
无论该人是在互联网上阅读新闻还是在世界著名的经典小说中阅读,每个人都独特地感知文本。 这也适用于各种算法和机器学习技术,它们以更数学的方式(即,使用高维向量空间)理解文本。
本文致力于使用t-SNE可视化高维Word2Vec词嵌入。 可视化对于了解Word2Vec的工作原理以及在神经网络或其他机器学习算法中使用它们之前,如何解释从文本中捕获的向量之间的关系非常有用。 作为培训数据,我们将使用Google新闻中的文章以及列奥·托尔斯泰(Leo Tolstoy)的古典文学作品,列奥·托尔斯泰被认为是有史以来最伟大的作家之一。
我们简要介绍了t-SNE算法,然后转到使用Word2Vec进行单词嵌入计算,最后,在2D和3D空间中使用t-SNE进行单词矢量可视化。 我们将使用Jupyter Notebook用Python编写脚本。
T分布随机邻居嵌入
T-SNE是一种基于非线性降维技术的用于数据可视化的机器学习算法。 t-SNE的基本思想是减少维空间,保持点之间的相对成对距离。 换句话说,该算法将多维数据映射到二维或更多维,其中最初彼此相距较远的点也位于相距较远的地方,并且接近点也转换为接近点。 可以说,t-SNE正在寻找保留邻域关系的新数据表示形式。 t-SNE整个逻辑的详细说明可以在原始文章[1]中找到。
Word2Vec模型
首先,我们应该获得单词的向量表示。 为此,我选择了Word2vec [2],即用于从原始文本数据中学习多维单词嵌入的计算有效的预测模型。 Word2Vec的关键概念是在向量空间中与其他词相比,将在训练语料库中共享通用上下文的词定位得很近。
作为可视化的输入数据,我们将使用Google新闻的文章和列夫·托尔斯泰的一些小说。 Google在
官方页面上发布了在Google新闻数据集的一部分(约1000亿个单词)上经过训练的预训练向量,因此我们将使用它。
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
除了预训练的模型外,我们还将使用Gensim [3]库在托尔斯泰的小说中训练另一个模型。 Word2Vec将句子作为输入数据,并生成单词向量作为输出。 首先,有必要下载经过预训练的Punkt Sentence Tokenizer,它将考虑到缩写词,搭配词和单词(可能指示句子的开始或结束),将文本分为句子列表。 默认情况下,NLTK数据包不包含针对俄语的经过预先训练的Punkt令牌生成器,因此我们将使用
github.com/mhq/train_punkt中的第三方模型。
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
在Word2Vec培训阶段,使用了以下超参数:
- 特征向量的维数为200。
- 句子中分析的单词之间的最大距离是5。
- 忽略所有语料的总频率低于5的所有单词。
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
使用t-SNE可视化单词嵌入
如果需要可视化位于多维空间中的对象之间的相似性,则T-SNE非常有用。 对于大型数据集,制作易于阅读的t-SNE图变得越来越具有挑战性,因此通常的做法是可视化最相似单词的组。
让我们从经过预训练的Google新闻模型的词汇表中选择几个单词,并准备单词向量以进行可视化。
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
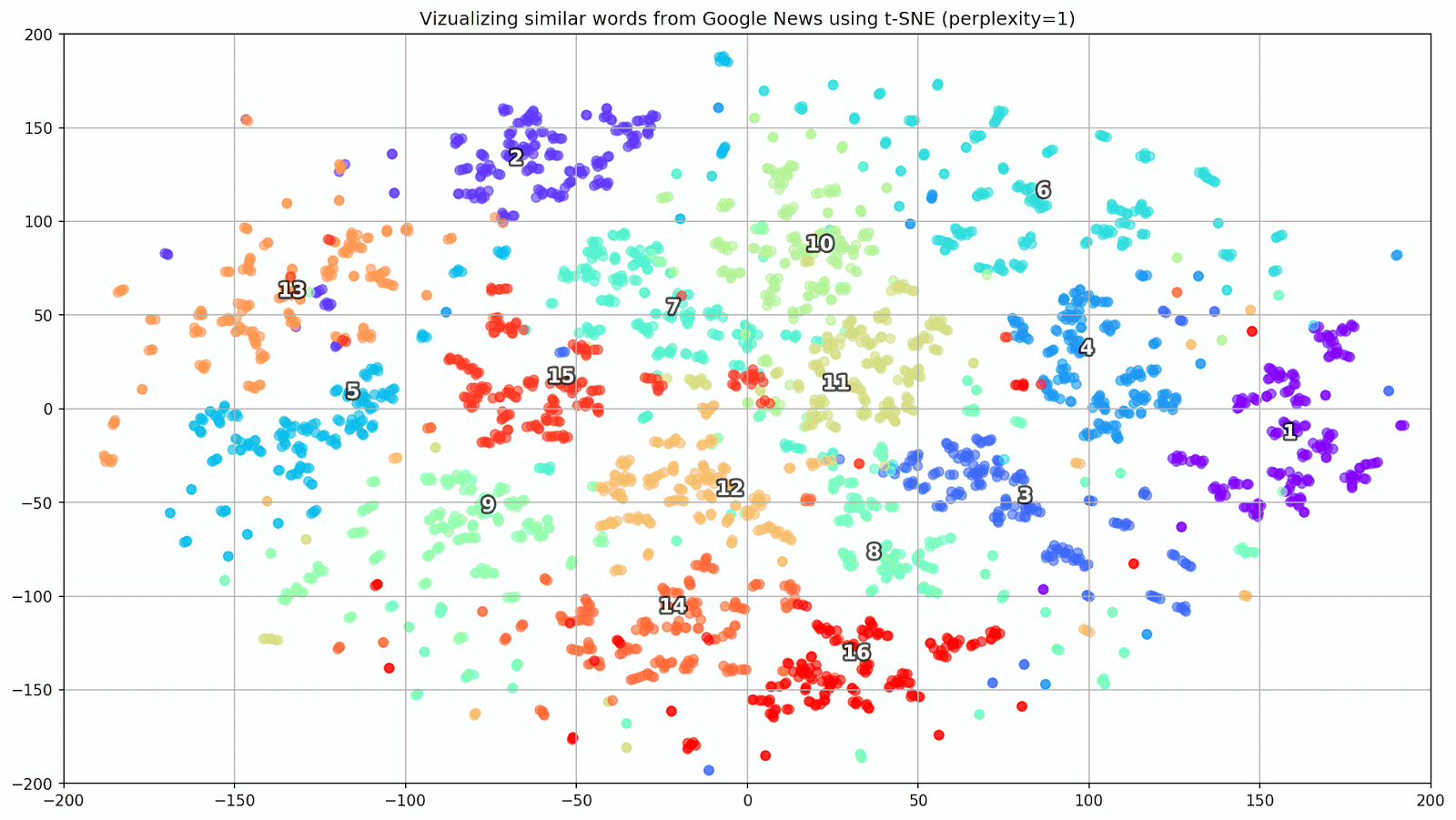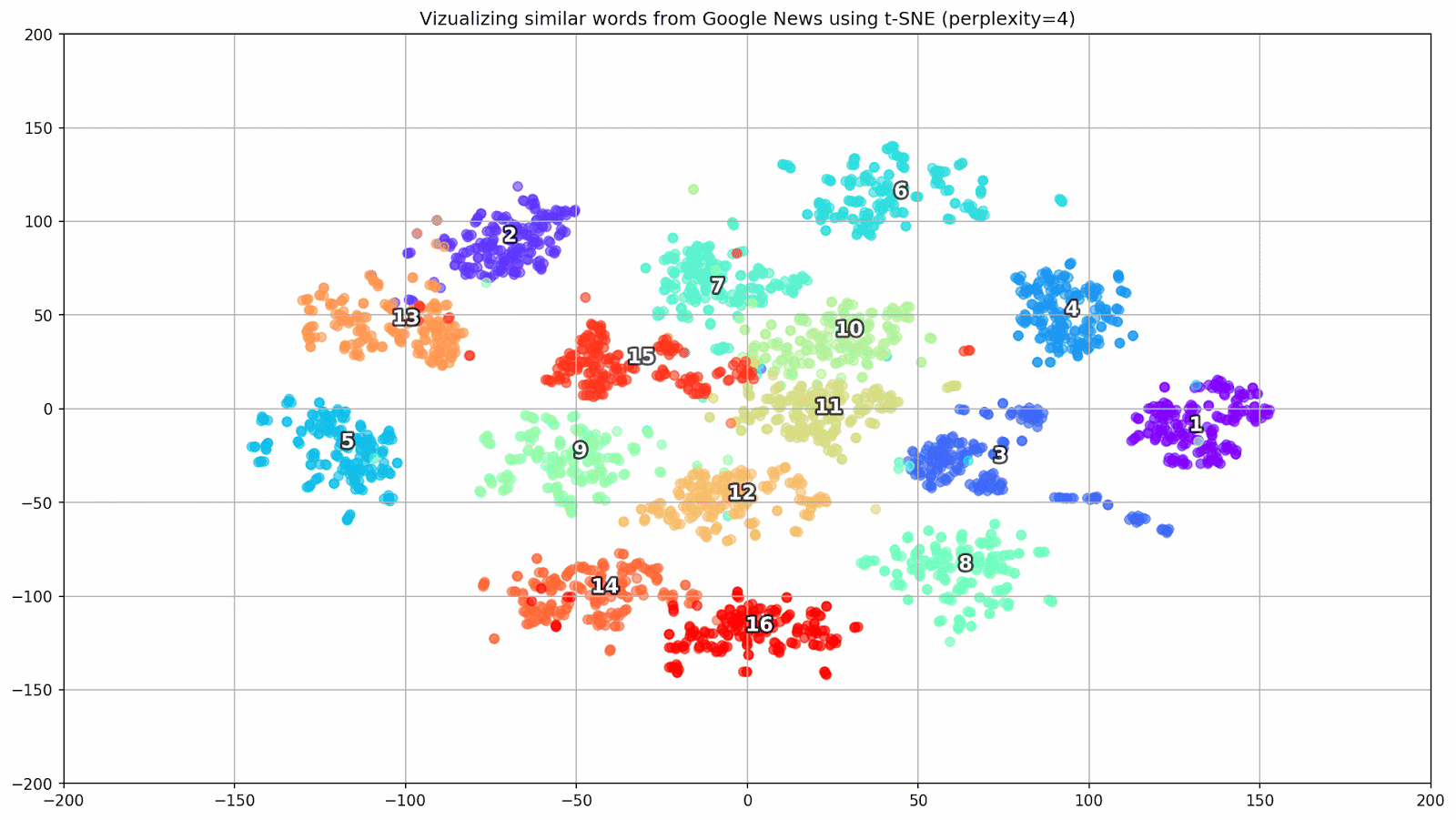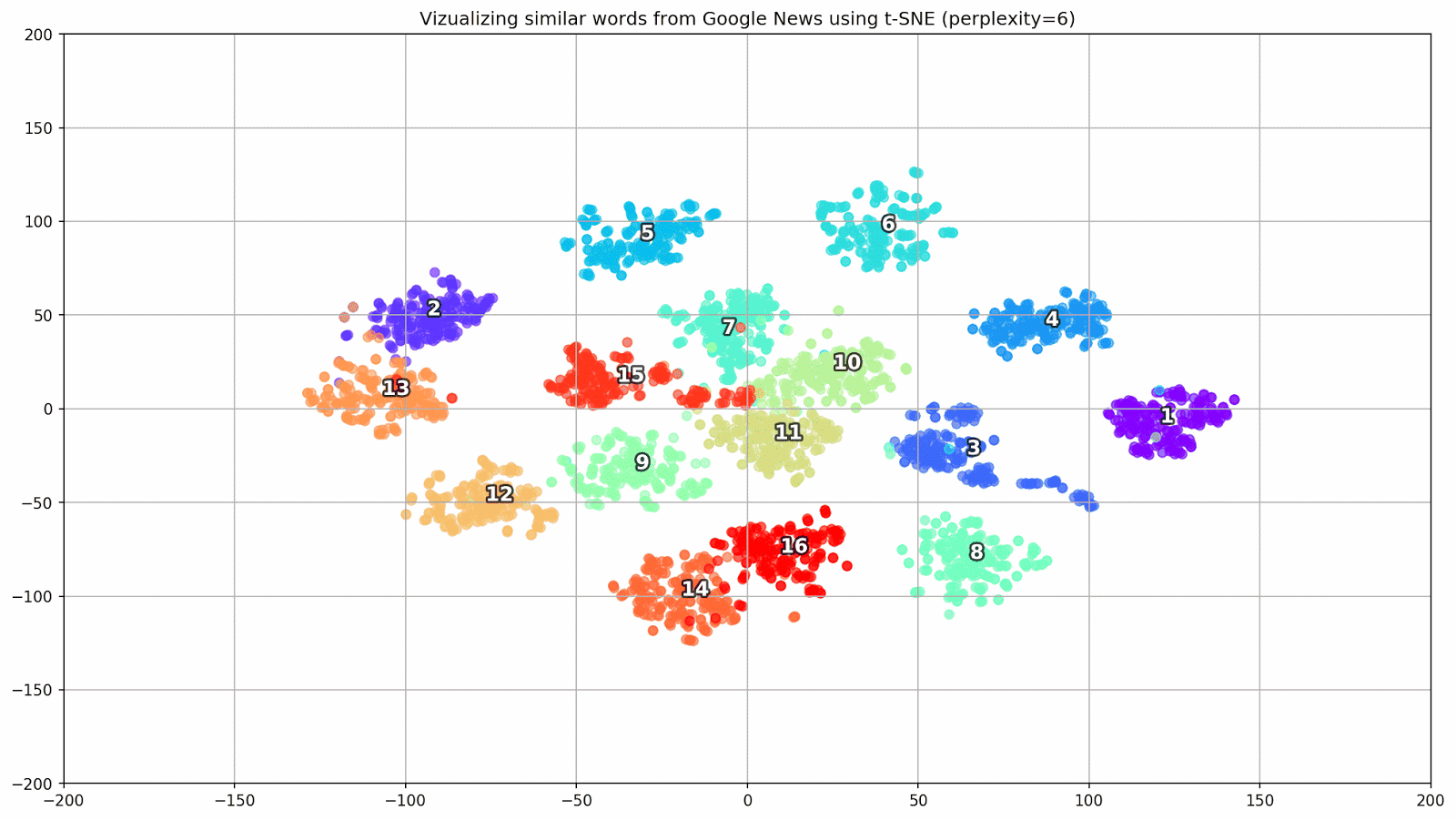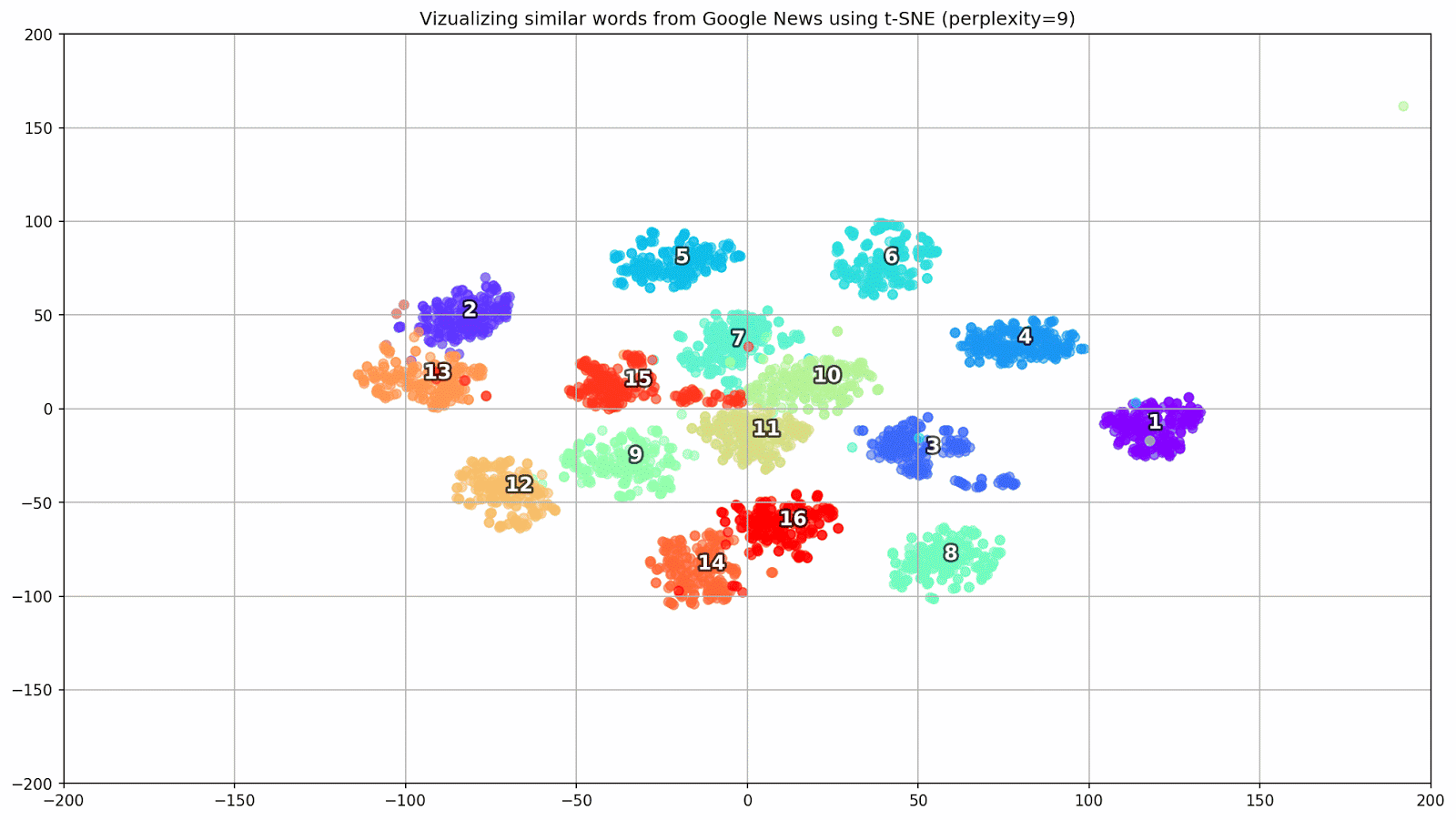 图 1.各种困惑值对词簇形状的影响。
图 1.各种困惑值对词簇形状的影响。接下来,我们继续进行本文的引人入胜的部分,即t-SNE的配置。 在本节中,我们应注意以下超参数。
- 组件的数量 ,即输出空间的尺寸。
- 在t-SNE的背景下, 困惑度值可以看作是邻居有效数量的平滑度量。 它与许多其他流形学习者中使用的最近邻居的数量有关(请参见上图)。 根据[1],建议在5到50之间选择一个值。
- 嵌入的初始初始化类型 。
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
应该提到的是,t-SNE具有非凸目标函数,使用带有随机起始的梯度下降优化可以将其最小化,因此不同的运行会产生略有不同的结果。
在下面,您可以找到使用Matplotlib创建2D散点图的脚本,Matplotlib是Python中用于数据可视化的最受欢迎的库之一。
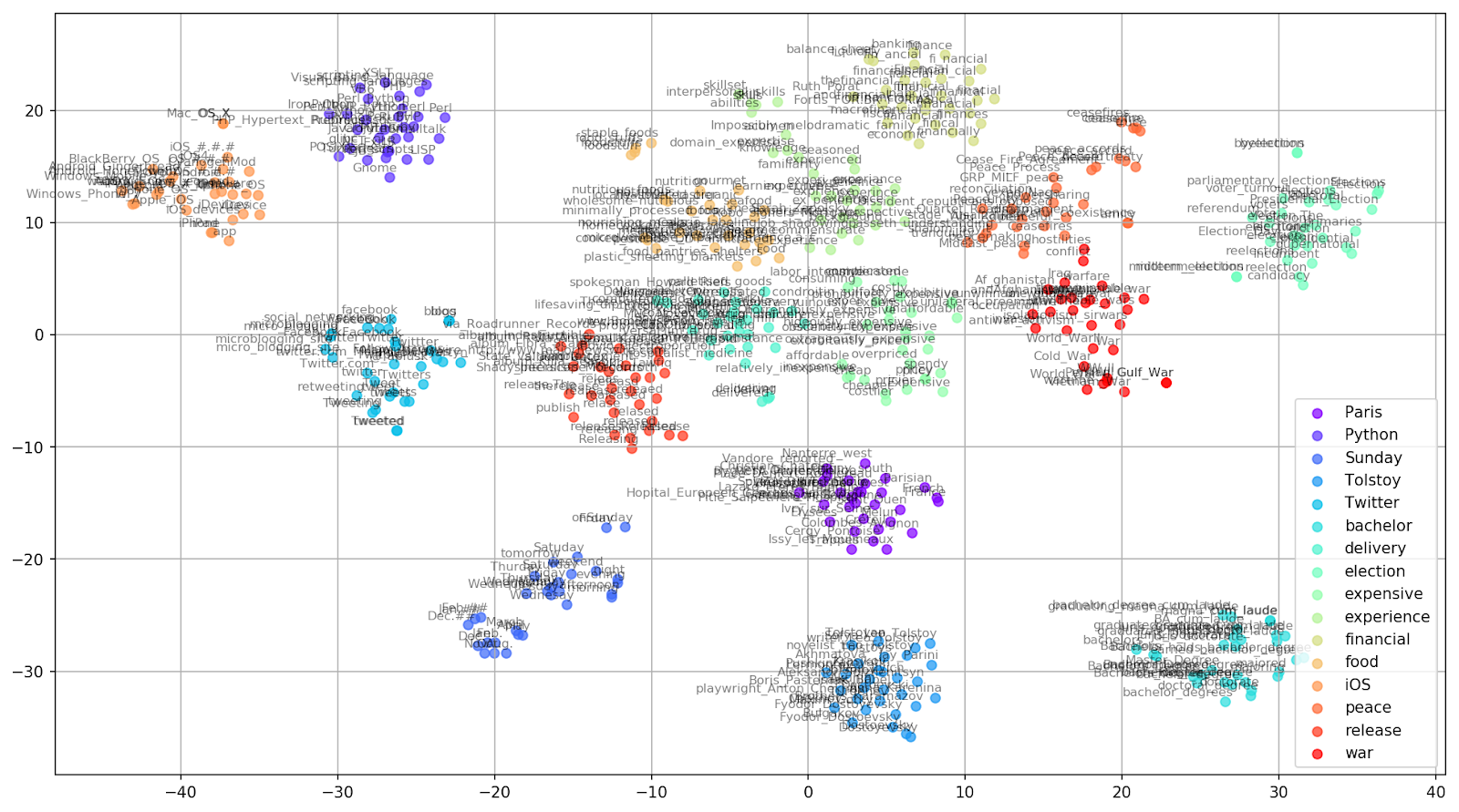 图 2.来自Google新闻的相似词簇(复杂度= 15)。
图 2.来自Google新闻的相似词簇(复杂度= 15)。 from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
在某些情况下,一次绘制所有单词向量以查看整个图片可能很有用。 现在让我们分析安娜·卡列尼娜(Anna Karenina),这是一部关于激情,阴谋,悲剧和救赎的史诗小说。
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
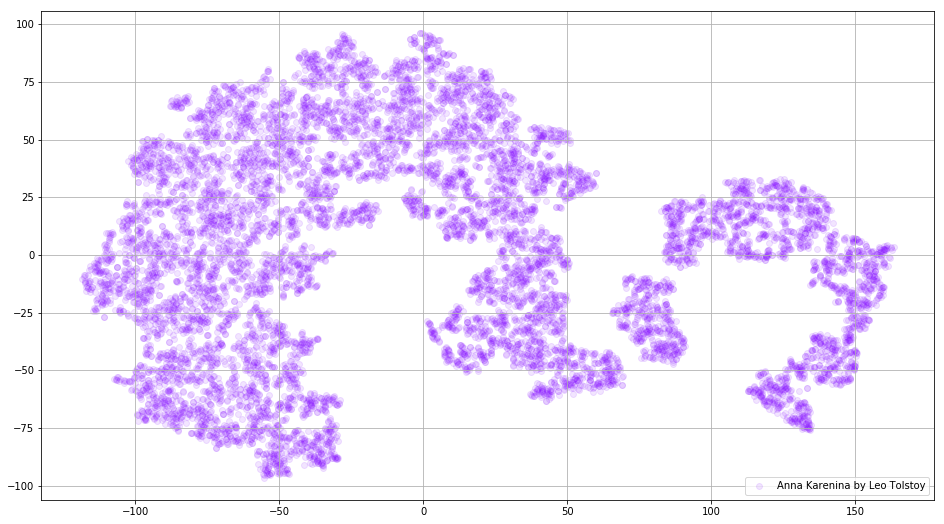
 图 3.在Anna Karenina上训练的Word2Vec模型的可视化。
图 3.在Anna Karenina上训练的Word2Vec模型的可视化。如果我们在3D空间中映射初始嵌入,则整个图片甚至可以提供更多信息。 在这个时候,让我们看一下《战争与和平》,这是世界文学的重要小说之一,也是托尔斯泰最伟大的文学成就之一。
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
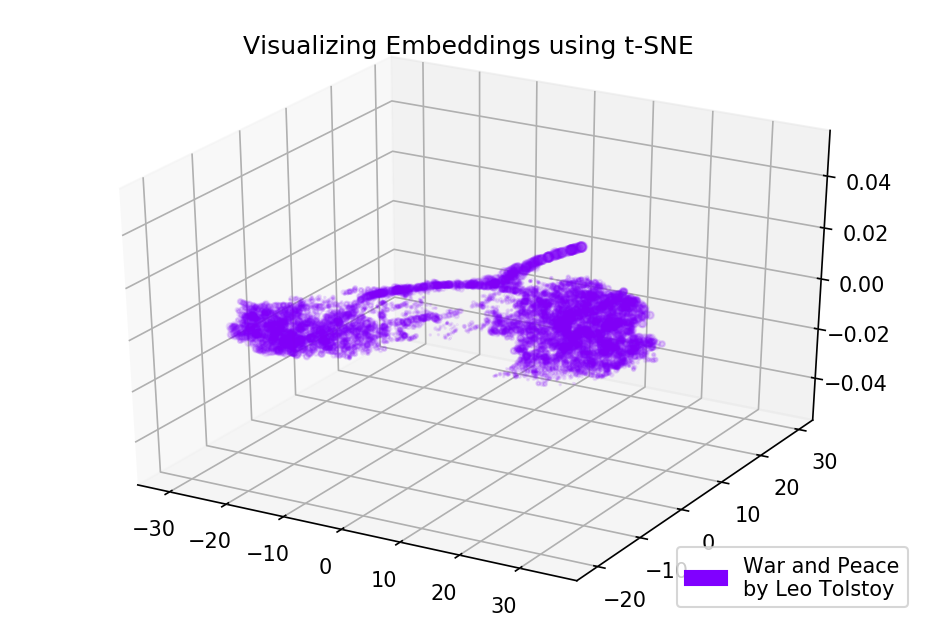 图 4.接受过战争与和平训练的Word2Vec模型的可视化。
图 4.接受过战争与和平训练的Word2Vec模型的可视化。结果
这就是Word2Vec和t-SNE前瞻性文本的样子。 我们为Google新闻中的类似词语绘制了一个内容丰富的图表,并为托尔斯泰的小说绘制了两个图表。 另外,还有一件事,GIF! GIF非常棒,但是绘制GIF与绘制常规图形几乎相同。 因此,我决定在文章中不提及它们,但是您可以在源代码中找到用于生成动画的代码。
源代码可从
Github获得 。
该文章最初发表于《
迈向数据科学》 。
参考文献
- L. Maate和G. Hinton,“使用t-SNE可视化数据”,《机器学习研究杂志》,第1卷。 9页。 2579-2605,2008年。
- T. Mikolov,I。Sutskever,K。Chen,G。Corrado和J. Dean,“单词和短语的分布式表示形式及其组成”,《神经信息处理系统进展》,第11页。 3111-3119,2013年。
- R. Rehurek和P. Sojka,“大型语料库主题建模的软件框架”,LREC 2010 NLP框架新挑战研讨会的论文集,2010年。