我与来自不同公司的数十名质量检查工程师进行了交谈,每个人都谈到了他们使用不同的系统和工具进行错误跟踪的事实。 我们还尝试了其中的几种,因此我决定分享我们提出的解决方案。

前言
我会平庸的。 在开发过程的各个阶段都会出现并检测到错误。 因此,您可以根据检测到错误的时间将错误分为几类:
- 不足之处 。 这些是开发人员在看到新功能时犯的错误。 这些错误是在团队开发摊位上的新功能的研究或验收测试期间发现的。
- 回归中的错误 。 这些缺陷可以在代码集成架上找到手动回归测试或自动UI和API测试。
- 出售虫子 。 这些是员工或客户发现并联系技术支持的问题。
我们从哪里开始,或者是吉拉
两年前,我们有一个专门的测试人员团队,他们在集成了所有团队的代码之后对产品进行了手动测试。 到目前为止,该代码已在开发人员立场的开发人员中进行了测试。 测试人员发现的错误记录在Jira的积压订单中。 错误被存储在一个常见的待办事项列表中,并与其他任务一起从sprint迁移到sprint。 每个sprint都有两个或三个bug,并已将其修复,但大多数错误仍在待办事项列表的底部:
- 错误积压在积压中的原因之一是它们不会干扰用户。 此类错误的优先级较低,因此无法修复。
- 另外,如果公司没有明确的,易于理解的错误建立规则,那么测试人员可以多次添加相同的问题,因为他们无法在此列表中找到已经添加的错误报告。
- 另一个原因可能是缺乏经验的测试人员参与了该项目。 对于刚开始测试的人员,输入错误以跟踪操作期间发现的所有错误是错误的。 没有经验的测试人员认为测试的目的是寻找错误,而不是提供有关产品质量和防止出现缺陷的信息。
我将举一个简单的例子。 在日期输入字段中构建报表时,默认情况下将替换日期。 在弹出窗口中更改日期时,您可以再次选择今天,日期输入字段将被清除。
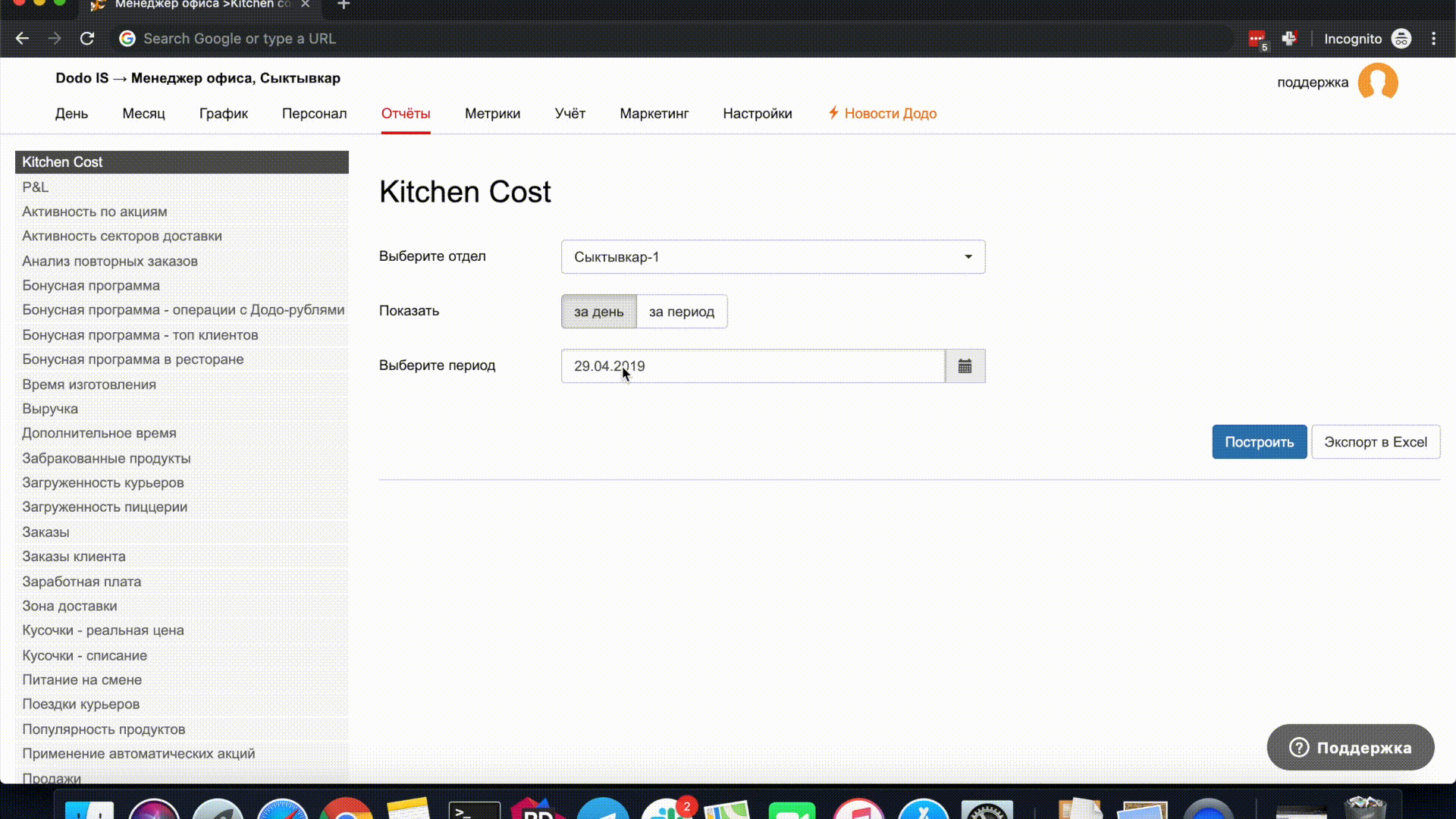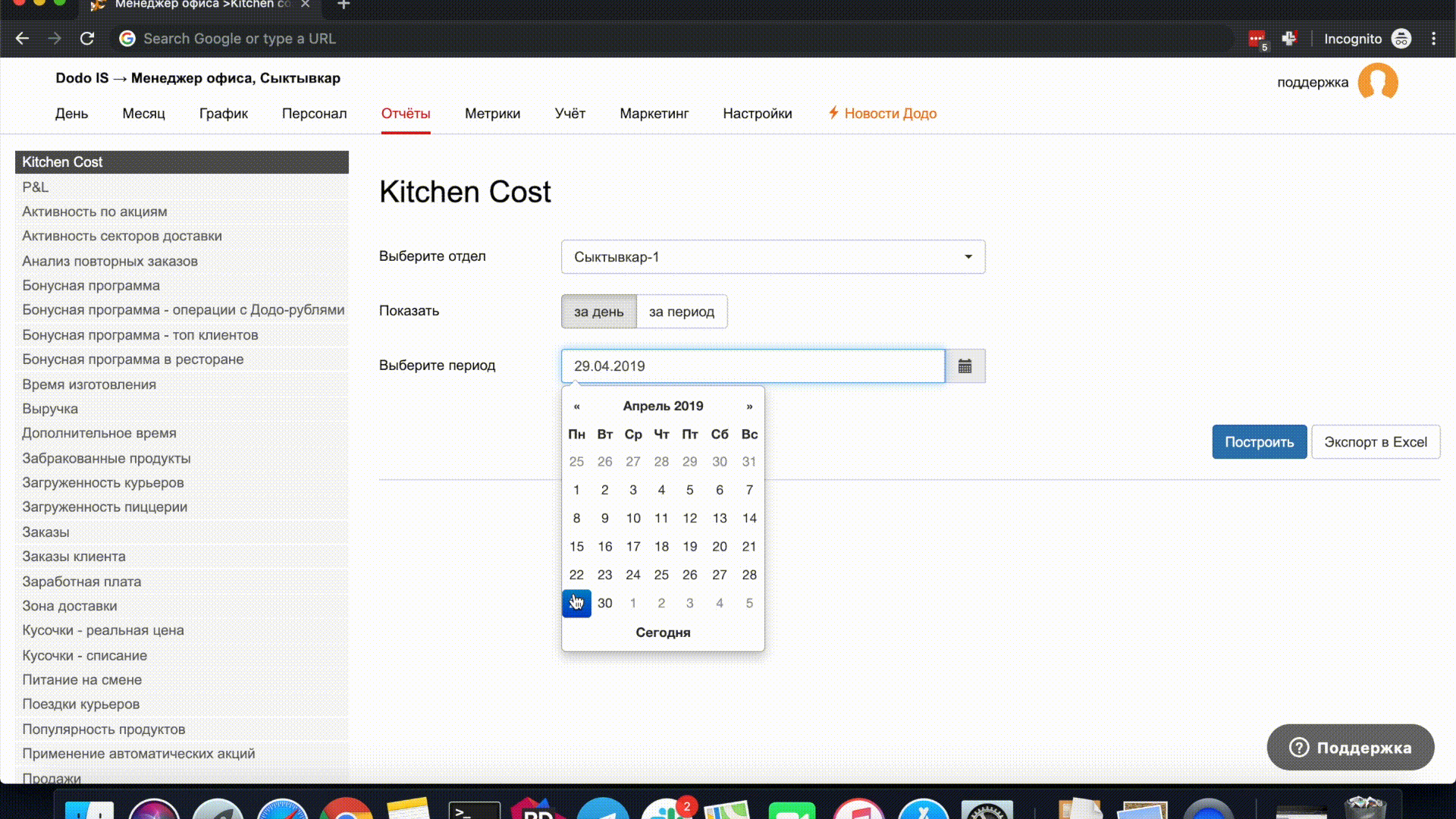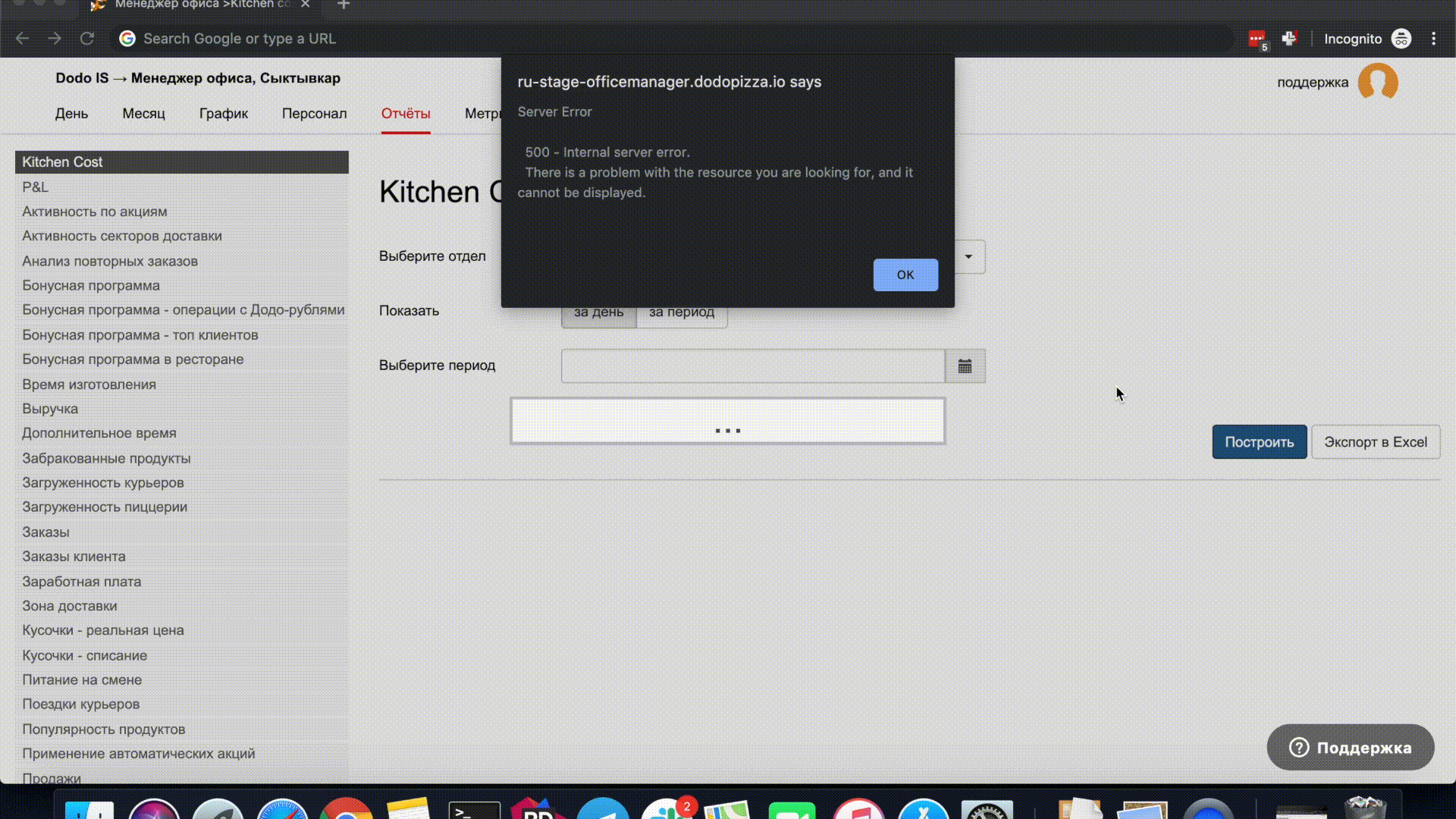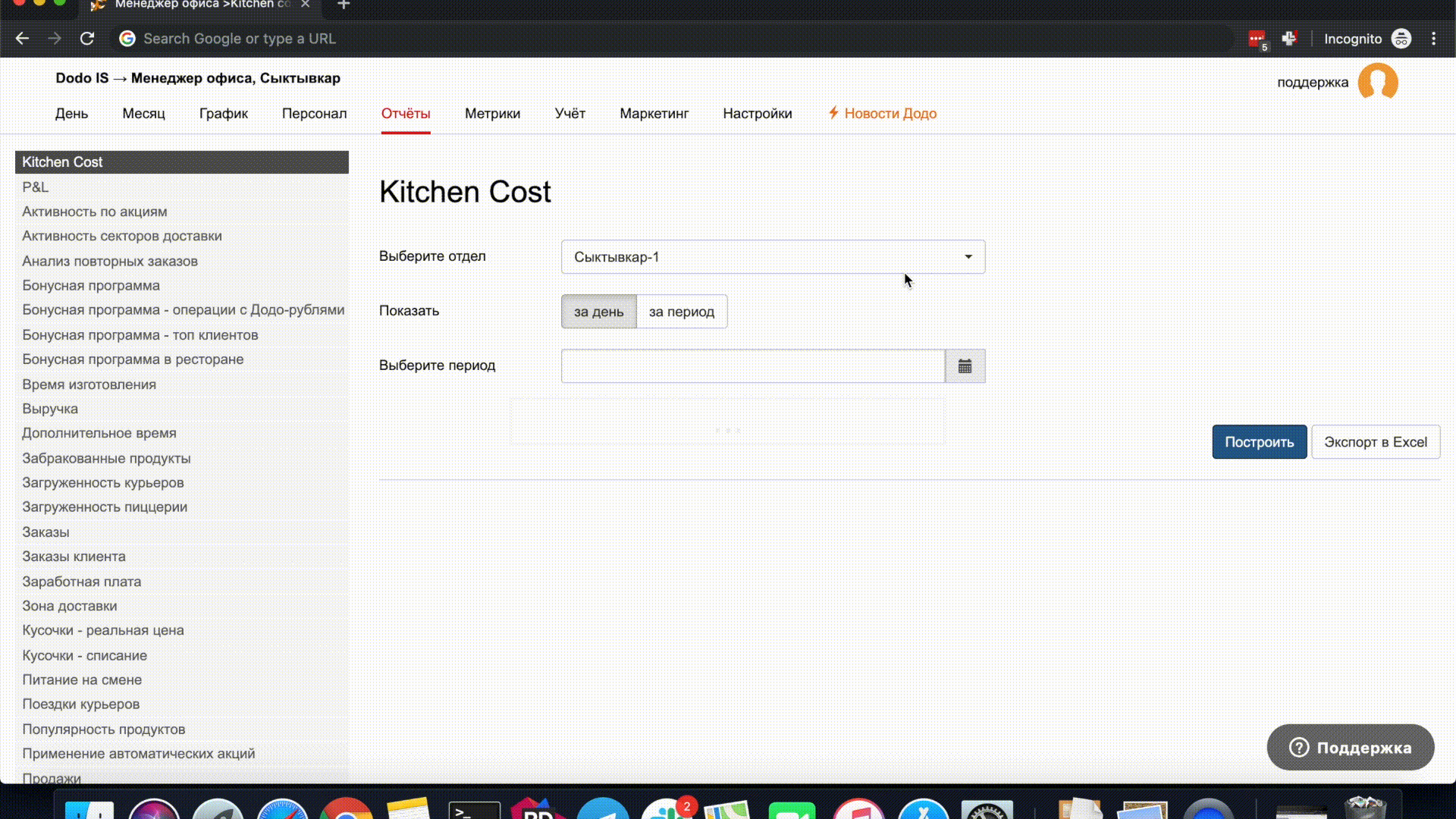
我怀疑在我们整个网络的整个生命周期中,除测试人员外,没有人没有重现此错误。 这些错误构成了大多数未修复的错误。
使用这种方法,当输入所有找到的错误时,其中一些会被重复,并且大多数错误都无法修复。
- 测试人员会感到沮丧,因为开发人员无法修复他们发现的错误。 人们会觉得工作没有意义。
- 产品负责人很难管理包含许多错误的积压订单。
再见了吉拉万岁Kaiten
在2018年春天,我们放弃了吉拉(Jira)并搬到了Kaiten。 工具的更改是由Andrei Arefiev在文章
“为什么Dodo Pizza开始使用Kaiten而不是一堆Trello和Jira的原因”中引起的。 迁移到Kaiten后,我们处理错误的方法没有改变:
- 缺陷记录在命令板上,开发人员独立决定是否修复它们。
- 回归中发现的错误(由专门的测试人员执行)在release分支中得到修复,并且直到所有问题都得到解决后才发布代码。 我们认为,在Slack的测试人员频道中保留和收集有关这些问题的信息将更加合乎逻辑。 测试人员写了一条消息,其中包含图例,带有日志的错误列表以及负责执行该任务的开发人员的姓名。 在表情符号的帮助下,他们更改了状态,并在交易中进行了讨论,应用了屏幕截图,进行了同步。 这种格式适合测试人员。 一些开发人员不喜欢这种方法,因为在聊天中并行存在另一个对应关系,并且此消息上升并且不可见。 我们修复了它,但是并没有大大简化生活。

- 在产品上发现的错误已记录在积压的产品所有者中,并对其进行了优先级排序并选择了我们将要修复的错误。
实验时间是否
我们决定尝试这些格式,并在Kaiten中创建了一个单独的面板,我们在该面板上保留了错误并更改了状态。 我们简化了错误报告的建立,以便花费更少的时间。 向Kaiten添加卡时,测试人员会标记开发人员。 关于此的通知已发送到他们的邮件。 我们将该板放置在工作场所附近过道上的监视器上,以便开发人员可以看到进度,并且测试过程变得透明。 这种做法也没有生根,因为主要的沟通渠道是Slack。 我们的开发人员不经常检查邮件。 因此,此解决方案很快停止工作,我们回到了Slack。
把蚂蚁带回来
在Kaiten中失败的电路板实验之后,一些开发人员仍然反对Slack中的消息格式。 我们开始思考如何跟踪松弛中的错误并解决妨碍开发人员的问题。 搜索的结果是,我遇到了Slack Workast的一个应用程序,该应用程序可以帮助在信使中与幼儿一起组织工作。 我们认为,该应用程序将使您可以更灵活地管理错误的处理过程。 该应用程序具有其优势:只需单击一个按钮,即可更改状态并分配给开发人员,隐藏了已完成的任务,并且消息没有增长到很大的规模。
因此,已解决的问题在Todo应用程序中查找并请求返回“蚂蚁”。 在Workast应用程序的试用期结束后,我们决定放弃它。 因为使用了此应用程序,所以我们得到了与使用Jira时相同的东西。 在此列表中,有些错误从回归到回归一直徘徊。 随着每次迭代,它们更多。 也许值得最终确定使用此扩展的过程,购买并使用它,但我们没有这样做。
我们现在处理错误的完美方法
在2018年底-2019年初,我们公司发生了许多更改,这些更改影响了使用Bug的过程。
首先,我们没有专门的测试人员团队。 所有测试人员分散到开发团队中,以增强测试团队的能力。 因此,在集成命令代码之前,我们开始更早地发现错误。
其次,我们放弃了手动回归测试,而选择了自动回归测试。
第三,我们采取了“零错误政策”。
bevzuk在文章“
#zerobugpolicy或我们如何修复错误 ”中详细介绍了如何选择我们修复的错误。
今天,处理错误的过程如下:
- 不足之处 。 测试人员将问题报告给分析师或产品经理。 他们走动,展示,复制,解释其将如何影响客户,并决定是否需要在发布前进行修复,还是可以在以后进行修复,或者根本不值得修复。
- 碰到系统这一部分的团队将修复自动测试发现的回归中的错误,直到解决问题,我们才会发布此代码。 测试人员可以在Slack的发行渠道上以任意格式修复这些错误。
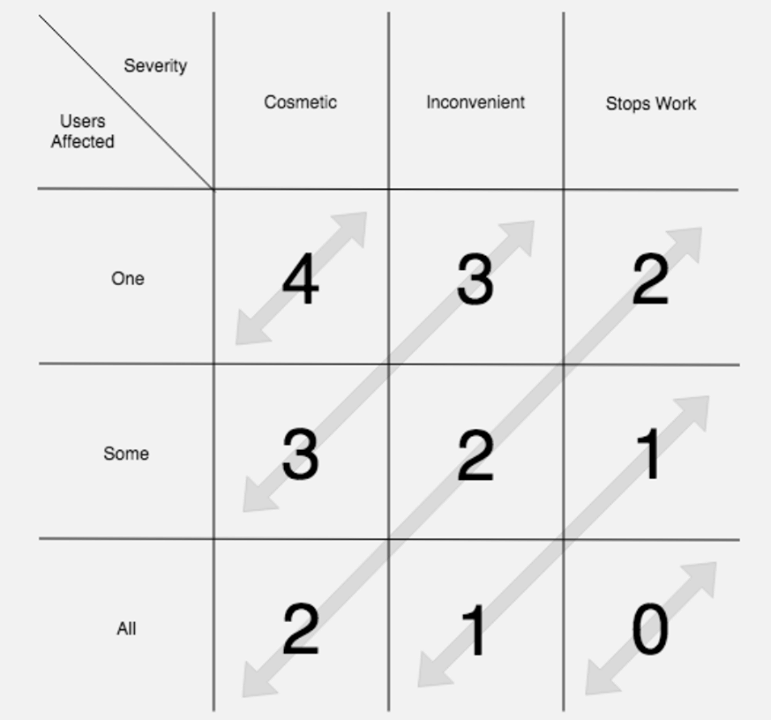
- 出售虫子 。 这些错误直接归任务所有者所有。 分析师会在错误的优先级矩阵上运行错误,然后将其添加到待办事项列表中或自行修复,从而累积了此问题的点击统计信息。
总结
简而言之,我们基本上放弃了错误跟踪系统 。 使用这种方法来处理错误,我们解决了许多难题:
- 测试人员不会感到烦恼,因为他们无法修复在错误跟踪中发现并触发的错误。
- 测试人员不会花时间在机构上,也没有人甚至不会阅读完整的错误描述。
- PO易于管理没有死负载的积压。
我不想说跟踪错误是没有用的。 像其他任务一样,我们跟踪工作中的错误。 但是,错误跟踪系统不是必需的测试属性。 不必仅因为大多数公司都在使用它,所以这是行业惯例。 您需要“头脑清醒”,并尝试适合您的流程和需求的工具。 非常适合我们现在不使用错误跟踪系统的情况下工作。 在半年的此类工作中,我们从未考虑过要重新使用它,并再次将所有错误收集在那里。
以及如何安排公司中的错误?