从高级开发人员Sergey Murylyov的报告中,您可以了解标准库的多线程关联容器,该容器正在作为WG21的一部分进行开发。 Sergey谈到了针对该问题的流行解决方案的利弊,以及开发人员选择的路径。
-您可能已经从标题中猜测到,今天的报告将涉及我们如何在21工作组的框架内制造类似于std :: unordered_map的容器,但是是针对多线程环境的。
在许多编程语言(Java,C#,Python)中,这种语言已经存在并且被广泛使用。 但是,在我们心爱的,最快,最高效的C ++中,这没有发生。 但是我们咨询并决定做这样的事情。

在向标准中添加某些内容之前,您需要考虑人们将如何使用它。 然后建立一个更正确的界面,该界面很可能会由委员会采用-最好不做任何修改。 这样一来,最终就不会让他们做一件事,但结果却是另一件事。
最著名和广泛使用的选项是缓存大型计算。 有一个相当知名的Memcached服务,该服务只是将Web服务器响应缓存在内存中。 显然,如果您拥有竞争性的关联容器,则可以在应用程序方面执行几乎相同的操作。 两种方法各有利弊。 但是,如果您没有这样的容器,则必须自己制造自行车或使用某种Memcached。
另一个流行的用例是事件重复数据删除。 我认为会议室中的许多人都在编写各种分布式系统,并且知道经常使用分布式队列在组件之间进行通信,例如Apache Kafka和Amazon Kinesis。 它们的特点是可以多次向一个消费者发送一条消息。 这被称为至少一次交货,这意味着至少一次交货保证:更多的可能,更少的不可能。
从现实生活的角度考虑这一点。 想象一下,我们有一些聊天室或社交网络的后端,在此进行消息传递。 这可能导致以下事实:某人写了一条消息,后来某人在其手机上多次收到了推送通知。 显然,如果用户看到此内容,他们将不会对此感到满意。 有人认为,使用如此出色的多线程容器可以解决此问题。
下一个使用频率较低的情况是,我们只需要在服务器端的某个位置保存一些内容,为用户保存一些元数据。 例如,我们可以节省用户上次进行身份验证的时间,以了解何时应在下次询问用户名和密码。
此幻灯片上的最后一个选项是统计。 从现实生活的应用程序中,可以给出在Facebook虚拟机中使用的示例。 他们制作了一个完整的虚拟机来优化PHP,并在其虚拟机中尝试将调用它们的参数记入所有内置函数的多线程哈希表中。 而且,如果他们在缓存中有结果,那么他们会尝试立即将其分发出去,而不计算任何内容。

向标准中添加大而复杂的内容并非易事,而且也不是很快。 通常,如果添加了一些较大的内容,则会通过技术规范。 当前,该标准在扩展标准库中的多线程支持方面做了大量工作。 具体来说,关于多线程队列的建议P0260R3现在正在进行。 该建议是关于与我们非常相似的数据结构,并且我们的设计决策在许多方面都非常相似。
实际上,它们设计的基本概念之一是它们的接口与标准std :: queue不同。 有什么意义? 如果查看标准队列,则要从中提取元素,您需要执行两项操作。 您需要先进行计数才能操作,而弹出操作则需要删除。 如果我们在多线程条件下工作,那么在这两个调用之间的队列上可能会有某种操作,并且可能发生是我们考虑了一个元素并删除了另一个元素,这在概念上似乎是错误的。 因此,这两个调用在那里被替换为一个,并添加了更多来自try push和try pop类别的调用。 但是一般的想法是,多线程容器将与普通接口不同。
多线程队列还具有解决多种不同任务的许多不同实现。 最常见的任务是生产者和消费者的任务,当我们有一些线程产生一些任务,并且有一些线程从队列中取出任务并对其进行处理时。
第二种情况是当我们只需要某种同步队列时。 对于制造商和消费者,我们得到的队列仅限于顶部和底部。 相对而言,如果我们尝试从空队列中提取内容,那么我们将进入等待状态。 如果我们尝试添加不适合队列大小的内容,则同样的事情会大致发生。
另外,在此提案中描述了我们有一个单独制作的接口,该接口使我们能够区分锁或无锁内部具有哪种实现。 提案中的所有地方都是无锁的,事实上,它是在书中以无等待的方式编写的。 这意味着我们的算法可以计算出固定数量的操作。 那里的无锁意味着有些不同,但这不是重点。
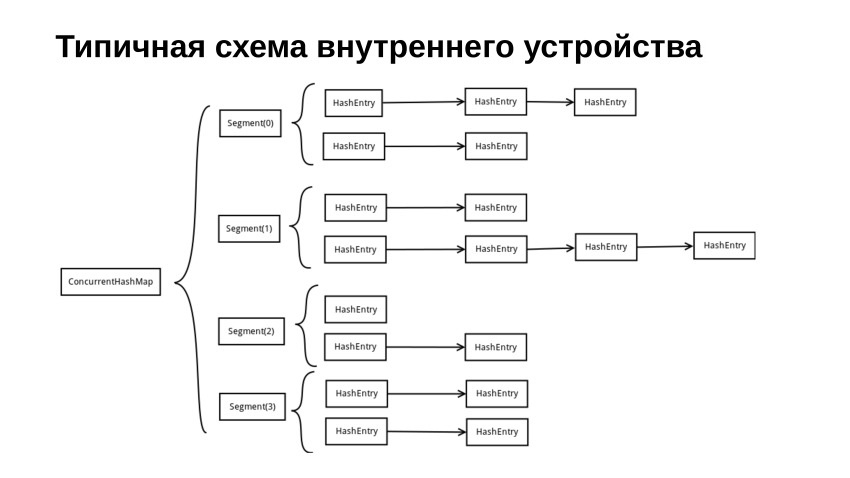
让我们看一个典型的图表,说明如果哈希表被阻止,它将如何实现。 我们将其分为多个部分。 通常,每个段都包含某种锁,例如Mutex,Spinlock或更棘手的东西。 除Mutex或Spinlock外,它还包含通常的哈希表,该哈希表受此业务保护。
在这张照片中,我们有一个哈希表,该哈希表是在列表上创建的。 实际上,在我们的参考实现中,出于性能原因,我们编写了带有开放寻址的哈希表。 性能方面的考虑与为什么std :: vector比std :: list更快的原因基本相同,因为相对而言,向量是顺序存储在内存中的。 进行操作时,我们具有顺序访问权,该访问权得到了很好的缓存。 如果我们使用某种类型的工作表,则在内存的不同部分之间会有各种跳跃。 整个事情通常以我们失去生产力的事实结束。
首先,当我们想在此哈希表中查找内容时,我们从键中获取哈希码。 您可以将其取模,然后对其进行其他操作,以便获得段号,并且在该段中查找,就像在常规哈希表中一样,但是当然,我们同时取了锁。

我们设计的主要思想。 当然,我们也创建了与std :: unordered_map不匹配的接口。 原因是这样的。 例如,在普通的std :: unordered_map中,我们拥有迭代器之类的奇妙功能。 首先,并非所有实现都能正常支持它们。 通常,那些可以支持的无锁实现需要垃圾回收或某种智能指针来清理其背后的内存。
除此之外,我们还进行了其他几种操作。 实际上,迭代器在很多地方。 例如,它们使用Java。 但是,通常来说,奇怪的是,它们不在那里同步。 而且,如果您尝试从不同的线程对它们进行处理,那么它们很容易进入无效状态,并且您可能会在Java中获得异常,并且如果您在加号上编写此异常,那么很可能是未定义的行为,甚至更糟。 顺便说一句,关于未定义行为的主题:我认为,Facebook的同志们在他们的愚蠢的库中做到了这一点,该库发布在GitHub的开源中。 刚刚使用Java复制了接口并获得了如此出色的迭代器。
我们也没有内存不足的投诉,也就是说,如果我们向容器中添加了一些东西并为其保留了内存,即使我们删除了所有内容,我们也不会将其归还。 做出此决定的另一个先决条件是我们有一个内部带有开放地址的哈希表。 它适用于线性数据结构,就像矢量一样,它不会返回内存。
下一个概念性时刻是,在任何情况下我们都不会向任何人发出外部链接和指向内部对象的指针。 正是这样做是为了避免需要垃圾回收,而不是强制执行智能指针。 显然,如果我们存储足够大的对象,则按值将它们存储在内部将是无利可图的。 但是,在这种情况下,我们总是可以将它们包装在我们选择的某种智能指针中。 并且,例如,如果我们想对值进行某种类型的同步,则可以将它们包装在某种类型的boost :: synced_value中。
我们看到了一个事实,即前一段时间,从返回该对象的活动链接数的方法中删除了shared_ptr类。 我们得出的结论是,我们还需要抛出几个函数,即size,count,empty,buckets_count,因为一旦我们从该函数返回该值,该值便立即不再有效,因为有人可以改变同一时刻。
在之前的一次会议上,他们要求我们添加一种模式,以便我们可以以单线程模式访问容器,例如常规的std :: unordered_map。 这样的语义使我们能够清楚地区分在多线程模式下工作的地方和不工作的地方。 为了避免人们使用多线程容器时出现的不愉快情况,请期望一切都会好起来,使用迭代器,然后突然发现一切都不好。

在夏威夷的这次会议上,对我们提出了整个提案。 :)我们被告知,这些事情在标准中没有任何地位,因为有很多方法可以创建多线程关联容器。
每个人都有其优点和缺点-尚不清楚如何使用我们最终成功的方法。 通常,在需要某种极端性能时使用它。 似乎我们的盒装解决方案不适合,需要针对每种特定情况进行优化。
该建议的第二点是,我们的界面与Facebook从其标准库发布到GitHub的事实不兼容。
实际上,那里没有特别的问题。 只是有一个问题来自“我没有读过,但遭到了谴责”。 他们只是看了-接口不同,这意味着它不兼容。
该提案的想法还在于,当需要创建一个附加的模板参数时,可以在其中传递一个我们希望启用和禁用其功能的位掩码,然后借助所谓的基于策略的设计来解决类似的任务。 确实,这听起来有些疯狂,并导致我们得到约2 ^ n个实现的事实,其中n是不同功能的数量。

在代码中,看起来像这样。 我们有一些参数和可以在此处传递的一些预定义常量。 奇怪的是,这项提议被拒绝了。

因为实际上,委员会已经采取了这样的立场,即当多线程队列通过SG1时,这种情况应该发生。 甚至没有对该问题进行投票。 但是有两个问题付诸表决。
第一个 许多人希望我们在参考实现方面能够支持阅读而无需任何锁定。 这样我们就可以完全不阻塞阅读。 这确实是有道理的:通常,最流行的用户案例是缓存。 快速阅读对我们非常有益。
第二刻 每个人都从前一个朋友那里听到很多,他们谈到基于策略的设计。 每个人都有一个主意-但是,我也要谈谈我的主意! 每个人都投票赞成基于策略的设计。 虽然我必须说,整个故事已经进行了相当长的时间,但在我们之前,我们的英特尔,阿奇·罗宾逊和安东·马拉霍夫的同事正在这样做。 他们已经对此问题提出了一些建议。 他们只是提议添加基于
SeepOrderedList算法的无锁实现。 他们还针对内存投诉采用了基于策略的设计。
这个提议不喜欢图书馆发展工作组。 结束语的原因是我们将简单地无限增加标准中的单词数。 充分地预览和简单地在代码中实现根本是不可能的。
我们对这些想法本身没有任何评论。 在大多数情况下,我们对参考实现有意见。 当然,我们可以引入一些思路使之更加清晰。 但基本上,下一次我们将采用相同的建议。 我们真诚地希望,与模块一样,我们不会有五个提案相同的电话。 我们真诚地相信自己,我们将被允许继续进行下一个电话会议,而且图书馆演进工作组将仍然坚持我们的意见,并且不允许我们进行基于策略的设计。 因为我们的对手不会停止。 他决定向所有人证明这是必要的。 但是正如他们所说,时间会证明一切。 我拥有一切,谢谢您的关注。