
特斯拉自治区投资者日第二部分的解密。 自动驾驶培训周期,数据收集基础设施,自动数据标记,人工驾驶员模仿,视频距离检测,传感器监控等等。第一部分是全自动驾驶计算机(FSDC)的发展 。主持人: FSDC可以与非常复杂的神经网络一起进行图像处理。 现在该讨论我们如何获取图像以及如何对其进行分析。 我们在特斯拉有一位高级AI总监Andrei Karpaty,他将向您解释所有这一切。
Andrei:我已经接受了大约10年的神经网络培训,现在已经有5-6年的工业使用经验。 包括斯坦福大学,Open AI和Google等知名机构。 这套神经网络不仅用于图像处理,还用于自然语言。 我为博士论文设计了将这两种方式结合在一起的体系结构。
在斯坦福大学,我教授了反卷积神经网络课程。 我是主要老师,并为他开发了整个课程。 一开始我有大约150名学生,在接下来的两三年中,学生人数增加到700名。这是一门非常受欢迎的课程,是斯坦福大学目前最大,最成功的课程之一。
伊隆:安德烈(Andrey)确实是世界上最好的机器视觉专家之一。 也许是最好的。
安德鲁:谢谢。 大家好 皮特(Pete)向您介绍了我们专门为汽车神经网络开发的芯片。 我的团队负责训练这些神经网络。 这包括数据收集,培训以及部分部署。
汽车中的神经网络有什么作用。 汽车上有八个摄像头可以拍摄视频。 神经网络观看这些视频,对其进行处理,并对所看到的进行预测。 我们对道路标记,交通参与者,其他物体及其距离,道路,交通信号灯,交通标志等感兴趣。

我的演讲可以分为三个部分。 首先,我将向您简要介绍神经网络,以及它们的工作原理和训练方法。 必须这样做,以便在第二部分中清楚说明为什么拥有如此庞大的特斯拉汽车车队(车队)如此重要。 为什么这是训练在旅途中有效工作的神经网络的关键因素? 在第三部分中,我将讨论机器视觉,激光雷达以及如何仅使用视频来估计距离。
神经网络如何工作?
(这里没有太多新内容,您可以跳过并转到下一个标题)网络在汽车中解决的主要任务是模式识别。 对于我们人类来说,这是一个非常简单的任务。 您查看图像,然后看到大提琴,船,鬣蜥或剪刀。 对您来说非常容易和简单,但对计算机而言却不是。 原因是这些计算机图像只是一个像素阵列,其中每个像素都是该点的亮度值。 计算机不仅会看到图像,而且还会以阵列形式接收一百万个数字。
伊隆:如果需要,可以选择矩阵。 真的是矩阵。
 安德鲁:
安德鲁:是的。 我们需要从像素和亮度值的网格过渡到诸如鬣蜥等更高级的概念。 可以想象,鬣蜥的图像具有特定的亮度模式。 但是鬣蜥可以在不同的背景下以不同的方式,不同的姿势,不同的照明条件进行描绘。 您可以找到许多不同的鬣蜥图像,我们必须在任何情况下都可以识别它。
您和我可以轻松处理此问题的原因是,我们内部有一个庞大的神经网络可以处理图像。 光线进入视网膜,并传输到大脑的后部,到达视觉皮层。 大脑皮层由许多相互连接并执行模式识别的神经元组成。
在过去的五年中,使用计算机进行图像处理的现代方法也开始使用神经网络,但在这种情况下是人工神经网络。 人工神经网络是视觉皮层的粗略数学近似。 这里也有神经元,它们相互连接。 典型的神经网络包括数以千万计的神经元,每个神经元具有数千个链接。
我们可以采用一个神经网络并向其显示图像,例如鬣蜥,然后该网络将对其做出预测。 首先,神经网络是完全意外地初始化的,神经元之间连接的所有权重都是随机数。 因此,网络预测也将是随机的。 事实证明,网络认为这可能是一条船。 在训练过程中,我们知道并注意到鬣蜥在图像上。 我们只是简单地说,我们希望该图像的鬣蜥的可能性增加,而其他所有事物的可能性都减少。 然后使用称为反向传播方法的数学过程。 随机梯度下降,这使我们可以沿链路传播信号并更新其权重。 我们将相当多地更新每种化合物的权重,一旦更新完成,此图像上鬣蜥的概率将略有增加,而其他答案的概率将降低。
当然,我们使用多个图像进行此操作。 我们有大量的标记数据。 通常这些是数百万个图像,数千个标签左右。 学习过程一次又一次地重复。 您向计算机显示一个图像,它告诉您它的意见,然后您说出正确的答案,并且网络已稍作配置。 您重复此操作数百万次,有时显示同一图像数百次。 培训通常需要几个小时或几天。
现在,关于神经网络的工作有些反常理。 他们确实需要很多例子。 它不仅适合您的大脑,而且真的是从头开始,他们什么都不知道。 这是一个例子-一只可爱的狗,你可能不知道她的品种。 这是日本猎犬。 我们正在看这张照片,看到一个日本西班牙猎狗。 我们可以说:“好,我知道了,现在我知道了日本猎犬的模样。” 如果我再给您看一些其他狗的图片,您会在其中找到其他日本猎犬。 您只需要一个示例,而计算机则不需要。 他们需要大量有关日本猎犬的数据,数千个示例,不同的姿势,不同的照明条件,不同的背景等。 您需要向计算机显示从不同角度看日本西班牙猎狗的外观。 他确实需要所有这些数据,否则计算机将无法学习所需的模板。
自动驾驶仪的图像布局
那么这与自动驾驶有何关系。 我们不是很关心狗的品种。 也许他们将来会在意。 但是现在我们对道路标记,道路上的物体,它们在哪里,我们可以去的地方等等感兴趣。 现在,我们不仅拥有像鬣蜥这样的标签,还拥有道路的图像,并且我们对例如道路标记感兴趣。 一个人看着图像并用鼠标对其进行标记。

我们有机会联系特斯拉汽车,并索取更多照片。 如果您需要随机照片,通常会在汽车沿着高速公路行驶的地方获取图像。 这将是一个随机数据集,我们将对其进行标记。
如果仅标记随机集,则您的网络将学习一种简单的常见流量情况,并且只能在其中正常运行。 当您向她展示一个稍有不同的示例时,假设有一个住宅区中的道路转弯的图像。 您的网络可能会给出错误的结果。 她会说:“好吧,我已经看过很多次了,这条路直走了。”

当然,这是完全不正确的。 但是我们不能怪神经网络。 她不知道左边的树,右边的车或背景中的建筑物是否重要。 网络对此一无所知。 我们都知道标记线很重要,而且标记稍微向侧面弯曲。 网络应该考虑到这一点,但是没有机制可以简单地告诉神经网络道路标记的这些笔画确实很重要。 我们手中唯一的工具是标记数据。

我们拍摄错误的网络图像,并正确标记它们。 在这种情况下,我们标记车削标记。 然后,您需要将许多相似的图像传输到神经网络。 随着时间的流逝,她将积累知识并学会理解这种模式,以了解图像的这一部分没有作用,但是这种标记非常重要。 网络将学习如何正确找到车道。
不仅训练数据集的大小很重要。 我们不仅需要数百万张图片。 为了覆盖汽车在道路上可能遇到的情况的空间,需要做大量的工作。 您需要教计算机在晚上和雨中工作。 道路可以像镜子一样反射光,照明可以在很大的范围内变化,图像看起来会非常不同。

我们必须教计算机如何处理阴影,叉子和占据大部分图像的大物体。 如何在隧道或修路区工作。 在所有这些情况下,都没有直接的机制来告诉网络该怎么做。 我们只有一个庞大的数据集。 我们可以拍摄图像,标记和训练网络,直到它开始了解它们的结构为止。
庞大而多样的数据集可帮助网络正常运行。 这不是我们的发现。 实验和研究Google,Facebook,百度,Alphabet的Deepmind。 所有这些都显示出相似的结果-神经网络真的像数据一样,如数量和种类。 添加更多数据,神经网络的准确性不断提高。
您将必须开发一个自动驾驶仪来模拟汽车的行为
许多专家指出,我们可以使用仿真来获得适当规模的必要数据。 在特斯拉,我们已经反复问过这个问题。 我们有自己的模拟器。 我们广泛使用仿真来开发和评估软件。 我们将其成功地用于训练。 但是最后,当涉及到训练神经网络数据时,没有什么可以替代真实数据。 模拟在建模参与者的外观,物理学和行为方面存在问题。

现实世界给我们带来了许多意外情况。 艰难的条件下有雪,树,风。 各种难以建模的视觉伪影。 道路维修区,灌木丛,塑料袋悬挂在风中。 可能有很多人,成年人,儿童和动物混杂在一起。 对所有行为和交互进行建模是一项绝对不可解决的任务。

这与行人的活动无关。 这是关于行人如何相互反应,汽车如何相互反应,他们如何对您做出反应。 所有这些都是很难模拟的。 您需要首先开发一个自动驾驶仪,仅在模拟中模拟汽车的行为。
这真的很难。 可能是狗,外来动物,有时甚至甚至都不是您无法假装的东西,而这是您永远不会想到的。 我不知道卡车可以载运一辆载有另一辆卡车的卡车。 但是在现实世界中,这件事和许多其他事情正在发生,这是很难想象的。 我在汽车数据中看到的多样性与我们在模拟器中拥有的相比简直是疯狂。 虽然我们有一个很好的模拟器。
伊隆:模拟就像是您自己发明自己的作业一样。 如果您知道要假装,好吧,那您当然会处理的。 但是正如安德烈(Andrei)所说,您不知道不知道什么。 这个世界很奇怪,有数百万个特例。 如果有人创造了能够真实再现现实的驾驶模拟,那么这本身将是人类的不朽成就。 但是没有人能做到这一点。 根本没有办法。
舰队是训练的关键数据源
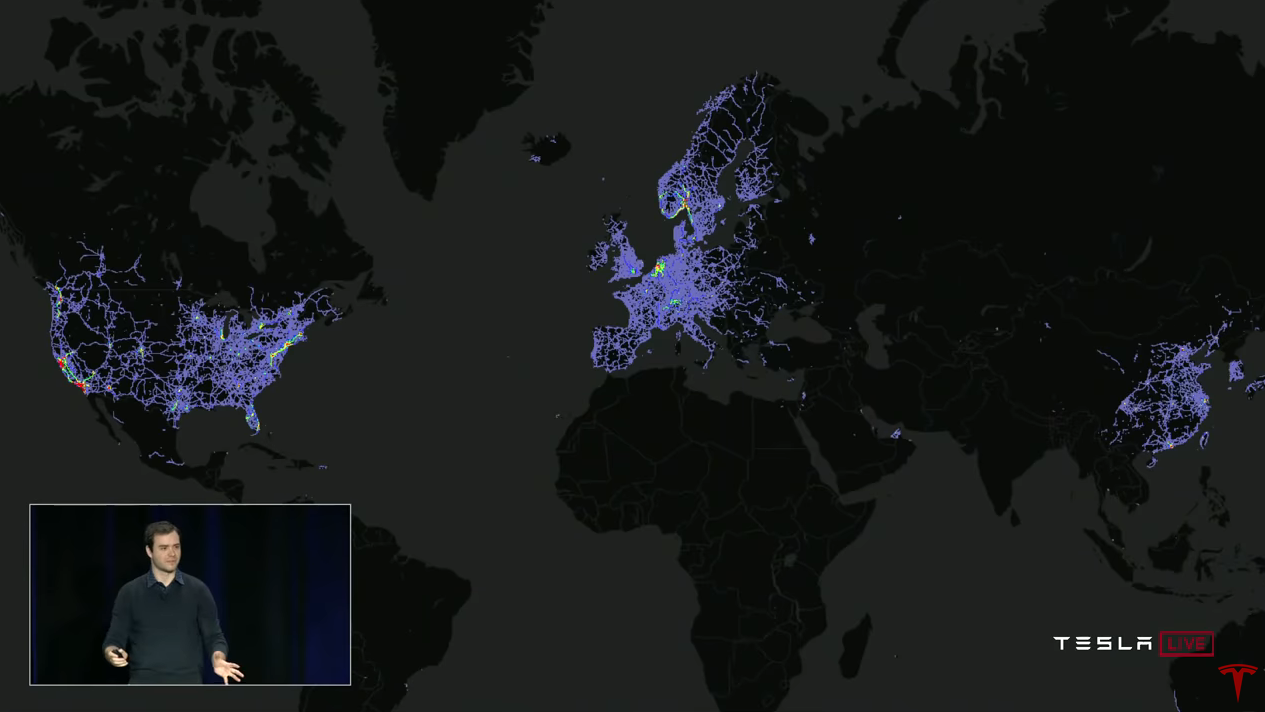 Andrei:
Andrei:为了使神经网络正常工作,您需要庞大,多样且真实的数据集。 而且,如果您有一个,则可以训练您的神经网络,它将很好地工作。 那么,为什么特斯拉在这方面如此特别? 答案当然是舰队(舰队,特斯拉舰队)。 我们可以从所有特斯拉车辆中收集数据,并将其用于培训。
让我们看一个改进对象检测器操作的特定示例。 这将使您了解我们如何训练神经网络,如何使用它们以及它们如何随着时间的推移而变得更好。
对象检测是我们最重要的任务之一。 我们需要突出显示汽车和其他物体的尺寸,以便跟踪它们并了解它们如何运动。 我们可以要求人们标记图像。 人们会说:“这里有汽车,这里有自行车”,依此类推。 我们可以根据这些数据训练神经网络。 但是在某些情况下,网络会做出错误的预测。

例如,如果我们偶然发现一辆在后面连接有自行车的汽车,则我们的神经网络将检测到两个对象-汽车和自行车。 我刚到的时候就是这样工作的。 并且以其自己的方式是正确的,因为这两个对象确实存在于此。 但是自动驾驶计划者并不在乎这个自行车是与汽车一起移动的独立物体这一事实。 事实是,这辆自行车牢固地固定在汽车上。 就道路上的物体而言,这是一个物体-一辆汽车。

现在,我们想将许多类似的对象标记为“一辆汽车”。 我们的团队使用以下方法。 我们拍摄该图像或其中存在这种模型的几个图像。 我们拥有一种机器学习机制,可以通过该机制要求机队向我们提供外观相同的示例。 舰队发送图像作为响应。

这是六个接收的图像的示例。 它们都包含与汽车相连的自行车。 我们会正确标记它们,并且我们的探测器会更好地工作。 网络将开始了解何时将自行车连接到汽车,并且这是一个对象。 只要您有足够的示例,就可以以此训练网络。 这就是我们解决此类问题的方式。
我谈论了很多有关从特斯拉汽车获取数据的事情。 我想马上说,我们从一开始就考虑到机密性开发了该系统。 我们用于训练的所有数据都是匿名的。
车队不仅向我们发送了骑自行车的自行车。 我们一直在寻找许多不同的模型。 例如,我们正在寻找船-船队发送道路上船的图像。 我们需要道路维修区域的图像,车队向我们发送了许多来自世界各地的图像。 或例如道路上的垃圾,这也很重要。 车队向我们发送了道路上的轮胎,圆锥,塑料袋等的图像。

我们可以获得足够的图像,正确标记它们,然后神经网络将学习如何在现实世界中使用它们。 我们需要神经网络来了解正在发生的事情并做出正确的响应。
神经网络不确定性触发数据收集
我们一次又一次地重复训练神经网络的过程如下。 我们从舰队收到的随机图像开始。 我们标记图像,训练神经网络并将其加载到汽车中。 我们拥有检测自动驾驶仪操作不准确的机制。 如果我们发现神经网络不确定或存在驾驶员干预或其他事件,则会自动发送发生该事件的数据。

例如,隧道标记难以识别。 我们注意到隧道中存在问题。 相应的图像落入我们的单元测试中,因此以后无法重复出现此问题。 现在,要解决此问题,我们需要大量的培训示例。 我们要求车队向我们发送更多的隧道图像,正确标记它们,将它们添加到训练集中并重新训练网络,然后将其加载到汽车中。 这个循环一遍又一遍地重复。 我们将此迭代过程称为数据引擎(数据引擎?数据引擎?)。 我们以影子模式打开网络,检测错误,请求更多数据,并将它们包括在训练集中。 我们这样做是为了对神经网络进行各种预测。
自动数据标记
我谈论了很多关于图像的手动标记。 无论是在时间上还是在财务上,这都是一个昂贵的过程。 可能太贵了。 我想在这里谈谈如何使用车队。 手动标记是一个瓶颈。 我们只想传输数据并自动对其进行标记。 为此,有几种机制。
例如,我们最近的一个项目是重建检测。
您正在高速公路上行驶,有人在向左或向右行驶,而他正在重建进入您的车道。 这是自动驾驶仪检测到重建的视频。当然,我们希望尽快发现它。解决此问题的方法是,我们不编写类似以下代码的代码:左方向指示灯亮,右方向指示灯亮,汽车是否随时间水平移动。相反,我们使用基于舰队的自动学习。如何运作?每当记录到车道的重建情况时,我们都要求车队向我们发送数据。然后我们倒带时间,并自动注意到这辆车将在1.3秒内在您面前重建。这些数据可用于训练神经网络。因此,神经网络本身将提取必要的信号。例如,一辆汽车正在搜寻然后进行重建,或者其转向信号灯已打开。神经网络从自动标记的示例中了解所有这些信息。
这是自动驾驶仪检测到重建的视频。当然,我们希望尽快发现它。解决此问题的方法是,我们不编写类似以下代码的代码:左方向指示灯亮,右方向指示灯亮,汽车是否随时间水平移动。相反,我们使用基于舰队的自动学习。如何运作?每当记录到车道的重建情况时,我们都要求车队向我们发送数据。然后我们倒带时间,并自动注意到这辆车将在1.3秒内在您面前重建。这些数据可用于训练神经网络。因此,神经网络本身将提取必要的信号。例如,一辆汽车正在搜寻然后进行重建,或者其转向信号灯已打开。神经网络从自动标记的示例中了解所有这些信息。阴影检查
我们要求车队自动向我们发送数据。我们可以收集50万张左右的图像,并且将在所有图像上标记重建内容。我们训练网络并将其加载到车队中。但是直到我们完全打开它,然后以阴影模式运行它。在这种模式下,网络会不断做出预测:“嘿,我认为这辆车将会被重建。”我们正在寻找错误的预测。 这是我们从阴影模式获得的剪辑的示例。在这里情况似乎并不明显,并且网络认为右侧的汽车即将重建。您可能会注意到他正在稍微跟标记线调情。网络对此做出了反应,并建议这辆车很快就会在我们的车道上。但这没有发生。网络在影子模式下运行并进行预测。其中有假阳性和假阴性。有时网络会做出错误反应,有时会跳过事件。所有这些错误都会触发数据收集。标记数据并将其合并到培训中,无需额外的努力。在此过程中,我们不会危害人们。我们重新训练网络并再次使用阴影模式。我们可以重复几次,以评估实际交通状况下的虚假警报。一旦指示器适合我们,我们只需单击开关,然后让网络控制汽车。大约三个月前,我们推出了第一个版本的重建检测器。如果您发现机器在检测重建方面已经变得更好,那就是在实际行动中训练舰队。在此过程中,没有一个人受伤。只是大量的基于真实数据的神经网络训练,使用阴影模式并分析结果。伊隆:实际上,所有驱动程序都在不断训练网络。自动驾驶仪是打开还是关闭都没有关系。网络正在学习。具有HW2.0或更高设备的机器所经过的每英里都可以教育网络。
这是我们从阴影模式获得的剪辑的示例。在这里情况似乎并不明显,并且网络认为右侧的汽车即将重建。您可能会注意到他正在稍微跟标记线调情。网络对此做出了反应,并建议这辆车很快就会在我们的车道上。但这没有发生。网络在影子模式下运行并进行预测。其中有假阳性和假阴性。有时网络会做出错误反应,有时会跳过事件。所有这些错误都会触发数据收集。标记数据并将其合并到培训中,无需额外的努力。在此过程中,我们不会危害人们。我们重新训练网络并再次使用阴影模式。我们可以重复几次,以评估实际交通状况下的虚假警报。一旦指示器适合我们,我们只需单击开关,然后让网络控制汽车。大约三个月前,我们推出了第一个版本的重建检测器。如果您发现机器在检测重建方面已经变得更好,那就是在实际行动中训练舰队。在此过程中,没有一个人受伤。只是大量的基于真实数据的神经网络训练,使用阴影模式并分析结果。伊隆:实际上,所有驱动程序都在不断训练网络。自动驾驶仪是打开还是关闭都没有关系。网络正在学习。具有HW2.0或更高设备的机器所经过的每英里都可以教育网络。在驾驶时,您实际上是在标记数据
 安德烈:我们在车队训练计划中使用的另一个有趣的项目是预测路线。当您开车时,实际上是在标记数据。您告诉我们如何在不同的驾驶情况下驾驶。这是在十字路口左转的驾驶员之一。我们拥有所有摄像机的完整视频,并且我们知道驾驶员选择的路径。我们还知道方向盘的速度和旋转角度是多少。我们将所有这些放在一起,并了解人们在这种交通状况下选择的路径。我们可以将其用作与老师一起教学。我们只是从舰队中获取必要的数据量,在这些轨迹上训练网络,然后神经网络可以预测路径。这称为模仿学习。我们采用现实世界中人们的轨迹,并尝试模仿他们。同样,我们可以采用迭代方法。这是在困难路况下预测路径的示例。在视频中,我们叠加了网络预测。绿色标记网络将移动的路径。
安德烈:我们在车队训练计划中使用的另一个有趣的项目是预测路线。当您开车时,实际上是在标记数据。您告诉我们如何在不同的驾驶情况下驾驶。这是在十字路口左转的驾驶员之一。我们拥有所有摄像机的完整视频,并且我们知道驾驶员选择的路径。我们还知道方向盘的速度和旋转角度是多少。我们将所有这些放在一起,并了解人们在这种交通状况下选择的路径。我们可以将其用作与老师一起教学。我们只是从舰队中获取必要的数据量,在这些轨迹上训练网络,然后神经网络可以预测路径。这称为模仿学习。我们采用现实世界中人们的轨迹,并尝试模仿他们。同样,我们可以采用迭代方法。这是在困难路况下预测路径的示例。在视频中,我们叠加了网络预测。绿色标记网络将移动的路径。 Ilon:疯狂的是网络预测了它甚至看不到的路径。具有难以置信的高精度。她看不到拐弯处的情况,但她认为这种轨迹的可能性非常高。事实证明是正确的。今天,您将在汽车中看到它,我们将提供增强的视野,以便您可以看到叠加在视频上的轨迹的标记和投影。安德烈:事实上,在幕后,发生的最多,而且伊隆:实际上,这有点吓人(安德烈笑了)。安德鲁:当然,我错过了很多细节。您可能不想连续使用所有驱动程序进行标记,而是想模仿最好的驱动程序。我们使用多种方法来准备这些数据。有趣的是,该预测实际上是三维的。这是我们以2D显示的三维空间中的路径。但是网络具有有关坡度的信息,这对于行驶非常重要。预测当前汽车中的工作方式。顺便说一句,大约五个月前,当您通过高速公路上的路口时,您的汽车无法应对。现在可以了。这是对您汽车行驶方式的预测。不久前我们打开了它。今天,您可以看到交叉路口的工作原理。通过自动标记数据可以获得克服交叉口训练的重要部分。我设法谈论了神经网络训练的关键组成部分。您需要大量不同的真实数据。在特斯拉,我们使用车队来获得它。我们使用数据引擎,影子模式和使用车队的自动数据分区。我们可以扩展这种方法。
Ilon:疯狂的是网络预测了它甚至看不到的路径。具有难以置信的高精度。她看不到拐弯处的情况,但她认为这种轨迹的可能性非常高。事实证明是正确的。今天,您将在汽车中看到它,我们将提供增强的视野,以便您可以看到叠加在视频上的轨迹的标记和投影。安德烈:事实上,在幕后,发生的最多,而且伊隆:实际上,这有点吓人(安德烈笑了)。安德鲁:当然,我错过了很多细节。您可能不想连续使用所有驱动程序进行标记,而是想模仿最好的驱动程序。我们使用多种方法来准备这些数据。有趣的是,该预测实际上是三维的。这是我们以2D显示的三维空间中的路径。但是网络具有有关坡度的信息,这对于行驶非常重要。预测当前汽车中的工作方式。顺便说一句,大约五个月前,当您通过高速公路上的路口时,您的汽车无法应对。现在可以了。这是对您汽车行驶方式的预测。不久前我们打开了它。今天,您可以看到交叉路口的工作原理。通过自动标记数据可以获得克服交叉口训练的重要部分。我设法谈论了神经网络训练的关键组成部分。您需要大量不同的真实数据。在特斯拉,我们使用车队来获得它。我们使用数据引擎,影子模式和使用车队的自动数据分区。我们可以扩展这种方法。通过视频感知深度
 在演讲的下一部分中,我将讨论通过视觉感知深度。您可能知道,汽车至少使用两种类型的传感器。一种是亮度摄像机,另一种是许多公司使用的激光雷达。激光雷达提供您周围距离的点测量。我想指出的是,所有人都只使用您的神经网络和视觉来这里。您没有用眼睛的激光射击,但仍然到了这里。显然,人类神经网络可以提取距离,并仅通过视觉将世界感知为三维。她使用了许多技巧。我将简要介绍其中一些。例如,我们有两只眼睛,因此您可以看到面前的两个世界图像。您的大脑将这些信息结合起来以获得距离的估计值,这是通过对两幅图像中的点进行三角测量来完成的。在许多动物中,眼睛位于侧面,其视场略微交叉。这些动物使用结构(运动)。他们移动头部可以从不同角度获取许多世界图像,并且还可以应用三角剖分。
在演讲的下一部分中,我将讨论通过视觉感知深度。您可能知道,汽车至少使用两种类型的传感器。一种是亮度摄像机,另一种是许多公司使用的激光雷达。激光雷达提供您周围距离的点测量。我想指出的是,所有人都只使用您的神经网络和视觉来这里。您没有用眼睛的激光射击,但仍然到了这里。显然,人类神经网络可以提取距离,并仅通过视觉将世界感知为三维。她使用了许多技巧。我将简要介绍其中一些。例如,我们有两只眼睛,因此您可以看到面前的两个世界图像。您的大脑将这些信息结合起来以获得距离的估计值,这是通过对两幅图像中的点进行三角测量来完成的。在许多动物中,眼睛位于侧面,其视场略微交叉。这些动物使用结构(运动)。他们移动头部可以从不同角度获取许多世界图像,并且还可以应用三角剖分。 即使一只眼睛闭上且完全不动,您仍可以保持一定的距离感。如果您闭上一只眼睛,在您看来,我距离我只有两米或一百米。这是因为大脑也应用了许多强大的单眼技术。例如,常见的错觉,在轨道的背景上具有两个相同的条纹。您的大脑会评估场景,并期望其中的一个比另一个大,这是因为铁路线消失了。您的大脑会自动执行很多操作,而人工神经网络也可以执行此操作。我将给出三个示例,说明如何实现视频的深度感知。一种经典方法,另外两种基于神经网络。
即使一只眼睛闭上且完全不动,您仍可以保持一定的距离感。如果您闭上一只眼睛,在您看来,我距离我只有两米或一百米。这是因为大脑也应用了许多强大的单眼技术。例如,常见的错觉,在轨道的背景上具有两个相同的条纹。您的大脑会评估场景,并期望其中的一个比另一个大,这是因为铁路线消失了。您的大脑会自动执行很多操作,而人工神经网络也可以执行此操作。我将给出三个示例,说明如何实现视频的深度感知。一种经典方法,另外两种基于神经网络。 我们可以在几秒钟内拍摄视频剪辑,并使用三角测量和立体视觉方法以3D方式重新创建周围环境。我们在汽车中采用了类似的方法。最主要的是信号确实具有必要的信息,唯一的问题是提取它。
我们可以在几秒钟内拍摄视频剪辑,并使用三角测量和立体视觉方法以3D方式重新创建周围环境。我们在汽车中采用了类似的方法。最主要的是信号确实具有必要的信息,唯一的问题是提取它。使用雷达打标距离
正如我所说,神经网络是一种非常强大的视觉识别工具。如果您希望他们识别距离,则需要标记距离,然后网络将学习如何做到这一点。除了具有标记数据外,没有任何限制网络预测距离的能力。我们使用指向前方的雷达。该雷达测量并标记到神经网络看到的物体的距离。您不必告诉人们“这辆车距离酒店约25米”,而是可以使用传感器更好地标记数据。雷达在此距离下效果很好。您标记数据并训练神经网络。如果您有足够的数据,则神经网络将非常擅长预测距离。 在此图像中,圆圈显示了雷达接收的对象,长方体是神经网络接收的对象。如果网络运行良好,则在顶视图中,长方体的位置应与我们观察到的圆的位置重合。神经网络在距离预测方面做得很好。他们可以了解不同车辆的尺寸,并根据图像上的尺寸准确确定距离。
在此图像中,圆圈显示了雷达接收的对象,长方体是神经网络接收的对象。如果网络运行良好,则在顶视图中,长方体的位置应与我们观察到的圆的位置重合。神经网络在距离预测方面做得很好。他们可以了解不同车辆的尺寸,并根据图像上的尺寸准确确定距离。自我监督
我将简要讨论的最后一种机制是技术性的。关于这种方法的文章很少,主要是最近一两年。这称为自我监督。 这是怎么回事。您将原始的未标记视频上传到神经网络。而且网络仍然可以学习识别距离。无需赘述,其思想是神经网络可以预测该视频每一帧的距离。我们没有用于验证的标签,但是有一个目标-时间一致性。无论网络预测的距离是多少,在整个视频中都必须保持一致。唯一保持一致的方法是正确预测距离。网络会自动预测所有像素的深度。我们设法复制了它,并且效果很好。
这是怎么回事。您将原始的未标记视频上传到神经网络。而且网络仍然可以学习识别距离。无需赘述,其思想是神经网络可以预测该视频每一帧的距离。我们没有用于验证的标签,但是有一个目标-时间一致性。无论网络预测的距离是多少,在整个视频中都必须保持一致。唯一保持一致的方法是正确预测距离。网络会自动预测所有像素的深度。我们设法复制了它,并且效果很好。—
总结一下。
人们使用视觉,而不用激光。我想强调的是,强大的视觉识别对于自动驾驶绝对至关重要。我们需要真正了解环境的神经网络。 来自激光雷达的数据很少充满信息。这个轮廓在路上,是塑料袋还是轮胎?激光雷达只会给您一些要点,而愿景可以告诉您它是什么。这个坐在自行车上的家伙正在回望吗,他是在尝试改变车道还是在直行?在道路维修区,这些标志是什么意思,我在这里应该如何表现?是的,整个道路基础设施都是为视觉消费而设计的。所有的标志,交通信号灯,所有的东西都可以看到,这就是所有信息所在的地方。我们必须使用它。这个女孩对电话充满热情,她会走在路上吗?这些问题的答案只能在视觉的帮助下找到,它们对于4-5级自动驾驶仪是必需的。这就是我们在特斯拉正在开发的东西。我们通过大规模的神经网络培训,我们的数据引擎和车队协助来做到这一点。在这方面,激光雷达是一种尝试去砍伐道路。它绕过了机器视觉的基本任务,而自动驾驶必须解决这一问题。它给人一种错误的进步感。激光雷达仅适用于快速演示。
来自激光雷达的数据很少充满信息。这个轮廓在路上,是塑料袋还是轮胎?激光雷达只会给您一些要点,而愿景可以告诉您它是什么。这个坐在自行车上的家伙正在回望吗,他是在尝试改变车道还是在直行?在道路维修区,这些标志是什么意思,我在这里应该如何表现?是的,整个道路基础设施都是为视觉消费而设计的。所有的标志,交通信号灯,所有的东西都可以看到,这就是所有信息所在的地方。我们必须使用它。这个女孩对电话充满热情,她会走在路上吗?这些问题的答案只能在视觉的帮助下找到,它们对于4-5级自动驾驶仪是必需的。这就是我们在特斯拉正在开发的东西。我们通过大规模的神经网络培训,我们的数据引擎和车队协助来做到这一点。在这方面,激光雷达是一种尝试去砍伐道路。它绕过了机器视觉的基本任务,而自动驾驶必须解决这一问题。它给人一种错误的进步感。激光雷达仅适用于快速演示。进展与现实世界中复杂情况下发生碰撞的频率成正比。

如果我想适合一张幻灯片上所说的所有内容,它将看起来像这样。 我们需要4-5级系统,可以在99.9999%的情况下处理所有可能的情况。 追求最后的九点将是非常困难的。 这将需要非常强大的机器视觉系统。
这里显示的是您在珍惜的小数位途中可能遇到的图像。 刚开始时,您只是拥有前进的汽车,然后这些汽车开始看起来有点不寻常,自行车出现在车上,汽车出现在车上。 然后,您会遇到真正罕见的事件,例如倒车甚至是跳车。 我们满足了来自机队的数据中的许多内容。
而且,与竞争对手相比,这些罕见事件的发生频率更高。 这决定了我们通过训练神经网络获取数据和解决问题的速度。 进展的速度与您在现实世界中遇到困难的情况成正比。 而且我们比其他任何人都更经常遇到他们。 因此,我们的自动驾驶仪比其他的更好。 谢谢啦
问与答
问题:您平均每辆车收集多少数据?
安德鲁:这不仅与数据量有关,还与多样性有关。 在某个时候,您已经拥有足够的公路行驶图像,网络可以理解这些图像,因此不再需要。 因此,我们在战略上专注于获取正确的数据。 而我们的基础架构,经过相当复杂的分析,使我们能够立即获取所需的数据。 这不是关于大量数据,而是关于精选的数据。
问:我想知道您将如何解决换车道的问题。 每当我尝试重建成一条密集的小溪时,它们就会切断我的注意力。 在洛杉矶的道路上,人类行为变得不合理。 自动驾驶仪要安全驾驶,而您几乎必须这样做是不安全的。
安德鲁:我说过数据引擎是训练神经网络。 但是我们在软件级别上也是如此。 影响选择的所有参数,例如,何时重建,攻击性如何。 我们还以阴影模式更改它们,并观察它们的工作情况并调整启发式方法。 实际上,为一般情况设计这样的启发式方法是一项艰巨的任务。 我认为我们将必须使用车队培训来做出这样的决定。 人们什么时候换车道? 在什么情况下? 他们什么时候觉得改变车道不安全? 让我们看一下大量数据,教机器学习分类器区分何时重建是安全的。 这些分类器将能够编写比人更好的代码,因为它们依赖于驱动程序行为的大量数据。
伊隆:可能,我们将采用“洛杉矶交通”模式。 疯了最大模式之后的某个地方。 是的,Mad Max在洛杉矶会很难过。
安德烈(Andrei)将不得不妥协。 您不想造成不安全的情况,但是想要回家。 和人们同时表演的舞蹈,很难编程。 我认为正确的是机器学习。 在这里,我们仅着眼于人们进行模仿的许多方式。
伊隆:现在我们有点保守了,随着我们信心的
增强 ,有可能选择一个更具侵略性的政权。 用户将可以选择它。 在激进模式下,当试图在交通拥堵中改变车道时,机翼可能会起皱。 没有发生严重事故的风险。 您可以选择是否同意粉碎机翼的机会不为零。 不幸的是,这是阻塞高速公路交通的唯一方法。
问:激光雷达会有用的小数点后的那九个数字之一会发生吗? 第二个问题是,如果激光雷达真的一文不值,那么那些根据其做出决定的人会发生什么呢?
伊隆:他们都会摆脱激光雷达,这是我的预测,您可以写下来。 我必须说,我并不像看起来那样讨厌激光雷达。 SpaceX Dragon使用激光雷达移动到ISS并停靠。 为此,SpaceX从头开发了自己的激光雷达。 我亲自领导了这个项目,因为激光雷达在这种情况下很有意义。 但是在汽车中,这真是愚蠢。 它很昂贵,没有必要。 而且,正如安德烈(Andrei)所说,一旦您处理了视频,激光雷达将变得无用。 您将拥有对汽车无用的昂贵设备。
我们有一个向前雷达。 它便宜且有用,特别是在可见性差的情况下。 雾,灰尘或雪,雷达可以穿透它们。 如果要使用有源光子生成,请不要使用可见光的波长。 因为有了无源光学元件,您已经做好了可见光谱中的所有工作。 现在最好使用具有良好穿透性的波长,例如雷达。 激光雷达只是可见光谱中光子的活跃生成。 想要主动产生光子,在可见光谱之外进行。 使用3.8毫米和400-700纳米,您将能够在恶劣的天气条件下看到。 因此,我们有一个雷达。 以及十二个用于周围环境的超声波传感器。 雷达在移动方向上最有用,因为它是您移动非常快的直接原因。
我们已经多次提出传感器问题。 有足够的吗? 我们有需要的一切吗? 需要添加其他内容吗? 嗯 够了
问题:汽车似乎正在进行某种计算以确定向您发送哪些信息。 这是实时完成还是基于存储的信息?
安德烈:计算是在汽车本身中实时进行的。 我们传达了我们感兴趣的条件,汽车进行了所有必要的计算。 如果他们不这样做,我们将不得不连续传输所有数据并在后端进行处理。 我们不想这样做。
伊隆:我们有242万辆HW2.0 +的汽车。 这意味着他们有八个摄像头,一个雷达,超声波传感器和至少一台nVidia计算机。 计算哪些信息很重要而哪些不重要就足够了。 他们压缩重要信息并将其发送到网络进行培训。 这是来自现实世界的大量数据压缩。
问题:您拥有数十万台计算机组成的网络,类似于强大的分布式数据中心。 您是否看到了除自动驾驶之外的其他用途?
伊隆:我想这可以用于其他用途。 虽然我们专注于自动驾驶。 一旦将其提升到正确的水平,我们就可以考虑其他应用程序。 届时,将有数以百万计或数以千万计的带有HW3.0或FSDC的汽车。
问题:计算流量?
伊隆:是的,也许是。 它可能类似于AWS(Amazon Web Services)。
问题:我是明尼苏达州的Model 3司机,那里下雪很多。 摄像机和雷达无法在雪中看到道路标记。 您将如何解决这个问题? 您会使用高精度GPS吗?
安德鲁:今天,自动驾驶仪在积雪的道路上表现良好。 即使在大雨中标记被隐藏,磨损或被水覆盖时,自动驾驶仪的性能仍然相对良好。 我们尚未使用数据引擎专门处理积雪的道路。 但是我相信这个问题可以解决。 因为在很多雪道图像中,如果您问一个人标记应该在哪里,他就会向您显示。 人们同意在哪里画标记线。 尽管人们可以达成共识并标记您的数据,但神经网络将能够学习到这一点,并且效果很好。 唯一的问题是原始信号中是否有足够的信息。 一个人注释者足够了吗? 如果答案是肯定的,那么神经网络就可以了。
Ilon:在源信号中有几个重要的信息源。 因此,标记只是其中之一。 最重要的来源是车道。 可以去哪里,不能去哪里。 比标记更重要。 巷道识别效果很好。 我认为,尤其是在即将来临的冬天过后,它将非常有效。 我们会想知道这怎么能很好地工作。 这太疯狂了。
安德鲁:甚至与人们的标记能力无关。 只要您(一个人)可以克服这条路。 舰队将向您学习。 我们知道您如何开车到这里。 您显然为此使用了视觉。 您没有看到标记,但是您使用了整个场景的几何形状。 您会看到路弯,周围其他车辆的位置。 神经网络将自动突出显示所有这些模式,您只需要获取有关人们如何克服这种情况的足够数据即可。
Ilon:不要紧紧抓住GPS,这一点非常重要。 GPS错误可能非常明显。 而且实际的交通情况可能无法预测。 可以是修路或改道。 如果汽车过于依赖GPS,则情况很糟糕。 你在找麻烦。 GPS很好,只能用作提示。
问题:您的一些竞争对手谈论他们如何使用高清地图来改善感知和路径规划。 您在系统中使用类似的东西吗,您看到任何好处吗? 是否有您想获得更多数据的区域,而不是来自机队的数据,例如卡片?
伊隆:我认为高分辨率地图是个坏主意。 系统变得非常不稳定。 如果您已附加到GPS和高分辨率地图,并且不优先考虑视觉,则无法适应变化。 愿景是应该做的所有事情。 看到,标记只是一个准则,不是最重要的。 我们尝试使用标记卡,并很快意识到这是一个大错误。 我们完全抛弃了他们。
问题:了解物体在哪里以及汽车如何行驶非常有用。 但是谈判方面呢? 在停车期间,在回旋处以及其他情况下,您会与其他人驾驶的汽车互动。 它更是一门艺术,而不是一门科学。
伊隆:效果很好。 如果您查看带有重排等的情况,自动驾驶仪通常可以应对。
安德鲁:现在,我们使用大量的机器学习来创建现实世界的想法。 最重要的是,我们有一个调度程序和控制器,以及关于如何驾驶,如何考虑其他汽车的许多启发式方法,等等。 就像模式识别一样,这里有很多非标准案例,就像是与他人一起玩的鹰和鸽子游戏。 我们有信心最终将使用基于舰队的培训来解决此问题。 手写启发法很快就停滞在高原上。
问题:您有排排模式吗? 系统有能力做到这一点吗?
安德烈:我绝对确定我们可以制定这样的制度。 但是同样,如果您只是训练网络来模仿人们。 人们会依附在汽车前面并开车,网络会记住这种行为。 里面有一种魔力,一切都是自己发生的。 不同的问题归结为一个问题,只是收集数据集并使用它来训练神经网络。
Ilon:自动驾驶的三个步骤。 首先是简单地实现此功能。 第二个方法是使它达到一定程度,以使乘车人根本不需要注意道路。 第三是显示使监管者信服的可靠性水平。 这是三个级别。 我们预计今年将达到第一水平。 我们预计,在明年第二季度的某个地方,当人们不再需要将手放在方向盘上并注视道路时,您将达到信心水平。 此后,我们预计到明年年底至少在某些辖区将获得监管部门的批准。 这些是我的期望。
对于卡车,车队制度很可能会比其他任何方式早得到监管机构的批准。 也许对于长途旅行,您可以在车队模式中使用一名司机驾驶头顶汽车,并在他身后使用4辆半卡车。
问题:自动驾驶的改进给我留下了深刻的印象。 上周,我在高速公路的右侧车道行驶,那里有一个入口。 我的Model 3能够检测到有两辆车进入高速公路并减速,因此一辆车安静地摆在我的前面,另一辆悄悄地摆在我后面。 然后我想,该死,这太疯狂了,我不知道我的Model 3有能力做到这一点。
但是在同一周,我又在右车道上行驶,并且在变窄,我的右车道与左车道合并。 我的Model 3无法正确反应,因此我不得不干预。 你能告诉特斯拉如何解决这个问题吗?
安德鲁:我谈到了数据收集基础架构。 如果您进行了干预,那么很可能我们会收到该剪辑。 例如,他进入了统计数据,然后我们才有机会正确地进入统计数据流。 我们看这些数字,看片段,然后看错了。 并且我们正在尝试纠正行为,以便与基准测试相比获得改善。
艾隆:恩,我们还有另一个关于软件的演讲。 我们与Pete进行了设备介绍,然后与Andrey进行了神经网络讨论,现在介绍了Stuart的软件。
...