哈Ha! 我向您介绍该帖子,该帖子是对
RailsConf 2018上
Stella Cotton的性能的文字改编,以及
Stella Cotton的文章
“使用Rails和Kafka构建面向服务的体系结构”的译文。
最近,从单片架构到微服务的过渡是显而易见的。 在本指南中,我们将学习Kafka的基础知识,以及事件驱动的方法如何改善Rails应用程序。 我们还将讨论通过面向事件的方法工作的服务的监视和可伸缩性问题。
什么是卡夫卡?
我确定您想获得有关您的用户如何进入平台或他们访问的页面,他们单击的按钮等信息。 真正流行的应用程序可以生成数十亿个事件,并将大量数据发送到分析服务,这对于您的应用程序可能是一个严峻的挑战。
通常,Web应用程序的组成部分需要所谓的
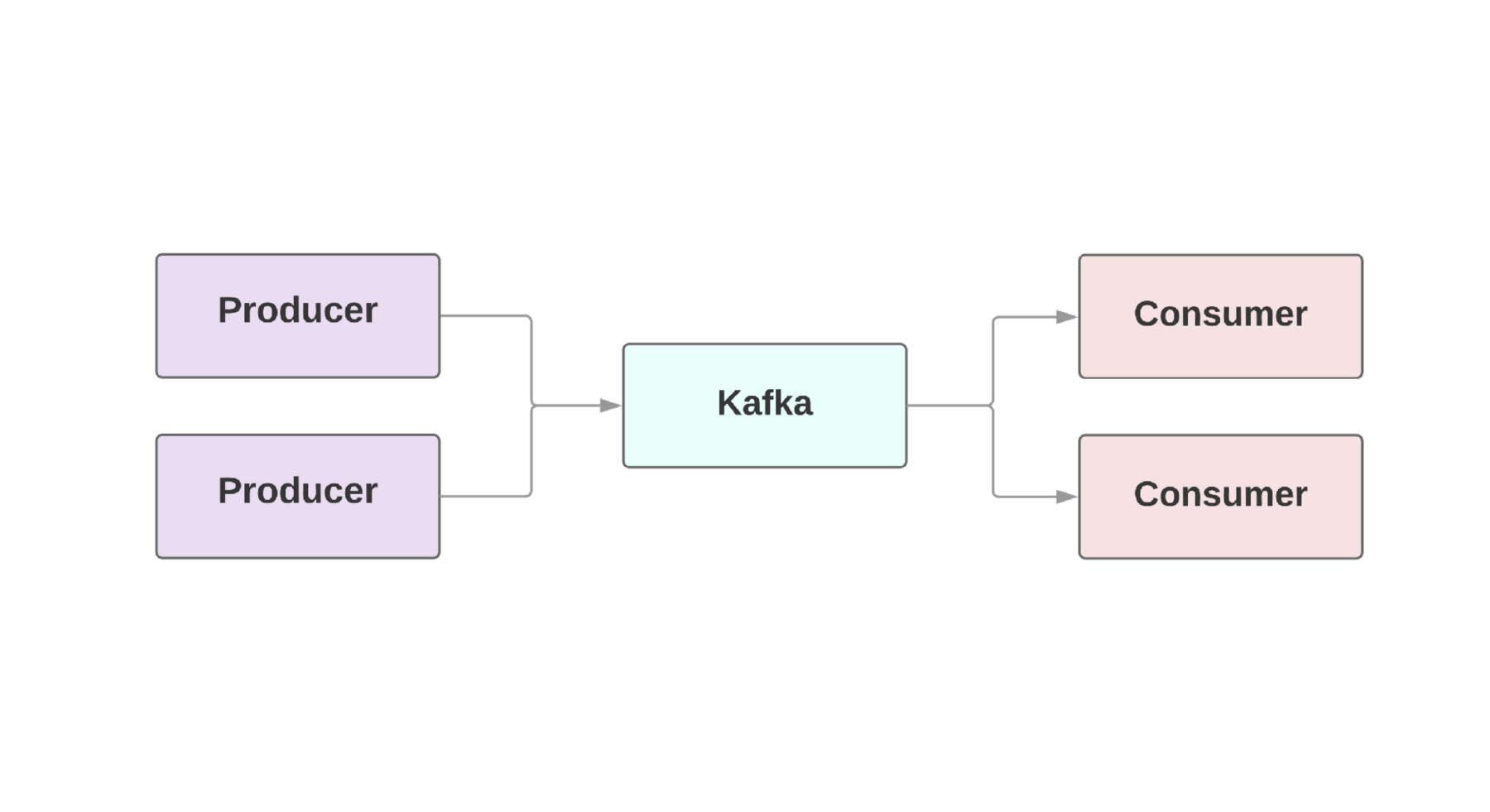
实时数据流 。 Kafka在
生产者 ,产生事件的
生产者和
消费者 ,接收这些事件的
消费者之间提供了容错连接。 在一个应用程序中甚至可能有多个生产者和消费者。 在Kafka中,每个事件都存在给定的时间,因此几个消费者可以一次又一次地读取同一事件。 Kafka集群包括几个代理,它们是Kafka实例。
Kafka的关键功能是事件处理的高速化。 传统的排队系统(例如AMQP)具有监视每个使用者的已处理事件的基础结构。 当用户数量增长到一个不错的水平时,该系统几乎无法开始应对负载,因为它必须监视越来越多的情况。 同样,使用者和事件处理之间的一致性也存在很大的问题。 例如,是否值得在系统处理完消息后立即将消息标记为已发送? 如果消费者跌倒了另一端却没有收到消息?
Kafka还具有故障安全架构。 该系统在一个或多个服务器上作为群集运行,可以通过添加新计算机来水平扩展。 将所有数据写入磁盘,然后复制到几个代理。 为了了解可扩展性的可能性,值得一看的公司包括Netflix,LinkedIn和Microsoft。 他们所有人每天都通过其Kafka集群发送数万亿条消息!
在Rails中设置Kafka
Heroku提供了可用于任何环境的
Kafka集群插件 。 对于红宝石应用,我们建议使用
ruby-kafka gem 。 最小实现看起来像这样:
配置完配置后,您可以使用gem来发送消息。 由于事件的异步发送,我们可以从任何地方发送消息:
class OrdersController < ApplicationController def create @comment = Order.create!(params) $kafka_producer.produce(order.to_json, topic: "user_event", partition_key: user.id) end end
我们将在下面讨论序列化格式,但是现在我们将使用良好的旧JSON。
topic参数指的是Kafka将此事件写入的日志。 主题分布在不同的部分,可让您将特定主题的数据拆分为不同的代理,以提高可伸缩性和可靠性。 每个主题都有两个或多个部分是一个好主意,因为如果其中一个部分落空,无论如何都会记录和处理您的事件。 Kafka确保在该部分(而不是整个主题)中按队列顺序发送事件。 如果事件的顺序很重要,则发送partition_key可以确保将特定类型的所有事件存储在同一分区上。
卡夫卡为您服务
使Kafka成为有用工具的某些功能还使其成为服务之间的故障转移RPC。 看一看电子商务应用程序的示例:
def create_order create_order_record charge_credit_card
用户下订单时,将
create_order函数。 这将在系统中创建一个订单,从卡中扣除钱,然后发送一封带有确认的电子邮件。 如您所见,最后两个步骤是在单独的服务中执行的。
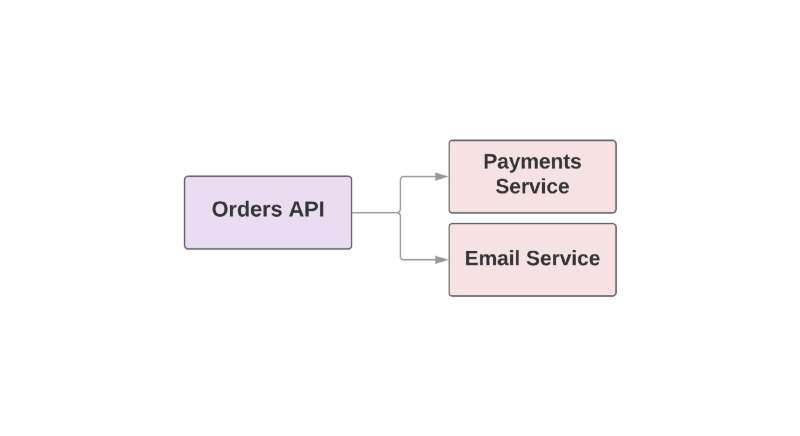
这种方法的问题之一是层次结构中的高级服务负责监视下游服务的可用性。 如果发送信件的服务真是糟糕的一天,那么更高级别的服务需要知道这一点。 而且,如果发送服务不可用,则需要重复执行某些操作。 在这种情况下,卡夫卡如何提供帮助?
例如:
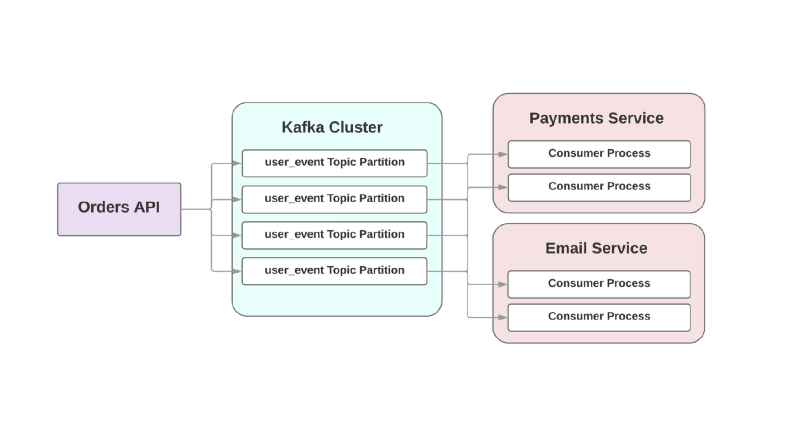
在这种事件驱动的方法中,高级服务可以在Kafka中记录已创建订单的事件。 由于采用了
至少一次的方法,该事件将至少在Kafka中记录一次,并可供下游消费者阅读。 如果发送信件的服务不起作用,则事件将在磁盘上等待,直到使用者抬起并读取它。
面向RPC的体系结构的另一个问题是快速增长的系统:添加新的下游服务需要在上游进行更改。 例如,您想在创建订单后再增加一个步骤。 在事件驱动的世界中,您将需要添加另一个使用者来处理新型事件。

将事件集成到面向服务的体系结构中
Martin Fowler的标题为“
事件驱动的含义是什么 ”的文章讨论了事件驱动的应用程序的困惑。 当开发人员讨论此类系统时,他们实际上是在谈论大量不同的应用程序。 为了大致了解此类系统的性质,Fowler定义了几种架构模式。
让我们看一下这些模式是什么。 如果您想了解更多信息,我建议您在GOTO Chicago 2017阅读他的
报告 。
活动通知
第一个Fowler模式称为
事件通知 。 在这种情况下,生产者服务以最少的信息通知事件的使用者:
{ "event": "order_created", "published_at": "2016-03-15T16:35:04Z" }
如果消费者需要有关事件的更多信息,他们会向生产者提出请求并获取更多数据。
事件进行状态转移
第二个模板称为
事件携带状态转移 。 在这种情况下,生产者提供有关事件的其他信息,而使用者可以存储此数据的副本而无需进行其他调用:
{ "event": "order_created", "order": { "order_id": 98765, "size": "medium", "color": "blue" }, "published_at": "2016-03-15T16:35:04Z" }
事件来源
Fowler将第三个模板称为“
事件源” ,它具有相当的结构性。 模板的发布不仅涉及服务之间的通信,还涉及事件表示的保留。 这样可以确保即使丢失数据库,也仍然可以通过简单地运行保存的事件流来恢复应用程序的状态。 换句话说,每个事件在特定时刻保存应用程序的特定状态。
这种方法的最大问题是应用程序代码总是在变化,并且生产者提供的数据格式或数量可能随之变化。 这使恢复应用程序状态成为问题。
命令查询职责隔离
最后一个模板是“
命令查询责任隔离 ”或CQRS。 想法是,应将应用于对象的操作(例如:创建,读取,更新)划分为不同的域。 这意味着一个服务应负责创建,另一服务应负责更新等。 在面向对象的系统中,所有内容通常都存储在一项服务中。
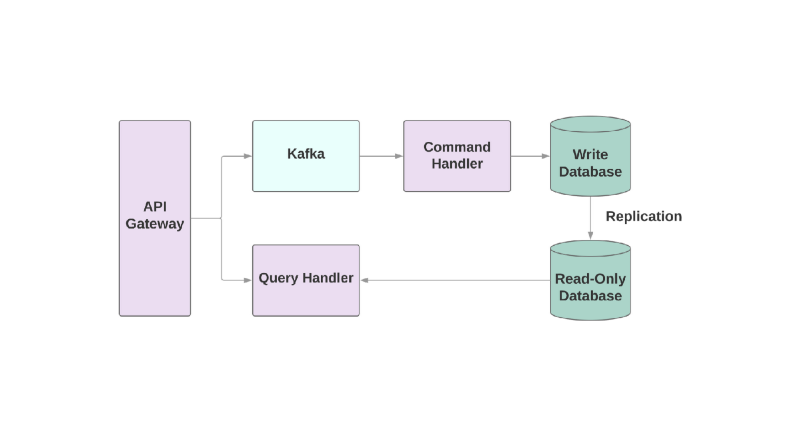
写入数据库的服务将读取事件流和处理命令。 但是,任何请求仅在只读数据库中发生。 将读写逻辑划分为两个不同的服务会增加复杂性,但可以让您分别优化这些系统的性能。
问题所在
让我们谈谈将Kafka集成到面向服务的应用程序中时可能遇到的一些问题。
第一个问题可能是消费缓慢。 在面向事件的系统中,当从上级服务接收事件时,您的服务应该能够立即处理事件。 否则,它们将简单地挂起,而不会出现有关问题或超时的任何警报。 可以定义超时的唯一地方是与Kafka代理的套接字连接。 如果服务不能足够迅速地处理事件,则连接可能会因超时而中断,但是恢复服务需要额外的时间,因为创建此类套接字非常昂贵。
如果使用者很慢,如何提高事件处理的速度? 在Kafka中,您可以增加组中使用者的数量,因此可以并行处理更多事件。 但是,一项服务至少需要2个消费者:万一其中一个掉落,可以重新分配损坏的部分。
具有度量和警报以监视事件处理的速度也非常重要。
ruby-kafka可以使用ActiveSupport警报,它还具有StatsD和Datadog模块,这些模块默认情况下处于启用状态。 此外,gem还提供了建议的监视指标
列表 。
使用Kafka构建系统的另一个重要方面是具有处理故障能力的消费者设计。 保证Kafka至少发送一次事件; 排除了根本不发送消息的情况。 但重要的是,消费者要做好应对重复发生的事件的准备。 一种方法是始终使用
UPSERT将新记录添加到数据库中。 如果记录已经存在且具有相同的属性,则该调用实际上将是无效的。 此外,您可以为每个事件添加唯一的标识符,而只是跳过先前已经处理过的事件。
资料格式
与Kafka一起使用时,惊喜之一可能是其对数据格式的简单态度。 您可以发送任何以字节为单位的数据,数据将被发送给使用者,而无需任何验证。 一方面,它提供了灵活性,并且使您不必关心数据格式。 另一方面,如果生产者决定更改正在发送的数据,则有可能最终导致某些消费者中断。
在构建面向事件的体系结构之前,请选择一种数据格式,并分析它在将来如何帮助注册和开发方案。
推荐使用的一种格式当然是JSON。 这种格式是人类可读的,并且受所有已知编程语言的支持。 但是有陷阱。 例如,JSON中最终数据的大小可能会变得惊人。 存储键值对所需的格式足够灵活,但是在每个事件中数据都是重复的。 更改模式也是一项艰巨的任务,因为如果需要重命名字段,则不存在将一个键覆盖在另一个键上的内置支持。
创建Kafka的团队建议
Avro作为序列化系统。 数据以二进制形式发送,这不是人类最容易理解的格式,但是在内部,对电路有更可靠的支持。 Avro中的最终实体包括架构和数据。 Avro还支持简单类型(例如数字)和复杂类型:日期,数组等。此外,它还允许您在方案内部包含文档,这使您可以了解系统中特定字段的用途,并包含许多其他用于处理方案的内置工具。
avro-builder是Salsify创建的一颗宝石,它提供了类似于红宝石的DSL来创建架构。 您可以在
本文中阅读有关Avro的更多信息。
附加信息
如果您对如何托管Kafka或如何在Heroku中使用Kafka感兴趣,可以参考一些报告。
Jeff Chao在DataEngConf SF '17上的“
超过50,000个分区:Heroku如何操作和推动Kafka的极限 ”
Pavel Pravosud在Dreamforce '16“
Dogfooding Kafka:我们如何构建Heroku的实时平台事件流 ”会议上
有一个不错的看法!