帕维尔本人告诉维基百科,维基百科的历史已经在维基百科上。 似乎每个人都已经认识她。 Pavel
在2010年就谈到了HighLoad ++网站的内部,架构和设计。 从那时起,许多服务器泄漏了,因此我们将更新信息:我们进行剖析,深入了解内部,权衡-我们从技术角度来看VK设备。
 Alexey Akulovich
Alexey Akulovich (
AterCattus )是VKontakte团队的后端开发人员。 该报告的笔录是对平台,基础架构,服务器及其之间的交互的常见问题的集体回答,但与开发(即
硬件)无关。 另外-有关数据库以及VK所处的位置,有关收集日志并监视整个项目。 细节剪下。
四年多来,我一直在执行与后端相关的各种任务。
- 下载,存储,处理,分发媒体:视频,实时流,音频,照片,文档。
- 基础架构,平台,开发人员监视,日志,区域缓存,CDN,专有RPC协议。
- 与外部服务集成:推送邮件,解析外部链接,RSS feed。
- 帮助同事解决各种问题,以获取您不得不陷入未知代码中的答案。
在这段时间里,我参与了该网站的许多工作。 我想分享这种经验。
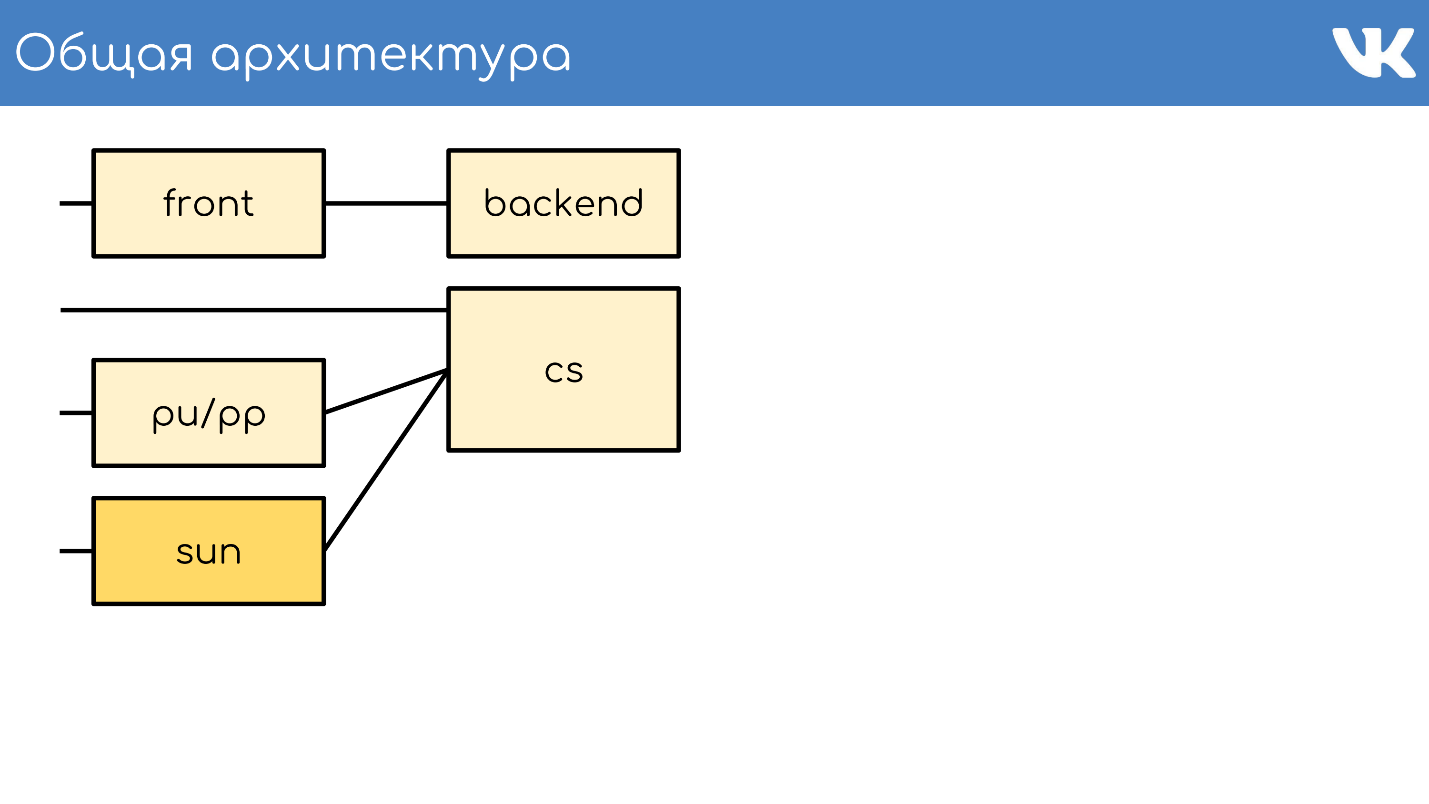
通用架构
与往常一样,一切都从一个服务器或一组接受请求的服务器开始。
前置服务器
前端服务器通过HTTPS,RTMP和WSS接受请求。
HTTPS是对网站的主要和移动Web版本的请求:vk.com和m.vk.com,以及我们API的其他官方和非官方客户端:移动客户端,即时通讯程序。 我们具有
RTMP流量,用于使用单独的前端服务器进行实时广播和用于Streaming API的
WSS连接。
对于HTTPS和WSS,
nginx安装在服务器上。 对于RTMP广播,我们最近切换到了自己的
kive解决方案,但这超出了报告的范围。 为了容错,这些服务器声明公用IP地址并作为组,以便在其中一台服务器出现问题的情况下,不会丢失用户请求。 对于HTTPS和WSS,这些相同的服务器会对流量进行加密,以承担其自身的CPU负载。
此外,我们将不再谈论WSS和RTMP,而仅谈论通常与Web项目相关的标准HTTPS请求。
后端
前端后面通常是后端服务器。 它们处理前端服务器从客户端收到的请求。
这些是运行HTTP守护程序的
kPHP服务器 ,因为HTTPS已被解密。 kPHP是根据
prefork模型工作的服务器:它启动主进程,一堆子进程,将监听套接字传递给它们,然后它们处理它们的请求。 同时,进程不会在用户的每个请求之间重新启动,而只是将它们的状态重置为初始零值状态(逐个请求),而不是重新启动。
负载分担
我们所有的后端都不是可以处理任何请求的庞大计算机池。 我们
将它们
分为不同的组 :常规,移动,api,视频,暂存...在另一组计算机上的问题不会影响其他所有人。 在视频出现问题的情况下,正在听音乐的用户甚至都不知道这些问题。 将请求发送到哪个后端由配置中位于前面的nginx解决。
指标收集和重新平衡
要了解每个组中需要多少辆汽车,我们
不依赖QPS 。 后端不同,它们具有不同的请求,每个请求具有不同的QPS计算复杂度。 因此,我们使用
服务器整体负载的
概念-CPU和perf 。
我们有成千上万个这样的服务器。 kPHP组在每个物理服务器上运行以利用所有内核(因为kPHP是单线程的)。
内容服务器
CS或Content Server正在存储 。 CS是一台服务器,用于存储文件,并且还处理上传的文件,主要Web前端为此提供的各种同步后台任务。
我们有成千上万个存储文件的物理服务器。 用户喜欢上传文件,我们喜欢存储和共享文件。 其中一些服务器被特殊的pu / pp服务器关闭。
//页
如果您在VK中打开了网络标签,那么您会看到pu / pp。

什么是pu / pp? 如果我们先关闭一台服务器,则有两种选择可用于将文件上传和下载到已关闭的服务器:
直接通过
http://cs100500.userapi.com/path或
通过中间服务器 http://pu.vk.com/c100500/pathPu是照片上传的历史名称,pp是照片代理 。 也就是说,一台服务器上传照片,另一台服务器上传。 现在,不仅可以加载照片,而且可以保留名称。
这些服务器
终止HTTPS会话,以从存储中删除处理器负载。 此外,由于在这些服务器上处理了用户文件,因此在这些计算机上存储的敏感信息越少越好。 例如,HTTPS加密密钥。
由于这些机器是由我们的其他机器关闭的,因此我们不能给它们提供“白色”的外部IP,而
给它们“灰色”的 IP。 因此,我们保存在IP池中,并保证保护计算机免受外部访问-根本没有IP可用。
通过共享IP的容错能力 。 在容错方面,该方案以相同的方式工作-几台物理服务器具有一个公共的物理IP,并且它们前面的一块铁决定了将请求发送到哪里。 稍后我将讨论其他选项。
有争议的一点是,在这种情况下,
客户端拥有较少的连接 。 如果多台计算机上有相同的IP-主机相同:pu.vk.com或pp.vk.com,则客户端浏览器对同时请求一个主机的数量有限制。 但是在无处不在的HTTP / 2中,我相信情况不再如此。
该方案的明显缺点是您必须通过另一台服务器
泵送所有流向存储
的流量 。 由于我们通过汽车来吸引流量,因此我们还不能以相同的方式(例如视频)来吸引大量流量。 我们直接进行传输-独立的直接连接,专门用于视频的各个存储库。 我们通过代理传输较轻的内容。
不久前,我们有了代理的改进版本。 现在,我将告诉您它们与普通的区别以及为什么有必要。
太阳
2017年9月,先前收购了Sun的甲骨文
解雇了大量Sun员工 。 可以说,此刻该公司不复存在。 为新系统选择一个名称后,我们的管理员决定对该公司表示敬意和尊重,并命名了新的Sun系统。 在我们之间,我们称之为“阳光”。
Pp有一些问题。
每个组一个IP是低效的缓存 。 多个物理服务器具有一个公共IP地址,并且无法控制请求将到达哪个服务器。 因此,如果不同的用户使用同一个文件,则在这些服务器上存在高速缓存时,该文件将驻留在每个服务器的高速缓存中。 这是一个非常低效的方案,但是什么也做不了。
结果,
我们无法分片内容 ,因为我们无法为此组选择特定的服务器-它们具有公共IP。 此外,由于某些内部原因,我们
没有机会将这些服务器放置在区域中 。 他们只站在圣彼得堡。
有了太阳,我们改变了选择系统。 现在我们有了
Anycast路由 :动态路由,Anycast,自检守护程序。 每个服务器都有自己的IP,但同时有一个公用子网。 一切都以这样的方式配置:在丢失一台服务器的情况下,流量会自动分散到同一组的其他服务器。 现在可以选择一个特定的服务器,
没有过多的缓存 ,并且不影响可靠性。
重量支撑 。 现在,我们有能力根据需要放置不同容量的汽车,并且在出现临时性问题的情况下,改变工作中的“太阳”的重量以减轻其负担,使它们“休息”并重新工作。
通过内容ID进行分片 。 关于分片的一个有趣的事情是,我们通常将内容分片,以便不同的用户通过相同的“ sun”跟踪同一文件,从而使他们拥有共同的缓存。
我们最近启动了Clover应用程序。 这是一个在线实时广播测验,演示者提问,用户通过选择选项进行实时响应。 该应用程序具有聊天功能,用户可以在其中进行泛洪。
超过10万人可以同时连接到广播。 他们都写了发送给所有参与者的消息,消息又是另一个化身。 如果有十万人在一个“太阳”中来到一个化身,那么它有时会滚过云层。
为了承受来自同一文件的大量请求,我们为某种内容提供了一种愚蠢的方案,该方案可将文件分布在该地区所有可用的“太阳”中。
太阳里面
反向代理到nginx,缓存在RAM或Optane / NVMe快速磁盘中。 示例:
http://sun4-2.userapi.com/c100500/path :
http://sun4-2.userapi.com/c100500/path链接到“ sun”,它位于第四个区域,即第二个服务器组。 它关闭物理上位于服务器100500上的路径文件。
快取
我们在架构方案中增加了一个节点-缓存环境。

下面是
区域缓存的布局,大约有20个。 这些正是缓存和“太阳”的确切位置,它们可以通过自身缓存流量。

这是多媒体内容的缓存,用户数据不存储在这里-只是音乐,视频,照片。
为了确定用户的区域,我们
收集了在区域中宣布的BGP网络前缀 。 在后备情况下,如果我们无法通过前缀找到IP,我们仍然可以解析geoip。
通过用户IP,我们确定区域 。 在代码中,我们可以查看用户的一个或多个区域-他在地理上最接近的那些点。
如何运作?
我们按地区来考虑文件的普及程度 。 用户所在的区域有一个缓存编号,还有一个文件标识符-我们采用这一对,并为每次下载增加等级。
同时,恶魔-地区中的服务-不时来到API并说:“我拥有这样的缓存,请给我列出我所在地区最受欢迎的文件列表。” API提供了一堆按等级排序的文件,守护程序将它们抽出,将它们带到区域并从那里提供文件。 这是pu / pp和Sun从缓存中获得的根本区别:即使文件不存在于缓存中,它们也会立即通过自身提供文件,并且缓存首先将文件下载到其自身,然后开始将其释放。
同时,我们使
内容更贴近用户并抹去了网络负载。 例如,仅在莫斯科缓存中,我们在繁忙时间分配的速率超过1 Tbit / s。
但是存在问题-
缓存服务器不是橡胶的 。 对于超级流行的内容,有时在单独的服务器上没有足够的网络。 我们有40-50 Gbit / s高速缓存服务器,但是有些内容完全阻塞了这样的通道。 我们正在努力实现在该地区存储一个以上的流行文件副本。 我希望我们能在今年年底之前实现这一目标。
我们研究了总体架构。
- 接受请求的前端服务器。
- 处理请求的后端。
- 由两种类型的代理关闭的保管库。
- 区域缓存。
该计划缺少什么? 当然,我们存储数据的数据库。
数据库或引擎
我们称它们不是数据库,而是Engines引擎,因为在通常公认的意义上,我们实际上没有数据库。
 这是必要的措施
这是必要的措施 。 发生这种情况的原因是,在2008-2009年间,VK的爆炸性增长使该项目完全在MySQL和Memcache上运行,并且出现了问题。 MySQL喜欢掉落并破坏文件,此后它没有上升,并且Memcache的性能逐渐下降,必须重新启动。
事实证明,在越来越受欢迎的项目中,有一个永久存储破坏了数据,而一个缓存却变慢了。 在这种情况下,很难发展一个不断发展的项目。 决定尝试重写项目依靠自己的自行车的关键事项。
解决方案成功 。 迫切需要这样做的能力,因为那时还不存在其他缩放方法。 目前还没有基础库,NoSQL还不存在,只有MySQL,Memcache和PostrgreSQL,仅此而已。
通用操作 。 开发工作由我们的C开发人员团队领导,并且所有操作均以相同的方式完成。 无论使用哪种引擎,到处都有几乎相同格式的文件写入磁盘,相同的启动参数,在发生边缘情况和问题时对信号进行相同的处理和表现相同。 随着引擎的增长,管理员可以方便地操作该系统-无需维护动物园,也无需学习再次操作每个新的第三方基地,这使得快速便捷地增加其数量成为可能。
引擎类型
团队已经编写了很多引擎。 以下是其中的一些:朋友,提示,图像,ipdb,字母,列表,日志,memcached,meowdb,新闻,nostradamus,照片,播放列表,pmemcached,沙箱,搜索,存储,喜欢,任务,...
对于需要特定数据结构或处理非典型请求的每个任务,C团队将编写一个新引擎。 为什么不呢
我们有一个单独的
memcached引擎,它与通常的引擎相似,但是带有一堆面包,并且不会减慢速度。 不是ClickHouse,但也可以。 单独有
pmemcached-这是一个
持久性的memcached ,它也可以将数据存储在磁盘上,并且存储在RAM中的数据要多得多,以便在重启时不会丢失数据。 有多种引擎可用于单独的任务:队列,列表,集合-我们项目所需要的全部。
集群
从代码的角度来看,无需将引擎或数据库想象为某些进程,实体或实例。 该代码专门用于具有引擎组的
集群 -
每个集群一种类型 。 假设有一个内存缓存集群-它只是一组计算机。
该代码不需要知道服务器的物理位置,大小和数量。 他通过某个标识符进入集群。
为此,您需要添加另一个实体,该实体位于代码和engines-
proxy之间 。
RPC代理
代理-
连接总线 ,几乎可以运行整个站点。 同时,我们
没有服务发现 -代替它,而是此代理的配置,该代理知道所有群集以及该群集的所有碎片的位置。 这是由管理员完成的。
程序员通常并不关心它的成本,成本和成本,而只是去集群。 这让我们受益匪浅。 收到请求后,代理将重定向请求,并知道它在哪里-它确定了这一点。

同时,代理是防止服务故障的保护点。 如果任何引擎速度变慢或崩溃,则代理可以理解这一点,并相应地响应客户端。 这使您可以删除超时-代码不等待引擎响应,但是知道它不起作用并且您需要采取不同的行为。 应该针对数据库并非始终有效的事实准备代码。
具体实施
有时,我们仍然非常想拥有某种定制解决方案作为引擎。 同时,决定不使用专门为我们的引擎创建的现成的rpc-proxy,而是为该任务创建单独的代理。
对于在某些地方仍然存在的MySQL,我们使用db-proxy,对于ClickHouse-
Kittenhouse 。
这样总体上是这样的。 有一个服务器,kPHP,Go,Python正在其上运行-通常,任何可以遵循我们的RPC协议的代码。 代码在本地传递到RPC代理-在有代码的每台服务器上,都会启动其自己的本地代理。 根据要求,代理知道要去哪里。
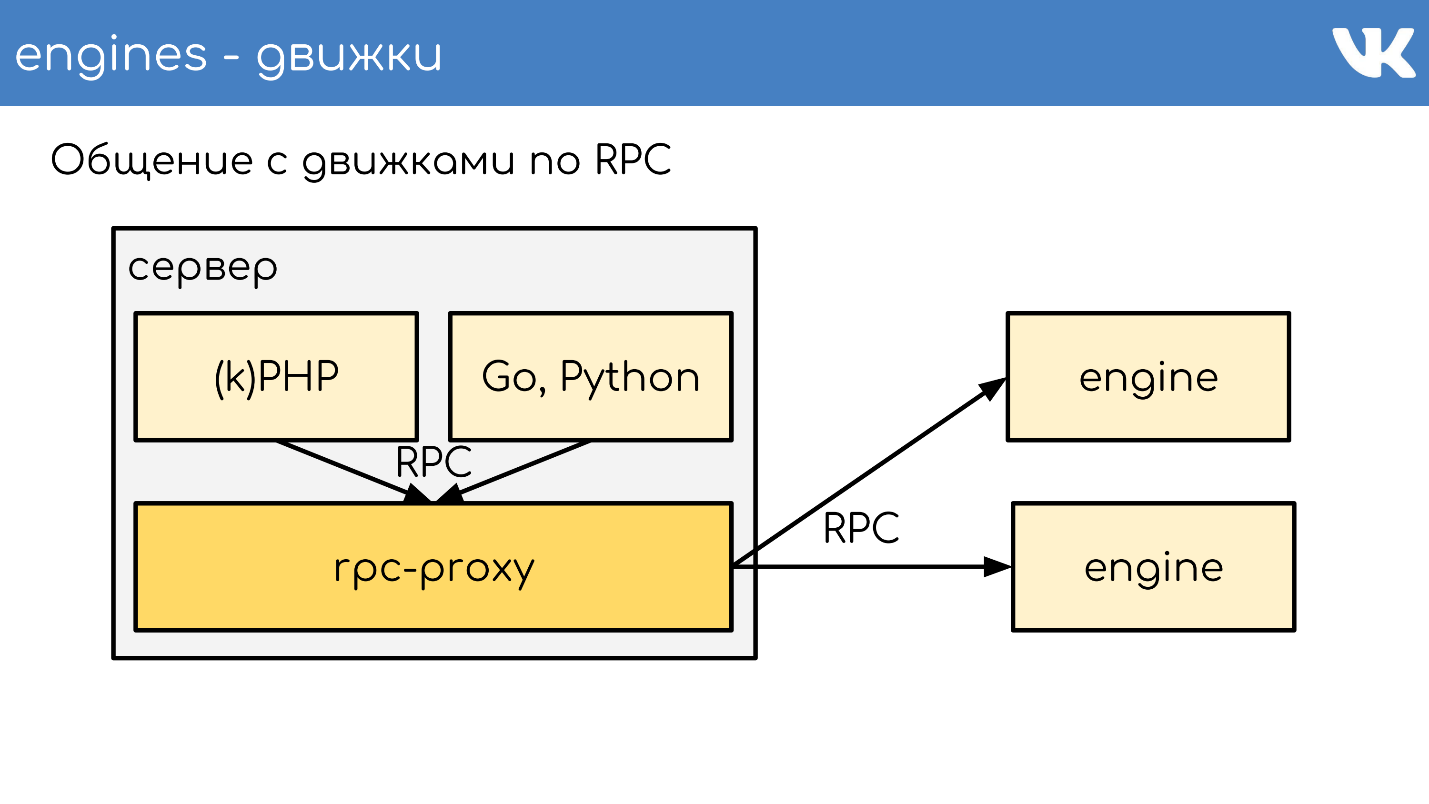
如果一个引擎想要转到另一个引擎,即使它是邻居,它也会通过代理,因为邻居可以位于另一个数据中心。 引擎不应该只知道自身以外的任何位置,我们拥有这种标准解决方案。 但是当然有例外:)
所有引擎均根据其工作的TL方案示例。
memcache.not_found = memcache.Value; memcache.strvalue value:string flags:int = memcache.Value; memcache.addOrIncr key:string flags:int delay:int value:long = memcache.Value; tasks.task fields_mask:# flags:int tag:%(Vector int) data:string id:fields_mask.0?long retries:fields_mask.1?int scheduled_time:fields_mask.2?int deadline:fields_mask.3?int = tasks.Task; tasks.addTask type_name:string queue_id:%(Vector int) task:%tasks.Task = Long;
这是一个二进制协议,最接近的类似物是
protobuf。 该方案预先描述了可选字段,复杂类型-内置标量的扩展和查询。 一切都按照此协议进行。
RPC over TL over TCP / UDP ... UDP?
我们有一个用于查询引擎的RPC协议,该协议在TL方案之上运行。 所有这些都可以在TCP / UDP连接之上进行。 TCP-很明显,为什么我们经常被问到UDP。
UDP有助于
避免服务器之间的大量连接问题 。 如果每个服务器上都有一个RPC代理,并且通常它可以连接到任何引擎,那么您将获得与该服务器成千上万的TCP连接。 有负载,但是没用。 如果是UDP,则不会出现此问题。
没有冗余的TCP握手 。 这是一个典型的问题:当出现新引擎或新服务器时,会立即建立许多TCP连接。 对于较小的轻量级请求,例如UDP负载,代码和引擎之间的所有通信都是
两个UDP数据包:一个在一个方向上飞行,另一个在另一个方向上飞行。 一次往返-代码收到了引擎的响应,没有握手。
是的,这一切仅
在很小的丢包率下起作用。 该协议支持重传和超时,但是如果丢失很多,我们实际上会获得TCP,这是无利可图的。 在大洋彼岸,请勿驱动UDP。
我们有成千上万个这样的服务器,并且有相同的方案:每台物理服务器上都放置了一组引擎。 基本上,它们是单线程的,可以在不阻塞的情况下尽快运行,并且被分解为单线程解决方案。 同时,我们没有比这些引擎更可靠的了,并且对持久性数据存储给予了很多关注。
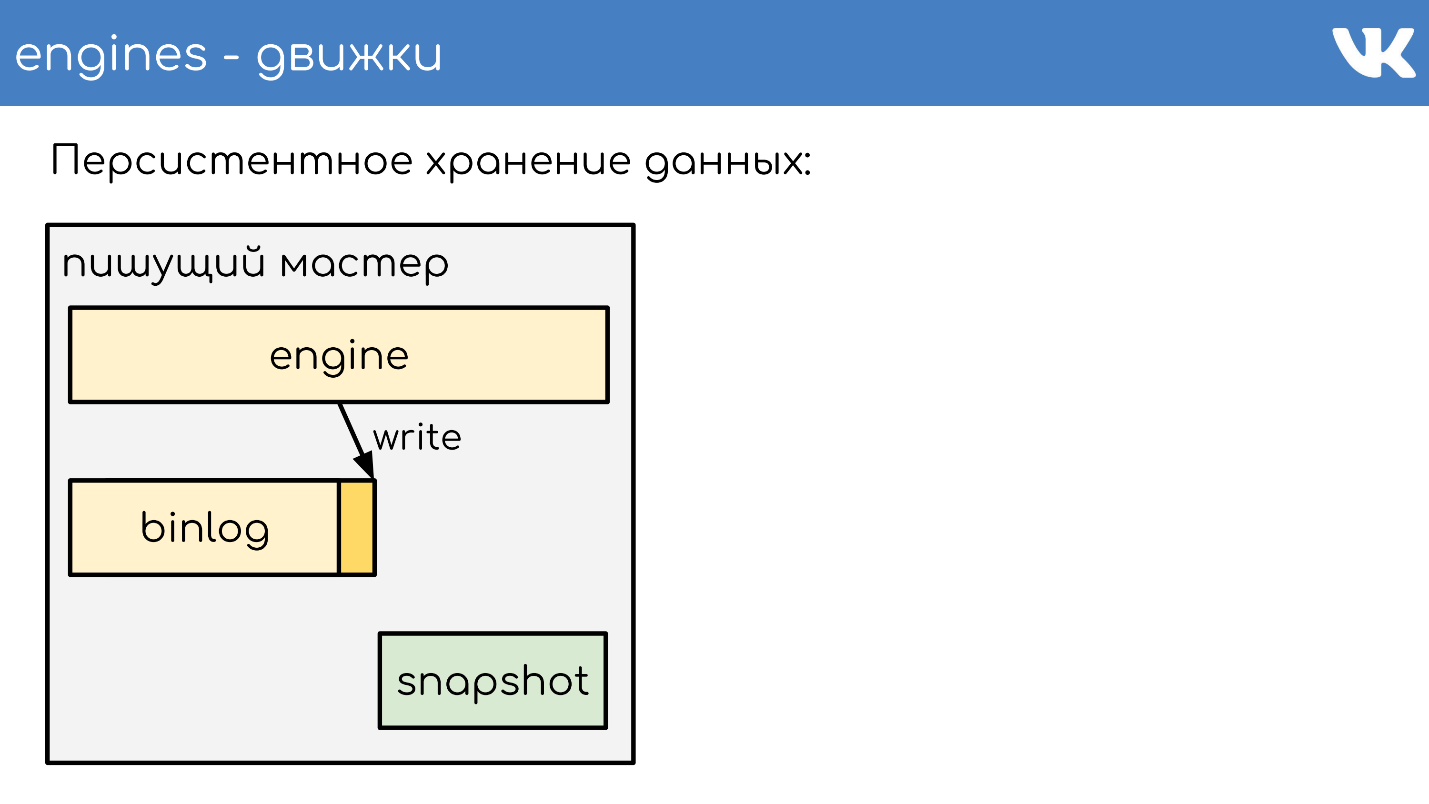
永久数据存储
引擎编写binlog 。 Binlog是一个文件,在文件的末尾添加了一个事件以更改状态或数据。 在不同的解决方案中,其名称有所不同:二进制日志,
WAL ,
AOF ,但原理是一种。
为了使引擎在多年的重新启动过程中不会重新读取整个binlog,引擎会写入
快照-当前状态 。 如有必要,他们首先从中读取,然后从binlog中读取。 根据TL方案,所有二进制日志均以相同的二进制格式编写,因此管理员可以使用其工具平等地对其进行管理。 无需快照。 有一个通用的标题,指示谁的快照是int,引擎的魔力,以及哪个主体对任何人都不重要。 这是记录快照的引擎的问题。
我将简要描述工作原理。 有一台正在运行引擎的服务器。 他打开一个新的空binlog进行记录,并向其中写入一个change事件。

在某个时候,他要么决定拍摄快照,要么他接收到信号。 服务器创建一个新文件,将其状态完全写入其中,将binlog的当前大小(偏移量)附加到文件末尾,然后继续进行进一步写入。 不会创建新的binlog。
在某个时候,引擎重新启动时,磁盘上将有一个二进制日志和一个快照。 引擎将读取完整的快照,并在特定点提升其状态。

减去创建快照时的位置和二进制日志的大小。
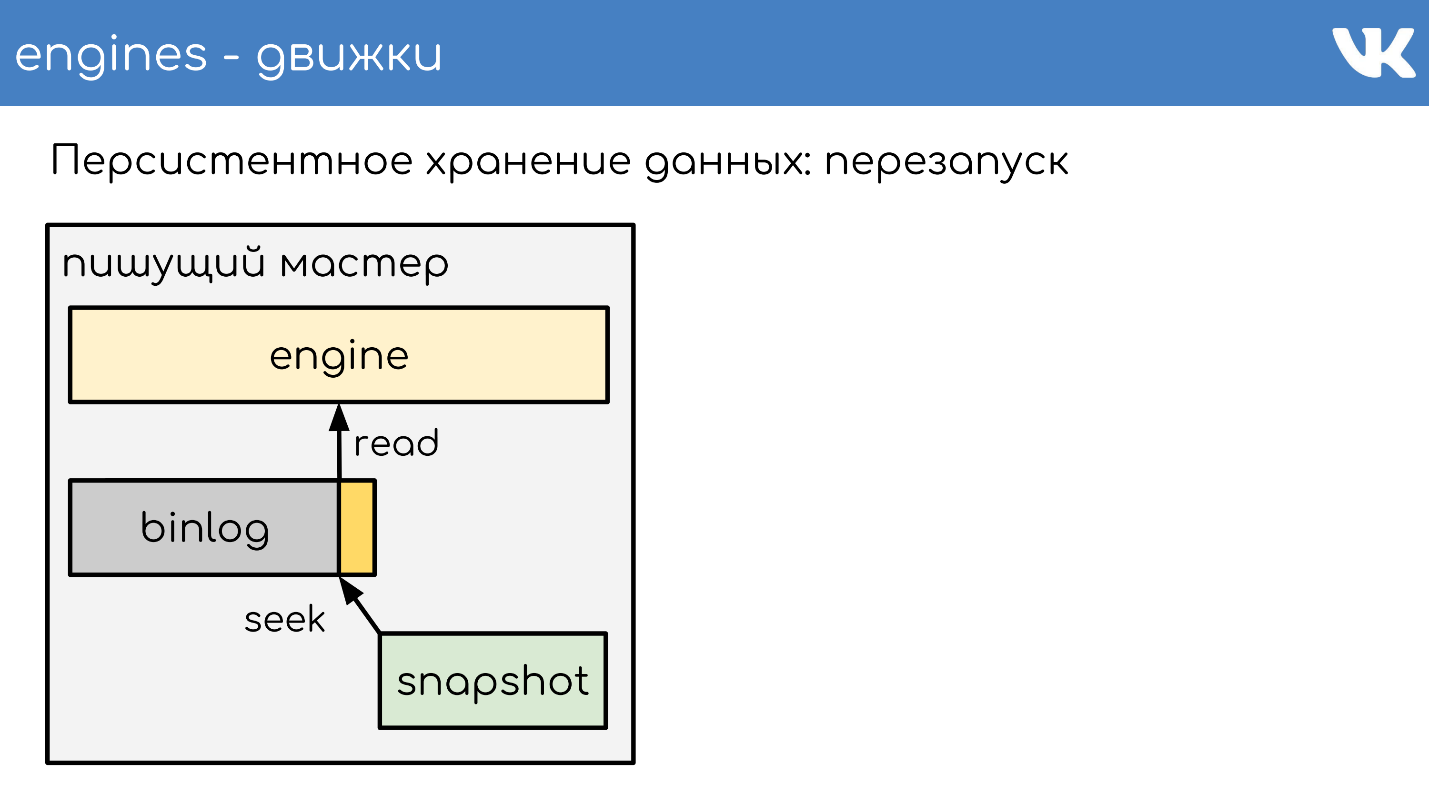
读取binlog的末尾以获取当前状态,并继续编写其他事件。 这是一个简单的方案,我们所有的引擎都可以使用它。
资料复制
结果,数据复制是
基于语句的 -我们不会将任何页面更改写入二进制日志,而是
请求更改 。 与网络上的内容非常相似,只有一点点变化。
相同的方案不仅用于复制,而且
用于创建备份 。 我们有一个引擎-编写二进制日志的写作大师。 在管理员设置的其他任何地方,复制此二进制日志都会增加,仅此而已-我们有一个备份。

如果您需要一个
读取副本以减轻CPU读取的负担,那么读取引擎就会启动,它会读取binlog的末尾并在本地执行这些命令。
这里的滞后很小,并且有机会找出副本副本在原版副本后面的数量。
RPC代理中的数据分片
分片如何工作? 代理如何理解要发送到哪个群集分片? 代码没有说:“发送到15个碎片!” -不,它可以代理。
最简单的方案是firstint ,即请求中的第一个数字。
get(photo100_500) => 100 % N.这是一个简单的Memcached文本协议的示例,但是,当然,请求是复杂的,结构化的。 该示例获取查询中的第一个数字,然后除以群集大小的余数。
当我们想要一个实体的数据局部性时,这很有用。 假设100是一个用户或组ID,并且我们希望一个实体的所有数据在同一分片上以进行复杂的查询。
如果我们不在乎请求如何在整个集群中分布,则还有另一种选择-
对整个分片进行哈希处理 。
hash(photo100_500) => 3539886280 % N我们还获得散列,除法的余数和分片的数量。
这两个选项只有在我们准备好增加群集大小时会多次分裂或增加群集这一事实时才起作用。 例如,我们有16个分片,我们丢失了,我们想要更多-您可以安全地获得32个而不会造成停机。 如果我们要进行多次构建,则会出现停机时间,因为无法小心地粉碎所有内容而不会造成损失。 这些选项很有用,但并非总是如此。
如果我们需要添加或删除任意数量的服务器,
则在la Ketama环上使用一致的哈希 。 但是,与此同时,我们完全失去了数据的局部性,我们必须向集群发出合并请求,以使每个块都返回其较小的答案,并且已经将响应合并到代理中。
- . : RPC-proxy , , . , , , . proxy.

. —
memcache .
ring-buffer: prefix.idx = line— , , — . 0 1. memcache — . .
,
Multi Get , , . , - , , , .
logs-engine . , . 600 .
, , 6–7 . , , , ClickHouse .
ClickHouse
, .

, RPC RPC-proxy, , . ClickHouse, :
- - ClickHouse;
- RPC-proxy, ClickHouse, - , , RPC.
— ClickHouse.
ClickHouse,
KittenHouse . KittenHouse ClickHouse — . , HTTP- . , ClickHouse
reverse proxy , , . .

RPC- , , nginx. KittenHouse UDP.

, UDP- . RPC , UDP. .
监控方式
: , , . :
.
Netdata ,
Graphite Carbon . ClickHouse, Whisper, . ClickHouse,
Grafana , . , Netdata Grafana .
. , , Counts, UniqueCounts , - .
statlogsCountEvent ( 'stat_name', $key1, $key2, …) statlogsUniqueCount ( 'stat_name', $uid, $key1, $key2, …) statlogsValuetEvent ( 'stat_name', $value, $key1, $key2, …) $stats = statlogsStatData($params)
, , — , Wathdogs.
, 600 1 .
, . — , . , .
,
memcache , .
stats-daemon .
logs-collectors , , .

logs-collectors.
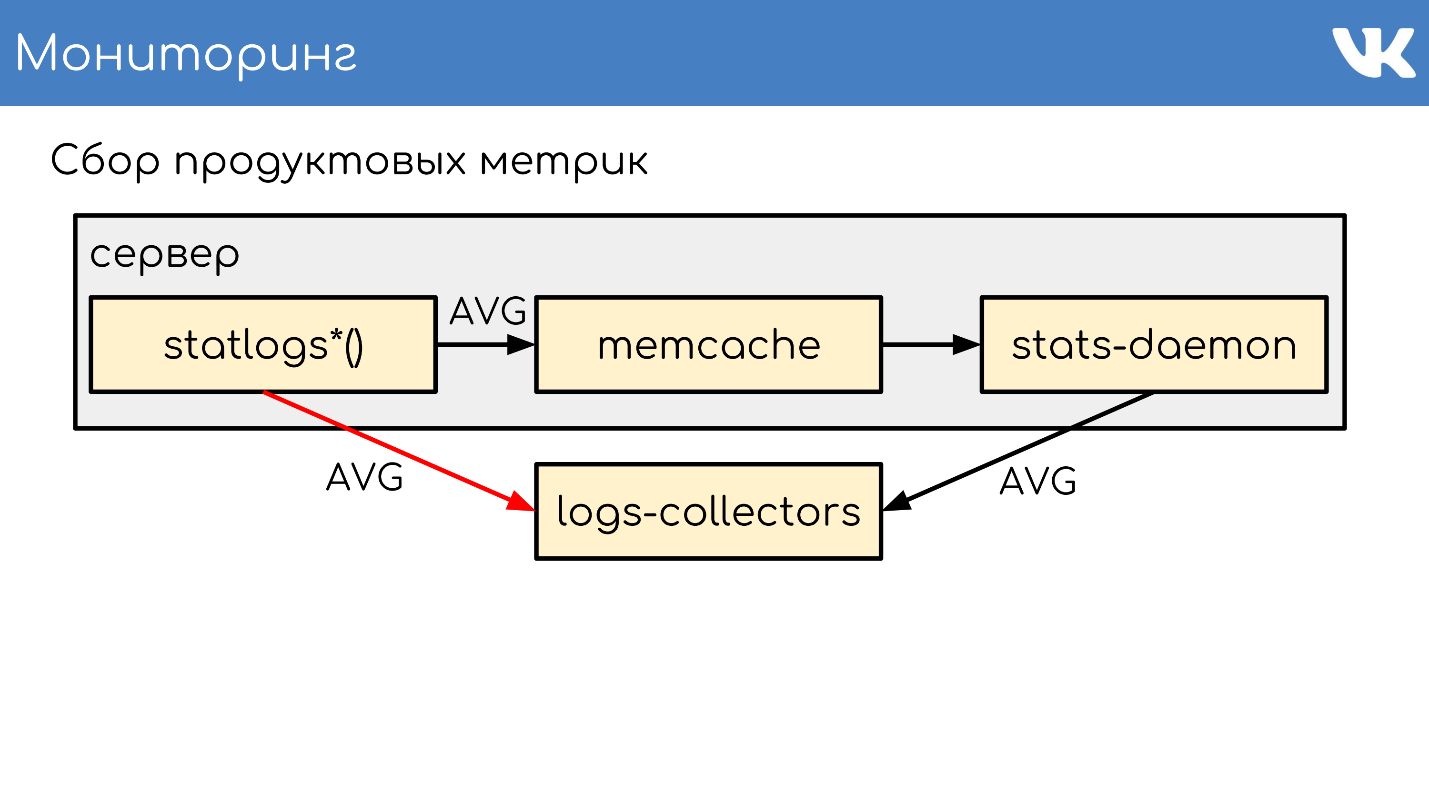
stas-daemom — , collector. , - memcache stats-daemon, , .
logs-collectors
meowDB — , .
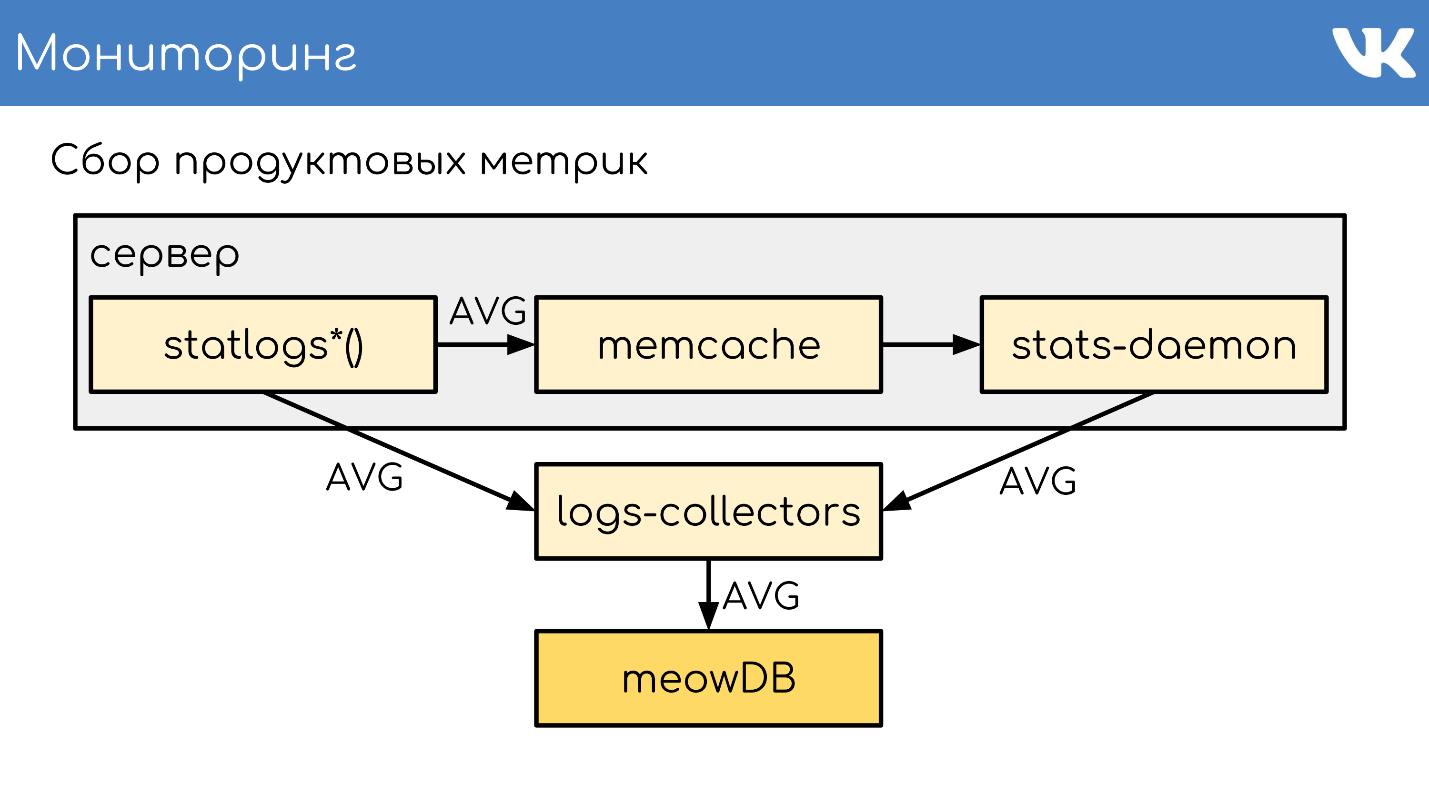
«-SQL» .

2018 , -, ClickHouse. ClickHouse — ?

, KittenHouse.
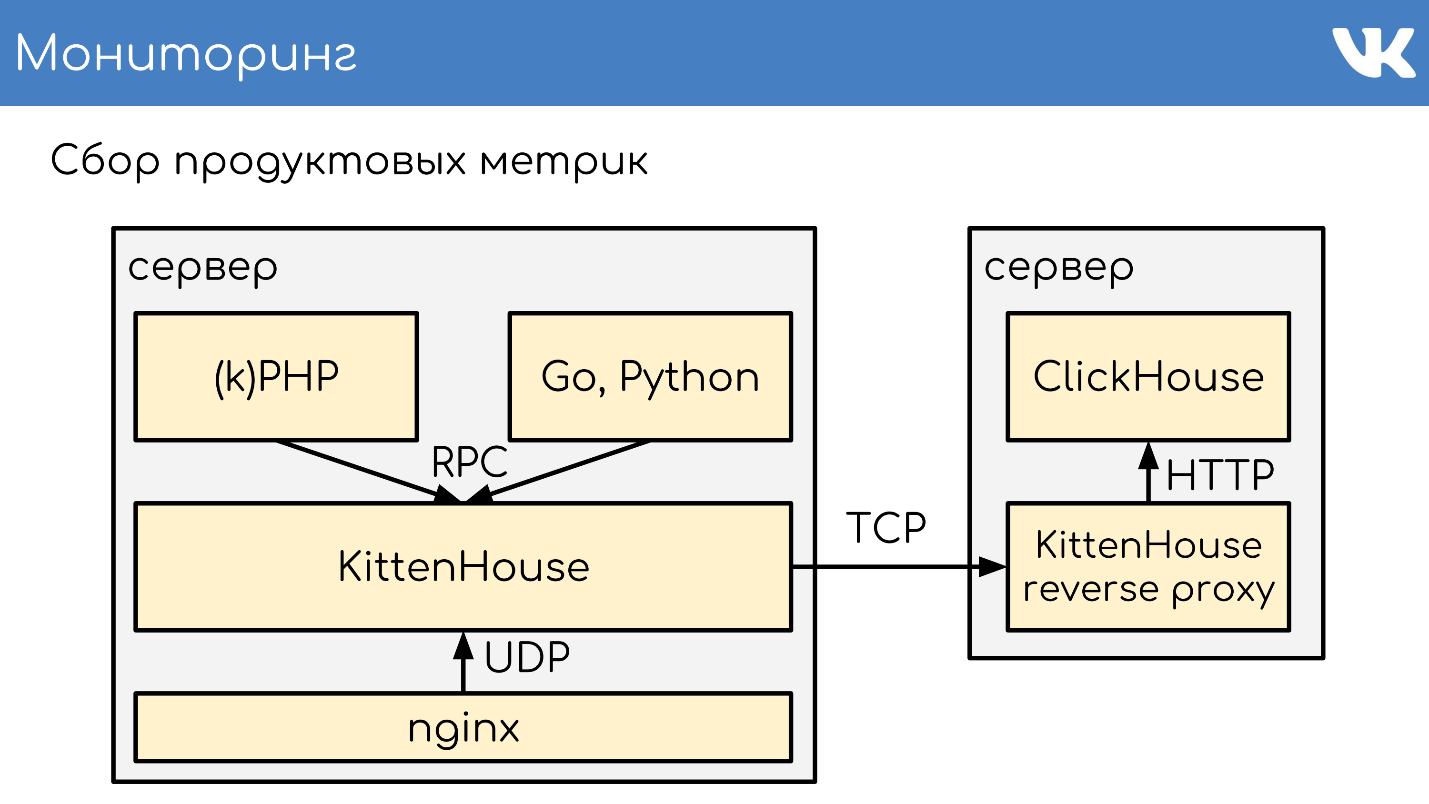 «*House»
«*House» , , UDP. *House inserts, , KittenHouse. ClickHouse, .
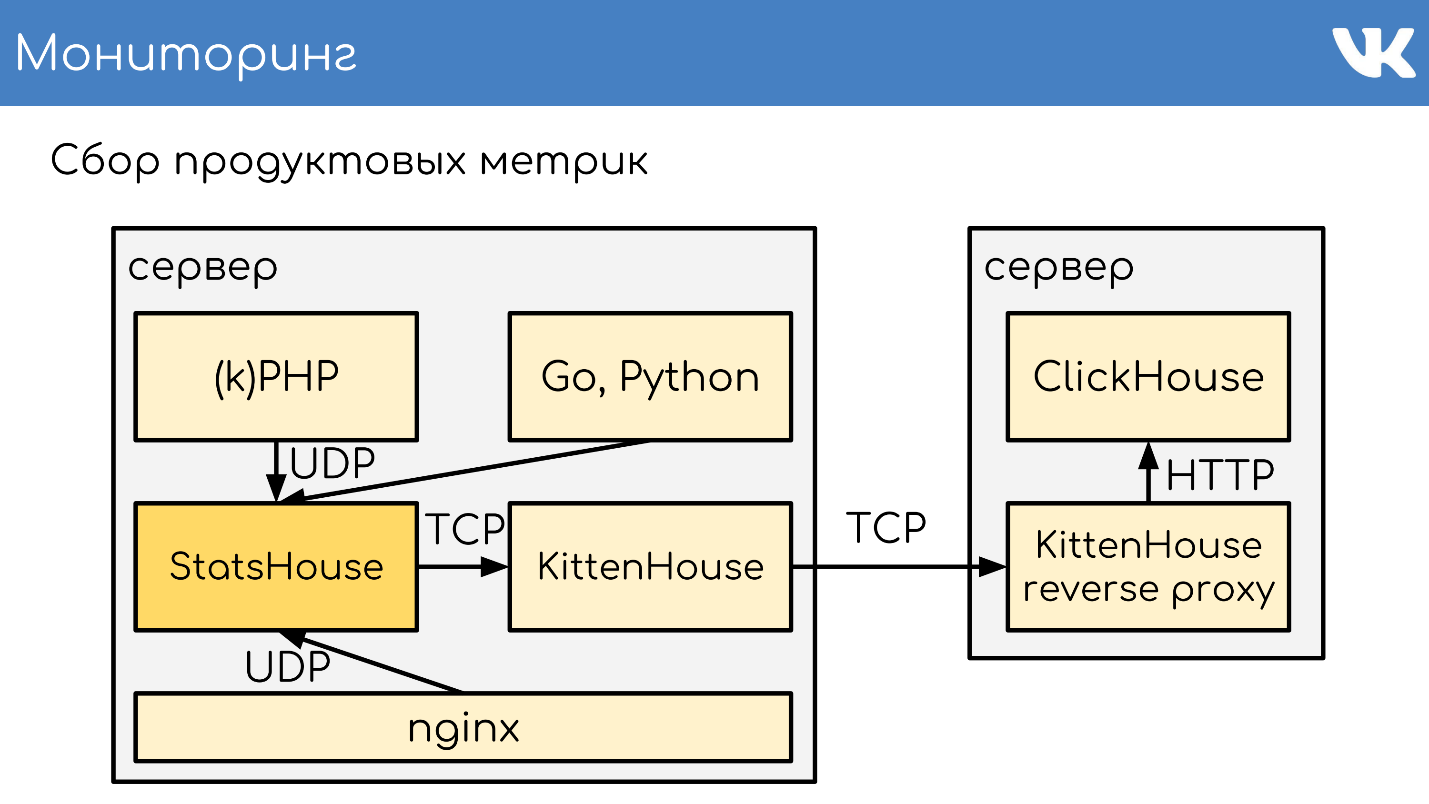
memcache, stats-daemon logs-collectors .

memcache, stats-daemon logs-collectors .
- , StatsHouse.
- StatsHouse KittenHouse UDP-, SQL-inserts, .
- KittenHouse ClickHouse.
- , StatsHouse — ClickHouse SQL.
, , . , , , . .
. , stats-daemons logs-collectors, ClickHouse , , .
, .
PHP.
git :
GitLab TeamCity . -, , — .
, diff — : , , . binlog copyfast, . ,
gossip replication , , — , . . ,
. .
kPHP
git .
HTTP- , diff — . —
binlog copyfast . , .
. copyfast' , binlog , gossip replication , -, .
graceful .
, , :
- git master branch;
- .deb ;
- binlog copyfast;
- ;
- .dep;
- dpkg -i ;
- graceful .
,
.deb ,
dpkg -i . kPHP , — dpkg? . — .
:, PHP Russia 17 PHP-. , , ( PHP!) — , PHP, .