继续在Habré上进行机器学习竞赛的主题,我们想向读者介绍另外两个平台。 它们肯定不如kaggle庞大,但它们绝对值得关注。

就个人而言,出于以下几个原因,我不喜欢kaggle:
- 首先,那里的比赛通常持续几个月,要积极参与,必须付出很多努力。
- 其次是公共内核(公共解决方案)。 狂笑的信徒劝告他们与藏族僧侣保持冷静,但实际上,当您突然发现一个月或两个月的时间被摆放在每个人的盘子上时,真是太可惜了。
幸运的是,机器学习竞赛在其他平台上举行,并且将讨论其中的一些竞赛。
| IDAO | SNA Hackathon 2019 |
|---|
官方语言:英语,
主办单位:Yandex,Sberbank,HSE | 官方语言:俄语,
组织者:Mail.ru组 |
在线回合:2019年1月15日至2月11日;
现场决赛:2019年4月4-6日 | 在线-2月7日至3月15日;
离线-从3月30日到4月1日。 |
根据大型强子对撞机上某个粒子的一组特定数据(关于轨迹,动量和其他相当复杂的物理参数),确定它是否为介子
通过此语句,区分了2个任务:
-您只需发送一次预测,
-另外,-用于预测的完整代码和模型,以及对执行时间和内存使用量的严格限制 | 在SNA Hackathon竞赛中,收集了用于显示2018年2月至3月用户新闻源中开放组内容的日志。 测试集隐藏了3月的最后一周半。 日志中的每个条目都包含有关向谁显示内容以及用户对此内容的反应的信息:在提要中放置“类”,添加注释,忽略或隐藏。
SNA Hackathon的任务的实质是为Odnoklassniki社交网络的每个用户安排他的磁带,并尽可能提高那些将获得“类”的帖子。
在在线阶段,任务分为三个部分:
1.基于各种合作理由对职位进行排名
2.通过帖子中包含的图像对帖子进行排名
3.根据文章中的文字对文章进行排名 |
| 复杂的自定义指标,例如ROC-AUC | 用户的平均ROC-AUC |
第一阶段的奖品-N个地方的T恤衫,进入第二阶段的比赛,在比赛期间支付住宿和膳食
第二阶段-??? (由于某种原因,我没有出席颁奖典礼,也无法弄清楚最终获得的奖品是什么)。 向获胜团队的所有成员提供了笔记本电脑 | 第一阶段的奖项-最佳100名参赛者的T恤衫,进入第二阶段的比赛,在那里他们支付了前往莫斯科的旅费,住宿和伙食费。 此外,在第一阶段快要结束时,宣布了在第一阶段的3项任务中最好的奖项:每个人都在RTX 2080 TI视频卡上获胜!
第二阶段是团队一,团队有2至5人,奖品:
第一名-300,000卢布
第二名-20万卢布
第三名-100,000卢布
评审团奖-10万卢布 |
| 电报中的官方小组,〜190名参与者,用英语交流,我不得不等待几天才能回答问题 | 电报中的正式小组,约有1500名参与者,参与者与组织者之间积极讨论任务 |
| 组织者提供了两个基本解决方案,简单和高级。 一个简单的内存需要少于16 GB的RAM,而16个内存中的一个高级内存则不适合。 同时,领先一步,参与者未能明显超过高级解决方案。 启动这些解决方案没有困难。 应该注意的是,在高级示例中,有一条注释,其中暗示着从哪里开始改进解决方案。 | 为每个任务提供了基本的原始解决方案,参与者很容易就可以解决。 在竞赛的初期,参与者面临一些困难:首先,数据以Apache Parquet格式给出,并且并非Python和parquet软件包的所有组合都能正常工作。 第二个困难是从邮件云中抽取图片,目前还没有一种简单的方法可以一次下载大量数据。 结果,这些问题将参与者推迟了几天。 |
IDAO。 第一阶段
任务是根据它们的特性对介子/非介子粒子进行分类。 这项任务的关键特征是训练数据中存在一个权重栏,组织者自己将其解释为对该行答案的信心。 问题是相当多的行包含负权重。
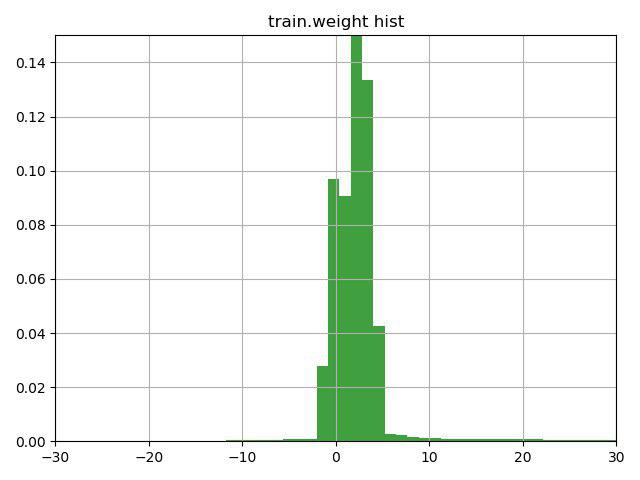
在考虑带有提示的提示行几分钟后(提示只是引起了对weight列的此功能的注意)并构建了此图,我们决定检查3个选项:
1)反转负权重(和权重分别为)的行的目标
2)将权重移到最小值,以使它们从0开始
3)不要对行使用权重
第三个选项原来是最差的,但是前两个选项改善了结果,最好的是第一个选项,它立即使我们在第一个任务中排名第二,在第二个任务中排名第一。

我们的下一步是查看缺失值的数据。 组织者为我们提供了已经精梳的数据,其中缺少很多值,它们被-9999代替。
仅在N = 2或3时,我们才在MatchHit_ {X,Y,Z} [N]和MatchHit_D {X,Y,Z} [N]列中找到缺失值。 ,然后停在3或4板。 数据还包含Lextra_ {X,Y} [N]列,这些列显然描述了与MatchHit_ {X,Y,Z} [N]相同的事物,但是使用了某种外推法。 这些微不足道的猜测表明,可以代替Lextra_ {X,Y} [N](仅用于X和Y坐标),而不是在MatchedHit_ {X,Y,Z} [N]中缺少值。 MatchedHit_Z [N]很好地填充了中位数。 这些操作使我们在两项任务上都达到了中间位置。

考虑到第一阶段的胜利他们什么都没给,我们可以停下来,但是我们继续,画了一些漂亮的照片并提出了新的功能。

例如,我们发现如果我们建立四个检测器板中每个粒子的相交点,我们可以看到每个板上的点被分为5个矩形,纵横比为4到5,中心在(0,0),并且第一个矩形没有点。
| 板号/矩形尺寸 | 1个 | 2 | 3 | 4 | 5 |
|---|
| 板1 | 500x625 | 1000x1250 | 2000x2500 | 4000x5000 | 8000x10000 |
| 板2 | 520x650 | 1040x1300 | 2080x2600 | 4160x5200 | 8320x10400 |
| 板3 | 560x700 | 1120x1400 | 2240x2800 | 4480x5600 | 8960x11200 |
| 板4 | 600x750 | 1200x1500 | 2400x3000 | 4800x6000 | 9600x12000 |
确定这些大小后,我们为每个粒子添加了4个新的分类特征-与每个平板相交的矩形的数量。
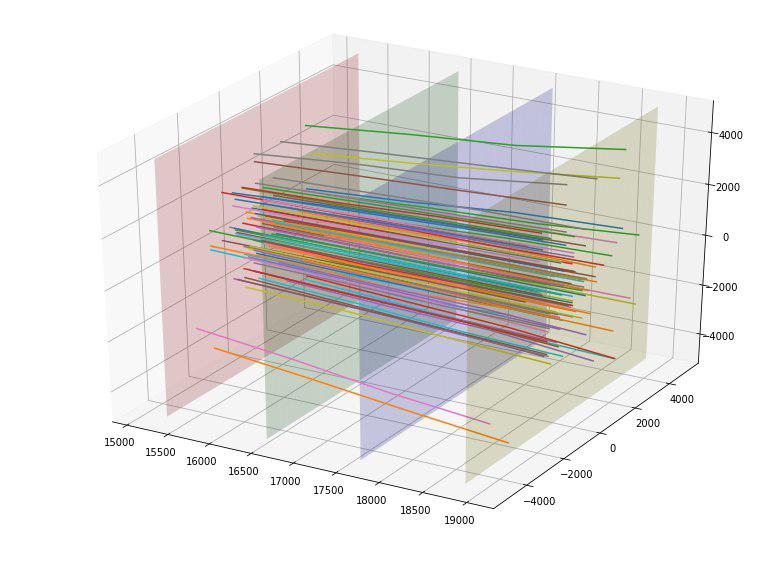
我们还注意到,粒子似乎从中心散布开来,并且提出了以某种方式评估此散布的“质量”的想法。 理想情况下,可能可以根据切入点提出某种“理想”抛物线并估计与之的偏离,但我们将自己限于“理想”线。 通过为每个入口点构建这样的理想线,我们能够从该线计算每个粒子的轨迹的均方差。 由于目标= 1的平均偏差为152,而目标= 0的平均偏差为390,因此我们暂时将该功能评为好。 确实,此功能立即击中了最有用的顶部。
我们很高兴,并添加了每个粒子与理想线的所有4个交点的偏差,作为附加的4个要素(它们也很好用)。
组织者提供给我们的有关竞赛主题的科学文章的链接表明,我们距离解决这一问题的道路还很遥远,也许还有一些专门的软件。 在github上发现了实现了IsMuonSimple,IsMuon,IsMuonLoose方法的存储库之后,我们进行了少量修改就将它们转移给了我们自己。 这些方法本身非常简单:例如,如果能量小于阈值,则这不是μ子,否则不是μ子。 在使用梯度增强的情况下,这种简单的符号显然无法增加,因此我们在阈值上添加了另一个符号“距离”。 这些功能也有所改善。 也许,在对现有方法进行了更彻底的分析之后,人们可以找到更强大的方法并将其添加到属性中。
在比赛快要结束时,我们为第二项任务拉了一些“快速”解决方案,结果在以下几点上与基线有所不同:
- 在负重量的行中,目标被反转
- 填写MatchedHit_ {X,Y,Z} [N]中的缺失值
- 深度减少到7
- 降低学习速度至0.1(原为0.19)
结果,我们尝试了更多功能(并非特别成功),选择了参数并训练了catboost,lightgbm和xgboost,尝试了不同的预测混合,并在打开privat之前自信地赢得了第二项任务,并且是第一个领导者。
privat打开后,我们在第1个任务中排在第十位,在第二个任务中排在第3位。 所有的领导者都混在一起了,私有党的速度比自由党的要高。 数据的分层似乎很差(例如,没有私有负权重的行),这有点令人沮丧。
SNA Hackathon 2019-文本。 第一阶段
任务是根据其中包含的文本在Odnoklassniki社交网络上对用户的帖子进行排名,除了文本之外,还有其他一些帖子特征(语言,所有者,创建日期和时间,查看日期和时间)。
作为处理文本的经典方法,我将提出两个选择:
- 将每个单词映射到n维向量空间中,以使相似的单词具有相似的矢量(更多详细信息可以在我们的文章中找到),然后查找文本的中间单词或使用考虑单词相对位置的机制(CNN,LSTM / GRU) 。
- 使用可以立即处理整个句子的模型。 例如,伯特。 从理论上讲,这种方法应该更好地工作。
因为这是我第一次学习文本,所以教一个人是错误的,所以我会自学。 这些是比赛开始时我会给自己的提示:
- 在您开始学习之前,请查看数据! 除了文本本身之外,数据中还有几列,并且从中可以挤出的比我多得多。 最简单的方法是对部分列进行目标编码。
- 不要从所有数据中学习! 有很多数据(大约1700万行),使用所有数据测试假设是完全可选的。 培训和预处理非常缓慢,我显然将有时间测试更有趣的假设。
- < 有争议的建议 >无需寻找杀手级的模型。 我与Elmo和Bert交往了很长时间,希望他们能立即将我带到一个很高的位置,结果,我使用FastText预训练的俄语嵌入。 使用Elmo,不可能获得更好的速度,但是使用Bert,我无法弄清楚。
- < 有争议的建议 >不要寻找一种杀手feature。 查看数据,我发现大约1%的文本实际上不包含文本! 但是,这里有一些资源的链接,我写了一个简单的解析器,打开了网站并提取了名称和描述。 看来这是个好主意,但后来我被带走了,决定解析所有文本的所有链接,并再次浪费了很多时间。 所有这些都没有使最终结果有显着改善(例如,尽管我想出了茎法)。
- 经典功能。 以Google为例,“文字功能kaggle”读取并添加了所有内容。 TF-IDF也改善了统计功能,例如文本的长度,单词,标点符号的数量。
- 如果有DateTime列,则应将它们解析为几个单独的功能(小时,星期几等)。 应该使用图形/一些指标来分析突出显示哪些功能。 在这里,我直觉地做了所有事情,并选择了必要的功能,但是正常的分析不会有任何伤害(例如,像我们在最后所做的那样)。
比赛的结果是,我根据单词训练了一个带卷积的keras模型,另一个基于LSTM和GRU。 那里和那里都使用了针对俄罗斯语言的经过预先训练的FastText嵌入(我尝试了许多其他嵌入,但是这些嵌入效果最好)。 对预测进行平均后,我在76位参与者中排名最后的第七位。
在第一阶段之后,已获得第二名的Nikolai Anokhin发表了一篇文章 (他参加了比赛),他的决定一直重复到某个阶段,但是由于查询键值关注机制,他走得更远。
第二阶段OK&IDAO
比赛的第二阶段几乎是连续进行的,所以我决定将它们一起考虑。
首先,在新近收购的团队的帮助下,我来到了Mail.ru令人印象深刻的办公室,我们的任务是将第一阶段的三个音轨的模型(文本,图片和协作)进行组合。 为此分配了2天多一点的时间,事实证明这很小。 实际上,我们只能重复第一阶段的结果,而不会从关联中获得任何收益。 结果,我们获得了第五名,但无法使用文本模型。 查看其他参与者的决定,似乎值得尝试将文本聚类并将其添加到协作模型中。 这个阶段的副作用是新的印象,熟人和与冷静的参与者和组织者的交流,以及严重的睡眠不足,这可能影响了IDAO最终阶段的结果。
在IDAO 2019决赛的面对面阶段的任务是预测在机场订购Yandex出租车司机的等待时间。 在第2阶段,分配了3个任务= 3个机场。 对于每个机场,都会提供六个月的出租车订单每分钟数据。 并给出了过去2周的下个月和每分钟的订单数据作为测试数据。 没有足够的时间(1.5天),任务非常具体,只有一个人从团队中参加比赛-结果,悲惨的地方临近尾声。 在有趣的想法中,曾尝试使用外部数据:天气,交通拥堵和Yandex出租车订单的统计数据。 尽管组织者没有说机场是什么,但许多与会者建议他们是谢列梅捷沃,多莫杰多沃和伏努科沃。 尽管这个假设在比赛后被驳回,但例如莫斯科天气数据等功能在验证和排行榜上都改善了结果。
结论
- ML竞赛非常有趣! 有一个数据分析,狡猾模型和技术技能的应用程序,欢迎常识。
- ML已经是一大堆知识,而且似乎呈指数增长。 我为自己设定了了解不同领域(信号,图片,表格,文本)的目标,并且已经意识到要学习多少。 例如,在这些比赛之后,我决定研究:聚类算法,用于处理梯度增强库的高级技术(特别是在GPU上与CatBoost一起使用),胶囊网络以及查询键值关注机制。
- 没有一个笑话! 在许多其他比赛中,至少一件T恤更容易获得,还有更多获得其他奖项的机会。
- 聊天! 在机器学习和数据分析领域,已经有一个庞大的社区,以电报,懈怠的主题团体活跃起来,来自Mail.ru,Yandex和其他公司的认真人士回答问题并帮助初学者,并继续他们在这一知识领域的旅程。
- 我建议所有对上一节充满热情的人都访问datafest ,这是将于5月10日至11日在莫斯科举行的大型免费会议。