一个好的出租车预订服务应该是安全,可靠和快速的。 用户无需详细说明:对他而言,重要的是,他单击“订购”按钮并尽快收到一辆汽车,这会将他从A点运送到B点。如果附近没有汽车,服务应立即告知此情况,以便客户不要进化出错误的期望。 但是,如果“无车”标牌显示得过于频繁,那么一个人停止使用这项服务并去找竞争对手是合乎逻辑的。
在本文中,我想谈一谈如何借助机器学习解决在密度低的区域(换句话说,乍一看没有汽车)的地区寻找汽车的问题。 以及结果。
背景知识
要叫出租车,用户需要执行一些简单的步骤,服务的胆量会怎样?
关于
ETA ,我们已经编写
了价格计算和
最合适的驱动程序的
选择 。 这是关于寻找司机的故事。 创建订单后,搜索会进行两次:在图钉和订单上。 对订单的搜索分为两个阶段:候选人的招聘和排名。 首先,路线图上有免费的候选驾驶员。 然后应用奖金和过滤。 其余的候选人将排名,获胜者将收到订单要约。 如果他同意,则分配给订单并转到交货点。 如果他拒绝了,那么提议就进入下一个提议。 如果没有更多候选者,搜索将再次开始。 这持续不超过三分钟,之后订单被取消-耗尽。
引脚上的搜索与订单上的搜索相似,仅不创建订单,并且搜索本身仅执行一次。 而且,使用了候选数和搜索半径的简化设置。 需要这样的简化,因为引脚数比数量级多一个数量级,并且搜索是相当困难的操作。
我们故事的关键时刻:如果在对图钉的初步搜索中没有合适的候选人,那么我们不允许下订单。 至少它曾经是。
这是用户在应用程序中看到的内容:
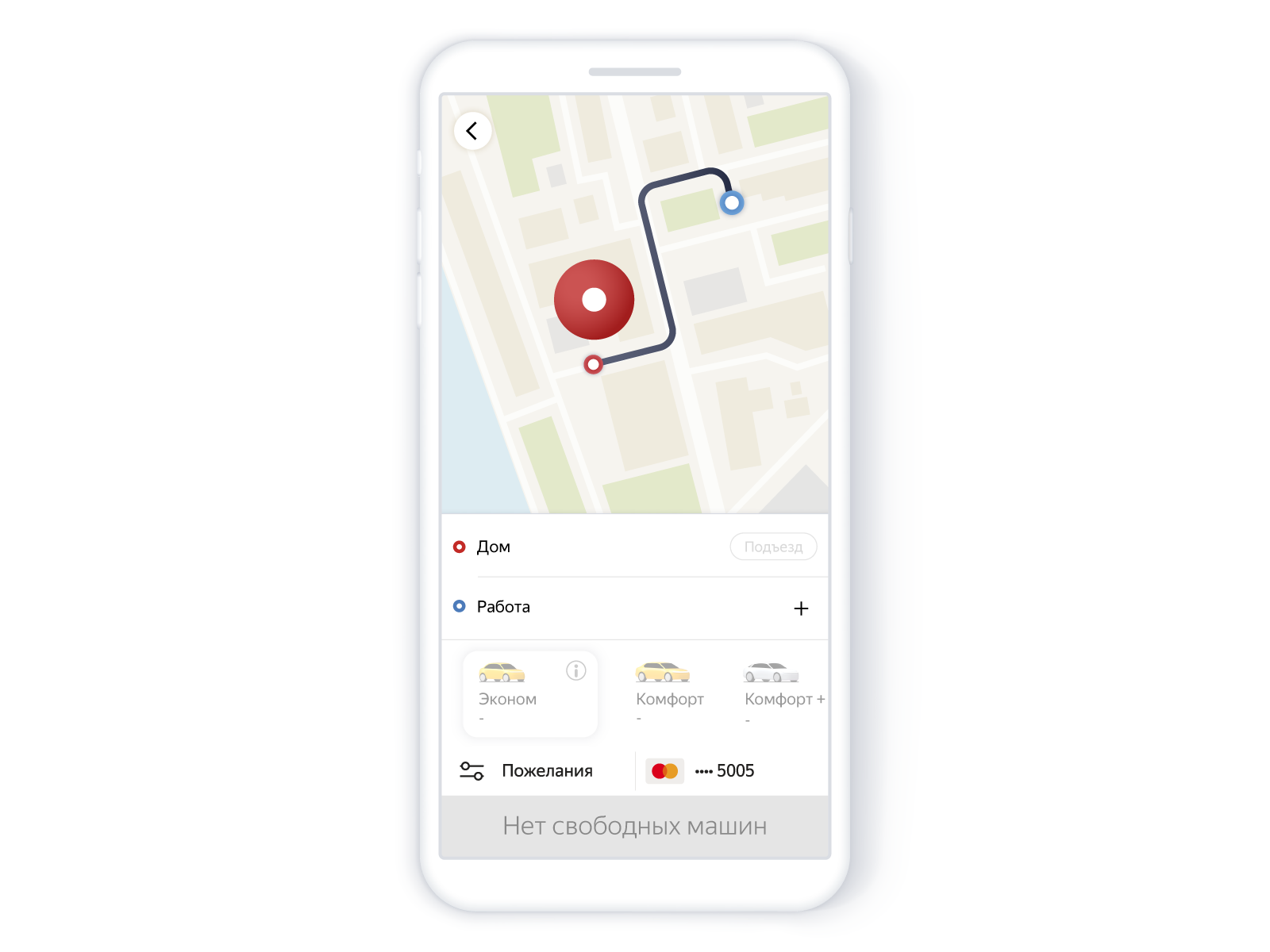
搜索没有汽车的汽车
一旦有了一个假设:也许在某些情况下,即使没有大头针,订单仍然可以完成。 实际上,在图钉和订单之间经过了一段时间,订单上的搜索更加完整,有时还会重复几次:在此期间,可能会出现免费的驱动程序。 我们也知道相反的情况:如果在针脚上找到了驱动程序,那么在订购时就不会找到它们。 有时他们消失了,或者所有人都拒绝了命令。
为了检验这个假设,我们启动了一个实验:在针刺搜索一组测试用户的过程中,我们停止了检查机器是否存在的工作,也就是说,他们有机会下达“没有汽车的订单”。 结果是非常出乎意料的:
如果汽车不在大头针上,那么在29%的情况下,它是后来的-当寻找订单时! 此外,没有汽车的订单在取消率,等级和其他质量指标方面与通常的订单没有太大差异。 没有汽车的订单数量占所有订单的5%,但仅占所有成功行程的1%以上。
为了了解这些命令的执行者来自哪里,让我们在图钉上搜索期间查看它们的状态:
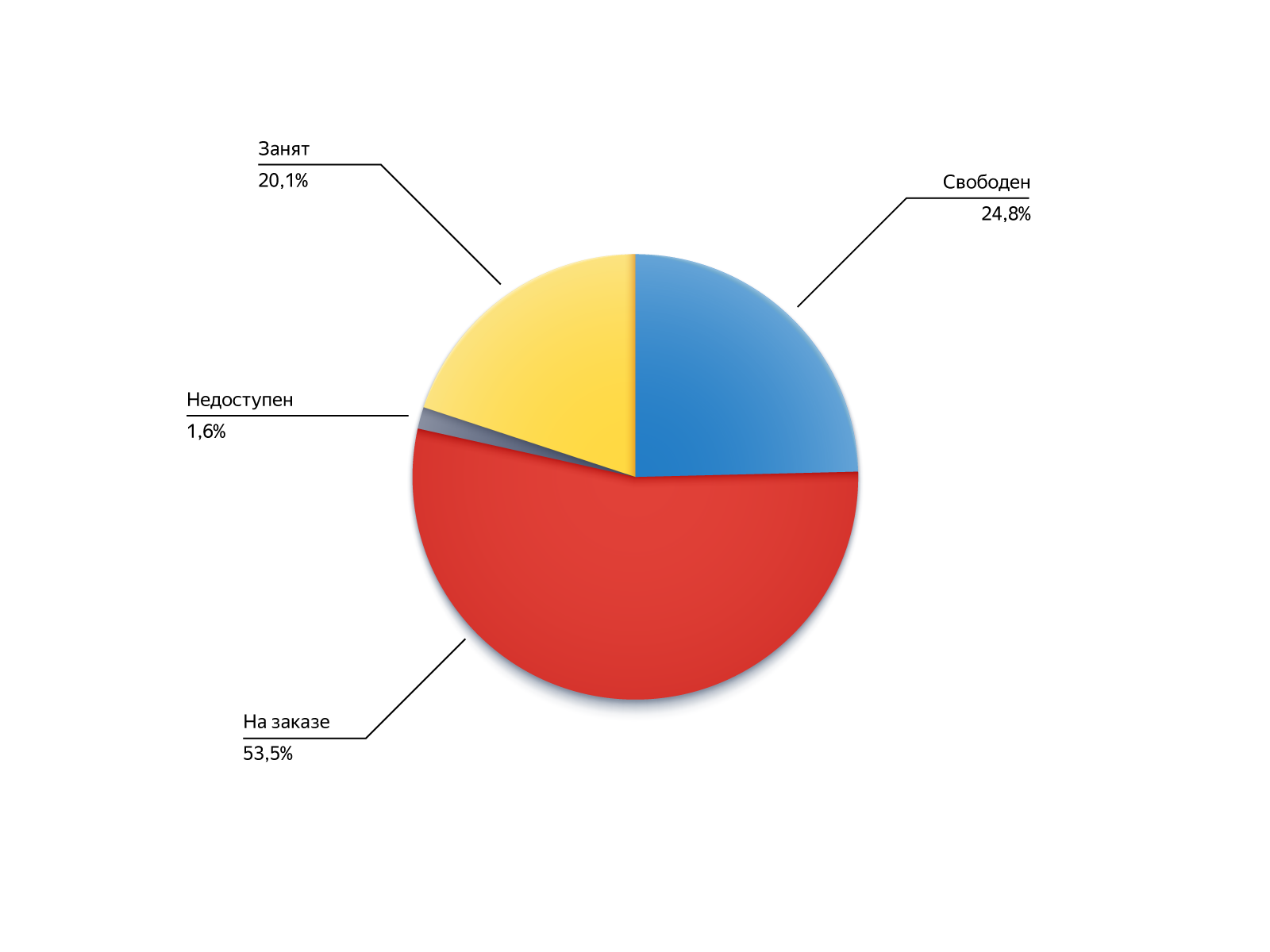
- 免费:可以使用,但由于某种原因未能进入候选人,例如,距离太远;
- 接受订单:他很忙,但是设法使自己解放出来或可以沿着链进行订购 ;
- 忙:接受订单的功能被禁用,但随后驾驶员返回生产线;
- 不可用:驱动程序不在线,但他出现了。
增加可靠性
额外的订单很棒,但是29%的成功搜索意味着在71%的情况下,用户已经等待了很长时间,结果没有离开任何地方。 尽管从系统效率的角度来看这并不可怕,但实际上,用户收到了错误的希望并花费了时间,此后他感到不安,并且(有可能)停止使用该服务。 为了解决这个问题,我们学会了预测在订单上找到机器的可能性。
该方案如下:
- 用户放置图钉。
- 搜索图钉。
- 如果没有汽车,我们预测:也许它们会出现。
- 并且根据概率,我们发出或不发出命令,但是我们警告此时该区域的汽车密度很小。
在应用程序中,它看起来像这样:
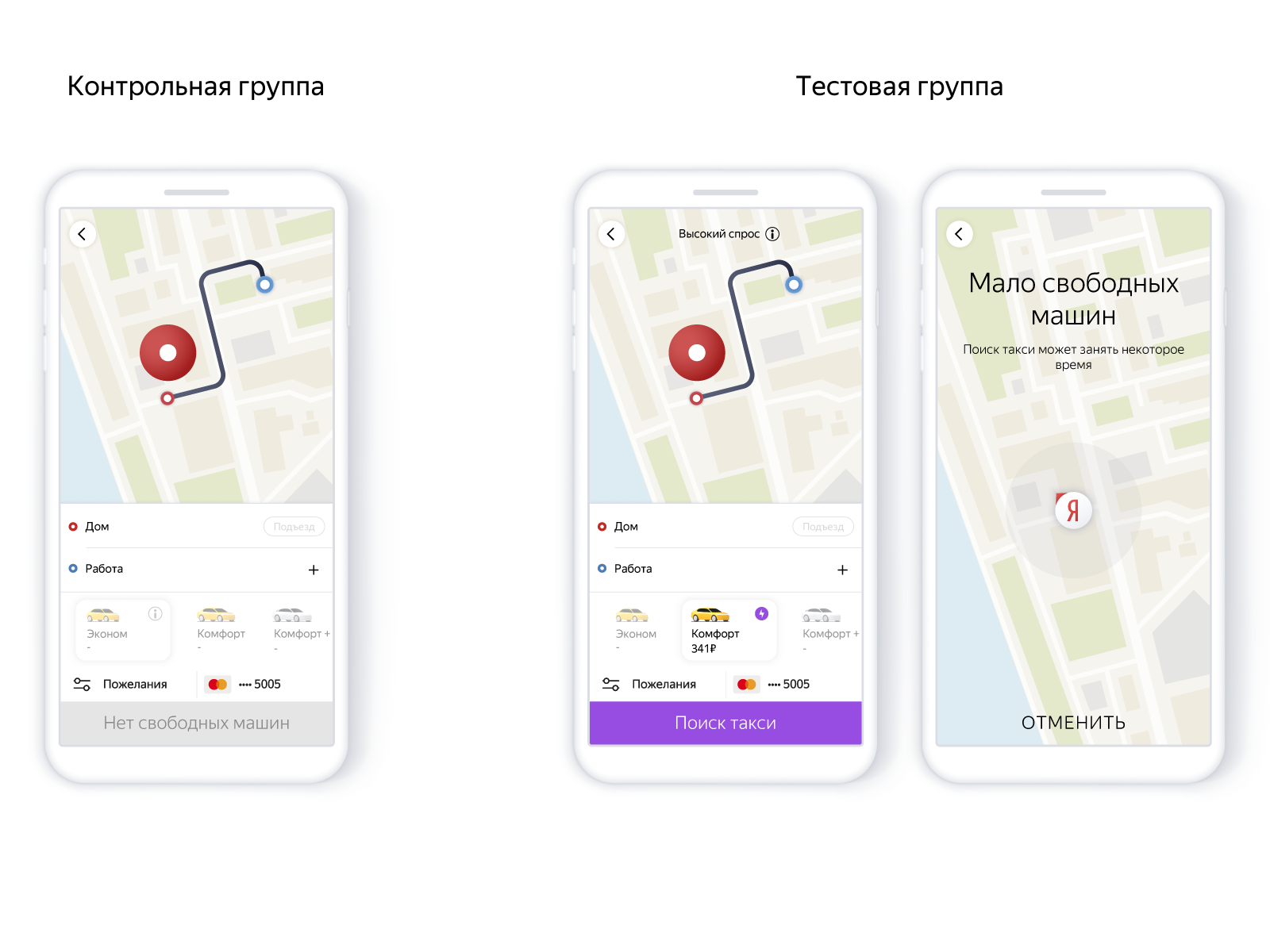
使用该模型可以使您仔细创建新订单,而不用向一个人保证。 也就是说,使用精确召回模型来调整可靠性比和不带机器的订单数量。 服务的可靠性影响继续使用该产品的愿望,即最终归结为行程次数。
关于精度调用的一点机器学习的基本任务之一是分类问题:将对象分配给两个类之一。 在这种情况下,机器学习算法的运算结果通常成为属于类别之一的数值估计,例如概率估计。 但是,执行的动作通常是二进制的:如果我们有汽车,那么我们将其定购,否则,我们将其定购。 为了确定性,我们将模型称为产生数值估计的算法,将分类器称为与两个类别(1或–1)之一相关的规则。 为了基于模型的评估进行分类,您需要选择评估阈值。 精确程度-高度取决于任务。
假设我们对一些罕见和危险的疾病进行了测试(分类器)。 根据测试结果,我们要么让患者接受更详细的检查,要么说:“健康,回家”。 对我们来说,送一个病人回家比徒劳地检查一个健康人差得多。 就是说,我们希望该测试对尽可能多的真正患病的人有效。 此值称为召回率=
。 理想的分类器召回率为100%。 堕落的情况是派大家进行检查,然后召回率也将是100%。
它发生,反之亦然。 例如,我们为学生制作了一个测试系统,它具有一个作弊检测器。 如果突然检查对某些作弊情况不起作用,则这是令人不愉快的,但不是很关键。 另一方面,不公平地责怪学生没有做的事情是非常糟糕的。 也就是说,对我们来说很重要的是,在分类器的肯定答案中,应该有尽可能多的正确答案,这可能会损害它们的数量。 因此,您需要最大化精度=
。 如果开始对所有对象进行操作,则精度将等于样本中确定的类的频率。
如果算法给出概率的数值,则选择不同的阈值,您可以实现不同的精确调用值。
在我们的任务中,情况如下。 回忆是我们可以提供的订单数量,精度是这些订单的可靠性。 这是模型的精确召回曲线:
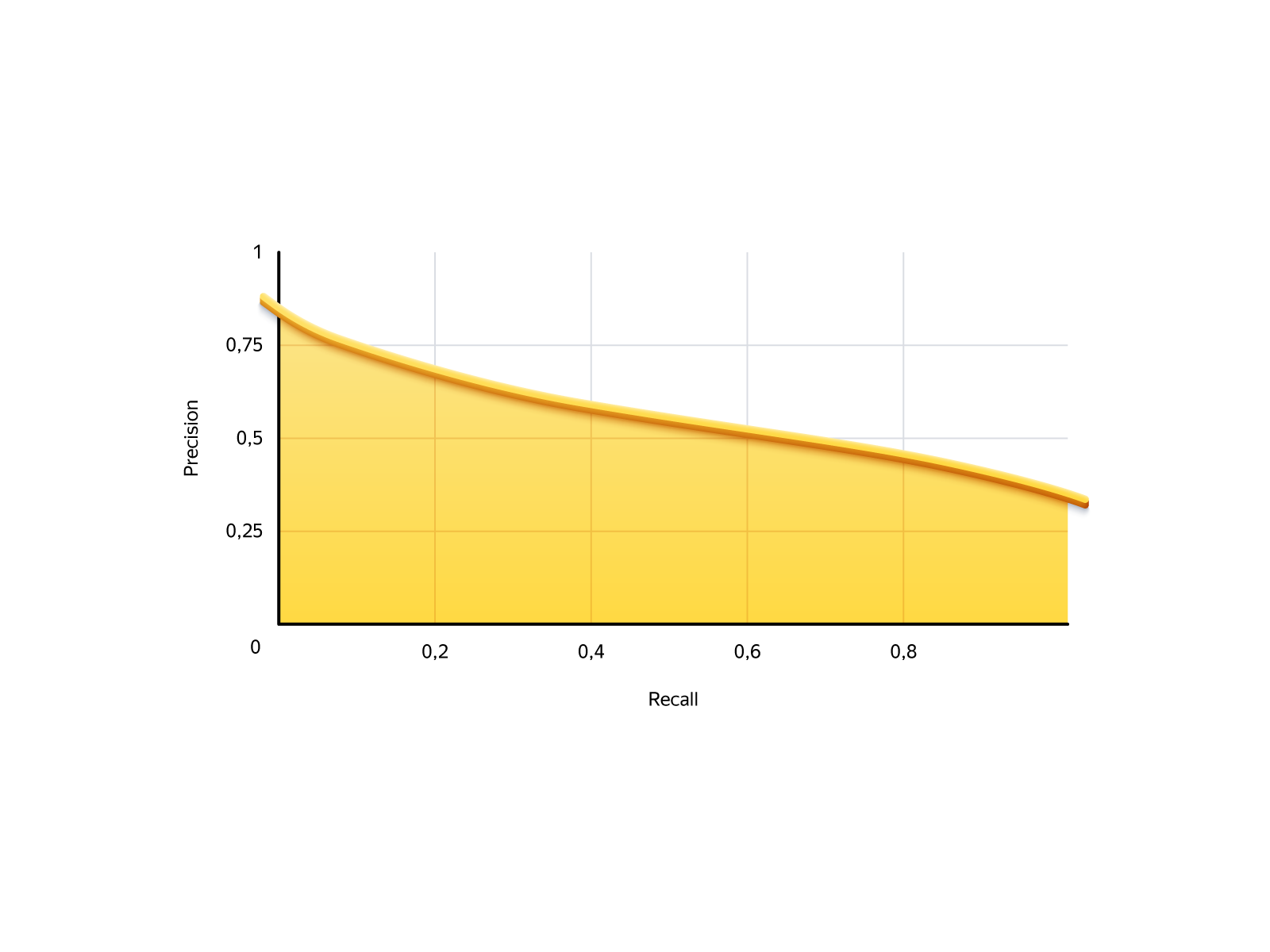
有两种极端的情况:不允许任何人订购和允许每个人订购。 如果您不允许任何人,则召回率将为0:我们不创建订单,但是它们都不会失败。 如果允许所有人,则召回率将为100%(我们将收到所有可能的订单),而精度为29%,即71%的订单将被证明是不好的。
作为标志,我们使用了出发点的各种参数:
- 时间/地点。
- 系统状态(附近所有收费标准和大头针占用的汽车数量)。
- 搜索参数(半径,候选数,限制)。
症状详情
从概念上讲,我们要区分两种情况:
- “死森林”-目前没有汽车。
- “倒霉”-有汽车,但搜索时没有合适的汽车。
“不幸”的一个例子是,周五晚上中心需求量很大。 订单很多,很多人想要很多,根本没有足够的驱动程序。 可能会这样发生:引脚上没有合适的驱动器。 但是从字面上看,它们会在几秒钟内出现,因为此时此位置有许多驱动程序,并且它们的状态不断变化。
因此,事实证明,系统在A点附近的各种功能都是不错的功能:
- 汽车总数。
- 订购的汽车数量。
- 处于“繁忙”状态的不可订购的机器数。
- 用户数。
毕竟,周围越多的汽车,它们中的任何一辆都变得更有可能。
实际上,不仅要拥有汽车,而且要成功旅行对我们来说很重要。 因此,可以预测成功旅行的可能性。 但是我们决定不这样做,因为此值高度依赖于用户和驱动程序。
CatBoost被用作模型学习算法。 为了进行训练,我们使用了从实验中获得的数据。 在实施之后,有必要收集训练数据,有时允许少量用户下达与模型决定相反的命令。
总结
实验结果出乎意料:该模型的使用可以显着增加无车定单导致的成功出行次数,但同时又不会降低可靠性。
目前,该机制已在所有城市和国家/地区启动,大约成功旅行的1%。 此外,在一些汽车密度较低的城市,此类出行的比例达到15%。
其他出租车技术岗位