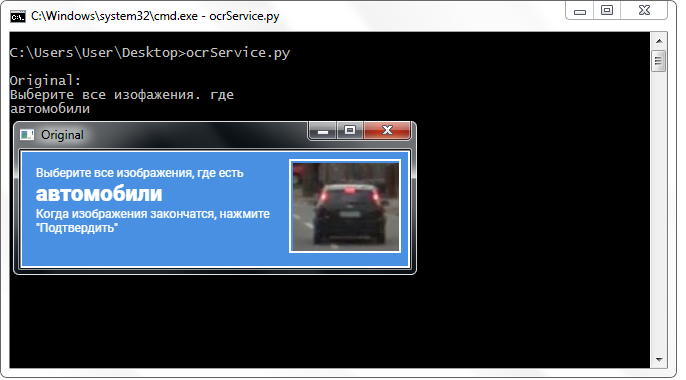 第三方服务可以很好地识别类名称,而无需对图像进行任何转换。
第三方服务可以很好地识别类名称,而无需对图像进行任何转换。合并
从标题获取文本是不够的。 需要将其与可用模型类的标识符进行比较,因为在类数组中,神经网络会准确地返回类标识符,而不是看上去的名称。 通常,在训练模型时,会创建一个文件,在其中比较类名及其标识符(也称为“标签图”)。 我决定简化操作并手动指定类标识符,因为验证码仍然需要俄语类(顺便说一下,可以更改):
if "" in query:
上面描述的所有内容都在程序的主循环中复制:确定对象的帧,单元格及其相交处,光标移动并单击。 当检测到标题时,将执行文本识别。 如果神经网络无法检测到所需的类别,则最多执行5次图像的任意移位(即,更改了神经网络的输入),如果仍然没有检测到,则单击“跳过/确认”按钮(类似地检测其位置)检测细胞和盖帽)。
如果您经常解决验证码问题,那么当所选单元格消失时,您可以观察图片,并且慢慢出现一个新的位置。 由于原型被编程为在选择所有单元格之后立即转到下一页,因此我决定暂停3秒,以排除单击“下一步”按钮而没有检测到缓慢出现的单元格上的对象。
如果本文不包含最重要的内容(成功通过验证码的复选标记)的说明,则本文将不完整。 我决定通过简单的
模板比较就可以做到这一点。 值得注意的是,模式匹配还远不是检测对象的最佳方法。 例如,我必须将检测灵敏度设置为“ 0.01”,以便该功能停止在所有事物上都看到滴答声,而在确实有滴答声时才看到。 同样,我使用了一个空的复选框,该复选框满足了用户的要求,并且验证码从此开始(验证没有问题)。
结果
所有上述操作的结果是一个应用程序,我在“
Toaster ”上测试了该应用程序的性能:
值得一提的是,该视频并非是第一次尝试拍摄的,因为我经常面临选择模型中未包含的类(例如,人行横道,楼梯或商店橱窗)的需求。
“ Google reCAPTCHA”会向网站返回一定的值,显示“您是机器人”的方式,而网站管理员可以反过来设置传递此值的阈值。 烤面包机上设置的验证码阈值可能相对较低。 这说明了该程序很容易通过验证码,尽管它两次被误认为没有从验证码的第一页看到交通信号灯和第四页的消火栓。
除烤面包机外,还在
reCAPTCHA官方
演示页面上进行了实验。 结果,人们注意到,在多次错误检测(和未检测到)之后,即使对于一个人而言,也很难获得验证码:需要新的类(例如拖拉机和棕榈树),样本中出现没有物体的细胞(几乎是单调的颜色),并且页数急剧增加,经历。
当我决定尝试单击随机单元以防止未检测到对象时(由于模型中没有它们),这一点尤其明显。 因此,我们可以肯定地说随机点击不会导致问题的解决。 为了摆脱审查员的这种“障碍”,我们重新连接了Internet连接并清除了浏览器数据,因为无法通过这样的测试-几乎是无止境的!
 如果您怀疑自己的人性,那么这样的结果是可能的。
如果您怀疑自己的人性,那么这样的结果是可能的。发展历程
如果本文和应用程序引起读者的兴趣,我将很高兴以更详细的形式继续其实施,测试和进一步的描述。
它是关于查找不属于当前网络的类的,这将大大提高应用程序的效率。 目前,迫切需要至少识别以下类:人行横道,商店橱窗和烟囱-我将告诉您如何重新训练模型。 在开发期间,我列出了最常见的类的简短列表:
- 人行横道;
- 消火栓;
- 商店橱窗
- 烟囱
- 汽车;
- 巴士
- 交通灯;
- 脚踏车
- 运输工具;
- 楼梯
- 迹象。
可以同时使用多个模型来提高对象检测的质量:这可能会降低性能,但会提高准确性。
提高对象检测质量的另一种方法是更改输入到神经网络的图像:在视频中,您可以看到,当未检测到对象时,我会进行多次任意图像移位(水平和垂直方向上10像素以内),并且通常此操作使您可以查看以前的对象未检测到。
图像从小方块到大方块(最多300 x 300像素)的增加也导致检测到未检测到的物体。
 左侧未找到任何对象:侧面为100像素的原始正方形。 在右侧,检测到总线:放大的正方形,最大300 x 300像素。
左侧未找到任何对象:侧面为100像素的原始正方形。 在右侧,检测到总线:放大的正方形,最大300 x 300像素。另一个有趣的转换是使用OpenCV工具删除图像上的白色网格:由于这个原因,有可能在视频中未检测到消防栓(此类存在于神经网络中)。
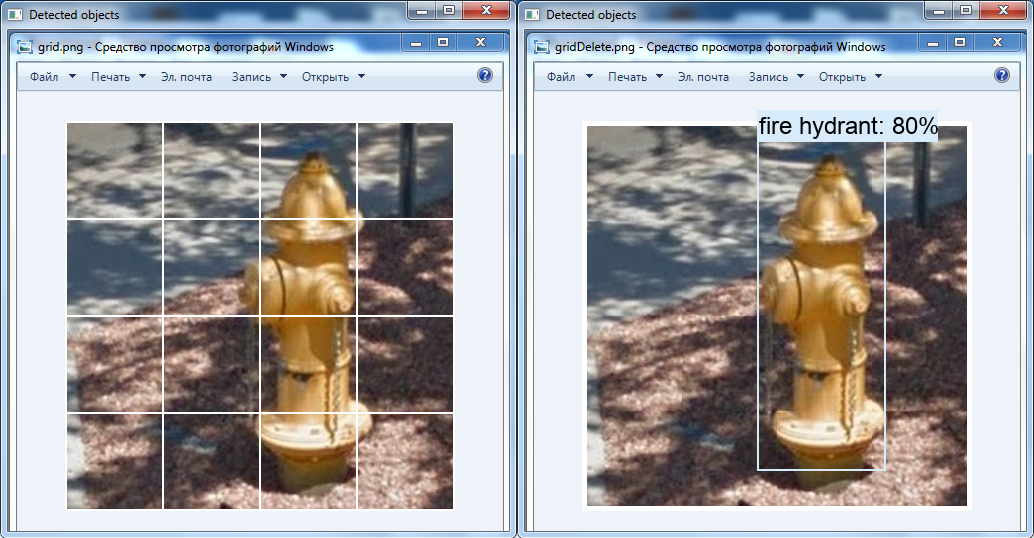 左侧是原始图像,右侧是在图形编辑器中更改的图像:删除网格,将单元格彼此移动。
左侧是原始图像,右侧是在图形编辑器中更改的图像:删除网格,将单元格彼此移动。总结
在本文中,我想告诉您,验证码可能不是针对机器人的最佳防护,并且很可能在不久的将来,需要一种新的针对自动化系统的防护方法。
所开发的原型,即使处于不完整的状态,也证明了使用神经网络模型中所需的类并在图像上应用转换,可以实现不应自动化的过程的自动化。
另外,我想提请Google注意以下事实:除了本文所述的避免人为验证的方法之外,还有
另一种 转录音频样本的方法。 我认为,现在有必要采取与提高针对机器人的软件产品和算法的质量有关的措施。
从材料的内容和本质上看,我似乎不喜欢Google,尤其是reCAPTCHA,但这远非如此,如果有下一个实现,我将告诉您原因。
进行开发和演示,以改进教育并改进旨在确保信息安全的方法。
谢谢您的关注。