
开发人员为最奇怪的事情疯狂。 我们每个人都倾向于认为自己是超理性的人,但是在选择特定技术时,我们陷入了一种疯狂,从对HackerNews的评论跳到博客上的帖子,现在,好像被遗忘了,我们无助我们正朝着最明亮的光源航行,顺从地屈服,完全忘记了我们原本要寻找的东西。
这根本不是理性的人如何做出决定。 但是正是这样,开发人员才决定使用MapReduce。
正如乔·海勒斯坦(Joe Hellerstein) 在针对本科生的数据库讲座 (第54分钟)中指出的那样:
事实是,世界上大约有5家公司执行此类雄心勃勃的任务。 对于其他所有人……他们花费了难以置信的资源来确保系统的弹性,而这是他们真正不需要的。 人们在2000年代曾有一种“谷歌搜索”的方式:“我们将像Google一样做所有事情,因为我们还管理着世界上最大的数据处理服务……” [具有讽刺意味的是,他摇了摇头,等待听众的欢笑。

您的数据中心大楼有几层? Google决定至少在俄克拉荷马州梅斯县的这个特定数据中心保留四名。
是的,您的系统比您需要的更具弹性,但请考虑可能会花费多少。 重点不仅在于需要处理大量数据。 您可能正在交换一个相对较弱的东西(包括事务,索引和查询优化)的完整系统。 这是重要的一步。 有多少Hadoop用户自觉地这样做? 他们中有多少人做出了真正平衡的决定?
MapReduce / Hadoop是一个非常简单的示例。 即使是货运崇拜的追随者也已经意识到飞机无法解决所有问题。 但是,使用MapReduce可以使您得到重要的概括:如果使用为大型公司创建的技术,但同时又解决了小问题,则您可能会采取无意识的行动。 即便如此,您很有可能会受到一些神秘想法的指导,这些想法是模仿Google和Amazon之类的巨头,您将达到相同的高度。

是的,这篇文章是货运邪教的另一个反对者。 但是,等等,我为您提供了一个有用的清单,您可以使用它来做出更明智的决定。
酷框架:UNPHAT
下次当您用谷歌搜索一些新颖的技术来重新构造系统时,我敦促您停止使用UNPHAT框架:
- 在理解(理解)问题之前,甚至不要尝试思考可能的解决方案。 您的主要目标是根据问题而非解决方案来“解决”问题。
- 列出(eNumerate)几种可能的解决方案。 无需立即将手指指向您最喜欢的选项。
- 考虑一个单独的解决方案,然后阅读文档(纸张) (如果有)。
- 定义创建此解决方案的历史环境 。
- 与缺陷匹配优势 。 分析决策者为实现目标必须付出的代价。
- 想(想) ! 冷静而冷静地考虑此解决方案适合您的需求的程度。 您真正需要改变什么才能改变主意? 例如,应减少多少数据,以便您不希望使用Hadoop?
你不是亚马逊
使用UNPHAT很容易。 回想一下我最近与一家公司的对话,该公司仓促决定使用Cassandra进行密集的夜间读取数据下载过程。
由于我已经熟悉了Dynamo文档,并且知道Cassandra是派生系统,因此我了解到在这些数据库中,主要重点是记录能力 (Amazon从未要求将动作“添加到购物车”没有失败)。 我还感谢开发人员牺牲了数据完整性-实际上,牺牲了传统RDBMS固有的每个功能。 但是毕竟,与我交谈过的公司没有记录能力。 老实说,该项目意味着每天创造一个大记录。

亚马逊出售很多东西。 如果“添加到购物篮”功能突然停止工作,他们将损失很多钱。 您有相同顺序的问题吗?
该公司之所以选择使用Cassandra,是因为它花费了几分钟来完成所涉及的PostgreSQL查询,并且他们认为这些是其硬件方面的技术限制。 在澄清了两点之后,我们意识到该表由大约5000万行(每个80字节)组成。 如果您必须完全通过SSD读取数据,则大约需要5秒钟。 这很慢,但仍比当时的查询执行速度快两个数量级。
在这个阶段,我有很多问题(U =了解,理解问题!),我开始权衡大约5种可以解决原始问题的策略(N = eNumerate,列出一些可能的解决方案!),但是无论如何到目前为止,已经很清楚使用Cassandra基本上是错误的决定。 他们所需要的只是一点耐心,可能是数据库的新设计,还可能(尽管不太可能),选择了不同的技术……但绝对不是具有密集记录的键值数据存储亚马逊为他们的购物篮而创建的!
您不是领英
我很惊讶地发现一家学生创业公司决定在卡夫卡周围建立其架构。 太神奇了 据我所知,他们的业务每天仅执行几十个非常大的操作。 在最成功的日子里可能只有几百个。 有了这个带宽,主数据仓库可以是一本普通书中的手写条目。
为了进行比较,回想一下Kafka的创建是为了处理LinkedIn上的所有分析事件。 这只是海量数据。 即使在几年前, 每天也发生约1万亿个事件 ,峰值负载为每秒1000万条消息。 当然,我知道Kafka可以用于较低的负载,但是要少10个订单?

太阳是一个非常重的物体,它仅比地球重6个数量级。
也许开发人员甚至根据预期需求和对Kafka用途的充分理解做出了有意的决定。 但是我认为,(通常是有道理的)社区对Kafka的热情为他们提供了动力,并且几乎从不怀疑这是否真的是他们需要的工具。 试想一下... 10个订单!
我说了吗 你不是亚马逊
比Amazon的分布式数据仓库更受欢迎的是为他们提供可伸缩性的体系结构设计方法:一种面向服务的体系结构。 正如沃纳·沃格斯(Werner Vogels)在2006年接受吉姆·格雷(Jim Gray) 采访时指出的那样,亚马逊在2001年意识到他们很难扩展前端部分,而面向服务的体系结构可以帮助他们。 这个想法接连感染了一个开发人员,而仅由几个开发人员组成且几乎没有客户的初创公司并没有开始将其软件拆分为纳米服务。
到亚马逊决定改用SOA(面向服务的体系结构)时, 他们已有大约7800名员工,销售额超过30亿美元 。

旧金山音乐厅Bill Graham礼堂可容纳7,000人。 当他们转向SOA时,亚马逊大约有7,800名员工。
这并不意味着您应该推迟到SOA的过渡,直到您的公司达到7800名员工的水平为止……只需要自己动手思考即可 。 这真的是您任务的最佳解决方案吗? 摆在您面前的任务到底是什么,还有其他解决方案吗?
如果您告诉我,由50名开发人员组成的组织的工作只是在没有SOA的情况下兴起的,那么我想知道为什么这么多大公司仅使用单个但组织良好的应用程序就能出色地工作。
甚至谷歌也不是谷歌。
使用系统处理高负载数据流(Hadoop或Spark)的示例确实令人迷惑。 通常,传统的DBMS更适合负载,并且有时数据量如此之小,以至于可用内存就足够了。 您是否知道可以10,000美元在某处购买1TB RAM? 即使您有十亿用户,您仍将能够为每个用户提供1 KB的RAM。
也许这不足以满足您的负载,因为您需要读写磁盘。 但是,您真的需要几千个磁盘来读写吗? 您实际上有多少数据? 创建GFS和MapReduce的目的是解决整个Internet的计算问题,例如,重新计算整个Internet的搜索索引。
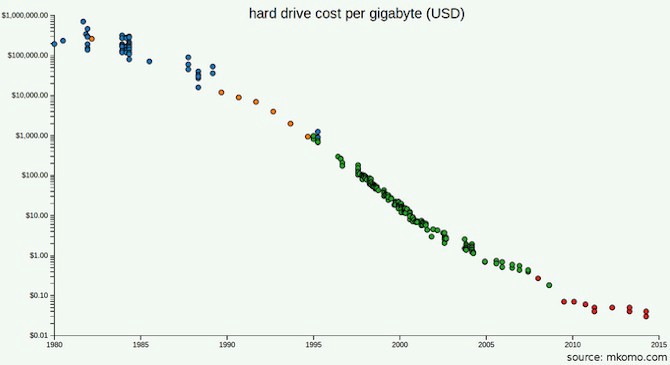
硬盘的价格现在比GFS文档发布时的2003年要低得多。
也许您阅读了GFS和MapReduce文档,并注意到Google的问题之一不是数据量,而是带宽(处理速度):它们使用分布式存储,因为从磁盘传输字节花费了太多时间。 但是,今年您将使用的设备的带宽将是多少? 假设您甚至不需要使用Google所需的设备,那么只购买更多现代驱动器会更好吗? 使用固态硬盘需要多少钱?
也许您想提前考虑可伸缩性。 您已经完成了所有必要的计算吗? 您会以比SSD价格下降更快的速度积累数据吗? 您的业务必须增长多少次才能使所有可用数据不再适合一台设备? 截至2016年,Stack Exchange每天处理2亿个查询,仅支持4台SQL服务器 :主要的一台用于Stack Overflow,另一台用于其他所有服务器,以及两份副本。
同样,您可以求助于UNPHAT并仍然决定使用Hadoop或Spark。 而且这个决定甚至可能是正确的。 最主要的是,您确实使用了正确的技术来解决您的问题 。 顺便说一下,这在Google众所周知:当他们确定MapReduce不适合索引时,他们就停止使用它。
首先要了解问题
我的信息可能不是什么新鲜事物,但是可能会以某种形式答复您,或者可能很容易让您记住UNPHAT并将其应用到生活中。 如果没有,您可以在Hammock Driven Development上观看Rich Hickey的演讲,或者在Paul 的书《如何解决》或Hamming的《科学与工程的艺术》中观看。 因为我们所有人都要求的主要是思考!
并真正了解您要解决的问题。 用保罗的励志话语:
“ 回答一个您不理解的问题是愚蠢的。 悲伤,就争取要达到的目标。“
俄语翻译
翻译: 亚历山大·特雷古波夫(Alexander Tregubov)
由 Alexey Ivanov(@ponchiknews) 编辑
社区: @ponchiknews
图: LucidChart内容团队