哈Ha!
我们提醒您,关于
Kafka的书之后,我们在
Kafka Streams API库上发布了同样有趣的作品。

到目前为止,社区仅理解此强大工具的局限性。 因此,最近发表了一篇文章,我们希望将其翻译介绍给您。 根据他自己的经验,作者讲述了如何从Kafka Streams建立分布式数据仓库。 祝您阅读愉快!
全球范围内的Apache
Kafka Streams库在企业中用于Apache Kafka之上的分布式流处理。 此框架被低估的方面之一是,它允许您存储基于流处理的本地状态。
在本文中,我将向您介绍我们公司如何成功地利用这一机会来开发用于云应用程序安全性的产品。 使用Kafka Streams,我们创建了共享服务微服务,每个微服务都充当了有关系统中对象状态的可靠信息的容错和高度可访问的来源。 对于我们来说,这在可靠性和易于支持方面都是向前迈出的一步。
如果您对允许您使用单个中央数据库来支持对象的正式状态的替代方法感兴趣-读取,这将很有趣...
为什么我们认为是时候改变我们在共享状态下工作的方式了我们需要根据代理报告维护各种对象的状态(例如:该站点是否受到攻击)? 切换到Kafka Streams之前,我们通常依靠单个中央数据库(+服务API)来管理状态。 这种方法有其缺点:在
数据密集型情况下,对一致性和同步的支持变成了真正的挑战。 数据库可能会成为瓶颈,或者可能处于
竞争状态并遭受不可预测的影响。
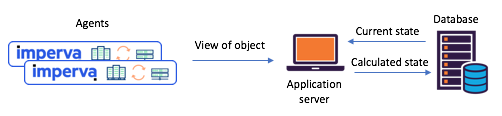 图1:过渡到过渡之前遇到的典型分裂状态场景
图1:过渡到过渡之前遇到的典型分裂状态场景
Kafka和Kafka Streams:代理商通过API交流其提交的信息,更新状态通过中央数据库计算认识Kafka Streams-现在可以轻松创建共享状态微服务大约一年前,我们决定彻底审查我们的共享状态方案,以解决此类问题。 我们立即决定尝试使用Kafka Streams-我们知道它的可伸缩性,高度可访问性和容错能力,其流传输功能的丰富性(转换,包括有状态转换)。 正是我们需要的,更不用说Kafka消息系统的成熟和可靠。
我们创建的每个状态保留微服务都是基于具有相当简单拓扑的Kafka Streams实例构建的。 它由1)源2)带有键和值的永久存储的处理器3)消耗组成:
 图2:我们的有状态微服务流实例的默认拓扑。 请注意,还有一个包含计划元数据的存储库。
图2:我们的有状态微服务流实例的默认拓扑。 请注意,还有一个包含计划元数据的存储库。使用这种新方法,代理可以编写传递到原始主题的消息,而消费者(例如,邮件通知服务)可以通过库存(输出主题)接受计算出的共享状态。
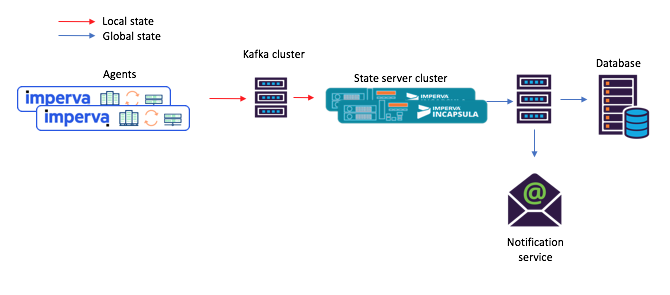 图3:具有共享微服务的场景的任务流程的新示例:1)代理生成一条消息,消息到达原始的Kafka主题; 2)具有共享状态的微服务(使用Kafka Streams)对其进行处理,并将计算出的状态写入最终的Kafka主题; 之后3)消费者接受新状态嘿,这个内置的键和值存储库实际上非常有用!
图3:具有共享微服务的场景的任务流程的新示例:1)代理生成一条消息,消息到达原始的Kafka主题; 2)具有共享状态的微服务(使用Kafka Streams)对其进行处理,并将计算出的状态写入最终的Kafka主题; 之后3)消费者接受新状态嘿,这个内置的键和值存储库实际上非常有用!如上所述,我们的共享状态拓扑包含键和值的存储。 我们找到了几种使用方法,下面将对其中两个进行说明。
选项#1:使用密钥库和值存储区进行计算我们的第一个键和值存储库包含计算所需的辅助数据。 例如,在某些情况下,共享状态是根据“多数投票”原则确定的。 在存储库中,可以保留有关某个对象状态的所有最新代理报告。 然后,从代理接收新报告,我们可以将其保存,从所有其他代理中提取有关存储库中同一对象状态的报告,然后重复计算。
下面的图4显示了我们如何打开对键和值存储区的访问,以访问处理器的处理方法,从而可以处理新消息。
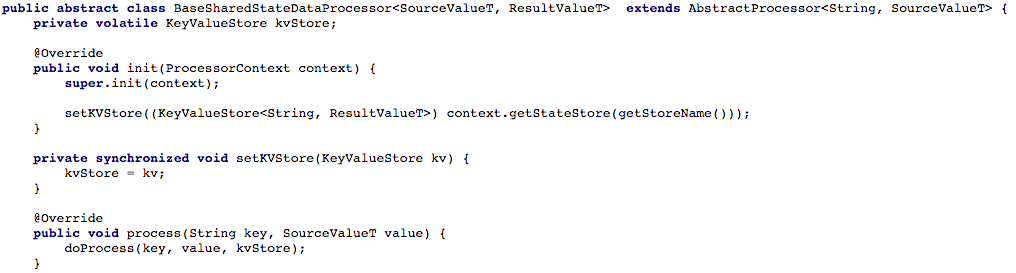 图4:我们打开了对处理器处理方法的键和值的存储的访问权限(此后,在每个处于共享状态的脚本中,您必须实现
图4:我们打开了对处理器处理方法的键和值的存储的访问权限(此后,在每个处于共享状态的脚本中,您必须实现doProcess方法)选项2:在Kafka Streams上创建CRUD API调整了基本任务流程后,我们开始尝试为共享服务微服务编写RESTful CRUD API。 我们希望能够检索某些或所有对象的状态,以及设置或删除对象的状态(这在服务器端的支持下很有用)。
为了支持所有Get State API,每当需要在处理过程中重新计算状态时,我们都会将其长时间放置在内置的键和值存储库中。 在这种情况下,使用单个Kafka Streams实例来实现这样的API变得非常简单,如下面的清单所示:
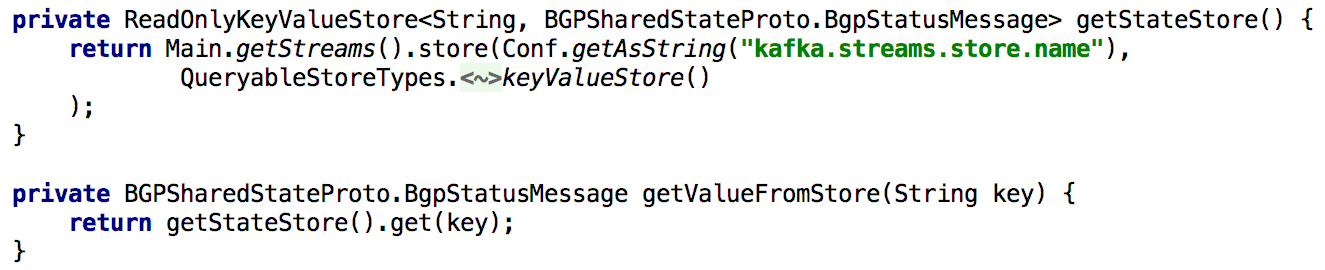 图5:使用内置的键和值存储来获取对象的预先计算状态
图5:使用内置的键和值存储来获取对象的预先计算状态通过API更新对象的状态也很容易实现。 原则上,为此,您只需要创建一个生产者Kafka,并在其帮助下进行记录以创建新状态。 这样可以确保通过API生成的所有消息的处理方式都与从其他生产者(例如代理)接收到的消息相同。
 图6:您可以使用生产者Kafka设置对象的状态一个小麻烦:Kafka有很多分区。
图6:您可以使用生产者Kafka设置对象的状态一个小麻烦:Kafka有很多分区。接下来,我们想通过为每种情况提供一个共享服务微服务集群来分配处理负载并提高可用性。 设置过程尽可能地简单:在配置完所有实例,使它们使用相同的应用程序ID(和相同的引导服务器)后,几乎所有其他事情都会自动完成。 我们还设置了每个源主题将由几个分区组成,以便可以为每个实例分配此类分区的子集。
我还要提到,为状态存储创建备份副本是正常的,例如,在发生故障后恢复的情况下,可以将该副本转移到另一个实例。 对于Kafka Streams中的每个状态存储,都会使用更改日志(在其中跟踪本地更新)创建复制的主题。 因此,Kafka不断地保护状态存储。 因此,如果一个或另一个Kafka Streams实例发生故障,则状态存储可以快速恢复到另一个实例,在该实例中相应的分区将进入。 我们的测试表明,即使存储库中有数百万条记录,也可以在几秒钟内完成此操作。
从一个共享服务微服务转移到一个微服务集群,实现Get State API变得不那么简单。 在新情况下,每个微服务的状态存储库仅包含整体图片的一部分(那些对象的键已映射到特定分区)。 我们必须确定在哪个实例上包含了我们所需对象的状态,并根据流元数据执行了此操作,如下所示:
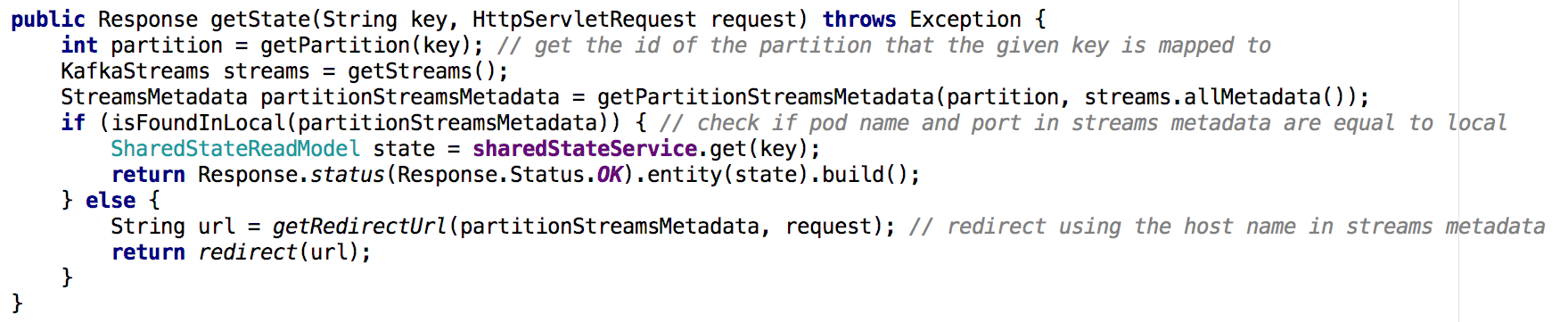 图7:使用流元数据,我们确定从哪个实例请求所需对象的状态; GET ALL API使用了类似的方法主要发现
图7:使用流元数据,我们确定从哪个实例请求所需对象的状态; GET ALL API使用了类似的方法主要发现实际上,Kafka Streams中的状态存储可以充当分布式数据库,
- 在卡夫卡连续复制
- 在这样的系统之上很容易构建CRUD API
- 处理多个分区要复杂一些
- 也可以将一个或多个状态存储添加到流拓扑以存储辅助数据。 此选项可用于:
- 长期存储流处理中计算所需的数据
- 数据的长期存储,在下次初始化流实例时可能会有用
- 更多...
由于这些优点和其他优点,Kafka Streams非常适合在像我们这样的分布式系统中支持全球地位。 事实证明,Kafka Streams在生产中非常可靠(从部署之时起,我们几乎没有丢失任何消息),并且我们确信其功能不限于此!