C / C ++中实现的多线程缓存的对比测试,以及如何安排O(n)缓存** RU系列的LRU / MRU缓存的描述
几十年来,已经开发了许多缓存算法: LRU,MRU,ARC等。 但是,当需要多线程工作的缓存时,有关此主题的google提供了一个半选项,有关StackOverflow的问题通常仍未得到解答。 我从Facebook找到了一个解决方案,该解决方案依赖于Intel TBB存储库中的线程安全容器。 后者还有一个多线程LRU缓存仍处于beta测试中,因此,要使用它,必须在项目中明确指定:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true
否则,由于在Intel TBB代码中进行了检查,因此编译器将显示错误:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif
我想以某种方式比较缓存的性能-选择哪个? 还是自己写? 早些时候,当我比较单线程缓存( link )时,我收到了使用其他键尝试其他条件的提议,并意识到需要更方便的可扩展测试平台。 为了使向测试中添加竞争算法更加方便,我决定将它们包装在标准接口中:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; };
类似地,这些接口也被包装:使用操作系统,获取设置,测试用例等。 源代码在存储库中进行布局 。 展位上有两个测试用例:从随机生成的数字中插入/搜索最多1,000,000个带键的元素,并从字符串中最多搜索100,000个元素(取自Wiki.train.tokens行的10Mb)。 为了评估执行时间,首先将每个测试高速缓存加热到目标体积,而不进行时间测量,然后信号量从链中卸载流以添加和搜索数据。 线程数和测试用例设置在asset / settings.json中设置 。 WiKi存储库中介绍了逐步编译说明和JSON设置的说明。 从释放信号量到最后一个线程停止为止的时间进行跟踪。 这是发生了什么:
测试用例1-随机数数组形式的键uint64_t keyArray [3]:
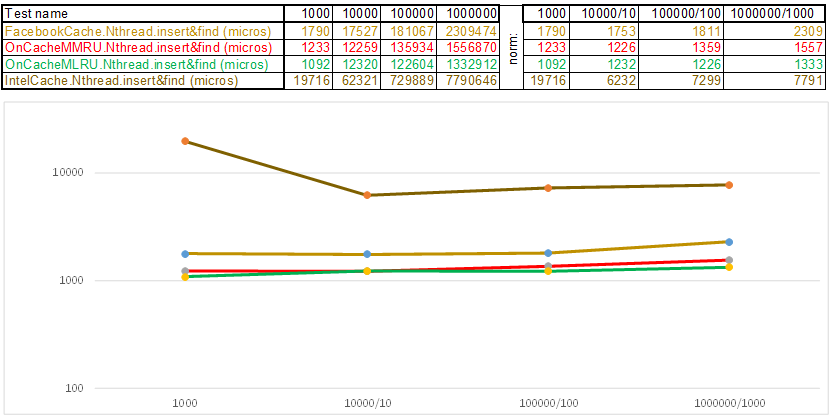
测试用例2-键为字符串:
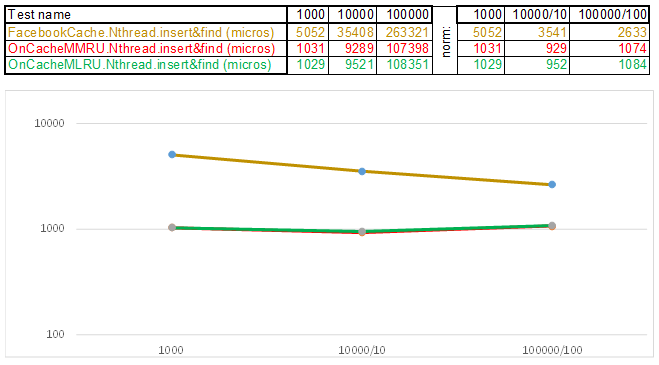
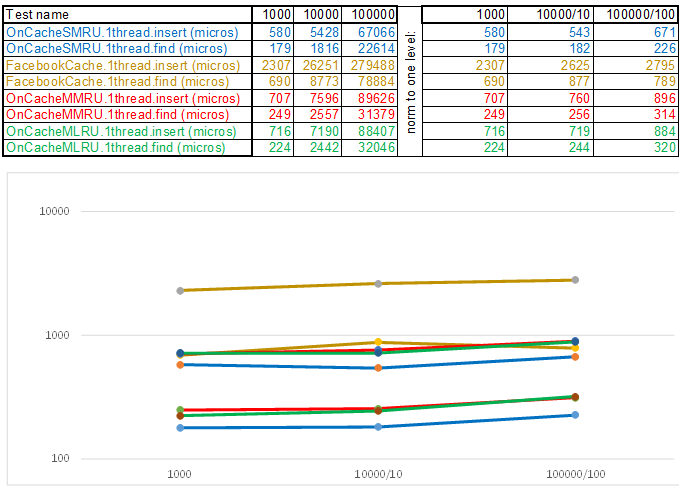
请注意,在测试用例的每个步骤中插入/搜索的数据量增加了10倍。 然后,处理下一个卷所花费的时间,我分别除以10、100、1000 ...如果算法在时间复杂度上表现得像O(n),那么时间线将保持与X轴大致平行。使用字符串键时,在O(n)Cache ** RU系列算法中比Facebook缓存具有3-5倍的优越性:
- 哈希函数无需读取字符串的每个字母,只需将指向字符串数据的指针强制转换为uint64_t keyArray [3]并计算整数之和。 也就是说,它的工作方式类似于“猜旋律”程序-我猜旋律有3个音符... 3 * 8 = 24个字母(如果是拉丁文),这已经使您可以很好地将行分散在哈希篮子中。 是的,可以在一个散列篮中收集很多行,并且此处算法开始加速:
- 每个购物篮中的“跳过列表”使您可以快速先跳转到不同的哈希值(购物篮ID =篮子的hash%数量,因此不同的哈希值可以出现在一个购物篮中),然后沿着顶点在同一哈希值中:
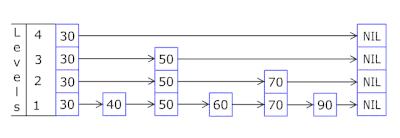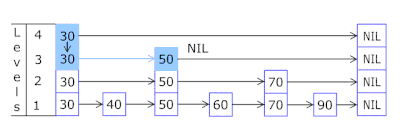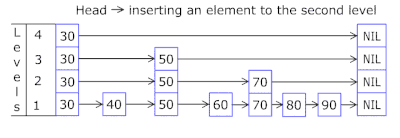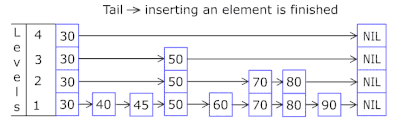
- 存储密钥和数据的节点取自先前分配的节点阵列,节点数与缓存容量一致。 原子标识符指示下一个要处理的节点-如果到达节点池的末尾,则它以0 =开头,因此分配器绕了一圈,覆盖了旧节点( OnCacheMLRU中的LRU缓存 )。
对于有必要将搜索查询中最流行的元素存储在缓存中的情况,将创建第二个OnCacheMMRU类 ,算法如下:除了缓存容量,该类的构造函数还传递第二个参数uint32_t uselessness,流行度限制是希望循环池中当前节点的搜索请求数量较少如果边界是无用的,则将该节点重新用于下一个插入操作(它将被逐出)。 如果该节点上的流行度很高(使用的{0}为std ::原子<uint32_t>),则在从循环池中请求分配器时,该节点将能够生存,但是流行度计数器将重置为0。因此,分配器传递的又一个循环并在节点池中重新获得人气,从而继续存在。 也就是说,它是MRU算法(最流行的算法永远挂在缓存中)和MQ(跟踪生命周期的算法)的混合体。 高速缓存不断更新,同时运行非常迅速-可以放置1个服务器来代替10个服务器。
总的来说,缓存算法在以下方面花费时间:
- 维护缓存基础结构(容器,分配器,跟踪元素的生存期和流行度)
- 添加/搜索数据时的哈希计算和键比较操作
- 搜索算法:红黑树,哈希表,跳过列表,...
考虑到最简单的算法在时间上是复杂的,而且通常是最有效的,因为任何逻辑都要占用CPU周期,因此有必要减少每一项的操作时间。 也就是说,无论您写什么,与简单的枚举方法相比,这些操作都应及时收回:当调用下一个函数时,枚举将必须经过另外一百或两个节点。 因此,多线程缓存将始终发挥单线程的作用,因为通过std :: shared_mutex保护篮子和通过std :: atomic_flag in_use保护节点不是免费的。 因此,对于在服务器上发布,我在Epoll主服务器线程中使用OnCacheSMRU单线程缓存(在并行工作流程中仅进行与DBMS,磁盘,加密有关的长时间操作)。 为了进行比较评估,使用了测试案例的单线程版本:
测试用例1-随机数数组形式的键uint64_t keyArray [3]:

测试用例2-键为字符串:
总之,我想告诉您可以从测试平台的源中提取出哪些有趣的东西:
- JSON解析库由一个specjson.h文件组成,对于那些不想将别人的代码的几兆字节拖到他们的项目中以便解析设置文件或传入的已知格式的JSON的人来说,这是一个小型的快速算法。
- 一种以形式(类LinuxSystem:public ISystem {...})而不是传统形式(#ifdef _WIN32)形式注入特定于平台的操作的方法。 将信号量包装起来,使用动态连接的库,服务等更为方便-在类中,只有特定操作系统的代码和标头。 如果需要另一个操作系统,则可以注入另一个实现(WindowsSystem类:public ISystem {...})。
- 展台将移至CMake-在Qt Creator或Microsoft Visual Studio 2017中打开CMakeLists.txt项目很方便。通过CmakeLists.txt处理该项目可让您自动化一些准备工作-例如,将测试用例文件和配置文件复制到安装目录:
- 对于那些掌握C ++ 17新功能的人来说,这是一个使用std :: shared_mutex,std :: allocator <std :: shared_mutex>,模板中的静态thread_local(有细微差别-分配到哪里?),在Windows 2000中启动大量测试的示例。测量执行时间的方式不同的线程:
- 有关如何编译,配置和运行此测试平台-WiKi的分步说明。
如果您还没有关于便捷操作系统的逐步说明,请为实现ISystem和逐步编译说明(适用于WiKi)对信息库做出的贡献表示感谢。或者只是写信给我-我将尝试寻找时间来筹集虚拟机并描述组装步骤。