关于NLP基础知识的文章的第一部分可以在
这里阅读。 今天,我们将讨论最流行的NLP任务之一-命名实体识别(NER)-并详细分析该问题的解决方案的体系结构。
NER的任务是突出显示文本中实体的跨度(跨度是文本的连续片段)。 假设有一个新闻文本,并且我们想突出显示其中的实体(一些预先设置的实体-例如,人员,位置,组织,日期等)。 NER的任务是了解文本“
1997年1月1日 ”的部分是日期,“
Kofi Annan ”是人,“
UN ”是组织。
什么是命名实体? 在1995年
MUC-6会议上制定的第一个经典环境中,这些人,人员,地点和组织。 从那时起,出现了几个可用的程序包,每个程序包都有自己的一组命名实体。 通常,新的实体类型将添加到人员,位置和组织。 其中最常见的是数字(日期,金额),以及其他实体(来自其他-其他命名的实体;例如iPhone 6)。
为什么需要解决NER问题
容易理解的是,即使我们能够很好地识别文本中的人员,位置和组织,也不太可能引起客户的极大兴趣。 当然,尽管有些实际应用在经典环境中存在问题。
仍然需要经典表述中的问题解决方案的情况之一是非结构化数据的结构化。 假设您有某种文本(或一组文本),并且其中的数据必须输入数据库(表)中。 经典命名实体可以对应于此类表的行或用作某些单元格的内容。 因此,为了正确地填写表格,您必须首先在文本中选择要输入到其中的数据(通常在此之后还有另一步-当我们了解到
联合国和
联合国跨越时,确定文本中的实体”指的是同一组织;但是,标识或实体链接的任务是另一项任务,在本文中我们将不再详细讨论。
但是,有许多原因使NER成为最受欢迎的NLP任务之一。
首先,提取命名实体是迈向“理解”文本的一步。 这既可以具有独立的价值,又可以帮助更好地解决其他NLP任务。
因此,如果我们知道实体在文本中突出显示的位置,那么我们可以找到对某些任务很重要的文本片段。 例如,我们只能选择遇到某种类型的实体的那些段落,然后仅使用它们。
假设您收到一封信,那么只对有用的部分做一个摘要,而不只是“
Hello,Ivan Petrovich ”。 如果您可以区分命名的实体,则可以通过显示字母中我们感兴趣的实体所在的部分(而不是像通常那样显示字母的第一句话)来使代码段变得聪明。 或者,您可以仅在文本中突出显示信函的必要部分(或直接对我们重要的实体),以方便分析人员。
此外,实体是刚性且可靠的搭配;它们的选择对于许多任务可能很重要。 假设您有一个命名实体的名称,无论它是什么,很可能是连续的,并且所有与它有关的动作都需要像一个块一样执行。 例如,将实体的名称转换为实体的名称。 您希望将
“ Pyaterochka Shop”翻译成法语,而不是分成彼此不相关的多个片段。 检测并置的功能对于许多其他任务(例如,语法分析)也很有用。
如果不解决NER问题,就很难想象解决许多NLP问题的解决方案,例如,解决代词照应或建立问答系统。 代词照应词使我们能够理解代词所指的文本元素。 例如,让我们分析文字“
白马驰Charming ”
。 公主跑出去见他并吻了他 。“ 如果我们在“迷人”一词上强调“女神异闻录”的本质,那么机器将更容易理解,公主很可能不是亲吻马,而是亲吻白马王子。
现在,我们给出一个示例,说明如何分配命名实体来帮助构建问答系统。 如果您在自己喜欢的搜索引擎中问“
谁在电影《帝国反击战 》中
扮演了达斯·维达的角色 ”的问题
,那么“很有可能会得到正确的答案。 只需隔离命名的实体即可完成:我们选择实体(电影,角色等),了解我们的要求,然后在数据库中寻找答案。
NER任务如此受欢迎可能是最重要的考虑因素:问题陈述非常灵活。 换句话说,没有人强迫我们挑出地点,人员和组织。 我们可以选择所需的任何连续文本,这些文本与其余文本有所不同。 结果,您可以为来自客户的特定实际任务选择自己的实体集,用该集合标记文本主体并训练模型。 这种情况无处不在,这使NER成为业界最常执行的NLP任务之一。
我将给出一些来自特定客户的此类案例的示例,而我也曾参与其中。
这是第一个:让您有一组发票(汇款)。 每张发票都有一个文字说明,其中包含有关转帐的必要信息(谁,谁,何时,什么以及以什么原因发送)。 例如,X公司在某某某日将$ 10转移给Y公司。 文字很正式,但用活泼的语言写成。 银行经过专门培训的人员会阅读此文本,然后将其中包含的信息输入数据库。
我们可以选择一组与数据库表中的列相对应的实体(公司名称,转移金额,日期,转移类型等),并学习如何自动选择它们。 此后,仅需输入表中的选定实体,以前阅读文本并将信息输入数据库的人将能够执行更重要和有用的任务。
第二个用例是:您需要分析来自在线商店的订单的信件。 为此,您需要知道订单号(以便可以标记与此订单相关的所有字母或将其放在单独的文件夹中),以及其他有用的信息-商店名称,已订购商品清单,支票金额等。 -订单号,商店名称等-可以被视为命名实体,并且很容易学习如何使用我们现在将要分析的方法来区分它们。
如果NER如此有用,为什么不到处使用它?
为什么NER任务不能总是得到解决,而商业客户仍然愿意为其解决方案花最少的钱? 看起来一切都很简单:了解要突出显示的文本,然后突出显示。
但是在生活中,一切都不是那么容易,各种困难都会出现。
使我们无法解决各种NLP问题的经典复杂性是该语言中的各种歧义。 例如,多义词和同音异义词(请参阅
第1部分中的示例)。 与NER任务有直接关系的另一种同音异义词-完全不同的实体可以称为同一单词。 例如,让我们有“
华盛顿 ”一词。 这是什么 人,城市,州,商店名称,狗名,对象等? 为了将文本的这一部分突出显示为特定实体,需要充分考虑-本地上下文(前一文本所涉及的内容),全局上下文(关于世界的知识)。 一个人考虑到了所有这些,但是教一台机器来做到这一点并不容易。
第二个难题是技术难题,但不要小看它。 无论您如何定义实体,很可能都会出现一些边界和困难的情况-当您需要突出显示某个实体,何时您不需要在实体中包括什么,什么不包括什么时,等等。(当然,如果我们的本质是诸如电子邮件之类的微不足道的变量;但是,您通常可以通过琐碎的方法来区分此类琐碎的实体-编写正则表达式,而不考虑任何类型的机器学习。
例如,假设我们要突出显示商店的名称。
在文本“
专业金属探测器商店欢迎您 ”中,我们几乎可以肯定要在我们的本质中包括“商店”一词-这显然是名称的一部分。
另一个例子是“
Volkhonka Prestige,您最喜欢的品牌商店,价格合理,欢迎您 。” 注释中可能不应包含“商店”一词-显然这不是名称的一部分,而只是其描述。 另外,如果您在名称中包含此词,则还必须包含“-您的最爱”一词,也许这是我根本不想做的。
第三个示例:
“尼莫的宠物店写信给您。 ” 尚不清楚“宠物商店”是否是名称的一部分。 在这个例子中,似乎任何选择都是足够的。 但是,重要的是我们需要做出选择并将其固定在标记说明中,以便在所有文本中对这些示例进行均等的标记(如果不这样做,由于标记的矛盾,机器学习将不可避免地开始犯错误)。
有许多这样的边界示例,如果我们希望标记保持一致,则所有标记都需要包含在标记说明中。 即使示例本身很简单,也需要考虑和计算它们,这将使指令变得更大,更复杂。
好了,说明越复杂,您就需要更多合格的标记。 抄写员需要确定字母是否为订单文本是一回事(尽管这里有一些细微和边界情况),而抄写员需要阅读50页的说明,查找特定实体,理解要包括的内容是另一回事。注释,没有。
熟练的标记器很昂贵,通常不能很快地工作。 您肯定会花这笔钱,但是获得完美的加价完全不是事实,因为如果说明很复杂,那么即使是有资格的人也可能会犯错误并误解某些东西。 为了解决这个问题,使用了不同人对同一文本进行的多个标记,这进一步增加了标记价格和准备时间。 避免此过程,或者甚至认真地减少它是行不通的:要学习,您需要拥有合理大小的高质量培训集。
这是NER尚未征服世界的两个主要原因,以及为何苹果树仍未在火星上生长的两个主要原因。
如何理解NER问题是否已以优质方式解决
我将向您介绍一些人们用来评估其NER问题解决方案质量的指标以及标准案例。
我们任务的主要指标是严格的f值。 解释一下它是什么。
让我们拥有一个测试标记(系统工作的结果)和一个标准(相同文本的正确标记)。 然后,我们可以计算两个指标-准确性和完整性。 准确度是真实肯定实体(即我们在文本中选择的实体,也存在于标准中)相对于我们系统选择的所有实体的比例。 完整性是真实肯定实体相对于标准中存在的所有实体的一部分。 一个非常准确但不完整的分类器的一个示例是一个分类器,它选择文本中的一个正确对象,而没有选择其他对象。 一个非常完整但通常不准确的分类器的一个示例是在文本的任何段上选择一个实体的分类器(因此,除了所有标准实体之外,我们的分类器还会分配大量垃圾)。
F度量是准确性和完整性的谐波平均值,这是一种标准度量。
如我们在上一节中所述,创建标记非常昂贵。 因此,很少有带有标记的可访问建筑物。
英语有多种选择-在受欢迎的会议上,人们竞争解决NER问题(并为竞赛创建标记)。 建立其具有指定实体的机构的此类会议的示例为MUC,TAC,CoNLL。 所有这些情况几乎全部由新闻文本组成。
评估NER问题解决质量的主要依据是CoNLL 2003案例(这里是
案例本身的
链接 ,在此是
有关此文章的文章 )。 大约有30万个令牌和多达1万个实体。 现在,SOTA系统(最新技术-即目前最好的结果)在这种情况下显示了0.93量级的f度量。
对于俄语,一切都更加糟糕。 有一个公共机构(
FactRuEval 2016 ,这是
有关该机构的文章 ,这是
有关Habré的文章 ),它很小,只有5万个代币。 在这种情况下,情况非常具体。 特别是,LocOrg(在组织环境中的位置)颇具争议的本质在该案例中脱颖而出,这与组织和位置都混淆了,因此,后者的选择质量比应有的低。
如何解决NER问题
将NER问题简化为分类问题
尽管实体通常很冗长,但NER任务通常归结为令牌级别的分类问题,即每个令牌都属于几种可能的类别之一。 有几种标准的方法可以执行此操作,但是最常见的方法称为BIOES方案。 该方案是在实体标签上添加一些前缀(例如,人的PER或组织的ORG),以指示令牌在实体范围内的位置。 更多详细信息:
B-从单词开头开始-实体范围内的第一个标记,由多个单词组成。
我-从内部的话-这就是中间。
E-从单词结尾开始,这是实体的最后一个标记,由多个元素组成。
S是单身。 如果实体由一个单词组成,则添加此前缀。
因此,我们向每种类型的实体添加4个可能的前缀之一。 如果令牌不属于任何实体,则用特殊标签标记,通常标记为OUT或O。
我们举一个例子。 让我们输入文字“
卡尔·弗里德里希·杰罗姆·冯·蒙克豪森出生于博登韦德 。” 这里有一个冗长的实体-人“ Karl Friedrich Jerome vonMünhausen”和一个一词一个-位置“ Bodenwerder”。
因此,BIOES是将跨度的投影或注释映射到令牌级别的一种方法。
显然,通过此标记,我们可以明确地建立所有实体注释的边界。 的确,对于每个令牌,我们都知道一个实体以该令牌开头还是以该令牌结尾是否正确,这意味着是要在给定令牌上结束实体的注释,还是将其扩展到下一个令牌。
绝大多数研究人员都使用这种方法(或带有较少标签的变体-BIOE或BIO),但是它有几个明显的缺点。 最主要的是该方案不允许使用嵌套或相交的实体。 例如,
以M.V. 罗蒙诺索夫 ”是一个组织。 但是罗蒙诺索夫本人是一个人,在标记中询问也将很高兴。 使用上述标记方法,我们永远无法同时传达这两个事实(因为我们只能在一个令牌上做一个标记)。 因此,“罗蒙诺索夫”令牌可以是组织注释的一部分,也可以是个人注释的一部分,但不能同时存在。
嵌入式实体的另一个示例:“
莫斯科国立大学力学与数学学院的数学逻辑与算法理论系 ”。 在理想情况下,在这里,我想区分3个嵌套的组织,但是上述标记方法允许您选择3个不相交的实体,或者选择一个对整个片段进行注释的实体。
除了将任务简化为令牌级别分类的标准方法之外,还有一种标准数据格式,在该数据格式中,可以方便地存储NER任务(以及许多其他NLP任务)的标记。 此格式称为
CoNLL-U 。
格式的主要思想是这样的:我们以表的形式存储数据,其中一行对应一个令牌,列对应一种特定类型的令牌属性(包括单词本身,单词形式)。 从狭义上讲,CoNLL-U格式定义了表中包括哪些类型的功能(即列),每个令牌共有10种类型的功能。 但是研究人员通常会更广泛地考虑格式,并包括特定任务所需的功能类型以及解决该问题的方法。
以下是类似CoNLL-U格式的数据示例,其中考虑了6种类型的属性:文本中当前句子的编号,单词形式(即单词本身),引词(初始单词形式),POS标签(词性),形态单词的特征,最后是在此令牌上分配的实体的标签。

您之前是如何解决NER问题的?
严格来讲,借助基于规则的系统(在最简单的版本中借助正则表达式),无需机器学习即可解决问题。 这似乎过时且无效,但是,您需要了解主题范围是否有限且定义明确,以及该实体本身没有太多可变性,那么可以使用基于规则的方法相当快速而有效地解决NER问题。
, (, ), , .
, ( ), . .
, 2000- SOTA . , .
, — . . . , ( ), 1, 0.
, (POS-), ( — , , ), (. . ), (, ), .
, , :
- “ , ”,
- “ ”,
- “ ”,
- “ ” ( , , “iPhone”).
, , - , — .
, – . , , , – , , , – , , , – . , (“” , “” — ), . , , , — ( , NER 2 — ).
, NER, ,
Nadeau and Sekine (2007), A survey of Named Entity Recognition and Classification . , , , ( - , , , HMM, , , , ), .
(summarized pattern ). NLP. , 2018
(word shape) .
NER ?
NLP almost from scratch
NER
2011 .
SOTA- CoNLL 2003. , . ML , .
NER , , NLP . , , , , . , NER ( , NLP).
, .
, :
- «» (window based approach),
- (sentence based approach).
– , – , .. , .
: , “
The cat sat on the mat ”.
K (, , , , . .). (, , 1 ). 让

— , i- j- .
, sentence based approach , , — , . i i-core, core — , ( , , ).
—
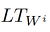
, Lookup Table ( “” ). ,
— , 1, – 0.
在
, . .
( i 1 K) – , .
word2vec ( , word2vec, ) , , word2vec ( ).
, ,
在
。
, sentence based approach (window based ). , (. . “The cat sat on the mat” 6 ). , , , — core.
: 3-5. , , ( ). m f, m — , (. . ), f — .
, — max pooling (. . ), f. , , , core, (max pooling , , ). “ ” , , core.
- ( — HardTanh), softmax d, d — .
, , — ( ), softmax — , core.
CharCNN-BLSTM-CRF
CharCNN-BLSTM-CRF, , SOTA 2016-2018 ( 2018 , NLP ; ). NER
Lample et al (2016) Ma & Hovy (2016) .
, NLP,
.
- . . – , – , — : , . . - .
. , , . — . Lookup- , , .
, .
, . — , , ( , ).
CharCNN ( , CharRNN). , - . - (, 20) — . , — , .
, , , , — ( ). - , .
2 .
– ( CharCNN). , sentence based approach .
, (, 3), . max pooling, 1 . .
– (BLSTM BiGRU; ,
). RNN.
, - . - .
BLSTM BiGRU. i- , RNN. ( RNN), ( RNN). - .
NLP, NLP.
, , NER. - , . .
– softmax d, d — . ( ).
, — . BiRNN, , . , I-PER B-PER I-PER.
— CRF (conditional random fields). , (
), , CRF , .
, CharCNN-BLSTM-CRF, SOTA NER 2018 .
. CharCNN f- 1%, CRF — 1-1.5%, ( multi-task learning,
Wu et al (2018) ). BiRNN — , , ,
.
, NER. , , .
,
NLP Advanced Research Group