日志是系统的重要组成部分,可让您了解它是否按预期工作(或不工作)。 在微服务体系结构的条件下,处理日志成为特殊奥林匹克竞赛的一个独立学科。 您需要立即解决一堆问题:
- 如何从应用程序写入日志;
- 在哪里写日志;
- 如何传递日志进行存储和处理;
- 如何处理和存储日志。
如今非常流行的集装箱技术的使用,在解决方案选项领域的耙子上方增加了沙子。
关于尤里·布什梅列夫(Yuri Bushmelev)报告“原木收集和交付领域的地图耙”的解码
谁在乎,请在猫下。
我叫尤里·布什梅列夫(Yuri Bushmelev)。 我在Lazada工作。 今天,我将讨论我们如何处理日志,如何收集日志以及在其中写些什么。

我们是哪里人 我们是谁 Lazada是东南亚六个国家/地区的第一大网上商店。 所有这些国家/地区均由数据中心分发。 现在有四个数据中心,为什么这很重要? 因为某些决定是由于两个中心之间的联系非常薄弱。 我们有一个微服务架构。 我惊讶地发现我们已经拥有80种微服务。 当我从日志开始任务时,只有20个。此外,还有相当大的PHP遗留部分,您还必须忍受并忍受。 目前,所有这些对我们整个系统而言,每分钟产生的消息超过600万条。 此外,我将展示我们如何尝试使用它,以及为什么这样做。

我们需要以某种方式处理这600万条消息。 我们该怎么办? 您需要600万条消息:
- 从应用程序发送
- 接受交货
- 进行分析和存储。
- 分析
- 不知何故存储。

当出现三百万条消息时,我的表情大致相同。 因为我们以几分钱开始。 很明显,应用程序日志被写入那里。 例如,我无法连接到数据库,我能够连接到数据库,但无法读取内容。 但是除此之外,我们的每个微服务还编写了一个访问日志。 到达微服务的每个请求均落入日志。 我们为什么要这样做? 开发人员希望能够进行跟踪。 在每个访问日志中,都有一个traceid字段,沿着该字段,一个特殊的界面进一步展开整个链并精美地显示跟踪。 跟踪显示了请求如何进行,这有助于我们的开发人员快速处理所有未识别的垃圾。

如何生活? 现在,我将简要描述选项的领域-通常如何解决此问题。 如何解决日志的收集,传输和存储问题。

如何从应用程序编写? 显然,有不同的方法。 正如时尚同志告诉我们的,尤其是最好的做法。 正如祖父所说,有两种形式的老学校。 还有其他方法。

与收集日志大约相同的情况。 解决此特定部分的选项不多。 已经有更多,但不是很多。

但是随着交付和随后的分析,变化的数量开始爆炸式增长。 我现在不会描述每个选项。 我认为所有对该主题感兴趣的人都会听到主要选项。

我将展示我们是如何在Lazada进行的,以及实际上是如何开始的。

一年前,我来到了Lazada,他们把我送到了一个有关原木的项目中。 就是这样 来自应用程序的日志已写入stdout和stderr。 他们以时髦的方式做所有事情。 但是随后,开发人员将其从标准流程中剔除,然后基础架构专家将以某种方式对其进行分类。 在基础架构专家和开发人员之间,还发布了一些版本,其中说:“呃……好吧,我们只需要将它们包装在带外壳的文件中就可以了。” 由于所有这些内容都在容器中,因此他们将其包装在容器本身中,在其中下载目录并将其放在那里。 我认为这几乎对每个人都显而易见。

让我们再远一点。 我们如何交付这些日志。 有人选择了td-agent,它实际上是流利的,但不太流利。 我仍然不了解这两个项目的关系,但是它们似乎是同一回事。 而且,这种流利的语言(用Ruby编写)可以读取日志文件,并在JSON中定期解析它们。 然后他把他们送到卡夫卡。 在Kafka中,每个API都有4个单独的主题。 为什么是4? 因为有现场,所以有舞台,也因为有stdout和stderr。 开发人员诞生了它们,基础架构工程师必须在Kafka中创建它们。 此外,卡夫卡由另一个部门控制。 因此,有必要创建一个票证,以便它们为那里的每个api创建4个主题。 每个人都忘记了。 总的来说,那里有垃圾和烟雾。
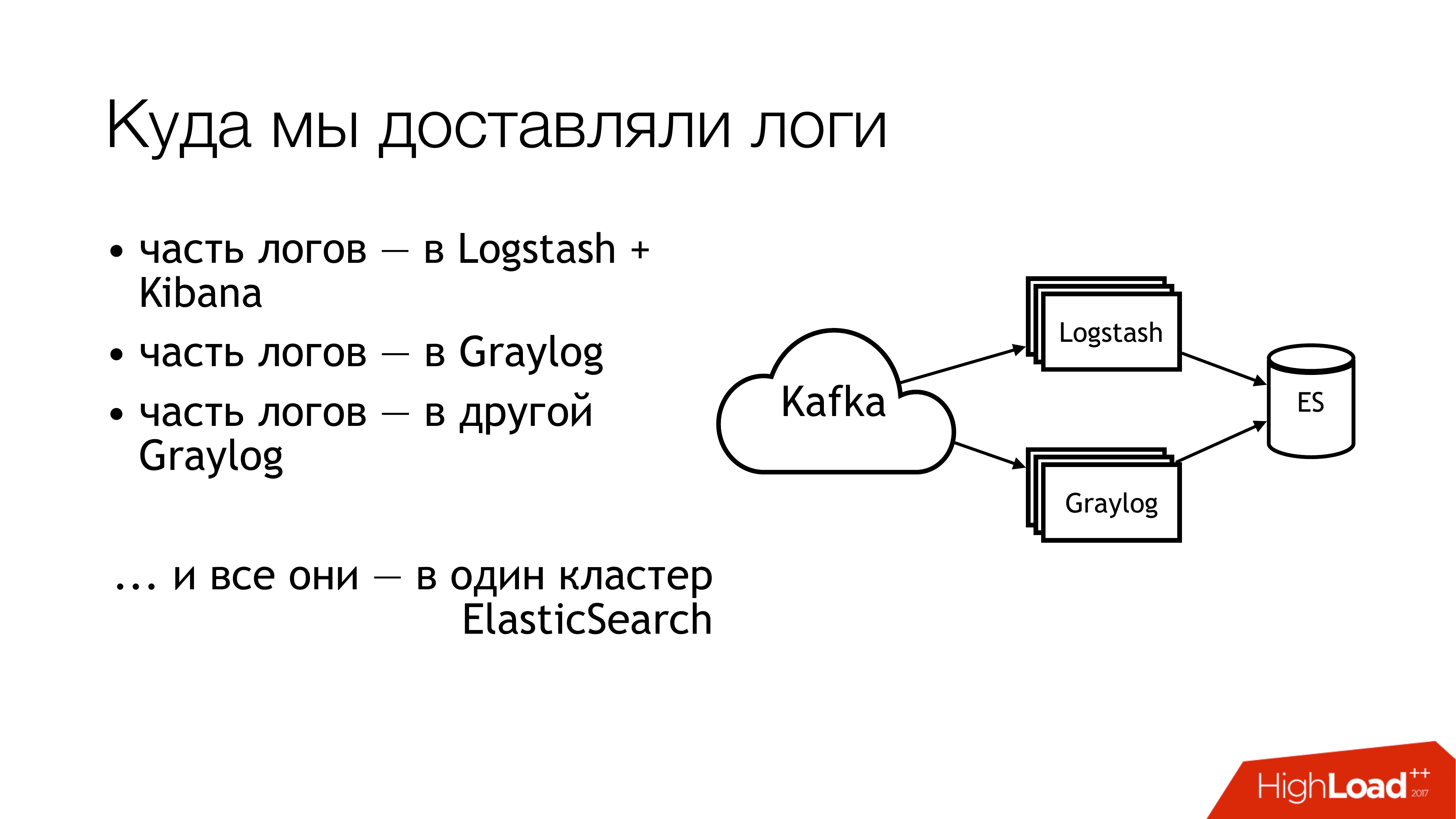
接下来我们要做什么? 我们将其发送给kafka。 距卡夫卡更远的地方,有一半的原木飞到了Logstash。 日志的另一半已共享。 部分飞入一个Graylog,另一部分飞入另一个Graylog。 结果,所有这些都飞入了一个Elasticsearch集群。 也就是说,整个混乱最终落在了那里。 您不必这样做!

如果您从上方遥望,这就是它的外观。 不要这样做! 在这里,数字立即指示问题区域。 实际上有更多这些,但是6个确实有很多问题,您需要使用它们来做点事情。 我现在将分别讨论它们。

这里(1,2,3)我们正在写文件,因此,这里一次有3个耙。
第一个(1)是我们需要将它们写在某个地方。 我并不总是希望让API能够直接写入文件。 希望将API隔离在容器中,甚至更好,使其为只读。 我是系统管理员,所以我对这些东西有一些替代的看法。
第二点(2,3)-我们有很多请求发送到API。 API将大量数据写入文件。 文件正在增长。 我们需要旋转它们。 因为否则无法获取任何光盘。 旋转它们很不好,因为它们通过外壳重定向到目录。 我们无法以任何方式移动它。 无法告知应用程序重新发现描述符。 因为开发人员会像傻瓜一样看着你:“描述符是什么? 我们通常写信给stdout。” 基础架构工程师在logrotate中进行了copytruncate,这只复制了文件并复制了原始文件。 因此,在这些复制过程之间,磁盘空间通常结束。
(4)我们使用了不同的格式,并且使用了不同的API。 它们略有不同,但是regexp的写法必须不同。 由于所有这些操作都是由Puppet控制的,因此他们的蟑螂种类繁多。 另外,td-agent大部分时间可能会吃掉内存,变得愚蠢,甚至会假装它可以工作,却什么也没做。 在外面,无法理解他什么也没做。 充其量,他会跌倒,然后有人会接他。 更确切地说,警报将到达,有人将用手过去。

(6)最浪费和浪费最大的是弹性搜索。 因为它是旧版本。 因为,那时我们没有专门的大师。 我们有异构的日志,其中的字段可以相交。 不同应用程序的不同日志可以用相同的字段名编写,但同时内部可能有不同的数据。 也就是说,在字段(例如,级别)中附带一个日志。 在级别字段中,String附带了另一个日志。 在没有静态映射的情况下,将获得如此美妙的效果。 如果在Elasticsearch中的索引旋转之后,第一个带有字符串的消息到达了,那么我们就正常了。 并且,如果它首先与Integer一起到达,那么所有随String到达的后续消息都将被简单丢弃。 因为字段类型不匹配。

我们开始问这些问题。 我们决定不认罪。

但是需要做些事情! 显而易见的是制定标准。 我们已经有了一些标准。 一些我们稍后得到。 幸运的是,当时已经批准了所有API的统一日志格式。 它直接写入服务交互的标准中。 因此,想要接收日志的人应该以这种格式写日志。 如果有人不以这种格式写日志,则我们不做任何保证。
此外,我想为记录,传递和收集日志的方法建立单一标准。 实际上,在哪里写它们以及如何交付它们。 理想的情况是项目使用相同的库。 这是Go的单独日志记录库,还有PHP的单独库。 我们拥有的每个人-每个人都应该使用它们。 目前,我要说的是我们将其提高了80%。 但是有些人继续吃仙人掌。
而且(在幻灯片上)几乎没有出现“用于日志传送的SLA”。 他还没有在那里,但我们正在努力。 因为当基础设施说如果您以某一种格式写入某某位置并且每秒不超过N条消息时,这非常方便,那么我们很可能会在某处传送某某信息。 这减轻了许多头痛。 如果有SLA,那就太好了!

我们是如何开始解决问题的? 主要的佣金是使用td-agent。 目前尚不清楚日志的去向。 他们交付了吗? 他们要去吗? 他们到底在哪里? 因此,第一项决定更换为td-agent。 我简要地介绍了替换它的选项。
流利的 首先,我在上一份工作中遇到了他,他也定期掉在那里。 其次,这是相同的,只是在配置文件中。
Filebeat。 对我们来说方便吗? 他在Go上的事实,我们在Go上有很多专业知识。 因此,如果那样的话,我们可以以某种方式自己添加它。 因此,我们没有接受它。 因此,即使没有诱惑也要开始为自己重写它。
对于sysadmin而言,显而易见的解决方案是所有此数量的syslog(syslog-ng / rsyslog / nxlog)。
或写一些我们自己的东西,但是我们删除了它,就像filebeat一样。 如果您写一些东西,最好写一些对业务有用的东西。 为了交付原木,最好准备一些东西。
因此,选择实际上归结为syslog-ng和rsyslog之间的选择。 他之所以倾向于rsyslog仅仅是因为我们在Puppet中已经有了rsyslog的类,而我发现它们之间没有任何明显的区别。 什么是系统日志,什么是系统日志。 是的,有人的文档质量较差,有人的文档质量较好。 他知道如何,而且他以另一种方式。

还有一点关于rsyslog的信息。 首先,它很酷,因为它具有很多模块。 它具有人类可读的RainerScript(现代配置语言)。 很棒的好处是我们可以使用它的常规方法来模拟td-agent的行为,而对于应用程序则没有任何变化。 也就是说,我们将td-agent更改为rsyslog,但并未涉及其他所有内容。 马上我们就可以开始工作了。 接下来,mmnormalize在rsyslog中是一件很棒的事情。 它允许您解析日志,但不能使用Grok和regexp。 她制作了一个抽象的语法树。 当编译器解析源代码时,它大致解析日志。 这样一来,您就可以非常快速地工作,几乎不占用CPU,并且总的来说,这是很酷的事情。 还有大量其他奖金。 我不会停下来。

Rsyslog仍然有很多缺陷。 它们与奖金大致相同。 主要问题-您需要能够烹饪它,并且需要选择版本。
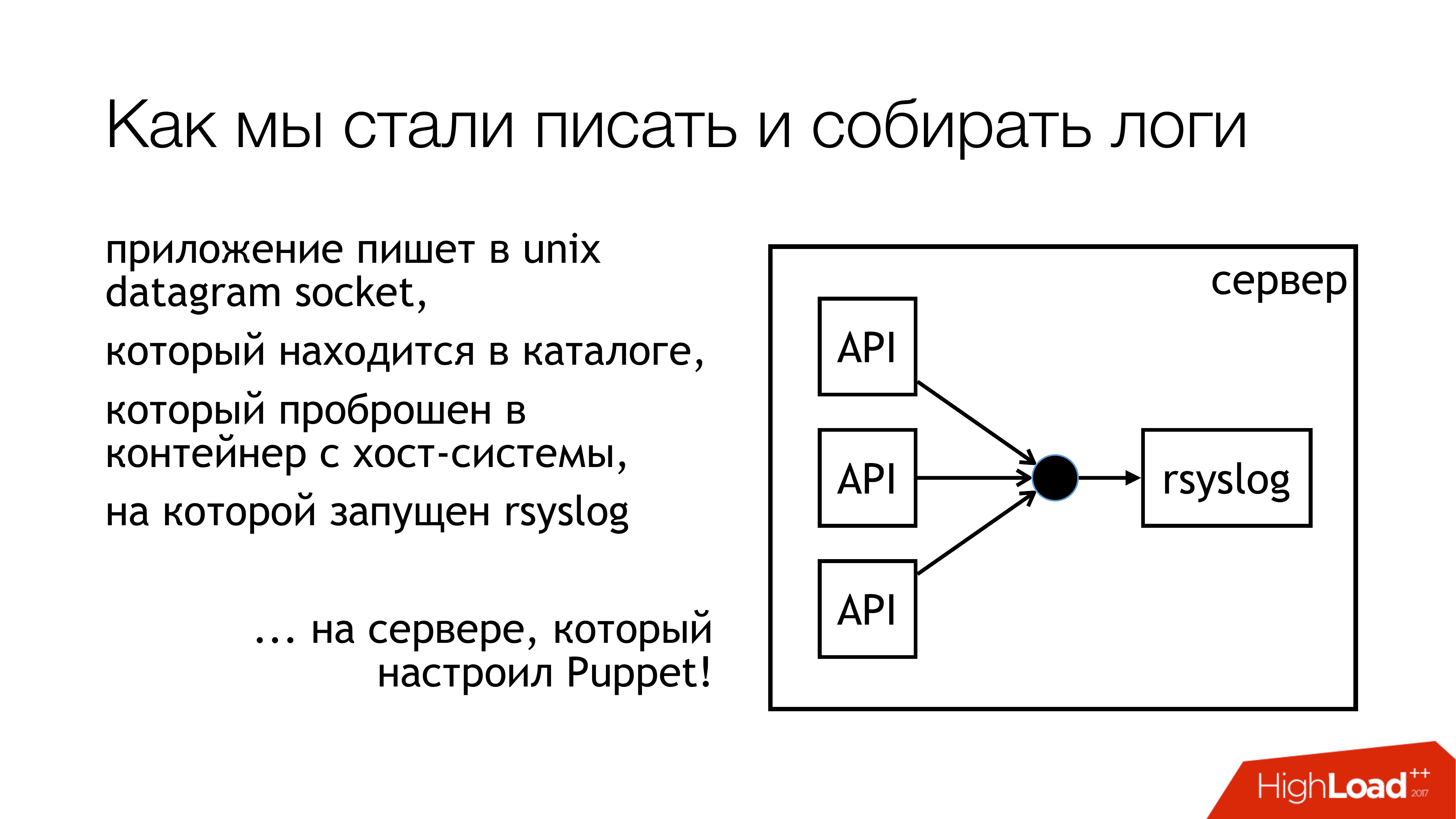
我们决定将日志写入unix套接字。 而且不在/ dev / log中,因为那里有系统日志中的粥,所以在此管道中记录了日志。 因此,让我们写一个自定义套接字。 我们将其附加到单独的规则集。 我们不会干涉。 一切将是透明和清晰的。 所以我们实际上做了。 具有这些套接字的目录是标准化的,并转发到所有容器。 容器可以看到他们需要的套接字,打开并编写它。
为什么没有文件? 因为每个人都读过一篇有关Badushechka的文章,他试图将文件转发给docker ,结果证明,在rsyslog重新启动后,文件描述符会更改,而docker会丢失此文件。 他继续打开其他东西,但是不写它们所在的套接字。 我们决定绕过此问题,同时绕过阻塞问题。

Rsyslog执行幻灯片上指示的操作,并将日志发送到中继或Kafka。 卡夫卡符合旧的方式。 中继-我尝试使用纯rsyslog传递日志。 如果没有Message Queue,则使用标准的rsyslog工具。 基本上,它可以工作。

但是在以后如何将它们塞入本部分(Logstash / Graylog / ES)中也存在细微差别。 此部分(rsyslog-rsyslog)在数据中心之间使用。 这是一个压缩的tcp链接,它可以节省带宽,并因此以某种方式增加了在通道已满的情况下我们将从另一数据中心接收某种日志的可能性。 因为,我们有印度尼西亚,那里的一切都不好。 这就是这个持续存在的问题所在。

我们考虑过如何实际监控,从应用程序记录的日志到达终端的概率是多少? 我们决定获取指标。 Rsyslog有自己的统计信息收集模块,该模块具有某种计数器。 例如,它可以显示队列的大小,或在此操作中传入了多少消息。 他们已经可以采取一些措施。 另外,它具有可以配置的自定义计数器,并且它将向您显示一些API编写的消息数。 接下来,我用Python编写了rsyslog_exporter,然后将其全部发送给Prometheus并进行了绘制。 Graylog指标确实很需要,但到目前为止,我们还没有时间配置它们。

有什么问题? 我们发现(突然!)我们的Live API每秒写入50k条消息,这引起了问题。 这只是一个实时API,没有暂存。 Graylog向我们显示每秒只有12,000条消息。 提出了一个合理的问题,但是剩菜剩饭在哪里? 从中我们得出结论,Graylog不能应付。 他们看了看,实际上,使用Elasticsearch的Graylog并没有掌握这一流。
此外,我们在此过程中还发现了其他发现。
写入套接字被阻止。 这是怎么发生的? 当我使用rsyslog进行交付时,有时数据中心之间的通道中断了。 交货在一个地方,交货在另一个地方。 所有这些都已经转移到具有写入rsyslog套接字的API的机器上。 有一个队列。 然后,写入unix套接字的队列已满,默认为128个数据包。 并且应用程序中的下一个write()被阻止。 当我们看一下我们在Go上的应用程序中使用的库时,它被写成在非阻塞模式下写入套接字。 我们确定没有任何障碍。 因为我们读了一篇有关Badushechka的文章 。 但是有片刻。 围绕此调用,仍然有一个无休止的循环,不断尝试将消息推入套接字。 我们没有注意到。 我不得不重写库。 从那时起,它发生了几次变化,但是现在我们摆脱了所有子系统中的锁。 因此,您可以停止rsyslog,并且不会有任何结果。
有必要监视队列的大小,这有助于避免踩踏此耙。 首先,我们可以监视何时开始丢失消息。 其次,我们可以监视原则上我们有交付问题。
另一个令人不快的时刻-在微服务架构中放大10倍-这非常容易。 我们没有很多传入请求,但是由于这些消息运行的图表和访问日志的原因,我们实际上使日志的负载增加了大约十倍。 不幸的是,我没有时间来计算确切的数字,但是微服务却是。 必须牢记这一点。 事实证明,当前日志收集子系统是Lazada中负载最大的子系统。

如何解决Elasticsearch问题? 如果您需要将日志快速收集到一个位置,以免在所有计算机上运行并且不将其收集到那里,请使用文件存储。 这样可以保证工作。 它由任何服务器制成。 您只需要将磁盘粘贴在那里并放入syslog。 之后,可以确保将所有日志放在一个位置。 此外,已经可以缓慢地调整elasticsearch,graylog等。 但是,您已经拥有了所有日志,此外,您可以将它们存储到足够的磁盘阵列。

在我撰写报告时,电路开始看起来像这样。 实际上,我们停止了对该文件的写入。 现在,很可能我们将关闭剩余的食物。 在运行该API的本地计算机上,我们将停止写入文件。 首先,有一个很好的文件存储。 其次,这些机器上的空间不断消耗runs尽,有必要对其进行持续监控。
Logstash和Graylog的这一部分确实飞涨。 因此,我们必须摆脱它。 您必须选择一件事。

我们决定扔掉Logstash和Kibana。 因为我们有一个安全部门。 有什么联系? 这种联系是,没有X-Pack和没有Shield的Kibana不允许区分对日志的访问权限。 因此,他们选择了Graylog。 他拥有一切。 我不喜欢他,但是行得通。 我们购买了新的铁,在其中放了新鲜的Graylog,然后将所有格式严格的原木移至单独的Graylog。 我们在组织上通过不同类型的相同字段解决了该问题。

新的Graylog中确切包含了什么。 我们只是在docker中记录了所有内容。 我们拿了一堆服务器,部署了三个Kafka实例,七个2.3版本的Graylog服务器(因为我想要Elasticsearch第5版)。 所有这些都来自硬盘的突袭。 我们看到索引速率高达每秒10万条消息。 我们看到了每周140 TB数据的数字。

再一次耙! 即将有两笔交易。 我们已经移动了600万条消息。 在我们这里,Graylog没有时间咀嚼。 我们不得不以某种方式再次生存。

我们这样生存了。 我们添加了更多服务器和SSD。 目前,我们以这种方式生活。 现在,我们已经在每秒咀嚼16万条消息。 我们还没有达到极限,所以我们还不能真正达到极限。

这些是我们对未来的计划。 实际上,最重要的可能就是高可用性。 我们还没有。 几辆车的配置相同,但到目前为止,所有事情都通过一辆车。 , failover .
Graylog.
rate limit , API, bandwidth .
, - SLA c , . , .
.

, , . -, . -, syslog — . -, rsyslog , . .
.
: - … (filebeat?)
: . . API , , . pipe. : « , , »? , , : « , ».
: HDFS?
: . , , , , long term solution.
: .
: . "" .
: rsyslog. TCP, UDP. UDP, ?
: . , , . , : « , - , - », «! , , , .» . , ? , ? best effort. , 100% . . .
: API - , , ? - .
: , . . , . , API . rsyslog . API , , timestamp . Graylog, timestamp. .
: Timestamp .
: Timestamp API. , , . NTP. API timestamp . rsyslog .
: . , . ? ?
: . - . , . . Log Relay. Rsyslog . . . . . . , (), Graylog. storage. , , . . .
: ?
: ( ) .
: , ?
: , . . , Go API, . , socket. . . socket. , . . , . prometheus, Grafana . . , .
: elasticsearch . ?
: .
: ?
: . .
: rsyslog - ?
: unix socket. 128 . . . , 128 . , , , , . , . .
c : JSON?
: JSON relay, . Graylog, JSON . , , rsyslog. issue, .
c : Kafka? RabbitMQ? Graylog ?
: Graylog . Graylog . . . , , . rsyslog elasticsearch Kibana. . , Graylog Kibana. Logstash . , rsyslog. elasticsearch. Graylog - . . .
Kafka. . , , . . , , . RabbitMQ… c RabbitMQ. RabbitMQ . , . , . . . Graylog AMQP 0.9, rsyslog AMQP 1.0. , , . . Kafka. . omkafka rsyslog, , , rsyslog. .
问题 :您是否因为使用过卡夫卡而使用它? 没有用于其他目的吗?
回答 :Kafka,Data S Dataience团队曾使用过。 这是一个完全独立的项目,不幸的是,我不能说什么。 我不知道 她由数据科学团队管理。 当日志开始时,他们决定使用它,以免放置自己的日志。 现在,我们更新了Graylog,并且失去了兼容性,因为存在旧版本的Kafka。 我们必须拥有自己的。 同时,我们摆脱了每个API的这四个主题。 我们为所有现场直播制作了一个广泛的话题,为所有演出制作了一个广泛的话题,只是在这里列出了所有内容。 Graylog将所有这些并行进行。
问题 :为什么这种带有插座的萨满教是必要的? 您是否尝试过将syslog日志驱动程序用于容器?
回答 :在我们问这个问题的那一刻,我们与码头工人有一个紧张的关系。 那是docker 1.0或0.9。 Docker本身很奇怪。 其次,如果您也将日志推入其中……我怀疑他是否通过docker守护程序将所有日志传递给了他自己。 如果我们有一个疯狂的API,则其余的API会因为无法发送stdout和stderr而陷入困境。 我不知道这将导致什么。 我对您不需要在此地方使用docker syslog驱动程序的程度感到怀疑。 我们的功能测试部门拥有自己的带有日志的Graylog集群。 他们使用docker日志驱动程序,那里的一切似乎都还不错。 但是他们立即将GELF写给Graylog。 在所有这些工作完成的那一刻,我们需要它才能正常工作。 也许稍后,当有人来说它已经正常工作一百年了,我们将尝试。
问题 :您在rsyslog上的数据中心之间进行交付。 为什么不去卡夫卡呢?
答 :实际上,我们两者都在做。 有两个原因。 如果通道完全死了,那么我们所有的日志,即使是压缩形式的日志,也不会通过它进行爬网。 卡夫卡让他们在这个过程中简单地迷路了。 通过这种方式,我们摆脱了粘贴这些日志的麻烦。 在这种情况下,我们直接使用Kafka。 如果我们有一个好的频道并希望释放它,那么我们将使用他们的rsyslog。 但是实际上,您可以对其进行配置,以使他本人可以丢弃未爬网的内容。 目前,我们只是在某个地方直接使用rsyslog传递,而在Kafka某个地方。